Machine Learning(Lesson2 一个完整的机器学习项目)
文章目录
-
- 引言
- 项目
-
- 项目概览
- 划定问题
- 性能指标
- 开始写代码了
-
- 看一下数据
- 特征工程
- 创建训练集、测试集
- 准备训练用的数据
- 自定义转换器(打包数据清洗过程)
- 模型训练
- 参数测试
- 结束
- 作业(你可以现在去,也可以再学学去)
引言
这一章的学习是最基础也是最重要的一个章节,一定要好好跟着做,就算你不一个个跟着敲代码,也至少确保每行代码都成功运行了,并得到了最终的结果。
对于很多人来说,机器学习只是一个工具,并不需要在乎他的实现原理,那么可能上完这节课也就够了。这节课会完完整整的带你进行一个机器学习项目。无论后面使用什么算法进行机器去学习,充其量也只不过是换一个函数的问题,大致了解一下有哪些流行的模型,适合什么问题,然后套进本节课的框架里,你就可以和别人说可以独立完成一个机器学习项目了,当然这对于学习来说是远远不够的。但是无论如何,至少这节课能让你第一次体验到使用机器学习的快乐(bushi
整个项目分为以下这些:
- 项目概述。
- 获取数据。
- 发现并可视化数据,发现规律。
- 为机器学习算法准备数据。
- 选择模型,进行训练。
- 微调模型。
- 给出解决方案。
- 部署、监控、维护系统。
本项目使用的数据集是90年的加州房价数据集,你可以到我第一节课提供的地址去下载教材,教材配套的所有代码和数据集都在教材里的下载链接里。如果懒的人我再次推荐使用Kaggle,直接在自带的notebook里面选择Add data,就可以直接搜索到数据集了。

项目
我这里都非常简洁,想好好学认真读书,在我这里过的比较快,我不会把它的内容大段复制过来,只提一些我想提醒你们注意的。
项目概览
本项目的数据集是加州的房价,我们需要通过房子的特征来预测出某个街区房价的中位数。
划定问题
第一部分是从项目角度来思考的,我倒觉得这没什么好教的,真正做项目的时候这些问题自然而然都会摆到你的面前。一般来来说我觉得就三点的平衡,精度、速度、成本。
精度:比如说你预测房价,预测的准不准肯定是最关键的,要是预测的还没有你自己估计的准,那你这个模型一点价值都没有。
速度:对于房价预测来说,我觉得对检测速度没有太大的要求
成本:成本总是老板最需要考虑的部分,成本其实还是挺复杂的,包括了很多内容。想要精度提升,通常需要更复杂的模型,更大的数据量。想要速度提升,那就得堆显卡。成本不仅仅是钱,一般来说比起模型而言,数据集的收集更为重要,那耗费的可能就是人力资源。再比如说做过芯片设计的人都知道,有一个东西叫空间成本,你的模型很多时候需要在嵌入式平台跑,需要保证在一定的体积下能进行计算,你不可能给你的单片机接一块巨大的3090,这时候就要思考怎么解决,比方说把模型在线部署到服务器上,采用在线检测之类的方法。
反正这些你在真正用起来的时候就会明白了,不用的话说了也没这种感受。
好了后面才是你要考虑的
你需要划定问题:监督或非监督,还是强化学习?这是个分类任务、回归任务,还是其它的?要使用批量学习还是线上学习?继续阅读之前,请暂停一下,尝试自己回答下这些问题。
数据都是包含房价的,有表情,监督学习。
任务是预测问题,多变量回归问题。
批量还是线上,跟数据量有关,其实这方面我也不太懂,因为没有实际接触过,可能要接触了真实的案例才会有感觉。
性能指标
性能指标就是一个算式,把你模型预测的数据和真实数据对比,计算出来一个值来给你的模型打分。
这里选择RMSE(均方根误差),应该是应用最广泛的指标,就是计算标准差。如果你学过概率论与数理统计,应该知道中心极限定理吗,如果每个特征都是独立分布(互相没关系),那么数据应该是呈高斯分布的(大约68%的值落在 1σ 内,95% 的值落在 2σ 内,99.7%的值落在 3σ 内)。
就是说,你的模型计算出来的σ越小,说明你预测的越准。
后面会介绍其他的指标,这里的RMSE从几何层面去理解,其实就是超空间(高维空间,就是由特征组成的特征空间)的欧氏距离(就是我们最常见的距离)。你也可以使用一维的曼哈顿距离,就是坐标差的和。
(1,1)和(2,2)欧氏距离根号2,哈密顿距离(2-1)+(2-1)=2
你预测出来的点和真实点越近,说明预测的越准,很直观吧。你要是想,也可以用三四阶距离,不过不常用。
怎么说呢,指标一般靠经验和尝试。但是我感觉某个指标能表现的很好,他在这个问题里面具有实际意义。(当然我是想不出来,就有这种感觉)
开始写代码了
自己配置环境,懒的话Kaggle的notebook直接上
这里给一下它获取数据的代码,但你不有可能下载数据失败
这里第一次出代码,说一下,我看着代码我也有些不知道的用法,去查,比方说six.moves是什么,我查了一下是为了兼容python2和3,six可能因为是23的最小公倍数。
就算遇到很长的代码,一行行去看,没啥看不懂的。然后英文好点的话,其实很多函数名都写得很清楚。
import os
import tarfile
from six.moves import urllib
