14.用Python实现BP神经网络算法/实现感知器神经元算法
0.前言
感知器算法是一种用于二进制分类的监督学习算法,可以预测数字向量所表示的输入是否属于特定的类(其分类结果假定标记为0和1),分类器(classfier)试图通过线性分离器(separator)来划分这两个类。感知机(Perceptron)是二分类问题的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取0和1二值也可取+1和-1二值。
感知器通过输入空间(特征空间)将实例划分为(正负)两类的分离超平面,属于判别模型。
找到一个权矢量,使得惩罚函数/损失函数最小化,通常使用梯度下降算法来迭代。
感知器不仅仅能实现简单的布尔运算。它可以拟合任何的线性函数,任何线性分类或线性回归问题都可以用感知器来解决。前面的布尔运算可以看作是二分类问题,即给定一个输入,输出0(属于分类0)或1(属于分类1)。
目录
0.前言
一、用感知器实现and函数
二、用感知器实现or函数(未完成)
一、用感知器实现and函数
注意⚠️:用0表示false,用1表示true.
 |
 |
 |
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
代码实例1:
from re import X
from tkinter import W
from functools import reduce
#定义感知器类
class Perceptron(object):
#初始化感知器,设置输入参数的个数,以及激活函数(类型:double -> double)
def __init__(self,input_num,activator):
self.activator = activator
self.weights = [0.0 for _ in range(input_num)]#权重向量初始化为0
self.bias = 0.0#偏置初始化为0
#打印训练所得权重和偏置
def __str__(self):
return 'weoghts\t:%s\nbias\t:%f\n' %(self.weights,self.bias)
def predict(self,input_vec):
#输入向量,输出感知器的计算结果
# 把input_vec[x1,x2,x3...]和weights[w1,w2,w3,...]打包在一起
# 变成[(x1,w1),(x2,w2),(x3,w3),...]
# 然后利用map函数计算[x1*w1, x2*w2, x3*w3]
# 最后利用reduce求和,计算出激活函数值
return self.activator(
reduce(lambda a,b: a+b,
map(lambda x,w: x * w,
zip(input_vec,self.weights)) ,0.0) + self.bias)
def train(self,input_vecs,labels,iteration,rate):
#输入训练数据:一组向量、与每个向量对应的实际值label;以及训练轮数,学习率
for i in range(interation):
self._one_iteration(input_vecs,lables,rate)
def _one_iteration(self,input_vecs,labels,rate):
#一次迭代,把所有的训练数据过一遍
# 把输入和输出打包在一起,成为样本的列表[(input_vec, label), ...]
# 而每个训练样本是(input_vec, label)
samples = zip(input_vecs,labels)
#对每个样本,按照感知器规则更新权重
for(input_vec,label) in samples:
# 计算感知器在当前权重下的输出
output = self.predict(input_vec)
# 更新权重
self._update_weights(input_vec,output,label,rate)
def _update_weights(self,input_vec,output,label,rate):
