【今日CV 计算机视觉论文速览 第132期】Tue, 18 Jun 2019
今日CS.CV 计算机视觉论文速览
Tue, 18 Jun 2019
Totally 64 papers
?上期速览✈更多精彩请移步主页

Interesting:
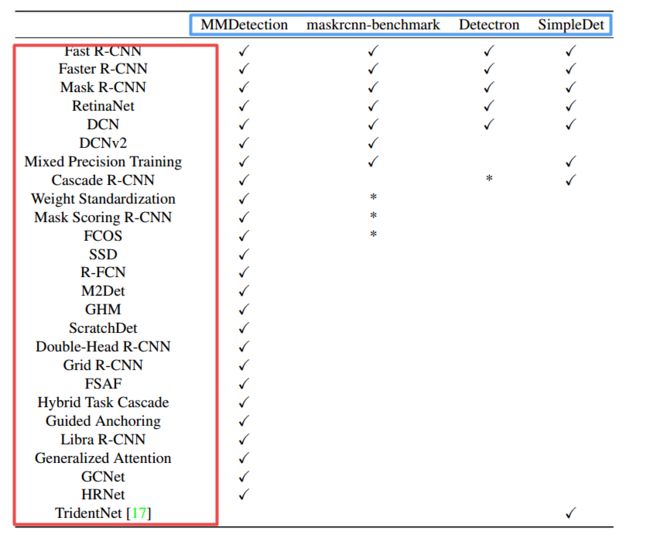
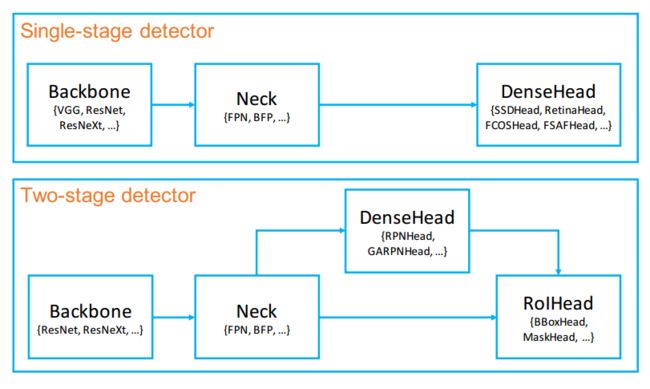
?****MMDetection, 一个目标检测模型工具箱和代码库,包含了常见的目标检测模型,标准模块和高效的实现。可以为研究人员提供高效灵活的目标检测实现工具。还包含了多GPU的分布式训练实现。(from 港中文、浙大、悉尼大学、商汤、微软亚研、北理理工、南大、华中科技、北大、港科技、中山大学、西北大学(us)、南洋理工)
工具箱支持的模型库与其他代码库比较:
通用的架构和训练流程:

code:https://github.com/open-mmlab/mmdetection
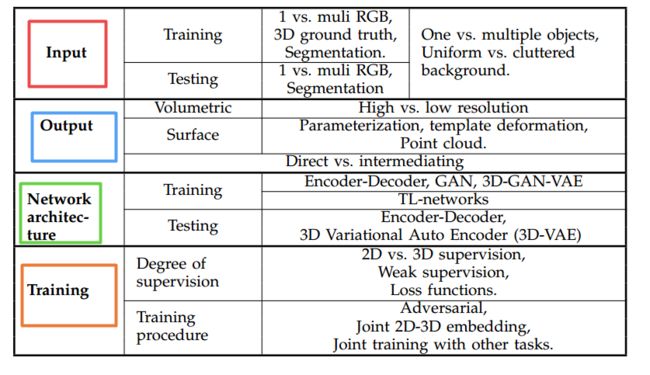
?****Image-based 3D Object Reconstruction基于图像的三维重建深度学习实现综述, 从输入数据类型、输出表示、网络架构和训练过程对整个基于图像的三维重建进行了深入的分析,并对100多个模型进行了分析和比较。是一篇较好的单图像三维重建综述文章。(from 天津大学)
?基于对抗网络的水下图像增强算法, 首先提出了U45水下数据集,同时设计了针对图像和特征的融合特征的损失函数。实现的模型参数较少,速度较快效果较好。(from 南京信息工程大学)

u45 dataset:https://github.com/IPNUISTlegal/underwater-test-dataset-U45-
rar:https://github.com/IPNUISTlegal/underwater-test-dataset-U45-/blob/master/U45.rar
Daily Computer Vision Papers
| MMDetection: Open MMLab Detection Toolbox and Benchmark Authors Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jiarui Xu, Zheng Zhang, Dazhi Cheng, Chenchen Zhu, Tianheng Cheng, Qijie Zhao, Buyu Li, Xin Lu, Rui Zhu, Yue Wu, Jifeng Dai, Jingdong Wang, Jianping Shi, Wanli Ouyang, Chen Change Loy, Dahua Lin 我们提供MMDetection,这是一个对象检测工具箱,包含丰富的对象检测和实例分割方法以及相关的组件和模块。该工具箱从MMDet团队的代码库开始,他们赢得了COCO Challenge 2018的检测轨道。它逐渐演变成一个统一的平台,涵盖了许多流行的检测方法和现代模块。它不仅包括训练和推理代码,还为200多种网络模型提供权重。我们相信这个工具箱是迄今为止最完整的检测工具箱。在本文中,我们将介绍此工具箱的各种功能。此外,我们还对不同的方法,组件及其超参数进行了基准研究。我们希望工具箱和基准可以通过提供灵活的工具包来重新实现现有方法并开发自己的新探测器,从而为不断增长的研究社区服务。代码和型号可在以下网站获得 |
| Machine-Assisted Map Editing Authors Favyen Bastani, Songtao He, Sofiane Abbar, Mohammad Alizadeh, Hari Balakrishnan, Sanjay Chawla, Sam Madden 今天制定道路网络是劳动密集型的。因此,许多国家的路线图在城市中心以外的覆盖率很低。已经提出了从航空图像和GPS轨迹自动推断道路网络图的系统,以改善道路地图的覆盖范围。但是,由于错误率很高,映射社区尚未采用这些系统。我们提出机器辅助地图编辑,其中自动地图推理被集成到现有的,以人为中心的地图编辑工作流程中。为了实现这一点,我们构建了机器辅助iD MAiD,我们使用机器辅助功能扩展了基于Web的OpenStreetMap编辑器iD。我们用一种新颖的方法来补充MAiD,该方法用于从航拍图像推断道路拓扑,其结合了先前分割方法的速度和先前迭代图形构造方法的准确性。我们设计MAiD来解决在现有地图覆盖率较差的地区增加主要干道,以及在已经绘制主要道路的地区逐步改善覆盖范围。我们进行了两项用户研究,发现当参与者获得固定时间绘制道路时,他们可以使用MAiD增加多达3.5倍的道路。 |
