使用Python+OpenCV探索鲸鱼识别(季军得主分享)

使用曲率积分和动态时间规整,让我们深入研究抹香鲸识别!
前言
最近,我们参加了Capgemini的全球数据科学挑战赛。我与Acores鲸鱼研究中心合作,挑战抹香鲸的识别任务,用人工智能帮助拯救抹香鲸的生命。
为了完成这项任务,我们收集了过去几年几千张的鲸鱼照片。在训练数据集中,平均每头鲸鱼有1.77张照片,很多动物只出现过一次,因此,我们的目标是,给定一个新的图片,在已有数据中找出最相似的。
因此,如果鲸鱼已经被拍下来,研究人员就可以知道是何时何地拍的了。
我很自豪地宣布,我们以第三名的成绩结束了比赛,我们使用暹罗网络取得了胜利,但是,由于已经有很多关于这个架构的文章,所以今天将介绍另一个更有趣、更新颖的方法来解决这个问题。
方法
本文介绍的方法由Weideman等人提出,算法的主要步骤如下:
基于颜色分析和轮廓检测的尾部提取
曲率积分进行尾部处理(IC)
与动态时间规整(DTW)进行尾部比较
所以该方法的预测率不如暹罗网络好,但是这个想法非常有趣,值得分享和了解。在许多数据科学项目中,数据准备是最困难的部分,要将鲸鱼尾部处理为信号,信号的质量必须非常好。在本文中,我们将花一些时间来理解信号处理之前的所有必要步骤。
探索我们的数据集,分析图片
如引言中所述,我们得到了数千张图片。乍一看,鲸鱼就是鲸鱼,所有这些图片看上去都像是一个蓝色背景(天空和大海),中间有一个灰色斑点(尾巴)。
经过初步探索之后,我们发现尾巴的形状可以作为区分鲸鱼的重要特征,我们确信这对我们的算法至关重要。那颜色呢?像素分布中是否有什么有用的信息?

使用Bokeh可视化库(https://bokeh.org/)来分析每个图片中颜色数量之间的相关性(绿色与红色–蓝色与红色–绿色与蓝色) ,我们很快发现图像中的颜色高度相关。因此,我们专注于轮廓,然后尝试通过颜色变化来识别鲸鱼。
基于彩色滤波器的尾部提取
检测尾巴轮廓的第一步是在图片里从天空和海水中提取尾巴,这也是尾部提取中最困难的部分。
首先,我们使用轮廓检测算法,但是由于从一个镜头到另一个镜头的阳光不断变化,因此对比度发生了很大变化,轮廓检测算法得到结果总不能令人满意。
使用颜色提取尾巴
我们为每个通道强度(红色,绿色,蓝色)绘制灰度图片

观察单个图片的三个通道
正如你在上面看到的,对于大多数图片来说,图片中间的颜色较少,可以按像素强度进行过滤。由于尾巴通常是灰色的,因此它们的每种颜色的数量几乎相同(R = G = B),但是,海和天空往往是蓝色的,这使该颜色成为过滤的理想选择。
让我们看看当只保留蓝色值,并且只保留蓝色值<选定的阈值(blue_value < SELECTED_THRESHOLD)的像素时会发生什么。
选定的阈值SELECTED_THRESHOLD的最大值为255,因为它是像素强度的最大值。

通过这一系列图片,我们可以确信通过此方法可以很容易提取图片中的尾巴区域。但是我们该如何选择过滤阈值?
以下是使用10到170(十乘十)的所有值作为单个图片的阈值的结果示例。
根据蓝色像素的强度,在一张图片上应用17种不同的滤波器:

以下是一些有趣的内容:
阈值很小(大约10),大海消失了,但尾巴也消失了
阈值很小(大约20),尾巴的一部分消失了
阈值不太高(大约40),提取的挺好,所有的尾巴都没有阈值那么蓝,但是所有的大海都比阈值蓝。
在中间阈值(大约80)的情况下,尾巴保持完整,但我们只能保留部分海洋
在接近中间值的阈值(约110)的情况下,很难区分海和尾巴
在较高的阈值(>=140)下,尾巴完全消失,这意味着即使大海也不够蓝,无法通过过滤器选择。
很明显应该采用SELECTED_THRESHOLD = 40并应用filter blue_value < 40。
但是并不是每一张图片的光照强度都是一样的,通过将所有这些阈值绘制在随机图片上的结果,该阈值在10到130之间变化。那么如何选择合适的值呢?
使用边界框选择阈值
通过查看前面的图片,我们想到了一些东西:正确阈值的正确图片是外部具有最大空白区域而内部具有最大区域的图像,我们希望一些在ImageNet上训练的神经网络可以对图片中的鲸鱼进行定位,我们决定使用基于ImageNet预训练的MobileNet。