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH = "datasets/housing"
HOUSING_URL = DOWNLOAD_ROOT + HOUSING_PATH + "/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
看一下数据
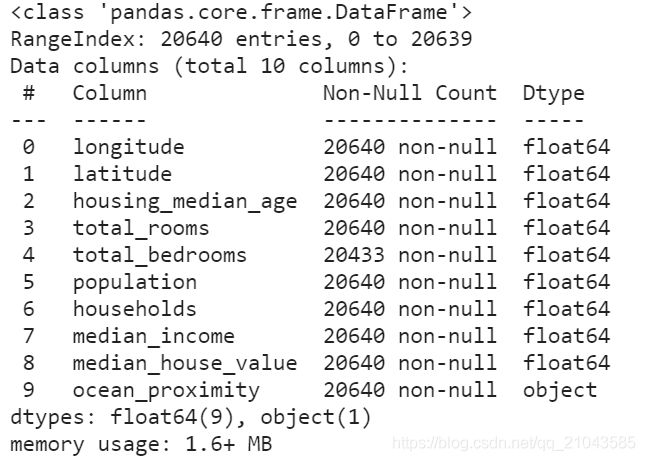
每一行都表示一个街区。共有 10 个属性(截图中可以看到 6 个):经度、维度、房屋年龄中位数、总房间数、总卧室数、人口数、家庭数、收入中位数、房屋价值中位数、离大海距离。
housing = pd.read_csv('../input/california-housing-prices/housing.csv')
housing.head() #查看前五条信息

通过housing.info()查看一下总体情况, 数据集中共有 20640 个实例,按照机器学习的标准这个数据量很小,但是非常适合入门。我们注意到总房间数只有 20433 个非空值,这意味着有 207 个街区缺少这个值。我们将在后面对它进行处理。
housing.info() #看一下总体数据
还有很多其他方式查看数据(书上比较详细),比方说查看数值数据的平均数、中位数的数字特征,而对于字符数据则需要分类(有的时候会有文本数据,图片数据,处理起来就更加丰富多彩了)。
另外,单看表格是看不出来什么的,需要掌握一点数据可视化的技能,最简单的比如matplotlib,绘制一点简单的图表,可以更好地发现数据的规律。
特征工程
前面看一下数据那部分,东西有点多,但是是重中之重,一定要跟着书好好看。
但是有些东西只是让你稍微看了看,给你一点感觉和提示,后面也并没有实际处理。比方说他通过经纬度将地图可视化了出来,但是在后面并没有进行具体的操作,甚至直接将经纬度作为数值参数丢入了模型,我觉得是不太合理的,应该通过分类的手段(后面学习)将地图进行划分,结合人口密度之类的信息(因为是真实数据就,可以附加其他的数据,距离海岸线的远近这种)对地点进行分组,作为参数。
另外还有特征的缩放,你参加了两次考试,一次满分100分,一次满分10分。你把两个分数直接加起来反应我的综合实力显然不合适。另外,如果两次考试一次是小测验,另一次是期末考试,两个分数我觉得占的比例是不同的,需要增加权重。
诸如这些操作就是所谓的特征工程,书上并没有花很多功夫介绍特征工程,后面只有最简单的特征缩放。这应该是单独作为一门课去学习的内容(比方说你想打数据分析竞赛或者从事相关行业)。当然,现在我们都只是初学者,可以把这部分先放一放,先熟练工具,但是如果感兴趣的话可以自己直接就试试看,看看你会不会魔法。
创建训练集、测试集
简单的来说,就是一部分数据用来训练一部分用于验证,一般来说是8比2。要注意一旦验证集被划分了出去,就不要再动他了,看都不要看。为的是用
书上在这里讲了很多,总结一下是在划分数据集要注意几个问题:要随即划分(具体实现可能使用hash算法),代码多次运行数据集的划分不能乱(要保证训练集和测试集不能混在一起),有新的数据进来的时候仍然要保持数据集不乱(要保证有序,不能把训练集数据测试集或者反过来)。
但是一般来说,划分完数据集之后,我们就直接把他们分开保存成文件了,也不太会有那么麻烦。
#用sklearn自带的工具进行划分
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
当数据分布不均匀的时候,可能不能直接随机抽样,比如说数据集中男女比例是6:4,那划分后的数据集也应该保证这个比例,
#对数据集进行划分(采样),保证比例相同
#split.split(dataset,需要保证比例的对象)
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42) #n_splits就是分成几对训练集-数据集
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
准备训练用的数据
不会pandas的请先学习pandas
前面已经提到过了,我们拿到的数据是需要经过清洗的,数据集中可能有很多NAN(空值),还有非数字的特征,也有特征之间比例不均衡的问题。
所以,在放入模型训练之前,我们一定要对模型进行清洗。
- 分离标签
标签就是需要预测结果,肯定能作为训练集
housing = strat_train_set.drop("median_house_value", axis=1)
housing_labels = strat_train_set["median_house_value"].copy()
- 处理空数据
用平均值/中位数代替,或者直接删除
#数据清洗,删除没有的数据
housing.dropna(subset=["total_bedrooms"]) # 删除没有数据的那一行
housing.drop("total_bedrooms", axis=1) # 直接删除数据不全的一列