| Particle Swarm Optimization for Great Enhancement in Semi-Supervised Retinal Vessel Segmentation with Generative Adversarial Networks Authors Qiang Huo 基于深度学习的视网膜血管分割需要大量手动标记数据。这是耗时,费力和专业的。更糟糕的是,获取丰富的眼底图像很困难。由于存在异常,血管的大小和形状不同,不均匀的照射和解剖学变化,这些问题更加严重。在本文中,我们提出了一个数据有效的半监督学习框架,它有效地结合了现有的深度学习网络与GAN和自我培训的想法。针对半监督学习超参数调整的难度,提出了一种基于粒子群优化算法的超参数选择方法。据我们所知,这项工作是第一次将智能优化与半监督学习相结合以实现最佳性能的演示。在对抗性学习,自我训练和PSO的协作下,选择最佳超参数,我们获得的视网膜血管分割的性能接近或甚至优于代表性的监督学习,仅使用来自DRIVE的标记数据的十分之一。 |
| Boosting Supervision with Self-Supervision for Few-shot Learning Authors Jong Chyi Su, Subhransu Maji, Bharath Hariharan 我们提出了一种技术,通过引入自监督任务作为辅助损失函数来提高在小标记数据集上学习的深度表示的可转移性。虽然最近的自我监督学习方法已经显示了对大型未标记数据集进行培训的好处,但我们发现即使在小型数据集上以及与强有力的监督相结合时,也可以改进泛化。具有自我监督损失的学习表示在几个镜头学习基准上降低了现有技术元学习者的相对错误率,并且在从头开始训练时降低了标准分类任务的现成深度网络。我们发现自我监督的好处随着任务的难度而增加。我们的方法利用数据集中的图像来构建自我监督的损失,因此是学习可转移表示的有效方式,而不依赖于任何外部训练数据。 |
| Exemplar Guided Face Image Super-Resolution without Facial Landmarks Authors Berk Dogan, Shuhang Gu, Radu Timofte 如今,由于无处不在的视觉媒体,存在大量已经可用的高分辨率HR脸部图像。因此,为了超分辨人的给定的非常低分辨率的LR面部图像,很可能找到可用于指导该过程的同一人的另一个HR面部图像。在本文中,我们提出了一种基于卷积神经网络CNN的解决方案,即GWAInet,它将超分辨率SR应用于由同一个人的另一个无约束HR面部图像引导的面部图像上,可能在年龄,表情,姿势或尺寸。 GWAInet以对抗性生成方式进行训练,以产生所需的高质量感知图像结果。 HR引导图像的利用通过使用将其内容与输入图像对齐的整经器子网络以及对来自弯曲引导图像和输入图像的提取特征的特征融合链的使用来实现。在训练中,身份丢失进一步有助于通过最小化SR和HR地面真实图像的嵌入向量之间的距离来保持身份相关特征。与面部超分辨率的现有技术水平相反,我们的方法不需要用于其训练的面部标志点,这有助于其稳健性并且允许其以均匀的方式为周围的面部区域产生精细的细节。我们的方法GWAInet以升序因子8x产生照片逼真图像,并且在数量和感知质量方面优于现有技术水平。 |
| Towards Real-Time Action Recognition on Mobile Devices Using Deep Models Authors Chen Lin Zhang, Xin Xin Liu, Jianxin Wu 动作识别是计算机视觉中的一项重要任务,并且开发了许多方法以将其推向极限。然而,当前的动作识别模型具有巨大的计算成本,其不能部署到移动设备上的现实世界任务中。在本文中,我们首先说明实时动作识别的设置,这与当前动作识别推理设置不同。在新的推理设置下,我们根据经验研究了Kinetics数据集上的最新动作识别模型。我们的结果表明,设计高效的实时动作识别模型不同于设计高效的ImageNet模型,尤其是在权重初始化中。我们展示了ImageNet上经过预先训练的权重可以提高实时动作识别设置下的准确性。最后,我们使用手势识别任务作为案例研究来评估我们在移动电话上的实际应用中的紧凑实时动作识别模型。结果表明,我们的动作识别模型速度提高了6倍,并且具有与现有技术相似的精度,可以大致满足移动设备的实时要求。据我们所知,这是第一篇在移动设备上部署当前深度学习动作识别模型的论文。 |