与原始图片相比,一批提取的尾巴带有边框
如下所示,我们可以非常准确地确定图片中尾巴的位置,然后,我们可以在所有图片中将“尾部-内部”与“海部-外部”分开。

为了更好地了解这种分离,对于训练集的每张图片,我们将边界框内每个像素的蓝色值相加,并对框外的像素进行相同的处理。
然后,我们在下图上绘制每个图片,内部结果体现在X轴上,外部结果体现在Y轴上,蓝线代表X = Y。我们可以从此图形中获得的含义如下:你离线条越远,尾巴和海洋之间的分隔就越容易。
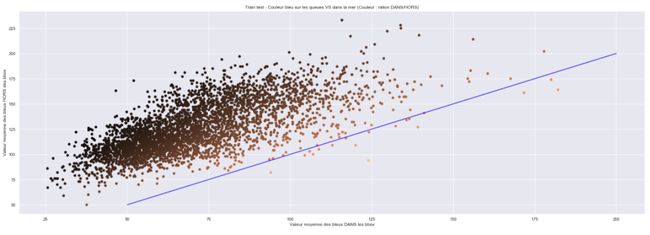
我们尝试根据与线的距离应用过滤器阈值,但这没有产生任何结果,经过几次尝试,我们知道仅根据图片的颜色分布还得不到结果,因此我们决定采用强硬的方法,即除了查看图片并确定阈值外,我们还为每张图片应用15个滤波器,对其进行分析,然后自动选择最佳滤波器以进行进一步处理。
然后对于给定的图片,我们将15个滤波器应用了15个不同的值作为阈值,对于每个滤波器,我们计算边界框内的像素和外面的像素的数量(过滤后,像素值为0或1,无需再对强度求和),然后,对结果进行归一化,使数字独立于图像的大小,并将结果绘制在一个图形上。
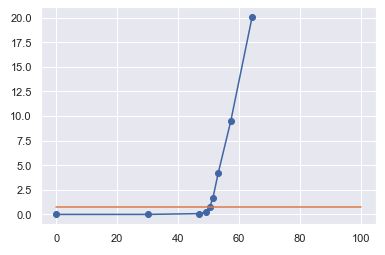
单个图片和不同过滤阈值的边界框内(X轴)和外框(Y轴)的像素数量。
对于每张图片,我们得到的曲线都类似于上面的曲线,这是我们随着阈值的演变而对前面的陈述进行的数学转换。
当阈值很小时,尾巴和大海消失了,尾部内部或外部均无像素
当阈值增加时,出现尾巴,并且X轴的值升高。
直到阈值开始出现在海洋的某些部分,并且外部关注度开始增长。
使用线性回归或导数,很容易计算出正确的阈值:它是图的两条线的交点处的阈值。
注意:橙色线是 y = y_of_the_selected_threshold
尾巴提取的最后提示
最后,为了在提取时得到最好的图片,当我们计算出最佳阈值(10,20,30,40,…,120,130,140,150)时,假设是80。我们对-5/+5值应用了过滤器,所以我们有三张照片:蓝色<75,蓝色<80,蓝色<85,然后我们将这些网格图片中的三个(0和1)求和,并且只保留结果像素值等于2的像素,这将作为最后的过滤器,去除尾部的噪音。
结果
我们可以使用滤波器根据蓝色像素的强度把尾巴和海洋区分开来
在过滤之前,需要为每个图片找到一个阈值
使用边界框是找到此阈值的有效方法
经过几个小时的工作,我们最终得到了一个非常好的尾巴提取器,可以很好地处理具有不同亮度、天气、海洋颜色、尾巴颜色的尾巴。