median = housing["total_bedrooms"].median()
housing["total_bedrooms"].fillna(median) # 用平均值代替
X = imputer.transform(housing_num) #中位数替换,结果是一个numpy数组
housing_tr = pd.DataFrame(X, columns=housing_num.columns)
- 文字标签处理
文字不能直接作为训练数据,要用数学手段进行替换,最简单的想法就是用1 2 3 4代替,但是直接代替的话,会加入原本并不存在的数学特征(大小关系和运算关系)。
最常用的手段是使用独热编码(onehotencoder),将标签转为一个向量。比如猫狗鼠,猫就是[1,0,0],狗就是[0,1,0],老鼠就是[0,0,1]。这种编码方式可以在保留原本特征的情况下不引入错误的数学特征。
PS:如果不是简单的标签,而是长文本的话就需要其他手段了,比方说word2sequence,用向量代替文本,这种处理手段使得文本之间也获得了数学运算的性质。
# 一步完成转换onehot编码
import category_encoders as ce # in future versions of Scikit-Learn
cat_encoder = ce.OneHotEncoder()
housing_cat_reshaped = housing_cat.values.reshape(-1, 1)
housing_cat_1hot = cat_encoder.fit_transform(housing_cat_reshaped)
housing_cat_1hot.to_numpy()
- 特征缩放(标准化、归一化)
前面提过特征缩放了,就是让不同特征对预测的影响均衡。
标准化就是把所有特征都映射到0-1之间,具体的映射方法有最简单的线性映射(最小值作为0,最大值作为1,中间均分),也有其他的方式,可以自己去研究。
归一化则使得数据全局减去平均值,然后除以方差,数据变为标准正态分布。那么归一化有什么作用呢?。例如,假设一个街区的收入中位数由于某种错误变成了100,归一化会将其它范围是 0 到 15 的值变为 0-0.15,但是标准化不会受什么影响。
自定义转换器(打包数据清洗过程)
什么是转换器呢?前面用平均值填充空白数据,把文本数据转为独热编码都可以理解为转换器。转换器的作用就是把原始数据转换成可以扔给模型训练的工具。
sklearn提供了很多转换器,包括标准化、归一化,但是我们有时候也希望使用自己定义的转换器,比如说下面就是自定义的归一化转换器
# 自定义转换器
from sklearn.base import BaseEstimator, TransformerMixin # 继承的两个基类
rooms_ix, bedrooms_ix, population_ix, household_ix = 3, 4, 5, 6
#转换器
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room = True): # no *args or **kargs
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self # nothing else to do
def transform(self, X, y=None):
rooms_per_household = X[:, rooms_ix] / X[:, household_ix]
population_per_household = X[:, population_ix] / X[:, household_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household,
bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)
housing_extra_attribs = attr_adder.transform(housing.values)
housing_extra_attribs
另外,我们的数据处理过程通常需要经过一个又一个的转换器,这个过程就像流水线一样,sklearn提供了这种流水线机制,帮助我们把不同的转换器组合在一起。
from sklearn.base import BaseEstimator, TransformerMixin
class DataFrameSelector(BaseEstimator, TransformerMixin):
def __init__(self, attribute_names):
self.attribute_names = attribute_names
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.attribute_names].values
