如何在NLP中有效利用Deep Transformer?
2020-01-18 04:15:10

作者 | 王子扬编辑 | Camel
2017年,谷歌在“Attention is all you need”一文中首次提出了完全基于self-attention(自注意力)机制的transformer模型,用于处理序列模型的相关问题,如机器翻译等。传统的神经机器翻译模型大都是采用RNN或者CNN作为encoder-decoder模型的基础,而Transformer模型则摒弃了固有的模式,采用完全并行化的结构,在提升了模型的性能的同时提高了训练的速度,目前已经被推广到多项自然语言处理的相关任务当中。
使用神经网络的方法解决自然语言处理的相关任务时,制约模型性能因素主要包括模型的表现力和用于进行模型训练的数据。然而在大数据时代背景下,对于很多自然语言处理的任务,我们已经能够获取到大量的高质量数据,结构简单的模型无法充分发挥海量数据的优势,不足以从数据中提取出潜在的信息和文本之间的规律,从而导致增大数据量并没有明显的性能提升,反而增加了训练的负担。因此往往需要增大模型容量来增强模型的表现力,主要的手段包括增加模型的宽度和深度。
人们广泛认知通过增加模型的隐层表示维度(宽度)即使用Transformer-Big能够有效地提高翻译的性能,但是近年来,深层网络越来越引起人们的注意,相比于增加宽度,增加模型深度具有对硬件要求低,模型收敛快等优点,本文将选取近年来有关于深层Transformer模型结构的工作进行介绍。
1、Deep Transformer在机器翻译中的应用(1)
论文标题:Learning Deep Transformer Models for Machine Translation
本文由东北大学小牛翻译团队发表于2019年ACL会议。本文的主要贡献包括:1)首次提出了transformer中的层正则化位置对于训练一个深层网络至关重要;2)提出了一种动态层信息融合的方式,提高了信息传递的效率,解决了深层网络信息传递效率差的问题,大大提高了深层网络的性能。
Pre-norm和Post-norm
文中指出transformer模型中层正则化的正确使用是学习深层编码器的关键。通过重新定位层正则化的位置将其置于每个子层的输入之前,便能够有效解决深层网络当中容易出现的梯度爆炸或者梯度消失现象,这对训练深层网络的影响在之前并未被研究过。
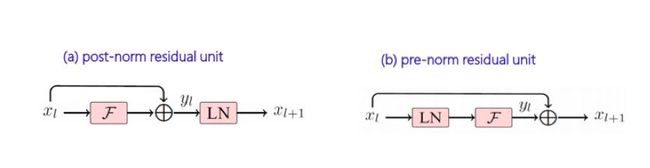
图1 post-norm和pre-norm
如图1(a)所示是传统的post-norm方式,即将层正则化位置放置在每一个子层的残差连接之后即通过对层输出进行归一化处理来防止参数漂移,增加模型训练的鲁棒性。具体的计算方式可以用如下流程表示:层输入->层计算->dropout->残差累加->层正则化。而将层正则化的位置提前,计算方式为如下流程:层输入->层正则化->层计算->dropout->残差累加。
如下图1(b)所示,通过pre-norm的方式网络在反向更新时,底层网络参数可以直接获得顶层梯度的信息,而不经过其他的变换,而传统的post-norm方式在进行梯度传递时底层的网络需要经过每一个正则化项,容易产生梯度爆炸和梯度消失的现象。
Dynamic Linear Combination of Layers
此外,pre-norm的方式已经能够帮助我们训练一个具有深层编码层的神经机器翻译系统。但随着编码端层数的加深,底层信息在传递过程中逐渐削弱,底层网络训练不充分,因此文中提出了一种动态线性聚合的方式在信息传递至下一层时对之前所有层的输出进行线性聚合。形式上为 ,其中 是一个整合之前各层输出 的现象聚合函数。在文中被定义为:

