目标跟踪问题中的孪生网络学习(一)
VOT问题的学习
考虑实际应用,今后采取Markdown与课题学习同步进行的节奏更新博客
这两天热度正盛,多写一点QAQ
孪生网络
在目标跟踪领域中,孪生网络异军突起,在各大会议刊物上都极为亮眼,研究热度也越来越火,刚好和最近的比赛相关,就顺手拿起一篇文章读一下,希望了解其中的思想.
阅读三要点
拿到一篇文章,按照 abstract > keyword > conclusion > introduction 的顺序,看看对它的兴趣程度,决定读或者走人,这里,Fully-Convolutional Siamese Networks for Object Tracking 一文,刚刚好适合小灰我读,just do it!
摘要
对形变物体的跟踪,以往通过在线更新的方式学习目标的形状模型得到了较好的解决。但在线学习的方式限制了模型丰富度的扩展,之前的深度学习在一定程度上能够解决这一问题,除了未知的待跟踪目标无先验知识这一情况,需要在线更新网络权重。文章提出基于全卷积孪生网络的跟踪算法,这是一种端到端的学习网络,在ILSVRC15数据集上训练得到。跟踪器实现了实时帧率处理,并取得了当时最优的跟踪性能。
思考: 针对模型学习简单和在线更新的问题,提出了孪生网络,这里面,在线更新是会使得学习耗时增多吗,类比现成函数和迭代函数,数据输入与函数生成同步进行?
关键词
目标跟踪;孪生网络;相似度学习;深度学习
PS: 综述撰写的时候,导师反复强调,关键词要有新意,最好不要和其他人的重复,当然,也不尽要些花里胡哨的东西
结论
摒弃传统在线学习跟踪方法,采取李现阶段学习强embedding,相较于分类问题,文章证明了孪生全卷积深度网络能够更有效地利用数据学习。执行有效空间搜索,测试时间更短;每一个子窗口以更少的花销高效表征有用的采样,训练时间更短。实验表明,深度嵌入为在线跟踪器提供了自然丰富的特征来源,并使简单的测试时间策略能很好执行,这是对复杂在线跟踪方法的补充。
吐槽: 自己的翻译老感觉怪怪的,但总体意思get到了,这就是我要看的文章
介绍
考虑视频中任意形状物体的跟踪问题,目标在首帧中由一个矩形框标定。现有的一些算法包括在线学习视频帧中的目标形状模型,例如TLD,Struck,KCF等,完全通过当前视频获取数据进行学习,只能获取简单模型。而基于大监督数据库的深度卷积网络,由于数据的缺失和实时操作的限制,无法适用在这种在每段视频中学习每一个检测器的场景。
迁移学习是这种问题的一种解决方式,通过不同类型但有所相关的任务学习到的深度网络,迁移到当前任务当中,具有一定可行性。这些方法采用浅层方法(shallow method)以及利用SGD微调网络中的多层进行迁移,或是无法满足端到端学习的优势,或是无法满足实时性要求。
文章提出一种初始离线阶段利用深度卷积网络训练学习问题,跟踪在线评估训练效果。文章关键指明了一种在当前跟踪任务下满足实时帧率要求的强有力方法。具体地,训练一个孪生网络在大的搜索图像中定位范例模板,这种孪生网络对搜索图像是完全卷积的,通过双线性层计算两个输入的互相关,从而实现密集而高效的滑动窗口评估。
跟踪问题中的相似度学习,由于标记数据集的缺少而往往为人们忽略,文章采用目标检测数据库ILSVRC进行训练,用ImageNet Video和ALOV/OTB/VOT测试性能。
用于跟踪的深度相似性学习
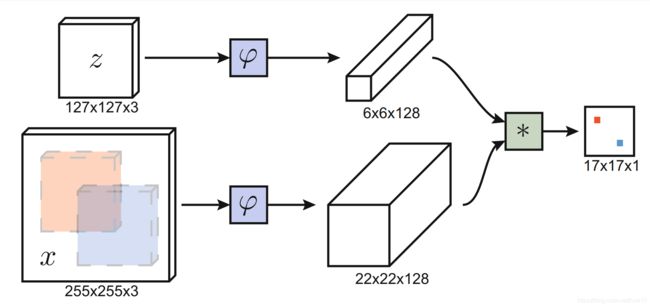
z为范例图像,x为从某帧中获取的与z相同大小的候选图像,学习一个度量范例z与候选x间相似度的函数f(z,x),当两张图像描述同一目标时,获取高的score,否则取得低的score。为寻找大尺度图像中得分最高的候选x,需要滑动遍寻整幅图像,计算得分然后比较,获取真实目标定位。
此网络架构对搜索图像x是全卷积的,输出为标量得分映射,维度由搜索图像尺度决定。这样对整幅图像进行搜索,能在一次评估内计算所有滑动窗的相似度函数得分。在以上图片描述中,最后输出的score map包含了相应子窗口对范例图像的相似度数值(红点和蓝点,实际为 17x17 个值,对应 17x17 个子窗口)。
孪生网络利用 φ \varphi φ 将两个输入映射至特征空间,即 φ \varphi φ 相当于embedding;之后通过函数 g 连结两个特征。总体为:
f ( z , x ) = g ( φ ( z ) , φ ( x ) ) f(z,x) = g(\varphi(z),\varphi(x)) f(z,x)=g(φ(z),φ(x)) 跟踪过程中,使用的是前一帧中以目标为中心的搜索图像。最高得分相较于得分映射中心的位置乘上网络的步长,可以得到目标在帧间的位移。通过组合小批量缩放图像,可以在一个前向传递中搜索多个尺度。
在较大的搜索图像上,利用互相关组合特征映射并对网络进行一次评价,在数学上等价于利用内积组合特征映射并在每个平移的子窗口上独立地对网络进行评价。
损失函数
采取的是对数损失函数: ι ( y , v ) = l o g ( 1 + e x p ( − y v ) ) \iota(y,v)=log(1+exp(-yv)) ι(y,v)=log(1+exp(−yv)),这里, v v v 是单个范例-候选对的真实得分, y ∈ { + 1 , − 1 } y\in\lbrace +1,-1 \rbrace y∈{+1,−1}也即候选框的实际 label 。在训练过程中,利用网络的全卷积特性,使用包含了范例图像与较大搜索图像对,产生得分映射,为每一对都有效生成出许多示例。将得分映射的损失定义为单个损失的平均值:
L ( y , v ) = 1 ∣ D ∣ ∑ u ∈ D ι ( y [ u ] , v [ u ] ) , L(y,v) =\frac{1}{|D|}\sum_{u\in D} \iota(y[u],v[u])\qquad, L(y,v)=∣D∣1u∈D∑ι(y[u],v[u]), 得分映射中每一个 u ∈ D u\in D u∈D,都需要有真实 label y [ u ] ∈ { + 1 , − 1 } y[u] \in\lbrace +1,-1 \rbrace y[u]∈{+1,−1}.
网络参数 θ \theta θ 由以下问题求解得到: a r g min θ E ( z , x , y ) L ( y , f ( z , x ; θ ) ) , arg \min_{\theta}E_{(z,x,y) }L(y,f(z,x;\theta)), argθminE(z,x,y)L(y,f(z,x;θ)),
心得
码公式好麻烦,溜了溜了,23:17~