第二课第二周第1-5节-基于树的模型用于医学预后
本周,我们将使用决策树(Decision Trees)构建我们的第一个机器学习模型。树(trees)在医学应用中非常有用的的原因是:1️⃣ 它们处理连续和分类数据的能力,2️⃣ 它们的可解释性以及训练速度。
我们将使用树来模拟在医学数据中观察到的非线性(non-linear)关系。当然,我们将构建我们的第一个基于机器学习树的模型,用于预测住院患者短期死亡率的预测任务。
在实践中,当我们训练机器学习模型时,我们面临的主要实际挑战之一是缺失数据(Missing Data)。我们将研究在机器学习管道中处理缺失数据的几种方法,以及不处理处理缺失数据时会发生什么。
我们将在本周的最后一部分讨论解释模型(interpreting models)。由于其复杂的内部工作原理,机器学习模型通常被认为是黑盒子,但在医学中,解释和解释模型的能力可能对人类的接受和信任至关重要。我们将介绍一些您可以用来解释您将要构建的预后模型的方法,您将有机会在本周的作业中应用所有这些想法。
文章目录
-
- Decision Trees
- 划分输入空间
- 构建决策树
- 如何解决过拟合问题?
Decision Trees
在本课中,我们将研究决策树和随机森林(random forests)。我们将从死亡率预测开始,我们的任务是预测十年的死亡风险。
我们将介绍构建决策树的高级过程,并研究最常见的机器学习问题之一:过拟合。最后,在我们学习单个决策树之后,我们将学习随机森林,这是一个强大的分类器,它构建了许多决策树以进一步提高预测性能。
随机森林已经成为一种非常流行的开箱即用学习算法,它具有良好的预测性能,而且调整相对较少。让我们开始吧。

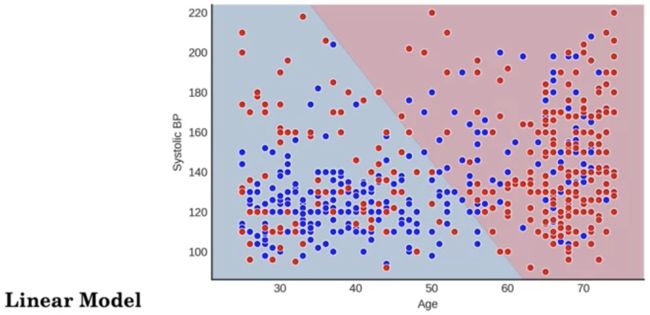
如上图,我们将特别关注使用年龄(age)和收缩压(BP)建立预后模型。收缩压是心脏跳动时血管中的压力。我们的预后模型将预测十年死亡率风险。我们将从图形方式探索年龄、血压和死亡之间的关系开始。
我们在 x 轴上绘制年龄,在 y 轴上绘制 BP。该图上的每个点都是一个患者。红色代表 10 年内死亡的患者,蓝色代表 10 年后还活着的患者。首先假设我们正在建立一个线性模型来区分死去的病人和活着的病人。花点时间思考一下线性模型如何进行这种分类。
划分输入空间
线性模型将拟合一条线,将高风险患者(此处以红色背景表示)与低风险患者(此处以蓝色背景表示)区分开来。但是,我们可以看到,这会错误地将许多高风险患者分类,而这些患者实际上应该位于红色区域。
现在让我们看下面一个分类器,它可以做出更好的分类,决策树。决策树使用垂直和水平边界将输入空间划分为高风险和低风险区域。决策树分类器可以看作是将输入特征空间划分为区域。

