提示学习概述【入门总结看这个就够了】
为什么需要提示学习
PLM+Finetuning 形式的缺陷
模型在做预训练的时候,采用的任务形式:自回归、自编码,与下游的任务形式存在较大的差别

(例如预训练模型训练的mask训练头是无法应用到下游任务上的CLS训练头)
因此需要较多的数据来适应新的形式,需要将预训练模型从最初的预训练能力(学习惯性)扭转到全新的下游任务上,所以会丧失预训练模型上已经学习到的能力。因此在微调模型上少样本学习能力差/容易过拟合。
预训练模型参数数量极大,为了一个特定任务去fine-tuning一个模型,然后去部署,会造成部署资源的极大浪费

PLM+Fine-tuning形式缺陷总结
1. 零样本/少样本学习能力差
2. 模型专用性导致成本高昂的大规模预训练模型,无法通用到不同任务。
所以针对这么缺陷,我们希望能有一个范式可以利用预训练模型学习到的知识(和预训练模型的训练形式大致相关),且做到部分通用性,finetuning的部分减少。
什么是提示学习?
预训练模型本身具有少样本学习能力
GPT-3提出的 In-Context Learning,有效证明了在零样本、少样本场景下,模型不需要更新任何参数,能够实现不错的效果。

上例为GPT-3模型
首先先给出任务描述:Translate English to French
然后给出少量例子,相当于告诉机器任务范式,提示机器按某种范式进去预测
最后进行预测
提示学习的本质
1. 将所有下游任务统一为预训练任务
2. 以特定的模板,将下游任务的数据组装成自然语言的形式,充分挖掘预训练模型本身的能力。
提示学习的形式
实验中采用预测mask的预训练模型
以电影评论情感分类任务为例,模型需要根据输入的句子做二分类模型:
原始输入:特效非常炫酷,我很喜欢。
根据预训练模型构造Prompt输入
特效非常炫酷,我很喜欢。这是一部[MASK]电影
然后Prompt输入
PLM模型会将mask预测为词表中的各个词的概率。
预训练模型的词表数量很大,我们有时候不需要关注那么多词。比如在这个例子中我们可能只需要关注mask预测出来的是“好"还是”坏“(关注对分类有效的词,可以是多个词)。
所以引入了类别映射(Verbalizer)的概念。类别映射就是将我们所关注的词映射为二分类问题中的两个类别[“好”--“positive”,“坏”—“negative”]

如上图,此时”好“的概率要高于”坏“的概率,所以将分类映射到”positive“,以此完成一次预测。
提示模板的作用在于:将训练数据组装成自然语言的形式,并在合适位置[mask],以激发预训练模型的能力。
类别映射/Verbalizer:选择合适的预测词,并将这些词对应到不同的类别
下图是类别映射的一个例子:
比如判断两个句子关系的三分类问题(entailment、neutral、contradiction)
构造问答形式的prompt输入:v1(句子1)?[MASK],v2(句子2)

经典提示学习方法
硬模板
硬模板-Pattern Exploiting Training
PET是一种较较为经典的提示学习方法,和之前的举例一样,将问题建模成一个完形填空问题,然后优化最终的输出词.
虽然PET 也是在优化整个模型的参数,但是相比于传统的 Fine tuning方法,对数据量需求更少

具体PET模型的介绍,可以参考我之前对PET论文的讲解Prompt-Tuning的鼻祖--PET
硬模板 LM-BFF
陈天琦团队的工作,在基础的 Prompt Tuning 基础上,提出了Prompt Tuning with Auto Prompt Generation
论文地址:Making Pre-trained Language Models Better Few-shot Learners

该方法在原有prompt-learning的基础上,通过构造模板,对于每一个类别都加入一个例子来帮助机器更好地学习,告诉机器[MASK]上值的发展方向。
硬模板方法的缺陷
硬模版的产生依靠两种方式:根据经验的人工设计&自动化搜索。但是,人工设计的不一定比自动搜索的好,自动搜索的可读性和可解释性也不强。
通过evaluate测试自动搜索产生的模板可能语句不通,没有具体含义(只是评分较高),且硬模板较为脆弱(稍加修改,准确率差距很大,如三四列)

