基于文本分类方法的警情数据处理和自助报警的实现
《文本分析与挖掘》
2021/2022(1)
期末综合实验报告
报告题目 文本分析期末大作业
计算机科学与技术学院
基于文本分类方法的警情数据处理问题
- 问题分析
当前公安机关掌握着各种宝贵警情数据资源,但是这些资源没有被进一步利用,普遍的是只对相关数据进行管理、统计和查询。随着时间的推移和数据的积累,如何将警情数据库及相关数据库里面的数据有效利用起来,进提高警队的战斗力,进一步打击违法犯罪活动,就成了当前急需解决的问题。现阶段,公安情报人员在分析文本情报时往往依赖人力手动完成,耗时长、效率低。烽火普天智能情报文本挖掘平台,基于自然语言处理等技术,可对多源、异构、海量的公安情报文本进行文本分析挖掘,与公安内部系统信息整合、综合分析和预警监测,不断提高智能化的情报工作能力,为公安业务提供有效的决策支持、提高公安快速响应与作战能力。
我们基于警情数据对于报案内容的进行分类,做了一个方便报案人员自动报警、及时找到相关部门解决问题、以及给警方人员提供一定的信息服务的系统。 对于报警人员, 主要涉及报警文本的分类。对于警方人员,主要涉及文本统计。
当前的文本分类算法主要有12中,包括8种传统算法:k临近、决策树、多层感知器、朴素贝叶斯(包括伯努利贝叶斯、高斯贝叶斯和多项式贝叶斯)、逻辑回归和支持向量机;4种集成学习算法:随机森林、AdaBoost、lightGBM和xgBoost;2种深度学习算法:前馈神经网络和LSTM。本次大作业我们主要利用TextCNN和fastText分类警情数据,给报案人员提供方便的报案途径。
- 系统构架/功能模块
主要为两个模块,报案人员自助报案和警局处理人员对系统的查询和管理。如下图所示:

自动报案主要是根据报案人员的报案信息,给予处理信息和一些反馈。自动报案需要提取报案内容,进行分类,显示分类结果,从而给予处理信息。
1.基于报警人员的报警信息分类:
分析表格数据,发现只有报警内容信息对文本的分类有效,先对报警信息文本的预处理:
1.数据清洗:
对于提供的警情数据信息:

提取全部文本中出现最多的单词:

图2-关键词
查看全部数据的词云显示:

图3-前2000个词汇的云图
查看‘求助’事件的词云显示:

图4-求助案件词汇的云图
查看‘治安案件’事件的词云显示:

图5-治安案件词汇的云图
查看‘纠纷’事件的词云显示:

图6-纠纷案件词汇的云图
查看‘举报’事件的词云显示:

图7-举报案件词汇的云图
查看‘其它报警’事件的词云显示:

图8-其他报警案件词汇的云图
查看‘刑事案件’事件的词云显示:

图9-刑事案件词汇的云图
从中我们可以看出有许多单词在各类文本中出现的次数很多,
例如【‘人称’,’有人’,’称’,’年’,’月’,’日’】等和【‘重复报警’】:

文档中的报警内容有很多都带有【‘重复报警’】,且【‘重复报警’】后的内容只含有日期和报警电话,对分类无帮助,还会增加训练的时间,所以也需要去除这部分的内容。
对于下列的信息,全部去除:
t1=['*'民警','1','2','3','4','5','6','7','8','9','0',' ','(',')','带领','年','月','日','时','分','辅警','(',')',',','人称','报警','称','有人']重复报警的内容也删除:
if(data[i]=='重' and i+1去除一些无用信息后,对训练集的数据进行分词,结果如下图所示:

图10-选择性删除一些信息
去除文本中的停用词,如【‘有人’】,标点符号,【‘几乎’】,【‘同时’】等信息。
加载停用词表(停用词表来自网络):
stopwords=pd.read_csv("stopwords.txt",index_col=False,sep="\t",quoting=3,names=['stopword'], encoding='utf-8')如下图所示:

