python常用代码总结2
1、列表的常规追加元素、追加列表操作
(1)列表追加多个元素,比如追加0-9
ls = []
ls.extend(list(range(10)))
ls
Out[20]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9](2)列表追加多个相同的元素,比如追加10个0
ls1 = []
for i in range(10):
ls1.append(0)
ls1
Out[23]: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]列表推导式
ls2 = []
ls2.extend([0 for _ in range(10)])
ls2
Out[27]: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]In[57]: list4 = [i for _ in range(2) for i in range(1, 4)]
...: print(list4)
...:
[1, 2, 3, 1, 2, 3]
In[58]: list4 = [i for i in range(1, 4) for _ in range(2)]
...: print(list4)
...:
[1, 1, 2, 2, 3, 3](3列表追加一个已有列表
ls3 =[]
expected_list = [1.2,2.3,3.4,5.6]
ls3.extend(expected_list)
ls3
Out[31]: [1.2, 2.3, 3.4, 5.6](4)列表中追加一个二维列表的一行或一列
ls4 = []
expected_list = [[1.2,2.3],[3.4,5.6],[7.0,8.0]] #3行2列
ls4.extend(expected_list[1]) #追加第二行
ls4
Out[44]: [3.4, 5.6](5)列表中可以追加不同长度的列表
lstwo = []
In[49]:
lstwo.append(ls1)
lstwo.append(ls2)
lstwo.append(ls3)
lstwo.append(ls4)
lstwo
Out[54]:
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[],
[3.4, 5.6]]2、numpy array 读写文件
读取混合数据类型的数据,我们可以object的类型追读写文件。读Object对象的时候必须开启allow_pickle =True.(允许使用Python pickles保存、读取对象数组)
x = np.array([[1, 1, 1], ['a', 'b', 'c'],[1,'a',0.654321]], dtype=object)
np.save('my_data',x)
y = np.load('my_data.npy',allow_pickle=True)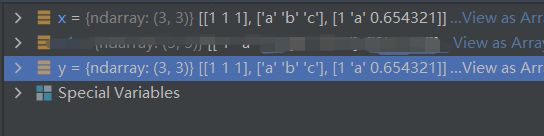
(1)numpy.save()函数
保存一个数组到一个二进制的文件中,保存格式是.npy
参数介绍:
numpy.save(file, arr, allow_pickle=True, fix_imports=True)
file:文件名/文件路径
arr:要存储的数组
allow_pickle:布尔值,允许使用Python pickles保存对象数组(可选参数,默认即可)
fix_imports:为了方便Pyhton2中读取Python3保存的数据(可选参数,默认即可)
(2)numpy.savez
这个同样是保存数组到一个二进制的文件中,但是厉害的是,它可以保存多个数组到同一个文件中,保存格式是.npz,它其实就是多个前面np.save的保存的npy,再通过打包(未压缩)的方式把这些文件归到一个文件上,不行你去解压npz文件就知道了,里面是就是自己保存的多个npy.。
参数介绍:
numpy.savez(file, *args, **kwds)
file:文件名/文件路径
*args:要存储的数组,可以写多个,如果没有给数组指定Key,Numpy将默认从'arr_0','arr_1'的方式命名
kwds:(可选参数,默认即可)
x2= np.arange(10)
x3= np.random.randn(10)
np.savez('my_data',x2,x3)
npzfile=np.load('my_data.npz')
x21=npzfile['arr_0']
x31=npzfile['arr_1']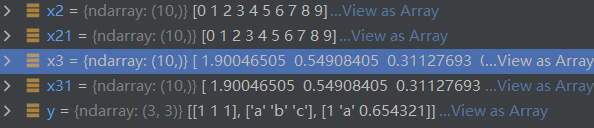
你可以不适用Numpy默认给数组的Key,而是自己给数组命名有意义的Key,这样就可以不用自己指定变量名'arr_0','arr_1'了
x2= np.arange(10)
x3= np.random.randn(10)
np.savez('my_data',x2=x2,x3=x3)
npzfile=np.load('my_data.npz')
x2=npzfile['x2']
x2=npzfile['x3']3、numpy.save()函数直接存储复杂dict,包含列表,字符串,数值,然后再读取。
dict1 ={'name': ['jack1', 'jack2', 'jack3', 'jack4'],
'sex': ['男', '女', '男', '女'],
'grade': [99.1, 99.2, 99.3, 99.4]}
dict1
Out[39]:
{'name': ['jack1', 'jack2', 'jack3', 'jack4'],
'sex': ['男', '女', '男', '女'],
'grade': [99.1, 99.2, 99.3, 99.4]}
np.save('dict.npy', dict1)
load_dict = np.load('dict.npy', allow_pickle=True).item()
load_dict
Out[42]:
{'name': ['jack1', 'jack2', 'jack3', 'jack4'],
'sex': ['男', '女', '男', '女'],
'grade': [99.1, 99.2, 99.3, 99.4]}4、用savez,在一个文件里,写多个变量(dict,list)并进行解析
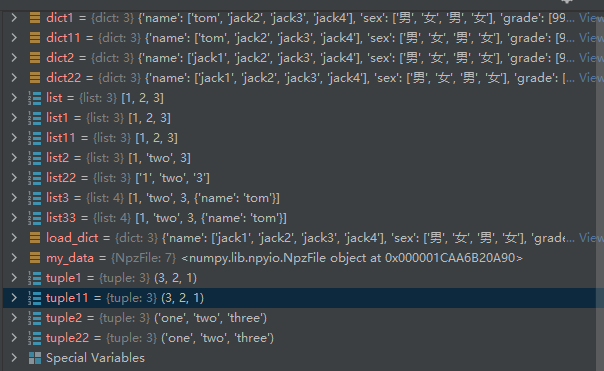
dict2 = {'name': ['jack1', 'jack2', 'jack3', 'jack4'],
'sex': ['男', '女', '男', '女'],
'grade': [99, 99, 99, 99.4]}
dict1 = {'name': ['tom', 'jack2', 'jack3', 'jack4'],
'sex': ['男', '女', '男', '女'],
'grade': [99, 99, 99, 99.4]}
list1 = [1, 2, 3]
list2 = [1, 'two', 3]
list3 = [1, 'two', 3, {'name': 'tom'}]
tuple1 = (3,2,1)
tuple2 = ('one','two','three')
np.savez('my_data', dict1=dict1, dict2=dict2, list1=list1, list2=list2, list3=list3,tuple1 = tuple1, tuple2 = tuple2)
my_data = np.load('my_data.npz', allow_pickle=True)
dict11 = my_data['dict1'].item()# 字典解析
dict22 = my_data['dict2'].item()
list11 = my_data['list1'].tolist() # list解析
list22 = my_data['list2'].tolist()
list33 = my_data['list3'].tolist()
tuple11 = tuple(my_data['tuple1']) # tuple解析
tuple22 = tuple(my_data['tuple2'])结果输出: