A Simple Baseline for BEV Perception Without LiDAR 论文笔记
原文链接:https://arxiv.org/pdf/2206.07959.pdf
本文是针对BEV分割任务提出的。
1.引言
许多多视图图像方法关注生成自车周围3D场景的BEV语义表达,并用于与驾驶相关的任务上;通常的方法是使用单应性矩阵、借助深度估计、MLP、几何感知的transformer或是跨时空的可变形注意力将2D图像平面的特征“提升”到BEV平面。
本文方法的“提升”操作是无需参数的,且不依赖深度估计:在3D空间定义坐标体积单元,将坐标投影到图像,并将投影位置的采样特征取平均。该方法性能和速度均能能超过SotA,且有更少的参数。实验表明batch size、数据增广和输入分辨率对性能的影响很大。
此外,虽然某些现有的雷达语义BEV映射工作表明,雷达点太过稀疏而没有作用,但都是单独评估雷达,而忽视了RGB图像和雷达可能相互补偿的多模态融合。本文使用了雷达的度量信息,将雷达在BEV栅格化并与RGB特征拼接,进一步缩小了与激光雷达方法的差距。
3.BEV映射方法
3.1 概述
如下图所示。输入数据可来自多视图相机、多雷达单元以及激光雷达(可选)。设各传感器数据被同步,且已知内外参。
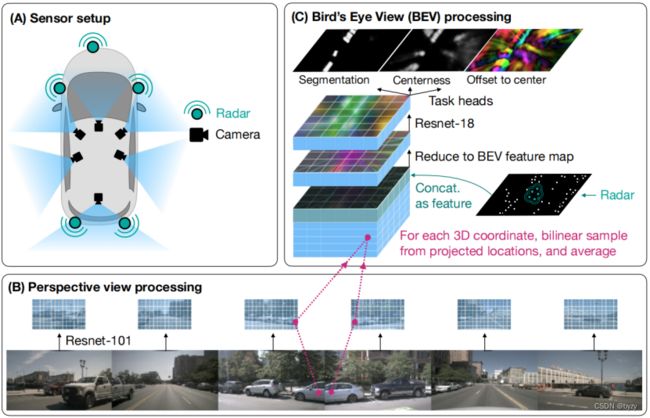
将3D空间离散化为体积单元(以参考相机为中心),并定义左右轴为 ,上下轴为
,上下轴为 ,前后轴为
,前后轴为 。
。
首先提取各图像特征,然后使用双线性采样为3D体积单元填充特征,即将各体积单元中心投影到各2D特征图上,使用双线性采样获取特征。若提供雷达数据,则将雷达栅格化为BEV图像,并与3D体积网格拼接。压缩垂直维度后,使用2D卷积进一步处理,输入到任务头中产生BEV下的分割图(每个像素类别的概率分布)、中心性分数图(与每个像素属于物体中心的概率正相关)、以及偏移量图(每个像素对应一个指向最近物体中心的向量;即物体内的点指向所属物体中心)。
3.2 结构
图像编码器使用ResNet-101不同层的多尺度输出,上采样后拼接,通过卷积块(卷积+Instance Normalization+ReLU)融合多尺度特征。
为每个视图图像建立体积网格并记录有效性(有效即体素中心位于图像棱台中),然后将各视图体积网格按有效性加权平均,并将垂直维度置于通道维度,即![]() (即M²BEV中提到的S2C操作)。
(即M²BEV中提到的S2C操作)。
对于雷达,直接离散化为BEV网格,使用雷达的非空间特征( 维)作为通道,得到
维)作为通道,得到 的张量。对于激光雷达,则体素化为大小为
的张量。对于激光雷达,则体素化为大小为 的二值占用图。
的二值占用图。
然后将雷达和图像特征拼接,使用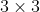 卷积压缩通道维度。使用ResNet-18得到多尺度BEV特征图,上采样到输入分辨率并拼接,输入到任务头(卷积+Instance Normalization+ReLU)中。
卷积压缩通道维度。使用ResNet-18得到多尺度BEV特征图,上采样到输入分辨率并拼接,输入到任务头(卷积+Instance Normalization+ReLU)中。
分割损失为交叉熵损失,中心性分数和偏移量损失为L1损失;使用基于不确定性的可学习加权来平衡各项损失。
与其他工作相比,本文的方法更简单,尤其是在2D到3D的提升阶段。
3.3 实施细节
图像主干ResNet-101进行目标检测的预训练。
训练时,随机选择相机作为参考相机,以使3D体积网格的朝向(以及标注物体的朝向)随机化;图像被随机裁剪(相应修改内参)。测试时,使用前视相机作为参考相机,图像进行中心裁剪。
4.实验
4.1 主要结果
对于单帧图像方法,本文的性能超过所有其余方法,甚至超过多帧BEVFormer方法。此外,加入雷达模态能大幅提高性能;RGB+激光雷达能得到更好的性能,但与RGB+雷达的方法的差距比期望的差距更小(有方法说RGB+雷达会起到副作用)。
速度和复杂度:比BEVFormer快速,且含更少的参数;主要参数都位于图像主干。
定性结果:虽然雷达点云稀疏而富含噪声,但雷达能为场景结构提供线索,与RGB特征融合后能得到更精确的BEV语义分割结果。
4.2 消融研究
输入分辨率:图像分辨率太大或太小时性能都有下降,可能是物体尺度和图像分支预训练数据集的物体大小不一致,使得迁移不那么有效。
Batch size:实验表明本文的模型,batch size越大性能越好。
数据增广:训练时随机选择参考相机的方法能带来微小的性能提升,且可视化表明该操作可以修正某些位置上某些朝向估计的微小偏差。
随机丢弃视图图像的数据增广会带来反作用,这可能是随机选择参考相机的方法已经能提供足够的正则化。
图像色彩、对比度和模糊数据增广方法均会使性能变差。
雷达的使用:仅使用雷达BEV占用图与图像融合会有性能下降,因为雷达的特征中包含了速度等信息,对从背景中区分运动物体很重要。此外,使用数据集官方提供的方法过滤outlier后的性能也有下降,这可能是过滤掉了一些真实点。使用多帧雷达(在当前帧坐标对齐)能提高性能,因为雷达点云更加密集。
局限性:未引入图像的时间信息;训练时间较长。