图11-停用词表
2.数据增强:
可以看出对于六类报警内容中,举报事件和刑事案件远远少于其他类别,基于这个问题我们可以进行文本增强。
用到的工具是nlpcda,进行安装nlpcda和依赖包后就可以使用:
!pip install nlpcda它的作用主要有:
①在不改变原文语义的情况下,生成指定数量的训练语料文本。
②对NLP模型的泛化性能、对抗攻击、干扰波动,有很好的提升作用。
nlpdata文本增强的主要方法如下:
①随机(等价)实体替换:即缺省时使用内置(公司)实体。对公司实体进行替换。
调用如下(参数解释:create_num=3 :返回最多3个增强文本change_rate=0.3 : 文本改变率seed : 随机种子):
from nlpcda import Randomword
test_str = '类别少的警情数据'
smw = Randomword(create_num=3, change_rate=0.3)
rs1 = smw.replace(test_str)②随机同义词替换:缺省时使用内置同义词表,你可以设定/自己指定更加丰富的同义词表:
调用如下(参数解释:create_num=3 :返回最多3个增强文本;change_rate=0.3 : 文本改变率; seed : 随机种子):
from nlpcda import Similarword
test_str = '类别少的警情数据'
smw = Similarword(create_num=3, change_rate=0.3)
rs1 = smw.replace(test_str)③随机近义字替换:缺省时使用内置【同义同音字表】,你可以设定/自己指定更加丰富的同义同音字表:
调用如下(create_num=3 :返回最多3个增强;change_rate=0.3 : 文本改变率;seed : 随机种子):
from nlpcda import Homophone
test_str = '类别少的警情数据'
smw = Homophone(create_num=3, change_rate=0.3)
rs1 = smw.replace(test_str)因为举报和刑事案件类别的文档内容比较少,所以选择增强这两类的文本内容。
具体方法:
随机选择类别为“举报”和“刑事案件”的报警内容100条,对其进行随机同义词替换,文本改变率设为0.3,分别重新生成100条报警信息,并存储下来和训练集一起训练。
下图为一个文本增强的例子:

图12-例子
下图为替换后的结果:

图13-文本替换
可以看出对应‘举报’类的报警信息,它主要是替换为了‘检举’,‘告发’,‘告密’等内容,对文本分类有一定的帮助。
3.基于报警人员的报警信息分类:主要使用了三种方法,TextCNN,朴素贝叶斯,fasttext。
整个分类的主要流程如下图所示:

图14-总体分类流程图
①基于TextCNN.
文本分类的关键在于准确提炼文档或者句子的中心思想,而提炼中心思想的方法是抽取文档或句子的关键词作为特征,基于这些特征去训练分类器并分类。因为CNN的卷积和池化过程就是一个抽取特征的过程,当我们可以准确抽取关键词的特征时,就能准确的提炼出文档或句子的中心思想。
TextCNN架构图如下所示:

图15-TextCNN架构图
分类流程如下图:
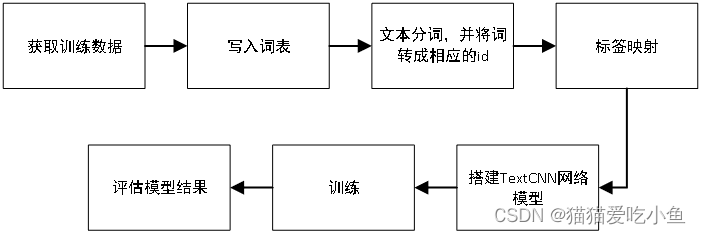
图15-TextCNN分类流程图
将词表写入本地vocab.txt文件
with open('vocab.txt', 'w') as file:
for word in vocab:
file.write(word)
file.write('\n')因为报警内容其实并不是很多,本次分类中把向量的最大维度
设为500:
class Config():
embedding_dim = 50#向量维度
max_seq_len = 100 # 文章最大词数
vocab_file = 'vocab.txt' # 词汇表文件路径这里需要注意:初始化词和id的映射词典,预留0给padding字符,1给词表中未见过的词。
标签映射如下:
elf.class_name = {0: '求助', 1: '治安案件',2:'纠纷',3:'举报',4:'其他报警',5:'刑事案件'}开始训练:
# 初始化模型类,启动训练
textcnn = TextCNN(config)
history=textcnn.fit(X_train,new_y_train, X_val, new_y_val, epochs=20, callbacks=[early_stop, checkpoint_callback]) # 训练训练结果如下:

图16-TextCNN训练结果
对于训练集的准确率已经达到了0.9,对于验证集的准确度0.6多。
测试集的各个准确度如下:

图17-TextCNN分类结果
②基于fasttext.
fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。fastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词。
fasttext的模型架构如下图所示:

图18-fastext网络架构
使用fasttext分类流程如下所示:
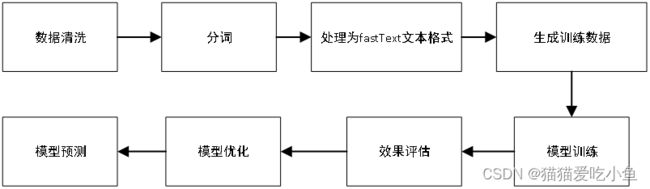
图19-fastext分类流程图
需要进行一些数据清洗、分词、去停用词、整理为fastText要求的文本格式,并生成训练数据。
生成的训练样本格式为:
__label_类别 分词1 分词2 分词3 ......分词n
例如:
__label__2 有人 赖着 不肯 离开
分割训练集和数据集,将训练数据和测试数据都写入文档:
with open('./data/train_data.txt', 'w') as out:
for sentence in train_set:
out.write(sentence+"\n")
print("done!")
with open('./data/test_data.txt','w') as f:
for sentence in test_set:
f.write(sentence+'\n')
print('done!')test_data.txt查看:

图20-fastext 测试数查看
训练模型(参数解释:word_ngrams设置 n-grams ;dim 训练的词向量维度):
classifier = fasttext.train_supervised('./data/train_data.txt',label='__label__', wordNgrams=2,epoch=20,lr=0.1,dim=100)训练集的准确度为:

图21-fastext训练准确度
测试集的准确度为:

图22-fastext测试准确度
准确度达到了0.6398,总的准确度还行,比TextCNN的高一些
③基于朴素贝叶斯的分类:
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的数据集,首先基于特征条件独立假设学习输入输出的联合概率分布;然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y,朴素贝叶斯法实现简单,学习与预测的效率都很高,是一种常用的方法。
训练的流程如下图所示:

图23-朴素贝叶斯分类流程图
先基于词频矩阵做训练:
vec = CountVectorizer(analyzer='word', max_features=50, lowercase = False)
feature = vec.fit_transform(words)feature的shape如下图所示:

导入贝叶斯模型:
from sklearn.naive_bayes import MultinomialNB #贝叶斯模型
classifier = MultinomialNB()
classifier.fit(feature, y_train)如下:

结果如下:

图24-基于词频矩阵分类结果
保存模型:
joblib.dump(classifier,'CountVectorizer.pkl')再基于TF-IDF矩阵做训练:模型初始化:
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(analyzer='word', max_features=20, lowercase = False)
vectorizer.fit(words)初始化如下图:

最终的分类准确度为:

图25-基于TF-IDF矩阵分类结果
分类效果没有 CountVectorizer的好。
保存模型:
joblib.dump(classifier,'TfidfVectorizer.pkl')- 功能展示/结果对比
我们本次大作业基于警情数据做了一个警方管理和自动报案系统,自动报案系统基于报案人的口述数据,判断该报案内容为哪一类的报案数据,对于类别联系自动联系对于警方部门来处理,这和报案内容分类的准确度有很大关系;警方管理主要是警方基于警情信息,对警情进行一些查看和分析。
界面总体模块图:

图25-界面模块图
1.分类准确度:
①TextCNN不做数据清洗,只滤去无关信息(未做数据增强):
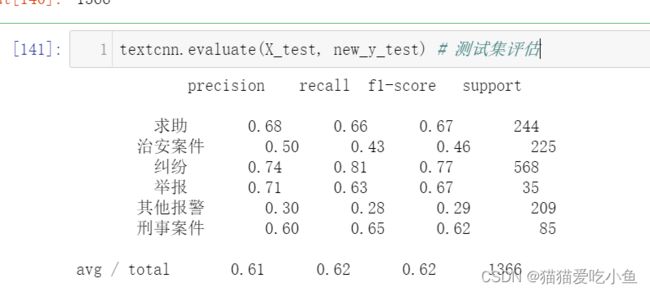
图26-基于TextCNN不做数据清洗(未做数据增强)分类结果
分类准确度如下:平均为0.61,其他报警类的报警数据分类准确度为0.3,特别低,治安案件的分类也比较差,只有纠纷类的比较高,因为其中的样本数是最多的。
②TextCNN做数据清洗(未做数据增强):

图27-基于TextCNN做数据清洗(未做数据增强)分类结果
分类准确度如下:平均为0.56,其他报警类的报警数据分类准确度为0.29,任然特别低,治安案件的分类还是比较差,只有纠纷类的准确度降低了,举报类和刑事案件类的准确度都上升了,因为数据清洗时可能会导致数据变为空的情况,也删除了很多信息,所以样本多的类别准确度会下降,而样本少的类别准确度会上升。对类别少的样本比较有利,但是总体的分类准确度还是降低了。
③fastText(做过清洗数据):
训练集准确度为0.93,比TextCNN的要高

图28-fastext训练准确度
测试集准确度为0.63,比TextCNN的要高

图29-fastext测试准确度
可见在警情数据分析中,fastText比textcnn更好一点,而且可以明显感觉到fastText的模型训练速度比textcnn快很多,但是fastText比textcnn训练的模型也大很多。
④朴素贝叶斯:
基于词频向量训练准确度为0.58。

基于TF-IDF的向量训练准确度为0.51.