一批提取出来的尾巴与原始图片进行的比较
轮廓检测
现在已经可以定位尾部在图片中的位置,我们可以进行轮廓检测了。
在这一步,我们可以使用OpenCV的轮廓检测算法,但是通过以下两个步骤会更快一些:
步骤1:使用熵去除尾巴周围的噪声
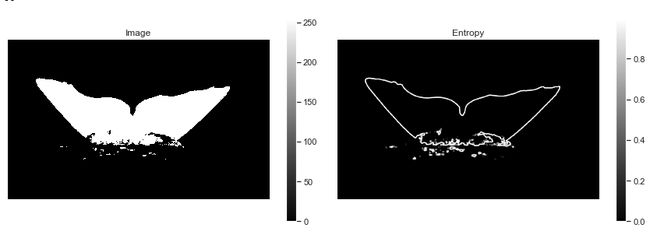
使用熵变仅保留提取的尾巴轮廓
步骤2:保持每列图片的高光像素

应用熵滤波器后检测到的尾巴轮廓
此步骤非常简单,没有什么复杂性。
曲率积分
通过从海中提取尾巴并获取图片的上部像素,我们可以把尾巴的后沿作为数学信号。现在我们就要处理规范化问题了,因为所有图片的大小或像素数量都不相同,同时到抹香鲸的距离并不总是相同,拍摄时的方位也可能会发生变化。

尾巴方向的示例,同一条鲸的两张照片之间可能会有所不同
为了进行标准化,我们必须沿着两个轴进行。首先,我们使用每条尾巴300个点进行信号比较;然后我们对最短的插值进行插值,并对最长的进行采样;其次,我们将0到1之间的所有值归一化,这导致信号叠加,如下图所示。

标度信号叠加
为了解决定向问题,我们使用了曲率积分度量,该度量通过局部评估将信号转换为另一个信号。然后,在每一步中,我们将信号的边缘沿圆形拉直,以使其内接为正方形。

