MySQL性能调优——索引篇
MySQL为什么会选错索引
使用explain命令可以查看查询语句使用了具体使用了哪个索引,比如
explain select * from t where a between 10000 and 20000;
![]()

查询结果如图所示。
选择索引是优化器的工作
优化器选择索引的目的是想找到一个最优的执行方案,并用最小的代价去执行语句。
在数据库中,扫描行数是影响代价的因素之一,扫描的行数越少,意味着访问磁盘的次数也就越少,消耗的CPU资源越少。
当然了,扫描行数并不是唯一的判断标准,优化器还会结合是否使用临时表、是否排序等因素进行综合判断。
问题 扫描行数是怎么判断的呢?
MySQL 在真正开始执行语句之前,并不能精确地知道满足这个条件的记录有多少条,而只能根据统计信息来估算记录数。
统计信息是什么呢?
统计信息就是索引的“区分度”。显然,一个索引上不同的值越多,这个索引的区分度就越好。而一个索引上不同的值的个数,我们称之为“基数”(cardinality)。也就是说,这个基数越大,索引的区分度越好。
可以使用show index的方法,看索引的基数具体是多少。比如
show index from t;

虽然这个表的每一行的三个字段值都是一样的,但是在统计信息中,这三个索引的基数值并不同,而且其实都不准确。
MySQL索引的基数是怎么算的呢?
采用了采样统计的方法。在采样统计的时候,InnoDB默认会选择N个数据页,统计这些页面上的不同值,然后加起来在除页数得到一个平均值,然后平均值乘数据表总页数就得到了索引的基数。
数据表不断地更新,索引统计信息也不会固定不变。所以,当变更的数据行数超过 1/M 的时候,会自动触发重新做一次索引统计。
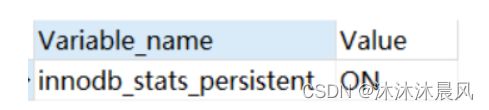
在 MySQL 中,有两种存储索引统计的方式,可以通过设置参数 innodb_stats_persistent 的值来选择:
- 设置为 on 的时候,表示统计信息会持久化存储。这时,默认的 N 是 20,M 是 10。
- 设置为 off 的时候,表示统计信息只存储在内存中。这时,默认的 N 是 8,M 是 16。
可以使用show variables innodb_stats_persistent来查看使用的是on或者是off。
上边图中的三个索引的基数虽然不一样,但是都是大差不差的,所以选错索引肯定还有其他的原因。
优化器还需要看需要扫描的行数(rows),
我认为预计扫描行数是与统计信息(基数)有关,还与索引具体的是否回表等有关。
如果你的explain语句执行出来的rows和心里预估的不吻合,可能是走你想要走的索引要回表,优化器考虑着这个回表的代价,就走主键索引了。
修正这项统计信息的方法:analyze table 表名。
所以在实践中,如果你发现 explain 的结果预估的 rows 值跟实际情况差距比较大,可以采用这个方法来处理。
索引选择异常和处理
- 一种方法是,采用 force index 强行选择一个索引。
- 第二种方法就是,我们可以考虑修改语句,引导 MySQL 使用我们期望的索引。
- 第三种方法是,在有些场景下,我们可以新建一个更合适的索引,来提供给优化器做选择,或删掉误用的索引。
怎么引导MySQL的优化器使用我们想使用的索引呢?
根据经验。