基于TF-IDF向量的分类可能更适用于主题检测中,或是新闻分类中,在警情数据分析中的分类效果不太理想。基于词频向量的准确度和TextCNN相差不大,训练速度稍微慢一点。
2.警方人员对警情数据的查看:
①搜索引擎,警方人员可以通过该系统上网搜索需要的信息。

图30-搜索引擎
②案件分布查看:警方人员查看报案人员的统计性别信息,地域信息和事件性质分布信息,来查看目前的案件统计状况,给解决案件提供相关的思路。

图31-案件性别信息
对于报案的地区做一个简单映射(为了方便地区的查看):
data=[('浙江', k1), ('江苏', k2), ('上海', k3), ('湖南', k4),
('安徽', k5), ('广东', k6), ('湖北', k7), ('河南', k8), ('江西', k9)]结果如下图所示:

图31-案件地域分布信息
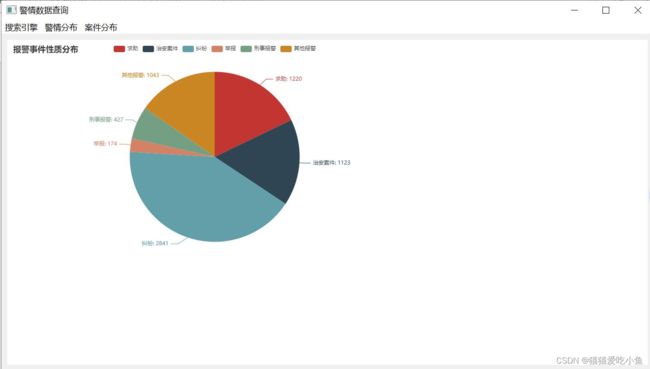 图32-案件类别分布信息
图32-案件类别分布信息
③警情分析查看:
用于查看警情的分布信息。

图32-警情分析查看
3.报案人员自助报案:

图33-自助报案界面
按下我要报警求助,进行报案语音的识别。模型检测报案内容,给出相关部门的指引(例如,你需要找到求助部门,已通知该部门的警察,请留下你的电话哦)。
我们语音输入【‘我要求助,我们家出事了!!’】,给出反馈如下所示:

图34-自助报案结果
- 讨论与总结
1.TextCNN的使用
TextCNN的流程:先将文本分词做embeeding得到词向量, 将词向量经过一层卷积,一层max-pooling, 最后将输出外接softmax 来做n分类。
TextCNN 的优势:模型简单, 训练速度快,效果不错。
TextCNN的缺点:模型可解释型不强,在调优模型的时候,很难根据训练的结果去针对性的调整具体的特征,因为在textCNN中没有类似gbdt模型中特征重要度(feature importance)的概念, 所以很难去评估每个特征的重要度。
实际训练中。TextCNN的网络模型比较复杂,但是效果还可以,,且训练速度也很快。
2.fastText的使用
fastText和word2vec模型结构很像,都是采用embedding向量的形式,得到word的隐向量表达。也都采用很多相似的优化方法,比如使用Hierarchical softmax优化训练和预测中的打分速度。但是而fasttext的输出层对应的是分类的label。不过不管输出层对应的是什么内容,起对应的vector都不会被保留和使用;fasttext输入层需要对应的整个sentence的内容,包括term,也包括 n-gram的内容。它的分类思想为利用h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者N个)。
例如:

在本次大作业中,我们体会到fastText的学习速度比较快,效果还不错。fastText适用与分类类别非常大而且数据集足够多的情况,当分类类别比较小或者数据集比较少的话,很容易过拟合。它可以完成无监督的词向量的学习,可以学习出来词向量,来保持住词和词之间,相关词之间是一个距离比较近的情况;也可以用于有监督学习的文本分类任务。
3.基于文本分类的应用和文本的实体之间的联系还没有过多的深入,我们的初步设想是利用警情数据中的报警处理信息,应用到给报案人员的自助报案的反馈中,但是提取文本的实体联系和文本的实体信息比较难,由于各种环境配置都没能成功,所以最后也没实现。
4.文本数据的清洗比较适用于长文本,不太适用于短文本,因为短文本的内容本来就信息量很少,即时是无关信息,也会造成分类准确度的影响。
5.TF-IDF特征在报警数据集中的表现特别差,因为基于TF-IDF向量的分类可能更适用于主题检测中,或是新闻分类中,在警情数据分析中的分类效果不太理想。
视频演示链接:
文本分析_警情可视和自助报警_哔哩哔哩_bilibili