【语言模型系列】原理篇二:从ELMo到ALBERT
上一篇讲到了word2vec存在”一词多义“的问题,其主要原因在于word2vec生成的词向量是“静态”的,每一个词固定的对应着一个词向量表示,也就是说在word2vec训练好之后,在使用单词的向量表示的时候,不论该词的上下文是什么,这个单词的向量表示不会随着上下文语境的变化而改变。历史的车轮滚滚向前,”一词多义“的问题也被各种思路清奇的算法所解决,这篇文章我们从解决”一词多义“问题的ELMo说起,逐一介绍现在大火的预训练模型。
一、ELMo
首先我们讲一个预训练模型ELMo,这个算法出自《Deep contextualized word representation》,ELMo的全称是“Embeddings from Language Models”,其核心的点在于可以根据上下文动态调整当前词的词向量表示,比如有下面两个句子:
I like to eat apple.(我喜欢吃苹果)
I like apple products.(我喜欢苹果的产品)
在ELMo这个模型中,会根据”苹果“这个词的上下文去推断其向量表示,最终第一个”苹果“的向量表示代表水果,第二个”苹果“的向量表示代表苹果公司,其词向量表示是完全不同的。
那么ELMo是怎么做到的呢?下面一起来看一看~
1.1 ELMo的核心原理
ELMo之所以能够动态的生成词向量,主要原因是由于该模型有两个阶段。第一个阶段是在具体任务训练之前,利用大量语料预训练一个语言模型,这个语言模型相当于一个动态词向量生成器,用于给具体任务生成词向量;第二个阶段是做下游任务,也就是利用第一阶段的动态词向量生成器产生的词向量,将其作为新特征加入到下游任务中,进行具体任务的训练。所以,这个算法比较重要的是第一个阶段,也就是预训练阶段,这个阶段存在的目的就是为了解决“一词多义”的问题。
首先来看第一阶段,ELMo第一阶段的目的就是得到一个动态词向量生成器,该生成器的输入是一个query,输出是该query的向量表示(词向量 or 句向量)。所以输入的query不同,其输出的向量表示肯定也不同,这就是动态词向量的核心点啦。
也就是说,我先预训练好一个语言模型,这个语言模型能够对当前的输入进行向量表示,同时,这个向量表示是根据整个query的不同而改变的。比如bank在query1中表示的是银行,在query2中表示的是岸边,那么query1和query2输入到这个语言模型中时,该模型根据query中的内容,也就是bank的上下文,来决定当前的bank的向量表示。下面是这个语言模型的结构,我们来看一下这个语言模型是怎么训练得到的。
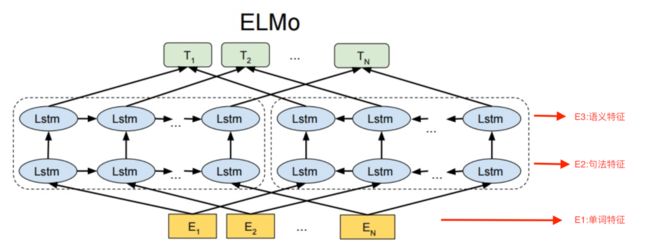 ELMo模型
ELMo模型
这个语言模型的输入是最下面一层的 ,代表一句话中N个词的初始词向量,这个初始词向量是利用字符卷积(char-cnn)得到的,这一点在图中没有体现。
和大多数的语言模型一样,该语言模型训练过程中的输出是最上面一层的 ,其中, 是一个m维向量,m为词表大小,所以 代表每个词的出现概率。
这个网络结构最重要的部分就是采用双向LSTM,所谓双向LSTM就是前向LSTM和后向LSTM的结合。
给定N个tokens ( ) ,前向LSTM通过给定前面的 个位置的token序列计算第k个token出现的概率:
后向LSTM通过反向的k-1个位置的token序列计算该token出现的概率:
所以双向lstm在训练过程中的目标函数就是:
对于每一个输入的token ,ELMo利用L层的双向LSTM将其表示成2L+1个向量。比如上图是一个两层的双向LSTM,即L=2,每一层都会有一个前向LSTM向量输出,一个后向LSTM向量输出,所以加上第一层的单词特征,那就会有5个表示向量。当然,在使用时会将双向LSTM层的前向输出和后向输出进行拼接,作为这一层的输出向量。所以,最终输出了三个向量,E1,E2,E3。
那ELMo有了这么多向量之后如何使用呢?也就是ELMo的第二阶段如何进行?
论文中的实验表明,ELMo中的每一层输出向量都有其不同的含义,比如图中的E1是单词特征,E2是句法特征,E3是语义特征,那么下游任务在使用动态词向量生成器产生的词向量时,将每一层双向LSTM产生的向量乘以权重参数,作为下游任务的一种特征输入,将该特征与下游任务的词向量进行拼接,构成最终的词向量进行任务的训练。
用公式总结一下就是:
其中 是ELMo第k个位置输出的词向量, 是每一层前向后向拼接后的输出, 是每一层输出向量的权重,这个参数可进行训练得到, 是对ELMO输出向量的一个缩放参数,可手动设置, 是具体任务使用的词向量,即原始词向量和ELMo输出向量的拼接。
另外,这里的向量构建方法也不一定固定不变,可以尝试多种方法,比如把每一层的输出直接进行拼接,前向后向进行加权拼接等等,可以尝试在不同任务中的效果。
1.2 现在谈ELMo
ELMo采用动态词向量的方法解决了一词多义的问题,现在来看,该模型也有其不足之处。最明显的一点就是没有使用抽取特征能力更强的transformer。
二、Transformer
所以,插播一下Transformer这个神奇的”特征抽取器“。Transformer是了解常用预训练模型之前,绝对绕不过去的一个算法模型。Transformer出自论文名字就霸气侧漏的《Attention is all you need》,这篇文章掀起了对以往常用的CNN、RNN类特征抽取器的革命和挑战,而且以压倒式的优势获得了胜利。
2.1 Transformer的核心原理
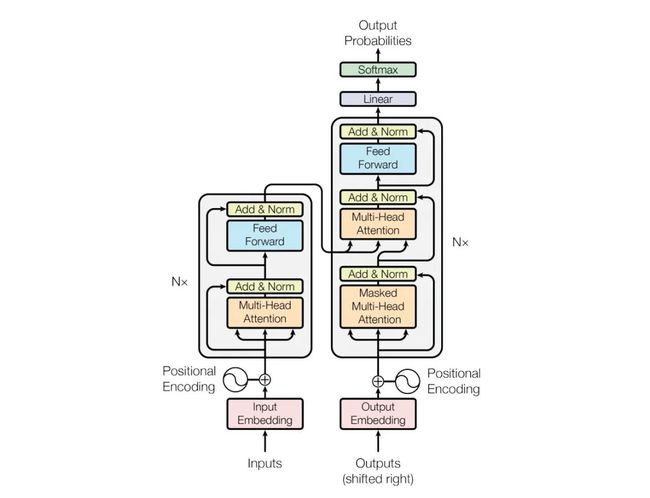 Transformer模型
Transformer模型
2.1.1 整体框架
Transformer和常见的seq2seq的模型类似,主要由encoder和decoder组成。上图的左半边用Nx框起来的,代表一层encoder,右半边用Nx框起来的代表一层decoder,论文中取Nx=6,也就是encoder和decoder都是由6个layer组成的。
encoder的输入部分是输入序列Inputs经过embedding后,得到Input Embedding,再和Positional Encoding相加,输入到encoder中。这里的Positional Encoding采用的是绝对位置编码,至于为什么需要Positional Encoding,以及Positional Encoding是怎么得到的,我们待会儿再讲。
decoder的输入部分是输出序列Output经过Embedding后,得到Output Embedding,再和Positional Encoding相加,输入到decoder中,同时中间还将encoder的输出作为decoder的输入。
整个模型的输出就是decoder的输出经过一个线性层,再经过一个softmax,和大多数语言模型一样,当前时刻的输出是一个m维向量,m是词库大小,该向量表示当前时刻输出每个词的概率。
下面打开黑盒子,看看里面的具体实现~
2.1.2 encoder
首先来看encoder部分,encoder的layer是由两个sub_layer组成的,也就是图中的Multi-Head Attention和Feed Forward,同时每个sub_layer还添加了残差网络和归一化,也就是图中的Add&Norm。Feed Forward是为了将得到的特征向量投影到更大空间,方便提取信息,这一块先不管它,主要关注Multi-Head Attention和Add&Norm。
2.1.2.1 Multi-Head Attention
Multi-Head Attention是由attention到self-attention,再到Multi-Head Attention一步步发展来的,所以先来回顾一下啥是attention。
了解attention机制的同学应该明白,所谓的attention就是为了得到一个权重信息,用来给当前query的每个词分配不同的权重。举个栗子,比如我们要做一个机器翻译的任务,输入”你好老师“,分词后为两个token”你好“,”老师“,对应译文是”hello teacher“,attention机制就是在预测”hello“的时候,利用 你好 和 老师 得到两个权重 和 ,然后用 你好 老师 作为当前时刻的特征向量 ,利用该特征向量去预测”hello“。同理可得 ,利用 去预测”teacher“,这里的 分别代表乘以权重矩阵 得到的向量。由于”hello“和”老师“在语义上是对应的,所以 应该大于 ,这样在预测”hello“的时候,注意力就更多的集中在”你好“这个token上,同时还考虑了上下文。当然,这里得到权重 和 的方式有很多种,这里只提到常用的点乘。矩阵形式的操作如下图所示,其中X代表输入序列的embedding,这里简化为4维,实际维度是512, 的维度简化为3,实际维度是64,最终的输出Z由 组成。

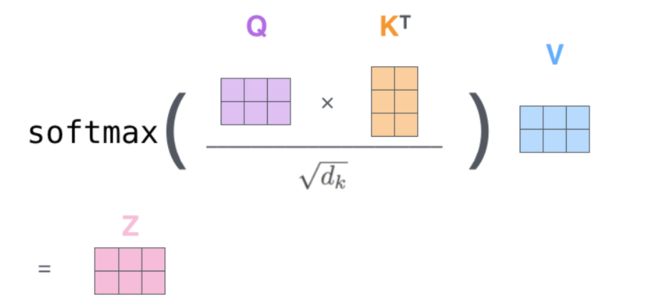
attention过程演示
那么什么是self-attention?看名字就知道,就是自己和自己进行点乘,以获得当前位置的权重。也就是说上图中的 ,这就是self-attention。为啥要有self-attention呢?因为encoder只有这一个输入啊,只能自己和自己玩喽~
那么什么又是Multi-Head Attention呢?看名字也知道,其实就是多个attention结果的拼接。还是上面那个例子,相当于有了多个权重矩阵,即存在,论文中存在8个head,这样就得到8个输出 ,维度都是 ,然后按行拼接 ,维度变成 ,再乘以一个额外的权重矩阵 ,维度为 ,得到 ,维度为 。所以Multi-Head Attention的输入X和最终的输出Z的维度大小是一致的。
这里为什么选择进行Multi-Head Attention呢?直接用一个head不可以吗?我个人理解这么做的目的其实是为了获取不同维度下的特征,或者说为了扩大模型的capacity。那为什么不直接调大Nx呢?原因在于扩充head,没有层与层之间的依赖,其操作可以进行并行化,可以提升效率。
2.1.2.2 Add&Norm
得到Multi-Head Attention的输出 之后,再经过残差网络和归一化,用公式表示一下:
其中LayerNorm代表归一化, 代表加入的残差网络。
2.1.3 decoder
看完encoder部分,再来看decoder就比较容易理解了。前面说了,decoder的输入有两个部分,一个是Output Embedding+Positional Encoding,另一个来自encoder的输出。decoder主要有三个sub_layer:Masked Multi-Head Attention、MUlti-Head Attention以及Feed Forward。
2.1.3.1 Masked Multi-Head Attention
这个sub_layer引入了MASK机制,其作用是为了消除未知信息对当前时刻预测的影响。比如当预测”teacher“这个位置时,需要把”teacher“这个信息给MASK掉,不让模型看见。其具体做法就是在得到权重系数之后,将该时刻以后的权重系数加上负无穷,然后再经过softmax,这样该时刻之后的值基本就是0了。
2.1.3.2 Multi-Head Attention
这个sub_layer的原理和encoder一样,其主要区别在于这里的attention不是self-attention,这个Multi-Head Attention输入的K和V来自encoder,Q来自Masked Multi-Head Attention的输出。
2.1.4 Feed Forward
这个sub_layer就是简单全连接层,而且是对每一个位置都各自进行相同的操作,其输入是Multi-Head Attention层每个位置上的输出。用公式表达就是
由以上的介绍可以知道,Multi-Head Attention每个位置上的输出 ,同时这里 , ,所以这个sub_layer单个位置的输出维度仍然是 。
另外可以看出来,这个操作就相当于先升维,再降维,其目的在于扩大容器的capacity。
2.1.5 Positional Encoding
模型的输入为什么要加入一个Positional Encoding?原因是单纯的attention机制没有考虑位置信息,也就是说”北京到上海的机票“和”上海到北京的机票“这两个query对于attention机制来说是相同的,这显然不合理,所以需要加入位置信息加以区分。
Transformer中的Positional Encoding采用正弦位置编码,论文中的公式为:
比如一句话中第三个token的Positional Encoding是
三、GPT
在了解完Transformer之后,我们可以继续进行探寻预训练模型啦~首先讲一个和ELMo极其相似的模型--GPT。
GPT是《Improving Language Understanding by Generative Pre-Training》这篇文章提出的一种预训练算法,和ELMo很像,GPT也分为两个阶段,第一阶段是利用语言模型进行预训练,不同的是,GPT的第二阶段不再是重新搞一个具体任务的模型,而是直接在预训练模型的基础上进行微调(fine-tuning),完成具体任务的训练。
3.1 GPT的核心原理
GPT和ELMo的不同之处主要在于:
特征抽取器由双向LSTM替换成transformer
特征抽取时只使用单向信息,即该语言模型只使用上文预测当前词,而不使用下文
将预训练和fine-tuning的结构进行了统一,进行下游任务时,直接在预训练模型上进行改造,而不是将得到的词向量输入到具体任务的模型

对于第一阶段,首先,输入向量是词向量和位置向量的组合,然后特征提取层使用Transformer的decoder变体进行特征提取,然后根据输出的特征向量进行语言模型的训练。搬出论文中的公式:
其中, 代表输入的单词token, , 代表词向量矩阵, 是词表大小, 是隐层维度大小, 代表位置向量矩阵, 就代表此时输入的序列特征,即图中的 ,n代表transformer的层数, 代表每个位置出现某个单词的概率。
对于第二阶段,在预训练模型准备好后,就可以通过构造不同的输入,利用transformer最后一层的输出进行不同任务的fine-tuning。
拿简单分类任务举例,假设我们有带标签的数据集 ,对于输入序列 以及标签y,首先将输入序列喂到预训练模型中,得到transformer最后一层的输出 ,然后再经过全连接层与softmax,得到预测的概率。注意这里是拿了最后一层的最后一个token作为输出,源码里就是这么写的。简单分类任务的目标函数是
论文在具体微调时结合了语言模型的部分,即:
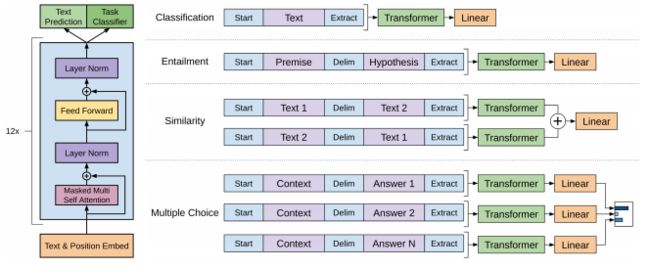
不同的任务有着不用的输入构造方式,但大同小异,如下图所示。
3.2 GPT中的Transformer
