(一)模型量化与RKNN模型部署
文章目录
-
- 1.计算平台运算能力评估
- 2.模型量化原因
- 3.模型量化方式
-
- 3.1 基本原理
-
- 3.1.1 int8
- 3.1.2.uint8
- 3.2 量化分类
- 4.模型量化方法
-
- 4.1 Per-Layer/Per-Tensor
- 4.2 Per-Channel
- 5. Rockchip NPU相关
-
- 5.1数据排列方式
- 5.2 `rknn_output`设置`want_float`
- 5.3开发板上组件版本查询方法
- 参考资料
欢迎访问个人网络日志知行空间
1.计算平台运算能力评估
-
深度学习模型部署运算量的衡量使用的是乘累加运算次数
MAC, Multiply Accumulate,形如:
a ← a + b + c a\leftarrow a+b +c a←a+b+c -
硬件的运算速度使用的单位是
GOPS/TOPS/POPS/EOPS分别表示Giga/Tera/Peta/Exa Operations Per Second,对应的是 1 0 9 / 1 0 12 / 1 0 15 / 1 0 18 10^9/10^{12}/10^{15}/10^{18} 109/1012/1015/1018次运算,中文表示分别是十亿/万亿/京/艾。1TOPS相当于处理器有512个MAC单元,运行频率为1GHZ。
2.模型量化原因
机器学习模型训练时,通常使用如float32的浮点数进行计算,这样能够保持好的精度,但浮点数在提升计算精度的同时,也导致了更多的运算量和存储空间占用。在模型推理时,并不需要进行梯度的反向传播,因此不需要那么高的计算精度,这时可将模型映射到较低精度的运算上,降低运算量,提升运算速度。这样将模型从高精度运算转换到低精度运算的过程叫作模型量化。
3.模型量化方式
3.1 基本原理
参考自https://aistudio.baidu.com/aistudio/projectdetail/3875525
模型量化的关键是找到数据映射的关系,以浮点到定点数据的的转换公式为例:
Q = R S + Z R = ( Q − Z ) ∗ S Q = \frac{R}{S}+Z \\ R = (Q-Z)*S Q=SR+ZR=(Q−Z)∗S
R表示输入的浮点数据Q表示量化之后的定点数据Z表示零点(zero point)的数值S表示缩放因子
可以根据S和Z这两个参数来确定这个映射关系,一种MinMax求解方式如下:
S = R m a x − R m i n Q m a x − Q m i n Z = Q m a x − R m a x ÷ S S=\frac{R_{max} - R_{min}}{Q_{max} - Q_{min}} \\ Z = Q_{max} - R_{max} \div S S=Qmax−QminRmax−RminZ=Qmax−Rmax÷S
- R m a x R_{max} Rmax表示输入中浮点数据的最大值
- R m i n R_{min} Rmin表示输入中浮点数据的最小值
- Q m a x Q_{max} Qmax表示最大的定点数,如
int8 127 - Q m i n Q_{min} Qmin表示最小的定点数,如
int8 -128
3.1.1 int8
- 范围
[-128, 127]
o u t p u t = i n p u t s c a l e + z e r o _ p o i n t _ u 8 output = \frac{input}{scale} + zero\_point\_u8 output=scaleinput+zero_point_u8 - 非对称量化

3.1.2.uint8
-
范围
[0, 255
o u t p u t = i n p u t s c a l e + z e r o _ p o i n t _ i 8 output = \frac{input}{scale} + zero\_point\_i8 output=scaleinput+zero_point_i8 -
方便支持对称量化

3.2 量化分类
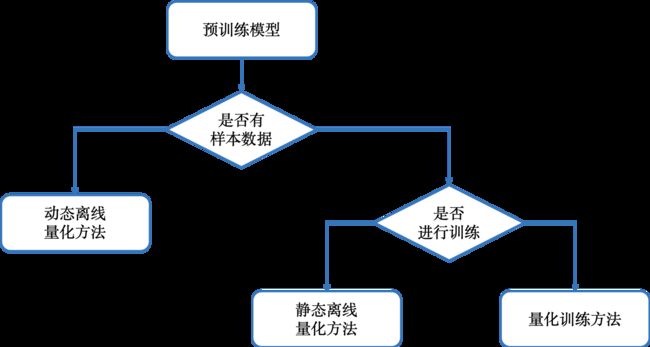
根据是否进行训练可将量化分为训练时量化和训练后量化
- 训练时量化,感知量化训练:量化训练让模型感知量化运算对模型精度带来的影响,使用大量有标签的数据,通过 finetune 训练降低量化误差。
- 训练后量化
- 静态量化:使用少量无标签校准数据,采用KL散度等方法计算量化比例因子
- 动态量化:无需额外数据,仅将模型中特定算子的权重从浮点类型映射成整数类型

4.模型量化方法
4.1 Per-Layer/Per-Tensor
- 特征图(feature)量化
- 权重(weights)量化
- 特征图或权重共享相同的量化参数(scale/zero_point)
4.2 Per-Channel
- 权重的每个卷积核具备不同量化系数(scale/zero_point)
- 提高量化精度
5. Rockchip NPU相关
5.1数据排列方式
- NCHW,(batch, channel, height, width), width方向连续,
- NHWC,(batch, channel, width, height), channel方向连续

5.2 rknn_output设置want_float
若want_float设置成1,rknn_outputs_get方法返回的data是float类型,若设置成0,返回的结果的是uint8类型的。根据非对称量化的量化和反量化公式可以根据使用情况确定want_float的值。
-
非对称量化
asymmetric_quantized-u8量化公式:q u a n t _ r e s = r o u n d ( f l o a t _ n u m s c a l e ) + z e r o _ p o i n t quant\_res = round(\frac{float\_num}{scale}) + zero\_point quant_res=round(scalefloat_num)+zero_point
static uint8_t qnt_f32_to_unit8(float f32, uint8_t zp, float scale) { float dst_val = (f32 / scale) + zp; uint8_t res = (uint8_t)__clip(dst_val, 0, 255); return res; } -
非对称量化
asymmetric_quantized-u8反量化公式:f l o a t _ n u m = s c a l e ∗ ( q u a n t − z e r o _ p o i n t ) float\_num = scale*(quant-zero\_point) float_num=scale∗(quant−zero_point)
static float deqnt_uin8_to_f32(uint8_t qnt, uint8_t zp, float scale) { return ((float)qnt - (float)zp) * scale; }
在获取模型输出结果时,可以在模型初始化时获得模型输出层的量化参数zero_point和scale,如下图:

在使用want_float=0时获得的unit8类型数据上进行后处理的一个例子(Yolov5):
static int process_u8(uint8_t *input, int *anchor, int grid_h, int grid_w, int height, int width, int stride,
std::vector<float> &boxes, std::vector<float> &boxScores, std::vector<int> &classId,
float threshold, uint8_t zp, float scale)
{
int validCount = 0;
int grid_len = grid_h * grid_w;
// 将confidence_threshold反量化到uint8类型上
float thres = unsigmoid(threshold);
uint8_t thres_u8 = qnt_f32_to_uint8(thres, zp, scale);
for (int a = 0; a < 3; a++)
{
for (int i = 0; i < grid_h; i++)
{
for (int j = 0; j < grid_w; j++)
{
uint8_t box_confidence = input[(PROP_BOX_SIZE * a + 4) * grid_len + i * grid_w + j];
if (box_confidence >= thres_u8)
{
int offset = (PROP_BOX_SIZE * a) * grid_len + i * grid_w + j;
uint8_t *in_ptr = input + offset;
// rknn模型输出的uint8类型反量化到float类型
float box_x = sigmoid(deqnt_uint8_to_f32(*in_ptr, zp, scale)) * 2.0 - 0.5;
float box_y = sigmoid(deqnt_uint8_to_f32(in_ptr[grid_len], zp, scale)) * 2.0 - 0.5;
float box_w = sigmoid(deqnt_uint8_to_f32(in_ptr[2 * grid_len], zp, scale)) * 2.0;
float box_h = sigmoid(deqnt_uint8_to_f32(in_ptr[3 * grid_len], zp, scale)) * 2.0;
box_x = (box_x + j) * (float)stride;
box_y = (box_y + i) * (float)stride;
box_w = box_w * box_w * (float)anchor[a * 2];
box_h = box_h * box_h * (float)anchor[a * 2 + 1];
box_x -= (box_w / 2.0);
box_y -= (box_h / 2.0);
boxes.push_back(box_x);
boxes.push_back(box_y);
boxes.push_back(box_w);
boxes.push_back(box_h);
uint8_t maxClassProbs = in_ptr[5 * grid_len];
int maxClassId = 0;
for (int k = 1; k < OBJ_CLASS_NUM; ++k)
{
uint8_t prob = in_ptr[(5 + k) * grid_len];
if (prob > maxClassProbs)
{
maxClassId = k;
maxClassProbs = prob;
}
}
float box_conf_f32 = sigmoid(deqnt_uint8_to_f32(box_confidence, zp, scale));
float class_prob_f32 = sigmoid(deqnt_uint8_to_f32(maxClassProbs, zp, scale));
boxScores.push_back(box_conf_f32* class_prob_f32);
classId.push_back(maxClassId);
validCount++;
}
}
}
}
return validCount;
}
5.3开发板上组件版本查询方法
# 查询 rknn-toolkit版本
pip list | grep rknn
# 查询rknn_server版本
strings /vendor/lib64/usr/bin/rknn_server | grep build
# 查询librknnrt.so版本
strings /vendor/lib64/librknnrt.so | grep librknnrt version:
# 查询NPU驱动版本
dmesg | grep rknpu
# 查询RGA API版本
strings /vendor/lib64/librga.so | grep rga_api | grep version
欢迎访问个人网络日志知行空间
参考资料
- 1.https://aistudio.baidu.com/aistudio/projectdetail/3875525
- 2.https://github.com/airockchip/rknn_model_zoo
- 3.Quantizing deep convolutional networks for efficient inference: A whitepaper