其中 是一个权重,对每个输出层进行线性加权。DLCL的方法可以被视为一个具有普适性的方法,例如,标准的残差连接可以看做DLCL的一个特例,其中 , , ,如下图a,稠密的残差连接则可以看做是一个标准加权的全连接网络如下图b,多层表示融合则可以表示为只在编码端的最顶层进行动态线性融合操作如下图c。DLCL的方法则为每个连续的编码层做一个单独的权重聚合。通过这种方式,可以在层之间创建更多的连接如图d

在WMT16-en2de,NIST OpenMT’12-ch2en和WMT18-zh2en等任务上,应用了DLCL的深层Transformer模型(30/25层编码层)相比于Transformer-Big/Base提升了0.4~2.4个BLEU值,同时相比于Transformer取得了3倍的训练加速和1.6倍的模型压缩。
2、Deep Transformer在语音识别中的应用
论文标题:Very Deep Self-Attention Networks for End-to-End Speech Recognition
这篇工作将深层的transformer 结构用于了语音识别任务,语音识别任务与机器翻译相似,采用的均是端到端的模型结构。文中分析表明,具有强大学习能力的深层Transformer网络能够超越以往端到端模型的性能。此外,为编码器和解码器结合随机残差连接训练了具有48层编码层的深层网络模型。
文中在训练深层网络时为了解决梯度消失和梯度爆炸的问题,使深层网络能够稳定训练,采用了与之前相同的pre-norm方法,同时作者认为残差网络时transformer能够多层训练,但是随着层数的加深,残差连接同样存在冗余,所以作者设计了类似drop的方式,在训练的过程中随机跳过某些子层,在图像领域中,曾有类似的方法如Stochastic Depth,随着NLP领域中深层网络的不断发展,这也是该方法首次被应用于NLP任务中,并作出了针对性的调整。
将pre-norm的子层计算定义为 , 为对应的子层运算,比如自注意力子层,前馈神经网络子层,或者编码解码注意力子层。随机残差连接的方式则是应用一个掩码M在子层的运算 上,如下:

掩码M为1或0,产生于类似于dropout的伯努利分布,当M=1时子层运算被激活,而当M=0时则跳过子层的运算。随机的残差连接是模型在训练阶段创造出更多的子网络结构,而在推理阶段,则使用整个网络,产生了类似模型集成的效果。
针对跳过每个层的概率p,作者认为,越底层p的概率应该越小,所以作者设置p的策略为:1)同一层内的子层共享相同的mask;2)浅层具有更低的概率:,其中p是一个全局变量,用于控制模型随机残差的力度。
此外对于每个子层的输出,作者对其进行了类似于drop的放缩操作,放缩系数 。
3、Deep Transformer在机器翻译中的应用(2)
论文标题:Improving Deep Transformer with Depth-Scaled Initialization and Merged Attention
在这篇文章中,作者同样认为对于自然语言处理任务发展中的总体趋势所示通过更深层的神经网络来提高模型的容量和性能。同时随着transformer模型层数的加深,也使得模型难以收敛,训练成本增加,甚至出现梯度爆炸或者梯度消失的问题。作者通过分析说明了由于禅茶连接和层正则化操作之间的相互作用导致了深层网络中出现的梯度消失或爆炸问题,不同于前面调整层正则化的位置解决该问题,作者从参数初始化的角度,提出了根据深度缩放进行初始化(DS-Init),在初始化阶段减少参数之间的方差,同时减少了残差连接输出的方差,有效缓解了梯度消失或爆炸的问题。
同时作者为了节约计算成本提出了一种基于自注意力和编码解码自注意力的注意力子层融合方法(MAtt)。
DS-Init
传统的Transformer模型中所有的参数,通过从一个标准正太分布中进行随机采样,公式如下:

其中 , 代表输入和输出的维度。这种初始化具有维持激活方差和反向传播方差的优点,因此能够帮助训练深层神经网络。
针对在增加Transformer的层数会导致梯度消失或爆炸的问题,作者经过分析认为这是残差连接(RC)和层正则化(LN)之间的相互作用导致的。针对输入向量 常规的计算是:
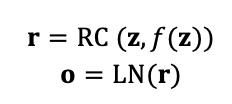
是 是中间的运算结果, 是神经网络的操作,作者假设在反向传播过程中LN的输出的误差信号为 ,RC和LN对误差信号的贡献如下:
,
作者定义误差信号的变化为 。 , , 分别代表模型,LN,和RC操作的一个比率,这个值越大,越容易发生梯度爆炸或者梯度消失的问题,一个神经网络应该为之层之间的梯度范数 ,才能够稳定训练一个深层网络。作者通过实验计算发现LN操作能够削弱误差信号,RC则会增强,而削弱的强度小于增强的强度,则会导致 ,残差连接的输出的方差变大,增加梯度爆炸或者梯度消失的风险,从而提出DS-Init,原始初始化方法进行如下修改:
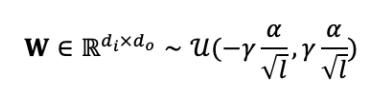
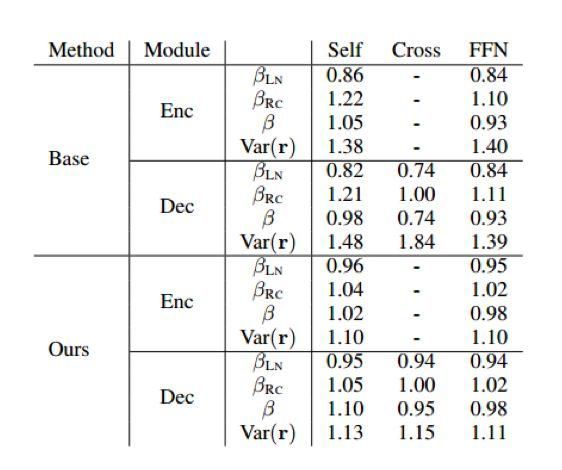
是一个介于0,1之间的超参数, 代表的是第 层,这样做可以使较高的层拥有更小的RRC输出方差,可以使更多的梯度回流。具体的结果如下表
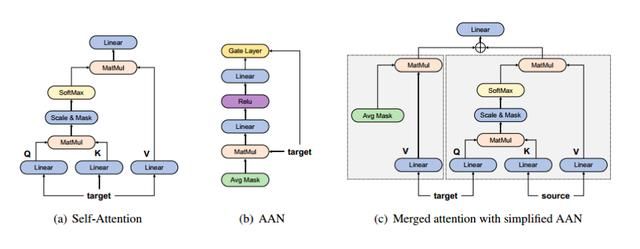
Merged Attention Model
该方法是AAN(Average Attention Network)一种简化,去除了出了线性变换之外所有的矩阵运算:
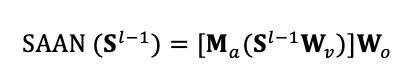
是 是AAN中的mask矩阵,我们通过如下方式将其与编码解码注意力机制结合:

在SAAN和ATT中共享, 是编码端的输出,ATT 则是编码解码注意力机制,通过这种方式,MAtt允许AAN和编码解码注意力并行,如下图:
4、Deep Transformer在语言模型中的应用
论文标题:Character-Level Language Modeling with Deeper Self-Attention
使用截断的反向传播方法训练的基于LSTM和RNN的各种变体的语言模型已经表现了强大的性能,这主要归功于其对于长期上下文的强大的记忆能力,但是在这篇文章中,作者使用了一个深度达到了64层的基于transformer的字符级语言模型,再次展现了深层模型强大的性能。
作者认为对于字符级这种长序列的语言建模,transformer模型由于能够在任意长度距离上快速的传递信息,而循环的结构则需要一步一步的传递,因此能够取得更好的效果。此外作者为了加快模型收敛,使能够稳定训练一个深层的模型,额外增加了三个辅助的损失函数辅助训练。
深层的Transformer语言模型采用与编码层相同单端的结构,此外额外应用了attention mask机制,限制信息只能从左到右流入,如下图。