from sklearn.pipeline import FeatureUnion
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
num_pipeline = Pipeline([
('selector', DataFrameSelector(num_attribs)),
('imputer', Imputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
cat_pipeline = Pipeline([
('selector', DataFrameSelector(cat_attribs)),
('cat_encoder', ce.OneHotEncoder()),
])
full_pipeline = FeatureUnion(transformer_list=[
("num_pipeline", num_pipeline),
("cat_pipeline", cat_pipeline),
])
housing_prepared = full_pipeline.fit_transform(housing)
housing_prepared
模型训练
终于进入激动人心的模型训练过程了,各种不同的算法模型本身是很复杂的存在,不过这些都有前人帮我们写好了,我们只需要调用就行了,所以就算你什么都没学过也一样可以使用机器学习算法。
我们先来试试最简单的线性回归模型
# 线性回归模型
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)
some_data = housing.iloc[:5]
some_labels = housing_labels.iloc[:5]
some_data_prepared = full_pipeline.transform(some_data)
print("Predictions:\t", lin_reg.predict(some_data_prepared))
print("Labels:\t\t", list(some_labels))
---------------------------------------------------------------
Predictions: [210644.60459286 317768.80697211 210956.43331178 59218.98886849
189747.55849879]
Labels: [286600.0, 340600.0, 196900.0, 46300.0, 254500.0]
我们计算一下标准差,大约68%的数据落在一个标准差里,我们常用标准差评家一个模型的预测效果好不好。大多数数据位于120000到 265000 美元之间,标准差高达68628并不是一个很好的结果。为什么会这呢?因为线性回归模型对于这个预测问题太过简单了,出现了欠拟合的情况。
# 线性回归模型
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(housing_prepared)
lin_mse = mean_squared_error(housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_mse)
print(lin_rmse)
---------------------------------------------------------------
68628.19819848922
让我们来尝试一下其他模型
# 使用决策树模型
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor()
tree_reg.fit(housing_prepared, housing_labels)
housing_predictions = tree_reg.predict(housing_prepared)
tree_mse = mean_squared_error(housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_mse)
tree_rmse
---------------------------
0.0
均方误差变成了0,就是说我们现在的模型可以完美预测训练集中的数据,这说明我们的预测已经完美了吗,显然这是不可能的,造成这种情况的原因是模型严重过拟合了,如果使用训练集以外的数据测试,就完全丧失作用了。
由此可见,使用训练集本身去做验证是不合适的,我们需要使用交叉验证进行模型的评估。什么是交叉验证呢,就是把训练集分为为训练集和测试集,每次用训练集训练,测试集验证。我们可以使用sklearn提供的k折交叉验证去进行,它随机地将训练集分成十个不同的子集,成为“折”,然后训练评估决策树模型 10 次,每次选一个不用的折来做评估,用其它 9 个来做训练。结果是一个包含10个评分的数组.
