利用jemalloc解决flink的内存溢出问题
前言:
遇到一个Linux系统 glibc内存分配导致的OOM问题,根源是内存回收出现问题,导致碎片太多,内存无法回收,系统认为内存不够用了。
涉及到以下知识点:
1、Linux中典型的64M内存区域问题
2、glibc内存分配器ptmalloc2的底层原理
3、glibc的内存分配原理(Arean、Chunk、bins等)
4、malloc_trim对内存回收的影响
1、问题描述
前段时间做POC,在测试的过程中发现一个问题,使用Flink集群Session模式反复跑批处理任务时,集群某些节点TaskManger总是突然挂掉。
查看挂掉节点的系统日志发现原因是:操作系统内存被耗尽,触发了系统OOM,导致Flink TaskManager进程被操作系统杀掉了,下图:

从图二可以看到,taskManager进程已经占了67%的内存40多G内存,继续跑任务还会继续增加

2、配置
2.1 测试环境及配置
测试使用的版本如下所示:
Flink 1.14.3
Icberg 0.13.1
Hive 3.1.2
Hadoop 3.3.1
jdk1.8.0_181
FLink Standalone配置
jobmanager.rpc.address: 127.127.127.127
jobmanager.rpc.port: 6123
env.java.opts: “-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/bigdata/dump.hprof”
jobmanager.memory.process.size: 2000m – flink JM进程总内存
jobstore.expiration-time: 36000 – 已完成任务保留时间,每个任务会消耗50M内存
taskmanager.memory.process.size: 22000m – Flink TM进程总内存
taskmanager.numberOfTaskSlots: 22
parallelism.default: 100
taskmanager.network.sort-shuffle.min-parallelism: 1 – 默认使用sort-shuffle,flink 1.15之后默认就是1
taskmanager.network.blocking-shuffle.compression.enabled: true – 是否启用压缩
taskmanager.memory.framework.off-heap.size: 1000m
taskmanager.memory.framework.off-heap.batch-shuffle.size: 512m
execution.checkpointing.interval: 60000
execution.checkpointing.unaligned: true – 启用未对齐的检查点,这将大大减少背压下的检查点时间
execution.checkpointing.mode: AT_LEAST_ONCE – 配置数据处理次数,至少一次可以减少背压,加快处理速度
io.tmp.dirs: /home/testdir – 临时文件存储位置,批处理和流处理,要注意磁盘空间是否够用
execution.checkpointing.checkpoints-after-tasks-finish.enabled: true – 打开已完成job不影响checkpoint
可以看到,在配置中,此TaskManager分配的内存为22G,实际上通过TOP看到的结果已经达到了40+G。
4、定位过程
4.1 查看内存占用情况
经过初步定位发现,在调用icebergStreamWriter的时候内存会猛涨一下,任务跑完之后,这块多出来的内存并不会回收,怀疑是申请了堆外内存做缓存,用完之后未释放
首先通过阿里的Arthas看一下内存情况
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar
[INFO] arthas-boot version: 3.5.5
[INFO] Process 142388 already using port 3658
[INFO] Process 142388 already using port 8563
[INFO] Found existing java process, please choose one and input the serial number of the process, eg : 1. Then hit ENTER.
- [1]: 142388 org.apache.flink.runtime.taskexecutor.TaskManagerRunner
[2]: 2161 org.apache.ranger.authentication.UnixAuthenticationService
[3]: 142577 org.apache.flink.table.client.SqlClient
[4]: 170692 org.apache.hadoop.hdfs.server.datanode.DataNode
[5]: 170900 org.apache.hadoop.yarn.server.nodemanager.NodeManager
[6]: 73912 org.apache.flink.table.client.SqlClient
[7]: 141982 org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint
然后输入1,Enter
然后输入dashboard即可看到当前内存情况

可以发现进程的堆内存只有6.3G,非堆也很小,加起来不到6.5G,那另外30多G内存被谁消耗了,查看JVM内存分配,如下所示
- 堆(Heap):eden、metaspace、old 区域等
- 线程栈(Thread Stack):每个线程栈预留 1M 的线程栈大小
- 非堆(Non-heap):包括 code_cache、metaspace 等
- 堆外内存:unsafe.allocateMemory 和 DirectByteBuffer申请的堆外内存
- native (C/C++ 代码)申请的内存
- 还有 JVM 运行本身需要的内存,比如 GC 等。
初步怀疑这块内存应该是被native内存或者堆外内存消耗掉了
堆外内存可以使用NMT(Native Memory Tracking (NMT) )工具进行查看
NMT必须先通过VM启动参数中打开,不过要注意的是,打开NMT会带来5%-10%的性能损耗。
-XX:NativeMemoryTracking=[off | summary | detail]
off: 默认关闭
summary: 只统计各个分类的内存使用情况.