Auxiliary Losses
作者发现在训练一个超过十层的Transformer网络时,容易产生收敛速度慢,精度变低的问题,通过增加辅助的损失,可以更好的优化网络,显著加快模型训练和收敛的速度。作者设计了三种类型的辅助损失,分别应用于中间位置,中间层和不相邻层,辅助了训练的同时提升了模型的性能。
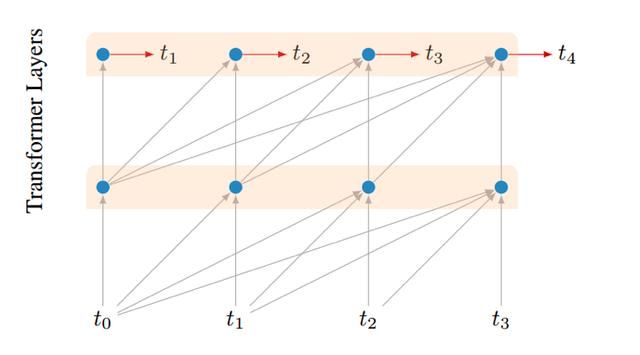
Multiple Positions loss
相比于只预测最后一个位置出现的词,额外增加了在最后一层,每个位置的预测任务,扩展了预测目标为L(序列长度),由于在transformer模型语言模型中在batch之间没有信息传递,这种方式强制在一个小的上下文内进行预测,虽然不确定是否在整个上下文的预测上有帮助,但是这种辅助损失加快了训练,并且取得了更好的效果,下图展示了这种损失的添加方式:
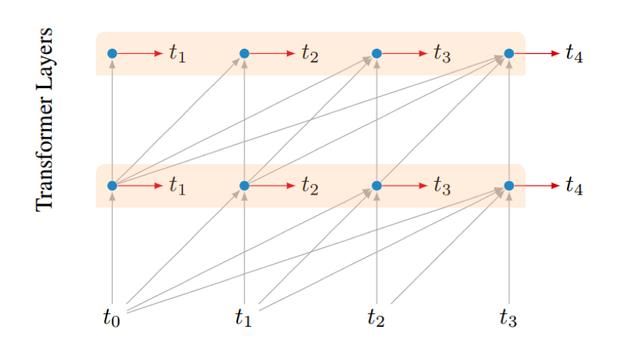
Intermediate Layer Losses
除了在最终层进行预测之外,作者还在模型的中间层增加了预测目标。与最后一层一样,在序列中添加了所有中间位置的预测(如下图)。如果总共有n层,那么第l层在完成l/2n的训练阶段后将停止预测,不在计算额外的辅助损失。即在完成一半的训练后,模型不在产生中间层损失。
Multiple Targets
在序列的每个位置,模型对未来的字符进行两次(或多次)预测。对于每个新目标,引入一个单独的分类器。额外目标的损失在加入相应的层损失之前,用0.5的乘数来加权。

在辅助损失的帮助下,成功训练了一个深度达到64层的基于transformer结构的语言模型,并且性能远远优于基于RNN的结构,并在两个text8和enwik8任务上达到了当时的最佳性能。
5、总结
本文列举了当前具有代表性的四篇基于transformer结构的深层网络工作,可以看到在transformer结构上单纯的通过堆叠网络结构会产生梯度消失/爆炸等造成训练不稳定的问题。
但是通过多种方式的调整,例如,调整层正则化的位置,改变初始化方式或是重新设计损失函数等方式,都能有效提高深层网络训练的稳定性。同时我们也可以观测到,随着网络层数的加深,给模型的容量和性能的提升也是巨大的。
相比于传统的同样采用增加模型容量来提升模型性能的transformer-big模型,增加模型的深度,带来的性能提升更大,同时具有对设备要求低,模型收敛快速的优点。
目前来说,深层网络在NLP任务上的发展还处于初期,相信未来在NLP领域会有更多关于深层网络的工作。
作者介绍:
王子扬,东北大学自然语言处理实验室研究生,研究方向为机器翻译。
小牛翻译,核心成员来自东北大学自然语言处理实验室,由姚天顺教授创建于1980年,现由朱靖波教授、肖桐博士领导,长期从事计算语言学的相关研究工作,主要包括机器翻译、语言分析、文本挖掘等。团队研发的支持187种语言互译的小牛翻译系统已经得到广泛应用,并研发了小牛翻译云(https://niutrans.vip)让机器翻译技术赋能全球企业。