| Semi-Supervised Semantic Mapping through Label Propagation with Semantic Texture Meshes Authors Radu Alexandru Rosu, Jan Quenzel, Sven Behnke 场景理解是机器人在非结构化环境中行动的重要能力。虽然大多数SLAM方法提供场景的几何表示,但语义地图对于与周围环境的更复杂的交互是必要的。当前的方法将语义映射视为几何的一部分,这限制了可伸缩性和准确性。我们建议将语义地图表示为几何网格和以独立分辨率耦合的语义纹理。关键的想法是,在许多环境中,几何形状可以大大简化而不会失去保真度,而语义信息可以以更高的分辨率存储,而与网格无关。我们从深度传感器构造网格以表示场景几何,并将信息融合到来自场景的各个RGB视图的分段的语义纹理中。使语义在全局网格中持久化使我们能够强制执行各个视图预测的时间和空间一致性。为此,我们提出了一种通过迭代地重新训练语义分割与存储在地图内的信息并使用重新训练的分割来重新融合语义来在各个分割之间建立共识的有效方法。我们通过重建来自NYUv2的场景的语义地图和跨越大型建筑物的场景来展示我们的方法的准确性和可扩展性。 |
| Trimmed Action Recognition, Dense-Captioning Events in Videos, and Spatio-temporal Action Localization with Focus on ActivityNet Challenge 2019 Authors Zhaofan Qiu, Dong Li, Yehao Li, Qi Cai, Yingwei Pan, Ting Yao 本笔记本文件介绍了我们为ActivityNet Challenge 2019修剪动作识别,视频中的密集字幕事件和时空动作本地化中的以下三个任务而设计的系统的概述和比较分析。 |
| Hallucinated Adversarial Learning for Robust Visual Tracking Authors Qiangqiang Wu, Zhihui Chen, Lin Cheng, Yan Yan, Bo Li, Hanzi Wang 人类可以从一个单一的范例中轻松地学习新的概念,这主要是因为他们具有非凡的想象力或幻觉能够在不同环境中看不见的样本。结合这种对被跟踪实例的各种新样本产生幻觉的能力可以帮助跟踪器减轻低数据跟踪状态中的过度拟合问题。为实现这一目标,我们提出了一种有效的对抗方法,表示为对抗性幻觉AH,用于稳健的视觉跟踪。所提出的AH被设计为首先在一对相同的身份实例之间学习可转移的非线性变形,然后将这些变形应用于看不见的跟踪实例,以便生成不同的正训练样本。通过通过检测框架将AH结合到在线跟踪中,我们提出了幻觉对抗跟踪器HAT,其以端对端方式联合优化AH与在线分类器,例如MDNet。此外,提出了一种新颖的选择性变形转移SDT方法,以更好地选择更适合转移的变形。对3个流行基准测试的广泛实验表明,我们的HAT实现了最先进的性能。 |
| Multi-Scale Convolutions for Learning Context Aware Feature Representations Authors Nikolai Ufer, Kam To Lui, Katja Schwarz, Paul Warkentin, Bj rn Ommer 寻找语义对应是一个具有挑战性的问题。随着CNN的突破,更强的功能可用于分类等任务,但不是专门针对语义匹配的要求。在下文中,我们提出了一种弱监督的度量学习方法,通过编码比以前的方法更多的上下文来生成更强的特征。首先,我们使用几何通知的对应挖掘方法生成更合适的训练数据,该方法不太容易进行虚假匹配,并且仅需要图像类别标签作为监督。其次,我们引入了一个新的卷积层,它是不同步幅卷积的学习混合,允许网络隐式编码更多上下文,同时保持匹配精度。特征方面的强几何编码使我们能够学习语义流网络,该网络比基于参数变换的模型生成更自然的变形,并且能够同时联合预测前景区域。我们的语义流网络在几个语义匹配基准测试中优于当前的技术水平,并且学习的特征在简单的最近邻居匹配方面表现出惊人的性能。 |
