使用Spark操作Hudi
开发环境:
hadoop 2.7.6
hive 2.3.7
spark 2.4.5
1、pom文件
<repositories>
<repository>
<id>maven-aliid>
<url>http://maven.aliyun.com/nexus/content/groups/public//url>
<releases>
<enabled>trueenabled>
releases>
<snapshots>
<enabled>trueenabled>
<updatePolicy>alwaysupdatePolicy>
<checksumPolicy>failchecksumPolicy>
snapshots>
repository>
repositories>
<dependencies>
<dependency>
<groupId>org.apache.hudigroupId>
<artifactId>hudi-clientartifactId>
<version>0.5.3version>
dependency>
<dependency>
<groupId>org.apache.hudigroupId>
<artifactId>hudi-hiveartifactId>
<version>0.5.3version>
dependency>
<dependency>
<groupId>org.apache.hudigroupId>
<artifactId>hudi-spark-bundle_2.11artifactId>
<version>0.5.3version>
dependency>
<dependency>
<groupId>org.apache.hudigroupId>
<artifactId>hudi-commonartifactId>
<version>0.5.3version>
dependency>
<dependency>
<groupId>org.apache.hudigroupId>
<artifactId>hudi-hadoop-mr-bundleartifactId>
<version>0.5.3version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>2.4.5version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>2.4.5version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.11artifactId>
<version>2.4.5version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-avro_2.11artifactId>
<version>2.4.5version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.7.2version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.47version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.11artifactId>
<version>2.4.5version>
dependency>
<dependency>
<groupId>org.spark-project.hivegroupId>
<artifactId>hive-jdbcartifactId>
<version>1.2.1.spark2version>
dependency>
dependencies>
2、模拟数据工具类
import java.io.{BufferedWriter, File, FileWriter}
import scala.util.Random
case class DwsMember(uid: Int,
ad_id: Int,
var fullname: String,
iconurl: String,
dt: String,
dn: String
)
object GenDataUtils {
def main(args: Array[String]): Unit = {
val writeFile = new File("text.txt")
val writer = new BufferedWriter(new FileWriter(writeFile))
for(i <- 1 to 10){
val dwsMember = DwsMember(i, Random.nextInt(i),
s"spark_hudi_${Random.nextInt(5)}",
s"www.baidu_${randomString(10)}.com",
"2021-03-04", // 后面这两个属于分区
s"dept_${Random.nextInt(10)}"
)
println(GsonUtil.toJson(dwsMember))
writer.write(GsonUtil.toJson(dwsMember)+"\n")
}
writer.close()
}
/**
* 生成随机字符串
* @param len 长度
* @return
*/
def randomString(len: Int): String = {
val rand = new scala.util.Random(System.nanoTime)
val sb = new StringBuilder(len)
val ab = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
for (i <- 0 until len) {
sb.append(ab(rand.nextInt(ab.length)))
}
sb.toString
}
}
3、配置文件
将集群配置文件复制到resources文件夹下,使本地环境可以访问hadoop集群
4、Hudi写Hdfs
import com.google.gson.Gson
import com.zyh.bean.DwsMember
import org.apache.hudi.DataSourceReadOptions
import org.apache.spark.sql.{SaveMode, SparkSession}
object HoodieDataSourceExample {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession
.builder()
.appName("dwd_member_import")
.master("local[*]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.enableHiveSupport()
.getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://localhost:8020")
ssc.hadoopConfiguration.set("dfs.nameservices", "localhost")
// insertData(sparkSession)
// queryData(sparkSession)
// updateData(sparkSession)
// incrementalQuery(sparkSession)
// pointInTimeQuery(sparkSession)
}
/**
* 读取hdfs日志文件通过hudi写入hdfs
* @param sparkSession
*/
def insertData(sparkSession: SparkSession) = {
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交时间
val df = sparkSession.read.text("/user/test/ods/member.log")
.mapPartitions(partitions => {
val gson = new Gson
partitions.map(item => {
gson.fromJson(item.getString(0), classOf[DwsMember])
})
})
val result = df.withColumn("ts", lit(commitTime)) //添加ts 时间戳列
.withColumn("uuid", col("uid")) //添加uuid 列 如果数据中uuid相同hudi会进行去重
.withColumn("hudipartition", concat_ws("/", col("dt"), col("dn"))) //增加hudi分区列
result.write.format("org.apache.hudi")
// .options(org.apache.hudi.QuickstartUtils.getQuickstartWriteConfigs)
.option("hoodie.insert.shuffle.parallelism", 12)
.option("hoodie.upsert.shuffle.parallelism", 12)
.option("PRECOMBINE_FIELD_OPT_KEY", "ts") //指定提交时间列
.option("RECORDKEY_FIELD_OPT_KEY", "uuid") //指定uuid唯一标示列
.option("hoodie.table.name", "testTable")
// .option(DataSourceWriteOptions.DEFAULT_PARTITIONPATH_FIELD_OPT_VAL, "dt") // 发现api方式不起作用 分区列
.option("hoodie.datasource.write.partitionpath.field", "hudipartition") //分区列