detail: Collect memory usage by individual call sites.
flink的NMT开关应该设置在flink-conf.yaml中,如下
env.java.opts: “-XX:+HeapDumpOnOutOfMemoryError -XX:NativeMemoryTracking=detail”,再次多次执行任务之后,查看结果:
[root@node11 ~]# jcmd 46538 VM.native_memory
46538:
Native Memory Tracking:
Total: reserved=14674985KB, committed=13459465KB
-
Java Heap (reserved=10657792KB, committed=10657792KB) (mmap: reserved=10657792KB, committed=10657792KB) -
Class (reserved=1184412KB, committed=149916KB) (classes #17919) (malloc=27292KB #30478) (mmap: reserved=1157120KB, committed=122624KB) -
Thread (reserved=389173KB, committed=389173KB) (thread #378) (stack: reserved=387392KB, committed=387392KB) (malloc=1243KB #1910) (arena=538KB #739) -
Code (reserved=262665KB, committed=81641KB) (malloc=13065KB #20566) (mmap: reserved=249600KB, committed=68576KB) -
GC (reserved=417087KB, committed=417087KB) (malloc=27699KB #650) (mmap: reserved=389388KB, committed=389388KB) -
Compiler (reserved=779KB, committed=779KB) (malloc=648KB #1797) (arena=131KB #18) -
Internal (reserved=1729717KB, committed=1729717KB) (malloc=1729685KB #79138) (mmap: reserved=32KB, committed=32KB) -
Symbol (reserved=27077KB, committed=27077KB) (malloc=24416KB #216304) (arena=2661KB #1) -
Native Memory Tracking (reserved=6055KB, committed=6055KB)
(malloc=459KB #6453)
(tracking overhead=5596KB) -
Arena Chunk (reserved=228KB, committed=228KB) (malloc=228KB)
堆外内存占用很少,远远达不到TaskManager进程占用的大小。
因为 NMT 不会追踪 native (C/C++ 代码)申请的内存,如压缩解压部分,到这里基本已经怀疑是 native 代码导致的。
4.2 使用jemalloc分析内存分配情况
分析代码无果,决定使用内存分析工具来分析一下到底是什么占用这么多内存。
找到了一篇文档,如下:
https://www.evanjones.ca/java-native-leak-bug.html
4.2.1 安装和配置 jemalloc
./configure --enable-prof
make
make install
然后在/etc/profile中配置一下:
export LD_PRELOAD=/usr/local/lib/libjemalloc.so
备注:
如果要生成分析文件需要多加一条配置:
export MALLOC_CONF=“prof:true,prof_prefix:/home/bigdata/jeprof.out,lg_prof_interval:30,lg_prof_sample:20”