#按照感知器规则更新权重
# 把input_vec[x1,x2,x3,...]和weights[w1,w2,w3,...]打包在一起
# 变成[(x1,w1),(x2,w2),(x3,w3),...]
# 然后利用感知器规则更新权重
delta = label - output
self.weights = map(
lambda x,w:w + rate * rate * x,
zip(input_vec,self.weights))
self.bias += rate * delta #更新bias
#利用这个感知器类去实现and函数
#定义激活函数
def f(x):
return 1 if x > 0 else 0
def get_training_dataset():
# 基于and真值表构建训练数据
# 输入向量列表
input_vecs = [[0,0],[0,1],[1,0],[1,1]]
# 期望的输出列表,注意要与输入一一对应
# [0,0] -> 0, [0,1] -> 0,[1,0] -> 0,[1,1] -> 1
labels = [0,0,0,1]
return input_vecs,labels
def train_and_Perceptron():
#使用and真值表训练感知器
# 创建感知器,输入参数个数为2(因为and是二元函数),激活函数为f
p = Perceptron(2,f)#新建一个感知器
#训练,迭代10轮,学习速率0.1
input_vecs,labels = get_traning_dataset()
p.train(input_vecs,labels,10,0.1)
#返回训练好的感知器
return p
if __name__ == '__main__':
#训练and感知器
and_Perceptron= train_and_Perceptron()
#打印训练获得的权重
print (and_Perceptron)
#测试
print ('0 and 0 = %d' % and_Perceptron.predict([0,0]))
print ('0 and 1 = %d' % and_Perceptron.predict([0,1]))
print ('1 and 0 = %d' % and_Perceptron.predict([1,0]))
print ('1 and 1 = %d' % and_Perceptron.predict([1,1]))
目前代码有一处错误❌:NameError: name 'Perceptron' is not defined
:(1)安装perceptron感知器
pip3 install perceptron
(2)缩进错误/类/定义
注意从属关系
代码实例2:
from functools import reduce
#定义感知器类
class perceptron(object):
#感知器初始化函数(参数个数,激活函数)
def __init__(self, input_num, activator):
self.activator = activator
self.weights = [0.0 for _ in range(input_num)] #将每个参数对应权值设为0
self.bias = 0.0 #偏置值设为0
#输出训练所得权值与偏置值
def __str__(self):
return 'weights\t:%s\nbias\t:%f\n' % (self.weights, self.bias)
#计算激活函数值
def predict(self, input_vec):
return self.activator(reduce(lambda a, b : a + b, map(lambda xw : xw[0] * xw[1], zip(input_vec, self.weights)), 0.0) + self.bias)
#更新权重与偏置值
def _update_weights(self, input_vec, output, label, rate):
delta = label - output #计算预测值与真值之差
self.weights = list(map(lambda xw : xw[1] + rate * delta * xw[0], zip(input_vec, self.weights))) #更新权重
self.bias = rate + delta #更新偏置
#迭代计算
def _one_iteration(self, input_vecs, labels, rate):
samples = zip(input_vecs, labels)
for(input_vec, label) in samples:
output = self.predict(input_vec) #计算激活函数值
self._update_weights(input_vec, output, label, rate) #更新权值与偏置值
#训练数据得权值、偏置值
def train(self, input_vecs, labels, iteration, rate):
for _ in range(iteration):
self._one_iteration(input_vecs, labels, rate)
def f(x):
return 1 if x>0.5 else 0
def get_training_dataset():
input_vecs = [[0,0], [0,1], [1,0], [1,1]]
labels = [0, 0, 0, 1]
return input_vecs, labels
def train_and_perceptron():
p = perceptron(2,f) #新建一个感知器
input_vecs, labels = get_training_dataset()
p.train(input_vecs, labels, 5, 0.1)
return p
if __name__ =='__main__':
and_perceptron = train_and_perceptron()
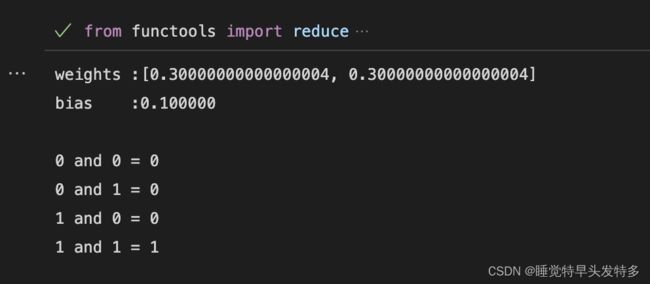
print(and_perceptron)
print('0 and 0 = %d' % and_perceptron.predict([0,0]))
print('0 and 1 = %d' % and_perceptron.predict([0,1]))
print('1 and 0 = %d' % and_perceptron.predict([1,0]))
print('1 and 1 = %d' % and_perceptron.predict([1,1]))运行结果:
二、用感知器实现or函数
|
|
|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
学习参考:NameError:“classname”在python中沒有定義錯誤 - NameError: name 'classname' is not defined error in python - 开发者知识库