.mode(SaveMode.Overwrite)
.save("/user/zyh/hudi")
}
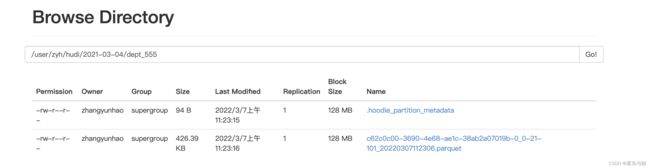
查看hdfs目录 /user/zyh/hudi :
5、查询hdfs上的hudi数据
/**
* 查询hdfs上的hudi数据
* @param sparkSession
*/
def queryData(sparkSession: SparkSession) = {
val df = sparkSession.read.format("org.apache.hudi")
.load("/user/zyh/hudi/*/*")
// 执行sql, 需要启动hive
df.createOrReplaceTempView("hudi_trips_snapshot")
sparkSession.sql(
"""
|select * from hudi_trips_snapshot
|where uuid <= 10
|""".stripMargin).show()
// df.show()
}
查询结果:
+-------------------+--------------------+------------------+----------------------+--------------------+---+-----+------------+--------------------+----------+--------+-------------+----+-------------------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|uid|ad_id| fullname| iconurl| dt| dn| ts|uuid| hudipartition|
+-------------------+--------------------+------------------+----------------------+--------------------+---+-----+------------+--------------------+----------+--------+-------------+----+-------------------+
| 20220307112306| 20220307112306_0_1| 9| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 9| 7|spark_hudi_1|www.baidu_NobsixQ...|2021-03-04|dept_555|1646623382412| 9|2021-03-04/dept_555|
| 20220307112306| 20220307112306_0_2| 4| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 4| 1|spark_hudi_0|www.baidu_poUl3kG...|2021-03-04|dept_555|1646623382412| 4|2021-03-04/dept_555|
| 20220307112306| 20220307112306_0_3| 6| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 6| 5|spark_hudi_3|www.baidu_EToGOeF...|2021-03-04|dept_555|1646623382412| 6|2021-03-04/dept_555|
| 20220307112306| 20220307112306_0_4| 1| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 1| 0|spark_hudi_3|www.baidu_jVe5qFR...|2021-03-04|dept_555|1646623382412| 1|2021-03-04/dept_555|
| 20220307112306| 20220307112306_0_5| 8| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 8| 6|spark_hudi_3|www.baidu_3QIQkmT...|2021-03-04|dept_555|1646623382412| 8|2021-03-04/dept_555|
| 20220307112306| 20220307112306_0_6| 3| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 3| 0|spark_hudi_1|www.baidu_y8Iy34C...|2021-03-04|dept_555|1646623382412| 3|2021-03-04/dept_555|
| 20220307112306| 20220307112306_0_7| 5| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 5| 3|spark_hudi_0|www.baidu_805Kokn...|2021-03-04|dept_555|1646623382412| 5|2021-03-04/dept_555|
| 20220307112306| 20220307112306_0_8| 10| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 10| 9|spark_hudi_3|www.baidu_JLTvL1M...|2021-03-04|dept_555|1646623382412| 10|2021-03-04/dept_555|
| 20220307112306| 20220307112306_0_9| 7| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 7| 5|spark_hudi_1|www.baidu_qmvx6sB...|2021-03-04|dept_555|1646623382412| 7|2021-03-04/dept_555|
| 20220307112306| 20220307112306_0_10| 2| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 2| 1|spark_hudi_2|www.baidu_n1tM4fJ...|2021-03-04|dept_555|1646623382412| 2|2021-03-04/dept_555|
+-------------------+--------------------+------------------+----------------------+--------------------+---+-----+------------+--------------------+----------+--------+-------------+----+-------------------+
6、修改hdfs上的hudi数据
另外生成10条数据,上传hdfs
def updateData(sparkSession: SparkSession) = {
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交时间
val df = sparkSession.read.text("/user/test/ods/member2.log")
.mapPartitions(partitions => {
val gson = new Gson
partitions.map(item => {
gson.fromJson(item.getString(0), classOf[DwsMember])
})
})
val result = df.withColumn("ts", lit(commitTime)) //添加ts 时间戳列
.withColumn("uuid", col("uid")) //添加uuid 列 如果数据中uuid相同hudi会进行去重
.withColumn("hudipartition", concat_ws("/", col("dt"), col("dn"))) //增加hudi分区列
result.write.format("org.apache.hudi")
// .options(org.apache.hudi.QuickstartUtils.getQuickstartWriteConfigs)
.option("hoodie.insert.shuffle.parallelism", 12)
.option("hoodie.upsert.shuffle.parallelism", 12)
.option("PRECOMBINE_FIELD_OPT_KEY", "ts") //指定提交时间列
.option("RECORDKEY_FIELD_OPT_KEY", "uuid") //指定uuid唯一标示列
.option("hoodie.table.name", "testTable")
// .option(DataSourceWriteOptions.DEFAULT_PARTITIONPATH_FIELD_OPT_VAL, "dt") // 发现api方式不起作用 分区列
.option("hoodie.datasource.write.partitionpath.field", "hudipartition") //分区列
.mode(SaveMode.Append)
.save("/user/zyh/hudi")
}
虽然代码操作和新增一样只是修改了插入模式为append, 但是hudi会根据 uuid 判断进行更新数据,操作完毕后,生成一份最新的修改后的数据,同时hdfs 路径上写入一份数据。
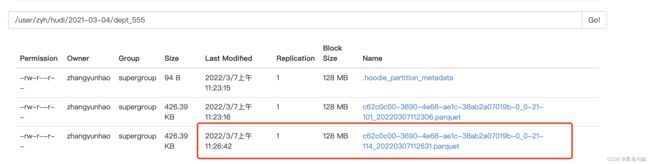