参数 lg_prof_interval:30,其含义是内存每增加 1GB(2^30,可以根据需要修改,这里只是一个例子),就输出一份内存 profile。这样随着时间的推移,如果发生了内存的突然增长(超过设置的阈值),那么相应的 profile 一定会产生,那么我们就可以在发生问题的时候,根据文件的创建日期,定位到出问题的时刻,内存究竟发生了什么样的分配
执行source /etc/profile
4.2.2 测试内存
4节点的集群,为其中两台配置了jemalloc,另外两台不变。
重新启动flink集群,开始跑批处理作业,跑了几轮之后发现了异常情况。
如下图所示:其中两台节点配置了jemalloc,另外两台仍旧使用Linux默认的ptmalloc。跑了几个任务之后其中打开jemalloc节点的TaskManager内存占用非常正常,内存暴涨之后,待任务结束就能降下来。但是使用glibc malloc的节点的TaskManager内存一直上涨。
联想到jemalloc的一个特征就是可以减少内存碎片,查了下资料,发现是glibc内存碎片导致的假性内存OOM。
5、Glibc内存管理
参考资料:
https://yuhao0102.github.io/2019/04/24/%E7%90%86%E8%A7%A3glibc_malloc_%E4%B8%BB%E6%B5%81%E7%94%A8%E6%88%B7%E6%80%81%E5%86%85%E5%AD%98%E5%88%86%E9%85%8D%E5%99%A8%E5%AE%9E%E7%8E%B0%E5%8E%9F%E7%90%86/
https://zhuanlan.zhihu.com/p/452291093
目前开源社区公开了很多现成的内存分配器(Memory Allocators,以下简称为分配器):
- dlmalloc – 第一个被广泛使用的通用动态内存分配器;
- ptmalloc2 – glibc 内置分配器的原型;
- jemalloc – FreeBSD & Firefox ,脸书所用分配器;
- tcmalloc – Google 贡献的分配器;
- libumem – Solaris 所用分配器;…
Linux 的早期版本采用 dlmalloc 作为它的默认分配器,但是因为 ptmalloc2 提供了多线程支持,所以 后来 Linux 就转而采用 ptmalloc2 了。多线程支持可以提升分配器的性能,进而间接提升应用的性能。
在 dlmalloc 中,当两个线程同时 malloc 时,只有一个线程能够访问临界区(critical section)——这是因为所有线程共享用以缓存已释放内存的「空闲列表数据结构」(freelist data structure),所以使用 dlmalloc 的多线程应用会在 malloc 上耗费过多时间,从而导致整个应用性能的下降。
5.1 内存管理结构
在 ptmalloc2 中,当两个线程同时调用 malloc 时,内存均会得以立即分配——每个线程都维护着单独的堆,各个堆被独立的空闲列表数据结构管理,因此各个线程可以并发地从空闲列表数据结构中申请内存。这种为每个线程维护独立堆与空闲列表数据结构的行为就「per thread arena」。
在glibc malloc中主要有 3 种数据结构,分别是:
- malloc_state ——Arena header—— 一个 thread arena 可以维护多个堆,这些堆另外共享同一个 arena header。Arena header 描述的信息包括:bins、top chunk、last remainder chunk 等;
- heap_info ——Heap Header—— 一个 thread arena 可以维护多个堆。每个堆都有自己的堆 Header(注:也即头部元数据)。什么时候 Thread Arena 会维护多个堆呢? 一般情况下,每个 thread arena 都只维护一个堆,但是当这个堆的空间耗尽时,新的堆(而非连续内存区域)就会被 mmap 到这个 aerna 里;
- malloc_chunk ——Chunk header—— 根据用户请求,每个堆被分为若干 chunk。每个 chunk 都有自己的 chunk header。
其中arena管理结构如下所示:
每一个arena都被malloc_state管理,malloc_state中包含了bins,toptrunk等重要信息
struct malloc_state
{
/* Serialize access. */