我们还可以将此分类器表示为具有 if-then 结构的树。决策树提出一系列问题,并根据每个问题的答案对患者进行分类。

让我们看一个例子。我们如何在这里对这三个病人进行分类?让我们来看看这个 if-then 结构。对于患者一,我们看到他们的年龄是 80 岁,血压是 162。所以我们会查看年龄,发现它大于 60,我们会将这个患者归类为高危患者。对于患者 2,我们会看到他们的年龄小于 60 岁,我们会查看他们的血压以确定他们是低风险的。最后,对于患者 3,我们会看到他们的年龄小于 60 岁且血压大于 160,因此我们将他们归类为高危人群。
决策树可以对非线性关联进行建模。请注意,当年龄和血压都较低时,他们如何能够在这里捕捉到风险较低。那是一种非线性关联。另一方面,线性模型无法捕捉到这一点,因为它们只能通过特征空间绘制一条直线。一个例外是当线性模型使用交互项时,正如我们上周看到的那样,它可以使用它来模拟一些非线性关联。
注意:决策树边界始终是垂直或水平的。因此,通过查看输入空间中分类器的边界,我们可以判断决策边界是否可以使用决策树构建。
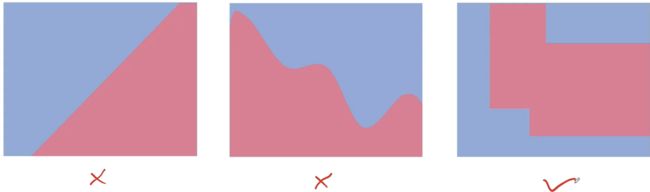
看上面的图,判断哪些是决策树构建的边界?前两个都不是决策树生成的,最后一个才是。
构建决策树
决策树是如何构建的?有很多算法用于学习决策树。我们将在high level上介绍决策树构建的过程。
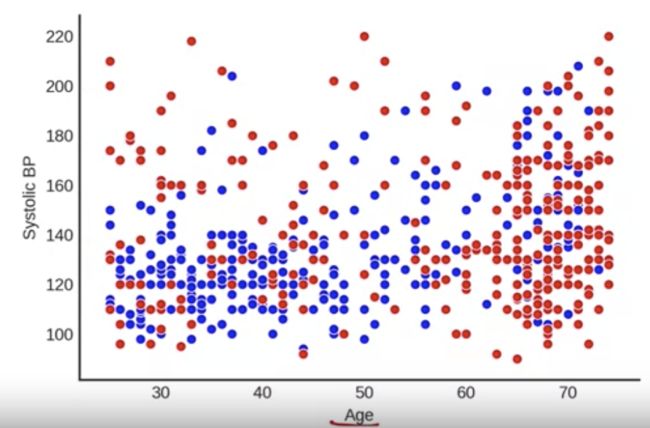
我们构建决策树的第一步是选择一个变量和该变量的值来对数据进行分区,这样一个分区主要包含红色,另一个分区主要包含蓝色。
现在,我们选择什么变量以及我们为该变量选择什么值,取决于它将红色带到一侧并将蓝色带到另一侧的程度。

在这里,我们将选择年龄并在 60 岁时创建一个分区,注意这很好地分离了右侧的红色点,左侧混合了蓝色和红色
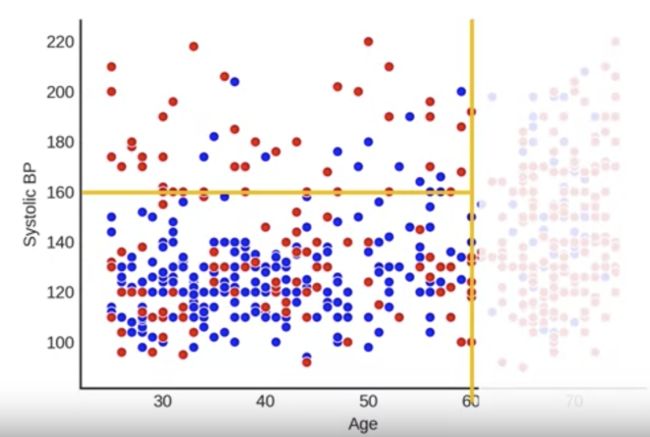
我们现在可以在这个分区中重复这个过程,在这里我们将再次选择一个变量和该变量的值,这样一侧将主要包含红色,而另一侧主要包含蓝色。所以我们可以在收缩压为 160 的位置添加一条水平线,注意很多红点出现在顶部,很多蓝点出现在底部。所以我们可以在每个分区内继续这个过程,直到分区或多或少完全是红色或蓝色。
假设我们在这里暂停划分
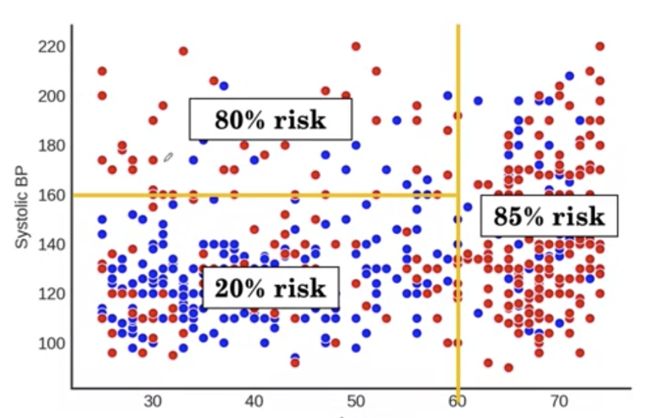
现在,在我们的三个分区中,我们可以估计风险。我们的风险估计将是每个分区内死亡的患者比例。对于左上分区,我们有 80% 的点是红色的,所以我们对新患者的估计是 80% 的风险。在左下,我们有 20% 的点是红色的,我们估计为 20%,右边是 85%。
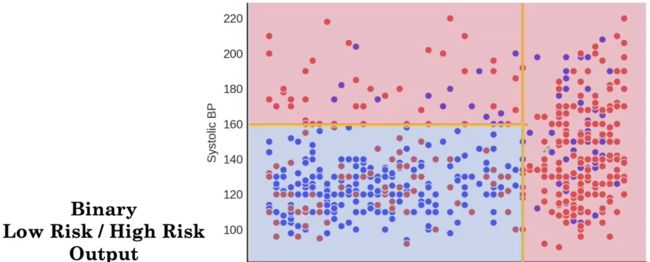
我们可以将输出二值化,只输出一个区域是低风险还是高风险。一种简单的方法是,如果预测概率大于 50%,则将预测称为高风险,否则称为低风险。这使我们有两个风险大于 50% 的红色分区和一个风险小于 50% 的蓝色分区。最后,就得到了下面的图。
如何解决过拟合问题?
构建决策树面临的挑战是,如果我们不停止增长决策树,它们会继续创建越来越多的分区并变得过于复杂。决策树模型可以创建几乎完美地拟合训练数据的过于复杂的树,这可能最终成为一件坏事。
这是可以得到 0.93 的训练精度的决策树。我们可以测试决策树是否过于复杂的方法是我们可以在另一个集合上查看它的性能。我们可以看到这个模型在测试数据上表现不佳。这被称为过拟合(overfitting),该模型非常适合训练数据,以至于它不能很好地推广到其他样本或现实世界。
我们对抗过度拟合的一种方法是控制决策树生长的停止时间。我们可以通过设置树可以生长的最大深度来停止生长决策树。