针对这些缺陷,有研究提出放弃硬模板,去优化prompt token embeding
软模版
P tuning
不再设计/搜索硬模板,而是在输入端直接插入若干可被优化的 Pseduo Prompt Tokens(伪提示词):
1. 不依赖人工设计
2. 要优化的参数极少,避免了过拟合(当然,也可以全量微调,退化成finetuning)
论文地址:GPT Understands, Too

输入伪提示词![]() ,通过[MASK]的loss 去更新prompt encoder的参数,而不去finetune预训练语言模型的参数。因此原始预训练模型不需要变化,只需要针对不同的模型训练不同的 prompt encoder即可。可以将prompt encoder 输出的不同任务prompt token embedding保存下来,在做相应任务的时候直接调用。所以相应的预训练语言模型在软模版的任务中就具有了通用性,不同任务需要改变的就只是prompt token embedding。
,通过[MASK]的loss 去更新prompt encoder的参数,而不去finetune预训练语言模型的参数。因此原始预训练模型不需要变化,只需要针对不同的模型训练不同的 prompt encoder即可。可以将prompt encoder 输出的不同任务prompt token embedding保存下来,在做相应任务的时候直接调用。所以相应的预训练语言模型在软模版的任务中就具有了通用性,不同任务需要改变的就只是prompt token embedding。
【可以有保留输入】:
例如:
硬模板中的输入 The capital of Britain iss [MASK]
软模版中的输入 ![]() captital Britain
captital Britain ![]() [MASK]
[MASK]
此时 Britain和capital就是保留输入,由人工指定输入。
软模版能够很好的克服MLM+Finetuning结构模型的两个弊端,实现:
1. 小样本/零样本模型效果佳
2. 模型具有一定的通用性
Prefix tunning
P-tuning更新Prompt token embedding的方法,能够优化的参数较少。Prefix tunning希望能够优化更多的参数,提升效果,但是又不带来过大的负担。
论文地址:Prefix-Tuning: Optimizing Continuous Prompts for Generation

所以相比于P-tuning只优化input层,prefix tuning希望优化每一层的(例如BERT 12层)的prompt token embedding,而不仅仅是输入层。该方法下可优化的参数更多,从实验效果看来确实比P-tunning更好。
Soft Prompt Tuning
Soft Prompt Tuning系统验证了软模板方法的有效性,并且提出:固定基础模型,有效利用任务特定的SoftPrompt Token,可以大幅减少资源占用,达到大模型的通用性。
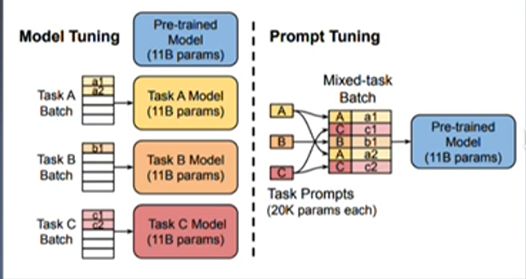
如图所示
图左为传统的MLM+Finetuning结构,同一个预训练模型针对于不同的任务,分别需要训练出不同的模型。
图右为Prompt tuning,只需要给不同的任务训练不同的prompt token embedding,然后输入数据拼接后输入预训练模型即可。特别有意思的是,虽然是不同的任务,输入时所给的prompt token embedding不同,预训练模型就会根据软提示的不同,在同一个batch里执行不同的训练任务
总结
Prompt Learning的组成部分
1.提示模版:根据使用预训练模型,构建完形填空 or基于前缀生成两种类别的模版
提示模版-1特效非常炫酷,我很喜欢。这是一部[MASK] 电影
提示模版-2特效非常炫酷,我很喜欢。这部电影很[MASK]
2. 预训练语言模型
3.类别映射/Verbalizer:根据经验选择合适的类别映射词
典型的 Prompt Learning方法
1.硬模版方法:人工设计/自动构建基于离散token的模版
a. PET
b. LM-BFF
2.软模版方法:不再追求模版的直观可解释性,而是直接优化 Prompt Token Embedding
a. P-tuning
b. Prefix Tuning