__libc_lock_define (, mutex);
/* Flags (formerly in max_fast). */
int flags;
/* Set if the fastbin chunks contain recently inserted free blocks. */
/* Note this is a bool but not all targets support atomics on booleans. */
int have_fastchunks;
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
/* Linked list */
struct malloc_state *next;
/* Linked list for free arenas. Access to this field is serialized
by free_list_lock in arena.c. */
struct malloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on
the free list. Access to this field is serialized by
free_list_lock in arena.c. */
INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};
注意:
- Main arena 无需维护多个堆,因此也无需 heap_info。当空间耗尽时,与 thread arena 不同,main arena 可以通过 sbrk 拓展堆段,直至堆段「碰」到内存映射段;
- 与 thread arena 不同,main arena 的 arena header 不是保存在通过 sbrk 申请的堆段里,而是作为一个全局变量,可以在 libc.so 的数据段中找到。
上述内存结构可以通过命令查看,如
使用pmap -x pid 查看内存的分布情况,发现有很多64M左右的内存区域,如图所示
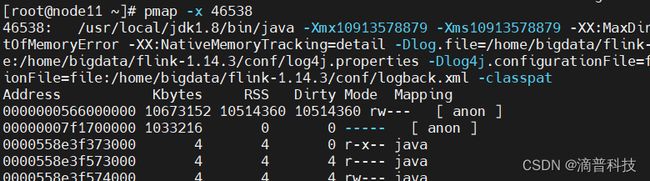
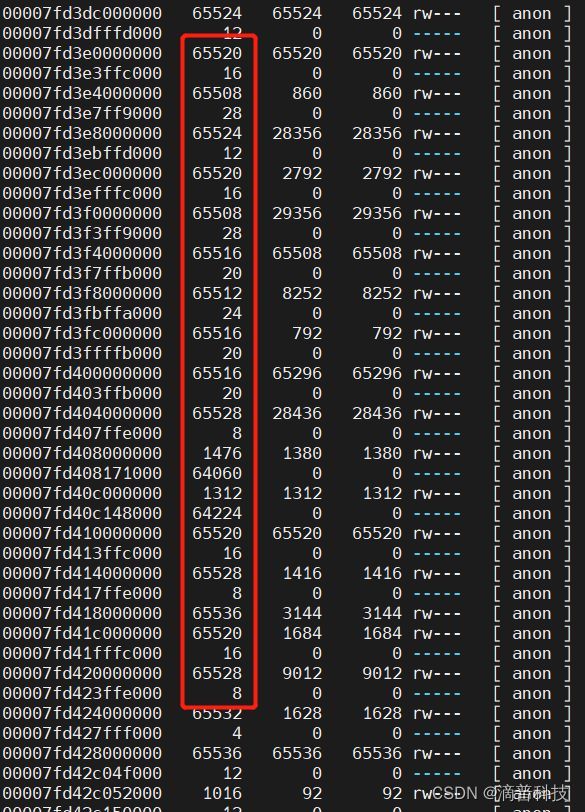
5.2 内存分配过程
Linux下内存管理是由glibc库来与内核交互,即用户空间是通过glibc来进行的系统调用。glibc提供两种方式来申请内存,分别是brk和mmap,当通过malloc/new申请的内存小于M_MMAP_THRESHOLD(缺省128K)时,glic调用brk来申请内存,当要申请的内存大于M_MMAP_THRESHOLD时,glibc调用mmap来申请内存。这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
当调用 malloc 分配内存的时候,会先查看当前线程私有变量中是否已经存在一个分配区 arena。如果存在,则尝试会对这个 arena 加锁
如果加锁成功,则会使用这个分配区分配内存
如果加锁失败,说明有其它线程正在使用,则遍历 arena 列表寻找没有加锁的 arena 区域,如果找到则用这个 arena 区域分配内存。
当调用 free 接口释放内存时,会根据一定的策略缓存起来,或者返还系统。
因为 ptmalloc2 本来就是一个内存池,为了提高内存分配效率,避免用户态和内核态频繁进行交互,它需要通过一些策略,将部分用户释放(delete/free)的内存缓存起来,不马上返还给系统。而缓存起来的内存块,通过 fastbinsY 和 bins 这些数组维护起来,数组保存的是空闲内存块链表。
top 这个内存块指向 top chunk,它对于理解 glibc 从系统申请内存,返还内存给系统有着关键作用。
下图时一个内存分配过程,brk是将数据段(.data)的最高地址指针_edata往高地址推,完成虚拟内存分配;而通过mmap系统调用分配的内存是在堆和栈的中间空闲地址分配一块虚拟内存,这样释放时可以不受约束地自由释放。这样通过brk分配的内存是连续的一块空间,如下图中依次brk申请ABD内存,释放的时候,若高地址的内存不释放,低地址的内存是不能释放的,如下图(7);而mmap申请的内存可以自由释放,如下图(6)。
参考:https://blog.csdn.net/u013259321/article/details/112031002