前面说到,GPT中的Transformer是正规Transformer模型的decoder部分的变体,也就是说GPT的Transformer部分是由 Masked Multi-Head Attention+Add&Norm+Feed Forward+Add&Norm构成的。同时,论文中采用Nx=12层的Transformer结构。
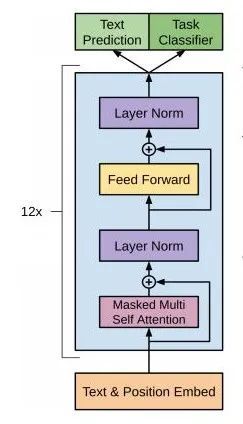
有前面的介绍可以知道,Masked Multi-Head Attention是只利用上文进行当前位置的预测,所以GPT被认为是单向语言模型。
另外,在Transformer输入的构造中,GPT的Position Encoding不再使用正弦位置编码,而是有一个类似于词向量表的位置向量表,该表可在训练过程中进行更新。
四、BERT
GPT在特征抽取上使用了transformer,但是语言模型构建过程中只利用了上文信息,没有利用下文信息,这样白白丢掉了很多信息,这使得GPT在一些类似于阅读理解任务中的应用场景受到限制。这也让BERT有了大火的机会,如果GPT使用了双向transformer,估计现在NLP领域的里程碑事件就不是BERT,而是GPT了。
4.1 BERT核心原理
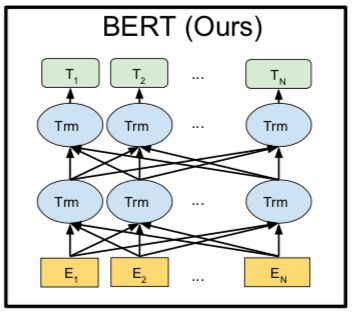
BERT和GPT在结构上更是极为相似,其主要区别是:
BERT采用transformer的encoder变体作为特征抽取器,且考虑双向,在预测当前词时,既考虑上文,也考虑下文,语言模型的预训练过程中采用MASK方法
语言模型训练过程中添加了句子关系预测任务
4.1.1 BERT的输入构造
由于BERT添加了句子关系预测任务,所以BERT的模型输入构建上有一点改变,添加了一个segement embedding,用来表示当前token属于哪一个句子,如下图所示:

Token Embeddings是词向量,第一个单词是CLS标志,一般都会拿该位置的输出进行分类任务的微调。
Segment Embeddings用来区别两种句子,因为预训练不光做语言模型的训练,还要做以两个句子为输入的分类任务。
Position Embeddings和GPT一样,通过对位置向量表进行look-up获得位置向量。
4.1.2 BERT的MASK机制
前面我们提到了BERT是一个采用双向Transformer的模型,我们知道transformer内encoder部分的主要结构是self_attention,并不是类似于LSTM那种串行结构,而是一个并行结构。对于串行结构,我们可以正向输入,依次预测每个词,构成前向LSTM,也可以反向输入,依次预测每个词,构成后向LSTM,这样就构成了一个双向LSTM,那么对于并行结构该如何实现”双向“这个概念呢?这个方法就是BERT用到的MASK机制,其原理和上一篇讲的word2vec的训练原理有些类似。
这个MASK方法的核心思想就是,我随机将一些词替换成[MASK],然后训练过程中让模型利用上下文信息去预测被MASK掉的词,这样就达到了利用上下文预测当前词的目的,和我们了解的CBOW的核心原理的区别就是,这里只预测MASK位置,而不是每个位置都预测。但是,直接这么做的话会有一些问题,训练预料中出现了大量的[MASK]标记,会让模型忽视上下文的影响,只关注当前的[MASK]。
举个栗子,当输入一句my dog is hairy ,其中hairy被选中,那么输入变为my dog is [MASK],训练目的就是将[MASK]这个token预测称hairy,模型会过多的关注[MASK]这个标记,也就是模型认为[MASK]==hairy,这显然是有问题的。而且在预测的过程中,也不会再出现[MASK]这种标记。那么为了避免这种问题,BERT的实际操作步骤是:
随机选择15%的词
将选中词的80%替换成[MASK],比如my dog is hairy → my dog is [MASK]
将选中词的10%随机替换,比如my dog is hairy → my dog is apple
将选中词的10%不变,比如my dog is hairy → my dog is hairy
这样做之后,训练过程中预测当前词时,该位置对应的token可以是任何词,那么这样就会强迫模型去学习更多的上下文信息,不会过多的关注于当前token。
4.1.3 BERT的句子关系预测任务
BERT语言模型训练过程中添加了句子关系预测任务,对于这个任务,简单来说,BERT通过构建句子关系的分类样本,对模型进行了进一步的训练。构建句子关系分类样本时,正样本就是正常语序的两个句子,负样本的构建是从另一个文本文件中选择一个句子与当前句子组合。
4.1.4 BERT的微调(fine-tuning)
在下游任务的改造中,BERT主要有四种:
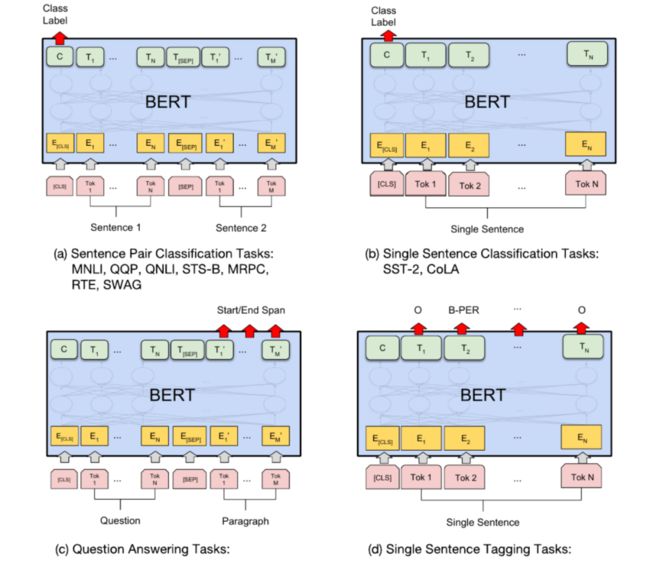
句子关系类任务:
输入:加上一个起始和终结符号,句子之间加个分隔符
输出:把第一个起始符号对应的 Transformer 最后一层位置上面串接一个 softmax 分类层
单句分类任务:
输入:增加起始和终结符号
输出:把第一个起始符号对应的 Transformer 最后一层位置上面串接一个 softmax 分类层
序列标注:
输入:增加起始和终结符号
输出:Transformer 最后一层每个单词对应位置都进行分类
阅读理解:
输入:[CLS]+问题+[SEP]+段落+[SEP]
输出:答案的开始和结束位置
4.2 BERT的缺陷
BERT这个模型效果强悍,应用广泛,但是由于模型拥有庞大的参数量,导致训练过程所耗硬件资源相当大,训练时间相当长,一般难以自行完成预训练过程。
五、ALBERT
ALBERT出自论文《 A Lite Bert For Self-Supervised Learning Language Representations》,其模型结构与BERT基本一致,其创新点主要在于以下几个改进和不同点:
词嵌入参数因式分解
-
BERT中词embedding维度( )和encoder输出的embedding的维度( )都是一样的,ALBERT认为由于单词的向量表示不包含上下文信息,所以词向量信息量理论上应该比encoder输出的embedding少,所以应该存在 ,采用参数因式分解将参数量由 变为 ,当E<
隐藏层间参数共享
-
ALBERT将encoder层的参数都进行共享,包括全连接层和attention层
段落连续性任务输入文本构造方式
-
BERT的句子关系预测任务中的负样本是从两个不同文档挑选句子组成的,这样导致句子关系预测任务变得简单,因为不同的文档大概率是不同主题的,这样构建负样本会让模型更多的关注于主题的判断,而不是句子连续性的判断。所以ALBERT将负样本的生成更改为直接调换正样本两个句子的顺序,这样就会让模型更多的关注句子的顺序,而非主题性差异。
ALBERT的优化初衷主要是为了将预训练模型进行落地,我们在实际应用中也使用了该模型,下一篇将会介绍预训练模型的工程落地的相关经验和实际效果。
作者介绍
李东超,2019年6月毕业于北京理工大学信息与电子学院,毕业后加入贝壳找房语言智能与搜索部,主要从事自然语言理解等相关工作。
交流学习,进群备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。
广告商、博主勿入!

