19.上下采样与BatchNorm
目录
- 池化层与采样
-
- downsample下采样
- upsample上采样
- BatchNorm
-
- feature scaling
-
- Image normalization
- Batch Normalization
-
- 规范化写法
- nn.BatchNorm2d
- test与train使用区别
- 优点
卷积神经网络过程中的一个单元:
conv2D->batchnorm->pooling->Relu
后面三个顺序取决于主流和心得,颠倒也没有很大影响。
池化层与采样
下采样意味对map缩小,上采样和放大方法很类似
downsample下采样
pooling和subsampl结果类似但是操作不一样
max pooling
是对kernel范围内的数值,选择一个最大的数。
avg pooling
是对kernel范围内的数值,进行平均值计算并且输出。
x=torch.rand(1,16,14,14)
layer=nn.MaxPool2d(2,stride=2)
out=layer(x)
print('out shape:',out.shape)
2的意思是尺寸2×2,步长是2,结果减半。

upsample上采样
针对tensor的。简单复制最近的数值,起到放大的作用。
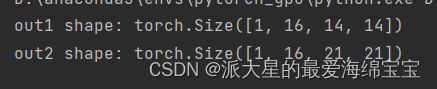
x=torch.rand(1,16,7,7)
out1=F.interpolate(x,scale_factor=2,mode='nearest')
print('out1 shape:',out1.shape)
out2=F.interpolate(x,scale_factor=3,mode='nearest')
print('out2 shape:',out2.shape)
BatchNorm
我们通常使用relu函数而不是sigmod,是因为sigmod函数在一定范围之外,梯度信息为0,但不得不使用sigmo时,我们需要把我们的输入值x,规范到这个一定范围内。最好x在0附近。
多个输入时,x1和x2的范围相差较大时,权重w1w2的不同变化,对loss的影响比较大。
- 1.在conv和relu之间使用,且卷积层不要使用bias;
- 2.训练时将training参数设置为True,验证时为False。通过model.train()和,model.eval()控制;
- 3.batch size尽可能大点,越大求的均值和方差越接近整个训练集的;
feature scaling
Image normalization
图片三个通道RGB都有均值方差
normalize=transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
(Xr-0.485)/0.229,(Xg-0.456)/0.224,(X\b-0.406)/0.225,得到的新分布比较符合我们讲的N(0,1),且输入到下一层con2d时,能很好的求解。
Batch Normalization

假设[16,3,784]
我们的channel是3,则对于channel0这个通道的所有16张数量的图片的所有feature,进行计算,得出均值和方差。最后共有维度为1,shape为3的数,代表着3个channel。
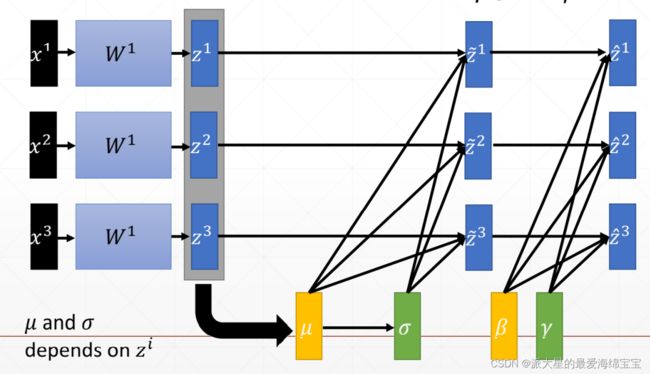
μ和σ是根据当前batch的数据统计出来的,在正向传播过程中统计得到的。对于全局的均值和方差存储在running_mean,running_var中。
β和γ我们学习出来的,在反向传播中训练得到的,会自动跟新,即使刚开始有初始值,且需要梯度信息的。
分别服从N(μ,σ),N(β,γ)
x=torch.rand(100,16,784)
layer=nn.BatchNorm1d(16)
out=layer(x)
print('running_mean:',layer.running_mean)
print('running_val:',layer.running_var)

规范化写法

nn.BatchNorm2d
x=torch.rand(1,16,7,7)
layer=nn.BatchNorm2d(16)
out=layer(x)
print('out shape:',out.shape)
print(vars(layer))
running_mean,running_var是全局的均值和方差,我们目前无法从参数中得知每个batch的均值和方差。
layer.weight和layer.bias参数是γ和β
‘affine:True’:β和γ是否要自动学习,且自动更新。

test与train使用区别
test时的μ和σ是全局的,可从running_mean,running_var复制数值。test没有backward,所以γ和β是不需要更新的。
layer.eval()
BatchNorm1d(16,eps=1e-05,momentum=0.1,affine=True,track_running_stats=True)
out=layer(x)
我们需要调用eval(),提前调到test模式
优点
收敛的更快
更好的性能
更加稳定