当通过brk释放的内存相邻的加起来达到M_TRIM_THRESHOLD(缺省128K)时,会进行内存紧缩,如下图,先释放B,B的内存并没有真正释放,再释放D时,B+D>128K,此时这一块内存组就会释放掉。

上述如图7所示就出现了内存碎片也叫内存空洞,就是这个导致了操作系统假性OOM。
5.3 内存碎片规避办法
glibc管理的内存唯一释放的条件是堆顶存在128k(M_TRIM_THRESHOLD)或以上的空闲区时才会释放,比如上图中只有D才有被归还系统的可能,B就老老实实成为内存空洞,虽然未来的分配还能用到,但释放不掉。
而有些32位条件下工作很好的程序,但是到64位后,这个阈值变大的原因(而物理内存其实并没有增大很多),因为总是到不了这个threshold,而总是有新的分配摞上来,这样就失去了释放的机会。
一般来说,通常的经验是
(1)glibc管理的内存绝大多数情况不会释放。因此编程时如果是小内存分配要尽快使用,尽快用完,尽快释放,不要停留,否则一直摞着,线性地址后面的就形成了空洞。
(2)如果是想内存总在控制中,可以分配大内存,自行管理释放和分配。不用的时候可以释放地很干净
(3)不要分配很小的内存比如几个字节,因为一次malloc至少分配16个字节,如果每次分配都很小,就太亏了。
(4)降低M_MMAP_THRESHOLD,可以让更多的分配走mmap,避免brk得总总问题,特别是64位机器的情况下。
(5)降低M_TRIM_THRESOLD,让堆顶的空闲内存更容易释放。
(6)定时调用malloc_trim()方法,将碎片的物理内存释放掉,等真正访问的时候,再触发缺页中断。
以上(4)(5)(6)都不可避免会增加系统缺页中断,影响系统性能,使用中需要慎重。
6、对比测试:
一共进行4轮测试,分别如下:
- Linux默认的glibc malloc
- 配置MALLOC_MMAP_THRESHOLD_=8092
- 配置MALLOC_ARENA_MAX = 4
- 安装配置jemalloc
不同模式分别跑15次批处理,开始测试之前内存使用情况:
6.1 Glibc malloc测试
任务结束后,TM内存直接暴涨到60%
6.2 修改MALLOC_ARENA_MAX值
任务结束后,TM内存直接涨到36%,再跑就不再上涨
export MALLOC_ARENA_MAX=4
6.3 修改内存缓存池分配阈值
export MALLOC_MMAP_THRESHOLD_=8192
任务结束后,内存控制的最好,TM内存维持在20%+,平均速度稍微慢一点
6.4 jemalloc测试
需要安装jemalloc,但是性能最佳
任务结束后,内存控制的好,TM内存维持在20%+,平均速度非常好
7、结论
经过对比可以看到jemalloc性能和内存使用情况最优,但是稳定性需要测试一下海量数据的处理。
8、备注
可以使用三种方式来解决这种由于碎片太多导致系统OOM的问题:
8.1 配置jemalloc
- 下载 jemalloc https://github.com/jemalloc/jemalloc
- 解压 tar -xjvf jemalloc-5.2.1.tar.bz2
- 生成makefile文件 ./configure --enable-prof
- make
- make install
- 配置环境变量/etc/profile中
export LD_PRELOAD=/usr/local/lib/libjemalloc.so
export MALLOC_CONF=“prof:true,prof_prefix:/home/bigdata/jeprof.out,lg_prof_interval:30,lg_prof_sample:20”
- source /etc/profile
- 启动flink集群
8.2 修改内存分配参数
- 在/etc/profile文件中配置 export MALLOC_MMAP_THRESHOLD_=8192
- 然后source /etc/profile
- 启动flink集群
该值默认的大小为128k,当申请的内存小于128k时,使用brk方式申请内存,free之后并不会立即释放,而是管理起来做内存池,大于128k时,使用mmap方式申请内存,free掉之后会立即还给操作系统
最优解需要根据实际情况进行测试。
备注:
既然堆内碎片不能直接释放,导致疑似“内存泄露”问题,为什么 malloc 不全部使用 mmap 来实现呢(mmap分配的内存可以会通过 munmap 进行 free ,实现真正释放)?而是仅仅对于大于 128k 的大块内存才使用 mmap ?
