MPViT: Multi-Path Vision Transformer for Dense Prediction源码详解
1.mmsegmentation注册自己的模块
- 创建一个新的文件
mmseg/models/backbones/mpvit.py,同时进行注册(@BACKBONES.register_module())

2.在 mmseg/models/backbones/__init__.py 里面导入模块
 3.在配置文件里使用它
3.在配置文件里使用它
2.网络源码详解

conv_stem:
如图所示,网络第一层为卷积层,直接运用transformer计算复杂度太大,因此网络初始部分使用卷积对特征图进行下采样四倍,假如输入图像大小为512*512,经过卷积后,特征图大小变为128*128。
conv_stem:
(stem): Sequential(
(0): Conv2d_BN(
(conv): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_layer): Hardswish()
)
(1): Conv2d_BN(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_layer): Hardswish()
)Multi-Scale Patch Embedding
Multi-Scale Patch Embedding,即使用具有不同卷积核大小的卷积进行embeding,如:当有三条路径时,使用3*3,5*5,7*7的卷积进行运算,同时,正如论文作者所说,为了减少运算量,将卷积改为深度 可分离卷积,同时使用两层3*3的卷积替代5*5的大卷积核,3个3*3的卷积替代7*7的大卷积核。
在代码实现上,作者做得更加简单,直接生成若干层卷积的list,每经过一层卷积就代表一个路径,三个路径共享了卷积的参数,
ModuleList(
(0): DWCPatchEmbed(
(patch_conv): DWConv2d_BN(
(dwconv): Conv2d(216, 216, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=216, bias=False)
(pwconv): Conv2d(216, 216, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(216, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): Hardswish()
)
)
(1): DWCPatchEmbed(
(patch_conv): DWConv2d_BN(
(dwconv): Conv2d(216, 216, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=216, bias=False)
(pwconv): Conv2d(216, 216, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(216, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): Hardswish()
)
)
(2): DWCPatchEmbed(
(patch_conv): DWConv2d_BN(
(dwconv): Conv2d(216, 216, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=216, bias=False)
(pwconv): Conv2d(216, 216, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(216, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): Hardswish()
)
)
)class Patch_Embed_stage(nn.Module):
def __init__(self, embed_dim, num_path=4, isPool=False, norm_cfg=dict(type="BN")):
super(Patch_Embed_stage, self).__init__()
self.patch_embeds = nn.ModuleList(
[
DWCPatchEmbed(
in_chans=embed_dim,
embed_dim=embed_dim,
patch_size=3,
stride=2 if isPool and idx == 0 else 1,
pad=1,
norm_cfg=norm_cfg,
)
for idx in range(num_path)
]
)
# scale
def forward(self, x):
att_inputs = []
for pe in self.patch_embeds:
x = pe(x)
att_inputs.append(x)
return att_inputsMulti-Path Transformer Block
Convolutional Local Feature:
如图所示,这层主要由3*3的深度可分离卷积实现,同时使用残差连接,论文上说的是为了保持卷积对纹理的依赖性。
ResBlock(
(conv1): Conv2d_BN(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_layer): Hardswish()
)
(dwconv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(norm): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): Hardswish()
(conv2): Conv2d_BN(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_layer): Identity()
)
)transformer ecoder:
卷积位置编码的实现:
由于整个网络是一种级联结构,特征图不断缩小,因此需要对位置编码进行一种重新的设置。论文中使用的是卷积位置编码,其原理就是先将序列resize成对应的特征图大小,然后使用3*3的深度可分离卷积提取出一个位置编码,并加到原特征图作为位置编码。 从可解释性的角度,博主个人觉得这个位置编码稍微有点low,并没有swin transformer那样具备较强的可解释性。
class ConvPosEnc(nn.Module):
"""Convolutional Position Encoding.
Note: This module is similar to the conditional position encoding in CPVT.
"""
def __init__(self, dim, k=3):
super(ConvPosEnc, self).__init__()
self.proj = nn.Conv2d(dim, dim, k, 1, k // 2, groups=dim)
def forward(self, x, size):
B, N, C = x.shape
H, W = size
feat = x.transpose(1, 2).contiguous().view(B, C, H, W)
x = self.proj(feat) + feat
x = x.flatten(2).transpose(1, 2).contiguous()
return x近似Attention的实现
由于 Multi-Path Transformer Block需要对多个路径的特征进行transformer的计算,因此计算复杂度很高,需要对transformer进行简化计算。
论文作者采取的有效的因素分解自注意:
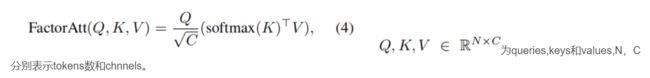
简单的说,原始的transformer计算queries、keys、values的点积时,计算方式一般是Batch_size,Heads, HW,C 点积 Batch_size,Heads, C,HW,因此时间复杂度为O(Heads*HW^2*C)与序列长度(图像H,W的乘积)的平方成正比,与channels成线性相关。
对于较大的特征图来说,比如128*128,其序列长度为16384,对于channels,一般最多设置为1024或者2048,因此,这个分解的思路是,能不能设计一种方法,让时间复杂度与HW成线性相关,与channels的平方成正比。
做法也比较简单,首先对Keys做softmax,然后计算k,v的点积,计算点积时,用Batch_size,Heads, C ,HW 点积 Batch_size,Heads, HW,C 得到 Batch_size,Heads, C ,C维度的向量,然后再与querys做点积,这样时间复杂度就变为(Heads*HW*C^2)
论文中的解释是,softmax (K)T V表示V的加权和,表示每个位置(x,y)在通道方向的空间注意。因此,为了获得每个位置的重要性,在通道维度上采用了softmax (K)的平均值,从而产生空间注意。
此外,还有一个需要注意的地方,当图像中,特征图两个点的q值相似的时候,其计算的结果也是相似的,因此为了避免这种情况,作者对计算后的结果加上了卷积位置编码
最后,经过dropout和全连接层,完成ecoder的运算
transformer ecoder代码如下:
class FactorAtt_ConvRelPosEnc(nn.Module):
"""Factorized attention with convolutional relative position encoding class."""
def __init__(
self,
dim,
num_heads=8,
qkv_bias=False,
qk_scale=None,
attn_drop=0.0,
proj_drop=0.0,
shared_crpe=None,
):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop) # Note: attn_drop is actually not used.
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
# Shared convolutional relative position encoding.
self.crpe = shared_crpe
def forward(self, x, size):
B, N, C = x.shape
# Generate Q, K, V.
qkv = (
self.qkv(x)
.reshape(B, N, 3, self.num_heads, C // self.num_heads)
.permute(2, 0, 3, 1, 4)
.contiguous()
) # Shape: [3, B, h, N, Ch].
q, k, v = qkv[0], qkv[1], qkv[2] # Shape: [B, h, N, Ch].
# Factorized attention.
k_softmax = k.softmax(dim=2) # Softmax on dim N.
k_softmax_T_dot_v = einsum(
"b h n k, b h n v -> b h k v", k_softmax, v
) # Shape: [B, h, Ch, Ch].
factor_att = einsum(
"b h n k, b h k v -> b h n v", q, k_softmax_T_dot_v
) # Shape: [B, h, N, Ch].
# Convolutional relative position encoding.
crpe = self.crpe(q, v, size=size) # Shape: [B, h, N, Ch].
# Merge and reshape.
x = self.scale * factor_att + crpe
x = (
x.transpose(1, 2).reshape(B, N, C).contiguous()
) # Shape: [B, h, N, Ch] -> [B, N, h, Ch] -> [B, N, C].
# Output projection.
x = self.proj(x)
x = self.proj_drop(x)
return xGlobal-to-Local Feature Interaction
这个模块就比较简单了,将不同路径的结果concat,在经过1*1的卷积就完成了特征融合模块。
head
在head的使用上,我使用了mmsegmentation提供的uper_head,论文地址见:https://arxiv.org/pdf/1807.10221.pdf