曲率积分原理
最后,我们定义曲率如下:
曲率是曲线下到正方形总面积的面积,这意味着直线的曲率值为c = 0.5
因此,我们获得了标准化信号,与鲸鱼和摄影者之间的距离无关、与鲸鱼和摄影者之间的角度无关、并且与鲸鱼和海洋之间的倾角无关。
然后,对于每张训练测试图片,我们在IC相移期间创建了半径分别为5、10和15像素的信号并将它们存储起来,用于最后一步:时间序列之间的比较。
对于一条尾巴,信号如下所示:
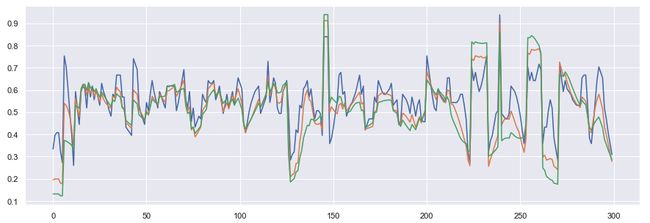
曲率积分应用于带有3个不同半径值的抹香鲸尾缘
现在,让我们进行信号比较!
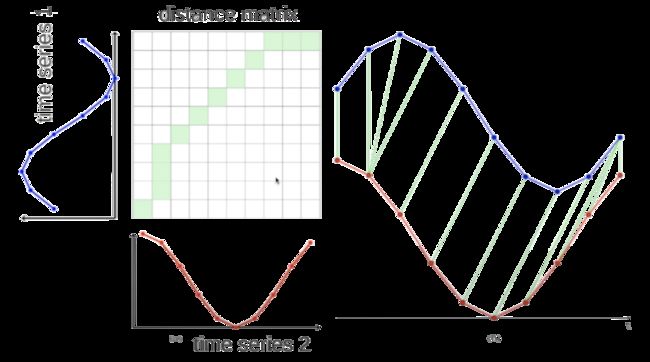
动态时间规整
动态时间规整(DTW,https://en.wikipedia.org/wiki/Dynamic_time_warping) 是一种能够在两个时间序列之间找到最佳对齐方式的算法,它通常用于确定时间序列的相似性,分类以及查找两个时间序列之间的对应区域。
与欧几里得距离(指的是两条曲线之间的距离,逐点)相反,DTW距离允许链接曲线的不同部分。该算法的工作原理如下:
使用两条曲线,并创建了两个曲线之间的距离矩阵,从左下角到右上角,计算两点之间的距离Ai和Bi,计算两个点之间的距离:D(Ai, Bi) = |Ai — Bi] + min(D[i-1, j-1], D[i-1, j], D[i, j-1])。
然后我们计算从右上角到左下角的权重较小的路径,为此,我们在每一步中选择具有最小值的平方。
最后,所选的路径(下图中的绿色)指示在序列A的数据点到序列B中的对应数据点。
这些基本计算的实现非常容易。例如,这是一个根据两个序列s和创建距离矩阵的函数t。
def dtw(s, t):
""" Computes the distance matrix between two time series
args: s and t are two numpy arrays of size (n, 1) and (m, 1)
"""
# Instanciate distance matrix
n, m = len(s), len(t)
dtw_matrix = np.zeros((n+1, m+1))
for i in range(n+1):
for j in range(m+1):
dtw_matrix[i, j] = np.inf
dtw_matrix[0, 0] = 0
# Compute distance matrix
for i in range(1, n+1):
for j in range(1, m+1):
cost = abs(s[i-1] - t[j-1])
last_min = np.min([
dtw_matrix[i-1, j],
dtw_matrix[i, j-1],
dtw_matrix[i-1, j-1]
])
dtw_matrix[i, j] = cost + last_min
return dtw_matrix
现在让我们回到我们的抹香鲸!数据集的每个尾巴都转换为“积分曲线信号”,我们计算了所有尾巴之间的距离,以发现最接近的那些尾巴。
然后,当接收到一张新图片时,我们必须使其通过整个准备流程:使用蓝色滤波器的尾部提取,使用熵方法进行轮廓检测以及使用IC进行轮廓转换,最后会得到一个300x1形状的张量,最后我们要计算它到整个数据集中所以样本的相似度,当然这个过程这很费时。
结果显示,当我们有两张相同的鲸鱼照片时,在大多数情况下,两张照片是最接近的40张,这在2000年中是最好的。但是,如引言中所述,使用暹罗网络的结果要好于该算法,鉴于比赛的时间,我们不得不研究选择其他的方法。
使用一半的尾巴和一半的信号
我们尝试使用半尾巴特征,如下所示:
尾巴是对称的,这将简化计算。
尾巴是不对称的,可以通过半尾巴进行比较。
尽管进行了大量测试,但这并没有给我们非常确定的结果,因为我们认为我们的分离不够可靠,我们将需要更多时间来研究信号处理带来的更好分离。
最后的想法
本文中由于图片的颜色(基本上是蓝色——海洋和天空)以及数据集中图片的不同亮度,我们对尾巴识别应用了两种连续的处理方法。
首先,曲率积分是一种通过查看曲线的局部变化对信号进行归一化的方法,然后,我们使用了动态时间规整,这是两条曲线之间的距离计算方法,即使移动了两条曲线也可能会发现两条曲线之间的相似性。
不幸的是,结果并不如我所愿,我们无法继续使用该解决方案。通过更多的时间和更多的努力,我深信我们可以改进实现中的每个步骤,从而获得更好的模型。
通过所有步骤,实现它们的不同方法以及参数,监视所有转换非常具有挑战性。正如我们有路线图一样,每一步都有其自身的困难,每一次小小的成功都是胜利,并开启了下一步,这是非常另人兴奋的。
我发现这种方法是非常有趣的,与通常的预训练CNN模型完全不同。希望你也喜欢本文中这种方法的优点。
参考文献
IC + DTW的总结:
-
https://arxiv.org/abs/1708.07785
动态时间规整1–0–1(中等)
-
https://towardsdatascience.com/dynamic-time-warping-3933f25fcdd
DTW python实现
-
https://pypi.org/project/dtw-python/
Kaggle座头鲸鉴定比赛
-
https://www.kaggle.com/c/humpback-whale-identification
关于此次活动的Capgemini 网页(面向公司外人员)
-
https://www.yammer.com/capgemini.com/#/threads/inGroup?type=in_group&feedId=13438430&view=all
参考链接:https://towardsdatascience.com/whale-identification-by-processing-tails-as-time-series-6d8c928d4343
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 mthler」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