这里评估分数采用的是均方误差的负数(neg_mean_squared_error),其他的可以看这个链接
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
rmse_scores = np.sqrt(-scores)
def display_scores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std())
display_scores(rmse_scores)
---------------------------
Scores: [69327.01708558 67430.64801927 70234.03094659 69516.91265994
71354.03636995 73414.81083178 70696.01708482 72123.50175018
75323.76675363 70567.14640818]
Mean: 70998.78879099092
Standard deviation: 2109.953161676695
显然,上面两个模型的表现效果都不算好,我们试试看其他模型,比如说随即森林模型(就是训练几棵使用部分特征的决策树,然后决策树投票出最终的结果,在后面课会仔细讲),你当然可以尝试一些其他模型,即便你不知道背后的原理,也可以测试一下什么模型的性能最好。
# 随机森林,训练时间大幅增加
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor()
forest_reg.fit(housing_prepared, housing_labels)
forest_scores = cross_val_score(forest_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
forest_rmse_scores = np.sqrt(-forest_scores)
display_scores(forest_rmse_scores)
------------------------------------
Scores: [49518.93649988 47601.12981233 49537.44334949 52152.80705027
49629.2986142 53296.7145367 48773.57110583 48127.6209621
52852.29323938 50057.90410063]
Mean: 50154.77192708145
Standard deviation: 1864.1244749532773
可以看到随即森林模型在这个训练集上比上面两个模型都有更好的表现。
参数测试
上面的代码中所有的模型都没有设置参数,由于sklearn提供了良好的默认参数,还是可以得到不错的效果。但是,对于不同任务来说,肯定不存在某个适用于所有情况的参数,为了使模型有最好的效果,我们需要测试不同的参数组合,以获得最好的效果。
sklearn提供了网格搜索工具,就是把你需要测试的参数列成表格,测试所有的组合,显然这非常耗费计算量,如果你的不希望耗费太多时间,也可以使用随即搜索。
from sklearn.model_selection import GridSearchCV
param_grid = [
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
] #是一个字典的列表,每个字典包括了几个要测试的参数以及候选值
forest_reg = RandomForestRegressor()
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error')
grid_search.fit(housing_prepared, housing_labels)
然后,你就会获得最佳的参数以及该参数下的模型
grid_search.best_params_
grid_search.best_estimator_
---------------------------
{'max_features': 8, 'n_estimators': 30}
RandomForestRegressor(max_features=8, n_estimators=30)
结束
好了,我们已经获得了一个训练好的模型,我们来看看他的效果
# 每个属性的重要性
feature_importances = grid_search.best_estimator_.feature_importances_
extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"]
# cat_one_hot_attribs = list(cat_encoder.feature_names) #我这里用的ce的onbehotencoder
cat_one_hot_attribs = list(housing_categories) #我这里用的ce的onbehotencoder
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(feature_importances,attributes), reverse=True)
# 最后三个数据其实可以丢掉了
----------------------------------
[(0.36654000485682237, 'median_income'),
(0.1535359612291148, 'INLAND'),
(0.108032207427434, 'pop_per_hhold'),
(0.07184005873864276, 'bedrooms_per_room'),
(0.07181935374615658, 'longitude'),
(0.06458620800432796, 'latitude'),
(0.048566023682625255, 'rooms_per_hhold'),
(0.04403229974763755, 'housing_median_age'),
(0.01609612394382148, 'population'),
(0.014893104300927527, 'total_bedrooms'),
(0.014734866482597347, 'total_rooms'),
(0.014634117525336334, 'households'),
(0.0058337257976848154, '<1H OCEAN'),
(0.0028788714167978413, 'NEAR OCEAN'),
(0.0019193777077431832, 'NEAR BAY'),
(5.7695392330197195e-05, 'ISLAND')]
通过feature_importances_可以看到不同特征对参数的重要程度,像最后三个特征对模型影响非常小,甚至可以忽略。
最后的最后,我们把训练完的模型用到测试集上看看效果怎么样
final_model = grid_search.best_estimator_
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse) # => 47994.53497582779
方差在48000左右,模型算是取得了还可以的效果。当然这绝对不是你能获得的最好结果,通过特征工程可以获得更好的预测效果,就交给你来试试看了。
作业(你可以现在去,也可以再学学去)
去Kaggle上面试一下预测Titanic幸存人员的竞赛,随便玩玩,可以先简单的试一下,学了之后的知识看看能不能在学习过程中慢慢提高分数。