查询数据, 表中提交时间发生了变化:
+-------------------+--------------------+------------------+----------------------+--------------------+---+-----+------------+--------------------+----------+--------+-------------+----+-------------------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|uid|ad_id| fullname| iconurl| dt| dn| ts|uuid| hudipartition|
+-------------------+--------------------+------------------+----------------------+--------------------+---+-----+------------+--------------------+----------+--------+-------------+----+-------------------+
| 20220307112631| 20220307112631_0_1| 9| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 9| 8|spark_hudi_4|www.baidu_SRovjgs...|2021-03-04|dept_555|1646623586500| 9|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_2| 4| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 4| 0|spark_hudi_1|www.baidu_jiSM0oC...|2021-03-04|dept_555|1646623586500| 4|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_3| 6| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 6| 2|spark_hudi_1|www.baidu_O3S0YnZ...|2021-03-04|dept_555|1646623586500| 6|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_4| 1| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 1| 0|spark_hudi_1|www.baidu_MqF7avB...|2021-03-04|dept_555|1646623586500| 1|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_5| 8| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 8| 4|spark_hudi_4|www.baidu_HU0td3F...|2021-03-04|dept_555|1646623586500| 8|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_6| 3| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 3| 1|spark_hudi_2|www.baidu_f8neGOp...|2021-03-04|dept_555|1646623586500| 3|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_7| 5| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 5| 2|spark_hudi_1|www.baidu_BOYBqAQ...|2021-03-04|dept_555|1646623586500| 5|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_8| 10| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 10| 6|spark_hudi_0|www.baidu_17CF5VH...|2021-03-04|dept_555|1646623586500| 10|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_9| 7| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 7| 2|spark_hudi_2|www.baidu_f1Da431...|2021-03-04|dept_555|1646623586500| 7|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_10| 2| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 2| 1|spark_hudi_1|www.baidu_4hZECat...|2021-03-04|dept_555|1646623586500| 2|2021-03-04/dept_555|
+-------------------+--------------------+------------------+----------------------+--------------------+---+-----+------------+--------------------+----------+--------+-------------+----+-------------------+
注: 只有同一个分区的uuid,数据才会被更新
7、增量查询
def incrementalQuery(sparkSession: SparkSession) = {
val beginTime = 20220307104004L
val df = sparkSession.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL) //指定模式为增量查询
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, beginTime) //设置开始查询的时间戳 不需要设置结束时间戳
.load("/user/zyh/hudi")
df.show()
println(df.count())
}
根据 _hoodie_commit_time 时间进行查询,查询增量修改数据,注意参数 beginTime 是和 _hoodie_commit_time 对比,而不是和ts对比。如果 beginTime 比 _hoodie_commit_time 大,就会过滤掉全部数据。
查询结果:
+-------------------+--------------------+------------------+----------------------+--------------------+---+-----+------------+--------------------+----------+--------+-------------+----+-------------------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|uid|ad_id| fullname| iconurl| dt| dn| ts|uuid| hudipartition|
+-------------------+--------------------+------------------+----------------------+--------------------+---+-----+------------+--------------------+----------+--------+-------------+----+-------------------+
| 20220307112631| 20220307112631_0_1| 9| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 9| 8|spark_hudi_4|www.baidu_SRovjgs...|2021-03-04|dept_555|1646623586500| 9|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_2| 4| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 4| 0|spark_hudi_1|www.baidu_jiSM0oC...|2021-03-04|dept_555|1646623586500| 4|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_3| 6| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 6| 2|spark_hudi_1|www.baidu_O3S0YnZ...|2021-03-04|dept_555|1646623586500| 6|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_4| 1| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 1| 0|spark_hudi_1|www.baidu_MqF7avB...