其实,进程向 OS 申请和释放地址空间的接口 sbrk/mmap/munmap 都是系统调用,频繁调用系统调用都比较消耗系统资源的。并且, mmap 申请的内存被 munmap 后,重新申请会产生更多的缺页中断。例如使用 mmap 分配 1M 空间,第一次调用产生了大量缺页中断 (1M/4K 次 ) ,当munmap 后再次分配 1M 空间,会再次产生大量缺页中断。缺页中断是内核行为,会导致内核态CPU消耗较大。另外,如果使用 mmap 分配小内存,会导致地址空间的分片更多,内核的管理负担更大。 同时堆是一个连续空间,并且堆内碎片由于没有归还 OS ,如果可重用碎片,再次访问该内存很可能不需产生任何系统调用和缺页中断,这将大大降低 CPU 的消耗。 因此, glibc 的 malloc 实现中,充分考虑了 sbrk 和 mmap 行为上的差异及优缺点,默认分配大块内存 (128k) 才使用 mmap 获得地址空间,也可通过 mallopt(M_MMAP_THRESHOLD, ) 来修改这个临界值。
8.3 修改MALLOC_ARENA_MAX
- 在/etc/profile文件中配置 export MALLOC_ARENA_MAX=4
- 然后source /etc/profile
- 启动flink集群
调试MALLOC_ARENA_MAX的数字就是在效率和内存消耗之间做选择. 使用默认的MALLOC_ARENA_MAX能获得最佳效率, 但是可能消耗更多的内存. 减少MALLOC_ARENA_MAX能减少内存使用, 但是效率可能稍微低一些.
9、名词解释
jemalloc:
jemalloc 是由 Jason Evans 在 FreeBSD 项目中引入的新一代内存分配器。它是一个通用的 malloc 实现,侧重于减少内存碎片和提升高并发场景下内存的分配效率,其目标是能够替代 malloc。jemalloc 应用十分广泛,在 Firefox、Redis、Rust、Netty 等出名的产品或者编程语言中都有大量使用。具体细节可以参考 Jason Evans 发表的论文 《A Scalable Concurrent malloc Implementation for FreeBSD》
tcmalloc:
tcmalloc 出身于 Google,全称是 thread-caching malloc,所以 tcmalloc 最大的特点是带有线程缓存,tcmalloc 非常出名,目前在 Chrome、Safari 等知名产品中都有所应有。tcmalloc 为每个线程分配了一个局部缓存,对于小对象的分配,可以直接由线程局部缓存来完成,对于大对象的分配场景,tcmalloc 尝试采用自旋锁来减少多线程的锁竞争问题。
ptmalloc:
ptmalloc 是基于 glibc 实现的内存分配器,它是一个标准实现,所以兼容性较好。pt 表示 per thread 的意思。当然 ptmalloc 确实在多线程的性能优化上下了很多功夫。由于过于考虑性能问题,多线程之间内存无法实现共享,只能每个线程都独立使用各自的内存,所以在内存开销上是有很大浪费的。
10、参考文档
https://yuhao0102.github.io/2019/04/24/%E7%90%86%E8%A7%A3glibc_malloc_%E4%B8%BB%E6%B5%81%E7%94%A8%E6%88%B7%E6%80%81%E5%86%85%E5%AD%98%E5%88%86%E9%85%8D%E5%99%A8%E5%AE%9E%E7%8E%B0%E5%8E%9F%E7%90%86/
https://zhuanlan.zhihu.com/p/452291093