《Attentive Generative Adversarial Network for Raindrop Removal from A Single Image》论文阅读
一、文章总结
这篇论文主要介绍了作者所在的研究团队所设计出的一个新的、利用单张图片去除图片中雨滴的算法。
作者认为实现这一问题的困难主要在两个方面:1、雨滴所在区域并没有被提前圈出;2、雨滴覆盖部分的图片信息大部分缺失。针对以上这两个问题,作者认为去除图片中的雨滴需要分三步。第一步是识别图片中的雨滴区域;第二步是利用雨滴区域附近的没有雨滴的区域对雨滴覆盖区域进行复原,以还原原本的图像;第三步则是对还原图像进行识别,判别还原结果,以确保复原后的图片不会有较大的人工修改痕迹。
作者使用了两种不同的神经网络来实现这三步,作者使用了Generative Network来识别图像中的雨滴,并对其进行复原。通过使用Discriminative Network来对复原后的图片进行识别,以提高复原质量。
作者同时提出,其方法最主要的突破就在于通过Generative Network生成“visual attention”,并将其使用在之后的所有步骤中。这一做法不仅提高了识别的精确程度,同时也缩小了需要还原的区域,并在一定程度上给出了还原图像所需背景信息的获取区域。在最后的检验过程中,作者也使用了“visual attention”,这一做法起到了缩小识别区域的作用,与提前人为划定雨滴范围有着相同的作用。
二、文章解读
A、解决问题
雨点滴落在镜头或是玻璃上会对拍摄出的图像有遮挡作用,这一作用使得通过镜头上有水珠的相机拍摄出的图像上会出现一个个的雨点,破坏了图片中应有信息的完整程度。
与其他的数字图像处理技术不同,去除雨点主要难在雨点模型的组成。雨点模型如下式所示:
![]()
式中I表示输入的图像,也就是表面有雨滴的图像;M表示该区域上存在雨点的可能性,M=1表示该区域必定存在雨点,M=0表示该区域一定不存在雨点,M的值在0-1上连续分布,值越大越有可能属于雨点遮盖区域。B表示镜头没有雨滴时拍出的图像,可以称之为真实图像。R表示由于雨点所带来的对于该部分原图像的干扰。
与雾气、污垢、粉尘等因素不同,雨滴对于图像的干扰并不单单体现在遮挡了原本图像中的信息。由于雨滴是透明且具有一定形状的,所以他对于原图像的干扰表现在使得这部分的图像摄入镜头的光发生了大角度的折射,同时也将一部分原本不该出现在这部分的物体的光折射入相机。
考虑到这一点后,之前人所做的例如去雾、去污、去雨线等算法在去雨滴领域都不能直接被使用,所以作者可以说是在一个新的领域进行了创新。
B、前人做法
事实上,关于解决由于恶劣天气造成的图像信息缺失方面的论文并不是很多,比较有名的仅有去雾和去雨线,很遗憾的是,这两种方法由于所研究对象的数学模型不同,并不能直接使用它们来实现去雨滴的操作。
在去雨滴的相关领域已经有一些科研团队做了一些研究。
Kurihata的研究团队致力于通过PCA让计算机学习雨滴的形状,从而识别图像中的雨滴区域。Kurihata的研究在一定程度上与作者的做法有一定的关系,但不同的是,Kurihata使用的是PCA算法。主成分分析法对于处理统一量化下的复杂信息时有很大的作用,但在处理雨滴识别方面,由于落在镜片上的雨滴数量是不确定的,且雨滴是透明的,其形状、大小更是千变万化,所以使用这一算法进行雨滴的识别是有一定的局限性的。
Yamashita的研究团队则是使用了“Stereo system”来实现识别并去除图像中的雨点,他的算法原理是通过使用多张图片,将多张图片中的信息进行整合,从而拼接出一幅没有雨滴的图像。You的研究团队更是实现了视频中的雨滴消除。但这两个研究团队的研究成果都是基于通过其他图片中的信息来补全雨滴部分的信息实现的去雨滴操作,所以并不能给作者太大的启发。Roser和Geiger的研究团队则是通过给定一个先验来实现对于雨滴的识别。Roser和Geiger认为,水滴一般都是圆形或是椭圆形的,所以他们的做法相当于是用了一个雨滴的形状模型对图片中信息不连续的区域进行范围的形状匹配。这在一些比较理想的状态下能实现对于雨滴的正确识别,但单个雨滴的形状可能只有圆形或椭圆形,当较多的雨滴落在镜头上时,有可能会出现较大范围的雨滴现象,但由于这一范围的形状大多是一个不规则的图形,所以这一做法的局限性仍然很大。
在单张图片的去雨滴方面对于作者来说价值比较大的是Eigen的研究成果,这也是作者的灵感来源。Eigen的做法是使用成对的有雨点覆盖和没雨点覆盖的图片生成一个3层的CNN网络,之后使用这个网络对有雨点覆盖的图像进行雨点识别和图像复原。很遗憾的是,由于网络层数较少以及对图像信息缺失部分的范围缺乏足够的限制,从而导致了其识别、修补具有又多又密的雨点部分图片的能力并不如人意。
C、作者的做法
基于以上的研究团队的研究成果,作者提出了自己的具体做法。
Eigen的研究做法对于作者有着较大的启发,所以作者选择构建神经网络的方式来实现对于雨滴的识别与消除。
作者使用GAN作为自己方法的主题架构,GAN中文名为生成式对抗网络,是一种深度学习模型。模型通过框架中至少两个模块(生成模块与识别模块)的相互博弈学习产生相当好的输出。
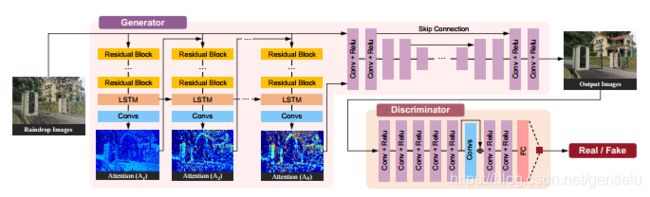
作者的生成模块和识别模块都使用神经网络组成,并负责整个流程中不同的部分,图1是作者模型中的神经网络模型。
C(1) Generative Network
作者的生成模块由两个副网络组成,分别是attentive-recurrent network和contextualautoencoder。
attentive-recurrentnetwork的作用在于寻找原始输入图片中可能存在雨滴的部分,并将这些部分构造成attention map,从而为contextual autoencoder指定雨滴部分及雨滴附近的需要注意的区域。这个网络可以说是作者整个方法的核心部分,正是“attention map”的引入使得后续的操作变得精准而简单,为图像的复原提供了较好的前提条件。
attentionmap的实质是一个大小与原图相等的二维数组,数组中的每一个元素的值是0-1内的一个值。元素的值越大,在后续的操作中,网络会给其及其附近的区域进行优先度更高的操作。
通过观察attention map,我发现attention map的数值在雨滴内部也有不同的分布,总的概括就是雨滴的边缘数值最大,雨滴的正中心数值想对来说最小。我认为这是由雨滴自身的形状决定的,雨滴边缘部分的光线折射角度最大,而中心部分可近似地看作一个平面,所以水滴的边缘部分图像的损失最严重,而中心部分的图像缺损相比来说会小一些。
Attractive-recurrent Network
attractive-recurrentnetwork的组成可以由先前的图片中得出,每一层由若干个Residual Block,一个LSTM和一个Convs组成。需要说明的是,图中的每一个“Block”由5层ResNet组成,其作用是得到输入图片的精确特征与前一个Block的模。
LSTM的公式如下:

式中 表示通过ResNet得到的图片特征, 表示用于下一次LSTM的cell,用编程的思想,一个cell相当于一个类,这个类中有三个“门”, 表示输入门, 表示遗忘门,遗忘门的作用是筛选掉上一次操作中遗漏的没有剔除的信息。 表示输出门,符合算法认证的信息将从这里输出。 则表示LSTM的最终输出。
attention map并不是一次生成的,其生成过程是一个不断叠加,不断优化的过程。作者让神经网络对分别有雨点和没有雨点的图片进行学习,并找出两幅图中信息不相等的部分,并对其进行一定的运算,以找到图片中的所有雨滴,公式如下:
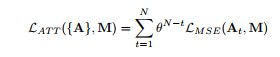
式中 表示最终的该点处最终计算所得的两幅图片在某点处的不匹配程度; 中, 是给定的常量,N指额定步数,t表示当前的步数。 表示在这一步中两幅图片的不匹配程度。
由该公式可以看出,随着步数的不断增加,原本图片中差距较小的部分的值会不断变大,这就是作者系统中对图像中雨点部分进行识别的不断精细化的过程。
Contextual Autoencoder

图 2 Contextual Autoencoder组成
该部分的组成由图2可以看出,该部分的作用在于根据Attractive-recurrentNetwork得出的attention map对于雨点图像进行还原。很讨巧的是,由于attention map的给出,这一部分的工作类似于将attention map中attention值较高的部分通过该部分周围的图片信息形成的新的色块进行替换,从而实现图片信息的还原。
如图片中所示,直接得到的复原图像G(I)并不是十分清晰,其中有一些复原点还很模糊。这是因为在复原过程中除了复原点周围过少造成的无法复原外,还有一部分是由于在卷积过程中的大小变换造成的,作者使用了下述公式来描述复原过程中由于图像大小变换造成的信息缺损:

式中 表示某点处信息的总缺损量; 表示decoder的第i层输出; 表示与encoder的第i层输出同样大规模的原图像信息; 类似于求差操作; 则是该大小规模下信息损失的权重,并且大小规模越大,该值就越大。从该公式不难看出,随着对图片的不断解压缩,造成的信息损失就越大。
作者选取倒数第1、3、5层的输出的误差进行累加,作为由于解压过程中图像规模变化造成的图像信息损失的量。
另一部分就是由于信息的不完全造成的图像复原失败。作者使用了下述公式来量化这一误差:
![]()
式中VGG(O)和VGG(T)分别表示对输出图像G(I)和无雨滴图像T的图像大小进行厘定后进行比较得到的误差。并将该部分误差作为由于图像信息不全造成的复原信息缺失。
最后对generative network的误差量进行累加,从而得到总的误差量:
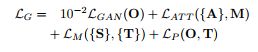
其中
![]()
。
C(2) Discriminative Network
GAN中Generative network的作用类似于学生根据题目进行解答,Discriminative network的作用则类似于老师。
由先前对于Generative network的介绍可以看出,最终输出的复原图像有 的误差。为了鉴别这部分的误差是否能被看出,从而引入了Discriminative network。其工作原理是将Generative Network生成的复原图像和原图像作为输入,让Discriminative network对其进行鉴别,判断其是否是同一个图像,若是同一图像,则该图像的复原是成功的,若不是,则不成功,需要继续复原。
作者在这里有一次引入了“attention map”来简化操作。由于Generative Network的操作区域只有“attention map”所标注的区域。所以只对这些区域的误差进行判别,既减少了计算量,也在一定程度上提高了识别精度。
三、总结
作者在最后对各种处理方式的图片质量进行了比较。通过比较可以看出,作者的做法大大提高了复原的质量。
作者的做法作为在单图像去雨点方面的最新做法,可以说是十分出色,尤其是其将attention map贯穿整个识别过程的做法更是十分新颖。