|2021-03-04|dept_555|1646623586500| 1|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_5| 8| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 8| 4|spark_hudi_4|www.baidu_HU0td3F...|2021-03-04|dept_555|1646623586500| 8|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_6| 3| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 3| 1|spark_hudi_2|www.baidu_f8neGOp...|2021-03-04|dept_555|1646623586500| 3|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_7| 5| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 5| 2|spark_hudi_1|www.baidu_BOYBqAQ...|2021-03-04|dept_555|1646623586500| 5|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_8| 10| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 10| 6|spark_hudi_0|www.baidu_17CF5VH...|2021-03-04|dept_555|1646623586500| 10|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_9| 7| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 7| 2|spark_hudi_2|www.baidu_f1Da431...|2021-03-04|dept_555|1646623586500| 7|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_10| 2| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 2| 1|spark_hudi_1|www.baidu_4hZECat...|2021-03-04|dept_555|1646623586500| 2|2021-03-04/dept_555|
+-------------------+--------------------+------------------+----------------------+--------------------+---+-----+------------+--------------------+----------+--------+-------------+----+-------------------+
10
8、指定特定时间查询
def pointInTimeQuery(sparkSession: SparkSession) = {
val beginTime = 20220307103005L
val endTime = 20220307112731L
val df = sparkSession.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL) //指定模式为增量查询
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, beginTime) //设置开始查询的时间戳
.option(DataSourceReadOptions.END_INSTANTTIME_OPT_KEY, endTime)
.load("/user/zyh/hudi")
df.show()
println(df.count())
}
查询结果:
+-------------------+--------------------+------------------+----------------------+--------------------+---+-----+------------+--------------------+----------+--------+-------------+----+-------------------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|uid|ad_id| fullname| iconurl| dt| dn| ts|uuid| hudipartition|
+-------------------+--------------------+------------------+----------------------+--------------------+---+-----+------------+--------------------+----------+--------+-------------+----+-------------------+
| 20220307112631| 20220307112631_0_1| 9| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 9| 8|spark_hudi_4|www.baidu_SRovjgs...|2021-03-04|dept_555|1646623586500| 9|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_2| 4| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 4| 0|spark_hudi_1|www.baidu_jiSM0oC...|2021-03-04|dept_555|1646623586500| 4|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_3| 6| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 6| 2|spark_hudi_1|www.baidu_O3S0YnZ...|2021-03-04|dept_555|1646623586500| 6|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_4| 1| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 1| 0|spark_hudi_1|www.baidu_MqF7avB...|2021-03-04|dept_555|1646623586500| 1|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_5| 8| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 8| 4|spark_hudi_4|www.baidu_HU0td3F...|2021-03-04|dept_555|1646623586500| 8|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_6| 3| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 3| 1|spark_hudi_2|www.baidu_f8neGOp...|2021-03-04|dept_555|1646623586500| 3|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_7| 5| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 5| 2|spark_hudi_1|www.baidu_BOYBqAQ...|2021-03-04|dept_555|1646623586500| 5|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_8| 10| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 10| 6|spark_hudi_0|www.baidu_17CF5VH...|2021-03-04|dept_555|1646623586500| 10|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_9| 7| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 7| 2|spark_hudi_2|www.baidu_f1Da431...|2021-03-04|dept_555|1646623586500| 7|2021-03-04/dept_555|
| 20220307112631| 20220307112631_0_10| 2| 2021-03-04/dept_555|c62c0c00-3690-4e6...| 2| 1|spark_hudi_1|www.baidu_4hZECat...|2021-03-04|dept_555|1646623586500| 2|2021-03-04/dept_555|
+-------------------+--------------------+------------------+----------------------+--------------------+---+-----+------------+--------------------+----------+--------+-------------+----+-------------------+
10