在这个特定示例中,当我们的默认最大深度为 22 时,我们得到了一个过于复杂的树,它实现了高训练和低测试精度,并且对数据过度拟合。但是,如果我们将最大深度控制为 4,那么我们会得到一个更简单的决策树,它的训练准确度和测试准确度相近,比我们在过于复杂的树中看到的测试准确度要高。
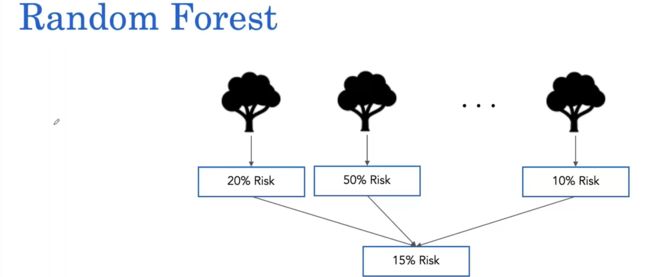
另一种对抗过度拟合的流行方法是构建随机森林(random forest)。随机森林构建多个决策树并对它们的风险预测进行平均。

因此,对于患者,我们可能让每棵树都提出风险预测,例如 20%、50% 或 10%,然后随机森林对这些风险预测进行简单平均,得出 15% 的风险预测。
那么如何训练随机森林呢?随机森林的训练有两个关键概念。首先,森林中的每棵树都是使用患者的随机样本构建的。例如,对于第一棵树,我们可能会绘制 P1、P2、P1(patient1),2个P1因为随机森林样本有放回。
其次,随机森林算法还修改了决策树构建中的分裂过程,以便在创建决策边界时使用特征子集。
通过这两个关键概念,随机森林算法学习在给定数据上构建多个决策树。随机森林通常会提高单棵树的性能。因此,对于单个决策树,您可能会获得 0.71 的测试准确度,而随机森林由 100 棵树组成,我们会获得更高的测试准确度。
随机森林被称为集成学习方法,因为它们使用多个决策树来获得比单独从任何决策树获得的更好的预测性能。集成这些决策树的流行方法包括 Gradient Boosting、XGBoost 和 LightGBM,它们在处理医学和其他领域的结构化数据时也能够实现高性能。
本节完后有作业见,下一篇文章。
文章持续更新,可以关注微信公众号【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持已实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连