首先,从上面的MPViT输出四层特征图,分别为下采样4倍、8倍、16倍、32倍的特征图。对于前三层特征图,通过1*1的卷积将特征图channels统一为512,对于下采样32倍的特征图,经过PPM层提取全局特征。
PPM层:
对于PPM层,PPM的主要作用为提取全局特征,如图所示,有四层路径,分别经过输出大小为1*1,2*2,3*3,6*6的全局平均池化,然后经过1*1的卷积,将通道数统一为512,再将特征图上采样到初始大小,最后,将这四层特征图拼接,经过3*3的卷积,将特征图通道数降为512.

PPM(
(0): Sequential(
(0): AdaptiveAvgPool2d(output_size=1)
(1): ConvModule(
(conv): Conv2d(288, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(1): Sequential(
(0): AdaptiveAvgPool2d(output_size=2)
(1): ConvModule(
(conv): Conv2d(288, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(2): Sequential(
(0): AdaptiveAvgPool2d(output_size=3)
(1): ConvModule(
(conv): Conv2d(288, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(3): Sequential(
(0): AdaptiveAvgPool2d(output_size=6)
(1): ConvModule(
(conv): Conv2d(288, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)FPN:
如图所示,下采样32倍的特征图经过PPM head后是一个非常经典的FPN,将高维特征上采样后加到低维特征中,实现高维特征与低维特征的特征融合。
得到输出结果
经过FPN层后,前三层特征图(下采样4倍、8倍、16倍)经过3*3的卷积append输出特征图的列表,而最后一层输出结果,由于经过了PPM进行全局特征提取,直接append输出特征图的列表。 将所有的特征图均上采样至第一层输出特征图的大小,拼接所有的特征图,经过3*3的卷积,将特征图通道数继续调整到512。经过1*1的卷积输出层,得到输出结果。并计算交叉熵损失。
代码如下:
class PSPHead(BaseDecodeHead):
"""Pyramid Scene Parsing Network.
This head is the implementation of
`PSPNet `_.
Args:
pool_scales (tuple[int]): Pooling scales used in Pooling Pyramid
Module. Default: (1, 2, 3, 6).
"""
def __init__(self, pool_scales=(1, 2, 3, 6), **kwargs):
super(PSPHead, self).__init__(**kwargs)
assert isinstance(pool_scales, (list, tuple))
self.pool_scales = pool_scales
self.psp_modules = PPM(
self.pool_scales,
self.in_channels,
self.channels,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg,
align_corners=self.align_corners)
self.bottleneck = ConvModule(
self.in_channels + len(pool_scales) * self.channels,
self.channels,
3,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
def forward(self, inputs):
"""Forward function."""
x = self._transform_inputs(inputs)
psp_outs = [x]
psp_outs.extend(self.psp_modules(x))
psp_outs = torch.cat(psp_outs, dim=1)
output = self.bottleneck(psp_outs)
output = self.cls_seg(output)
return output