| EnlightenGAN: Deep Light Enhancement without Paired Supervision Authors Yifan Jiang, Xinyu Gong, Ding Liu, Yu Cheng, Chen Fang, Xiaohui Shen, Jianchao Yang, Pan Zhou, Zhangyang Wang 基于深度学习的方法在图像恢复和增强方面取得了显着的成功,但是当缺乏配对的训练数据时它们仍然具有竞争力。作为一个这样的例子,本文探讨了低光图像增强问题,在实践中它极具挑战性同时拍摄同一视觉场景的低光和普通光照。我们提出了一种高效的无监督生成对抗网络,称为EnlightenGAN,可以在没有低正常光图像对的情况下进行训练,但证明可以很好地概括各种真实世界的测试图像。我们建议使用从输入本身提取的信息来规范非配对训练,并对低光图像增强问题进行基准测试,包括全局局部鉴别器结构,自我正则化,而不是使用地面实况数据来监督学习。感知损失融合和注意机制。通过大量实验,我们提出的方法在视觉质量和主观用户研究方面优于各种指标下的近期方法。由于非配对培训带来了极大的灵活性,EnlightenGAN可以很容易地适应各种领域的现实世界图像。该代码可在网址获取 |
| Noisy-As-Clean: Learning Unsupervised Denoising from the Corrupted Image Authors Jun Xu, Yuan Huang, Li Liu, Fan Zhu, Xingsong Hou, Ling Shao 在过去几年中,监督网络在图像去噪方面取得了很好的成绩。这些方法从大量嘈杂和干净的图像中学习图像先验和合成噪声统计。最近,仅使用外部噪声图像进行训练,提出了几种无监督的去噪网络。然而,从外部数据学习的网络固有地受到域间隙困境的影响,即,训练数据和损坏的测试图像之间的图像先验和噪声统计非常不同。在处理真实照片中依赖于信号的真实噪声时,这种困境变得更加清晰。在这项工作中,我们提供了一个统计上有用的结论,可以仅使用损坏的图像来学习无监督网络,近似于使用成对的噪声和干净图像学习的监督网络的最佳参数。这是通过提出一种嘈杂的清洁策略来实现的,该策略将损坏的图像作为清洁目标,并且基于损坏的图像作为输入的模拟噪声图像。大量实验表明,采用我们的Noisy As Clean策略学习的无监督去噪网络在去除几种典型的合成噪声和逼真噪声方面令人惊讶地优于以前的监督网络。该代码将公开发布。 |
| Multi-task Learning For Detecting and Segmenting Manipulated Facial Images and Videos Authors Huy H. Nguyen, Fuming Fang, Junichi Yamagishi, Isao Echizen 检测被操纵的图像和视频是数字媒体取证中的一个重要主题。大多数检测方法使用二进制分类来确定查询被操纵的概率。另一个重要的主题是定位操纵区域,即执行分割,其主要由三种常用的攻击移除,复制移动和拼接创建。我们设计了一个卷积神经网络,它使用多任务学习方法同时检测被操纵的图像和视频,并为每个查询定位操纵区域。通过执行一项任务获得的信息与另一项任务共享,从而提高两项任务的性能。半监督学习方法用于改善网络的可生成性。该网络包括编码器和Y形解码器。编码特征的激活用于二进制分类。解码器的一个分支的输出用于分割操纵区域,而另一个分支的输出用于重建输入,这有助于提高整体性能。使用FaceForensics和FaceForensics数据库的实验证明了网络对面部重演攻击和面部交换攻击的有效性,以及它处理先前看到的攻击的不匹配条件的能力。此外,仅使用少量数据进行微调就可以使网络处理看不见的攻击。 |
| Hierarchical Back Projection Network for Image Super-Resolution Authors Zhi Song Liu, Li Wen Wang, Chu Tak Li, Wan Chi Siu 基于深度学习的单图像超分辨率方法使用大量的训练数据集,并且最近在数量和质量上都取得了很好的质量进展。大多数深度网络都专注于通过残差学习从低分辨率输入到高分辨率输出的非线性映射,而无需探索特征抽象和分析。我们提出了一种分层反向投影网络HBPN,它将多个HourGlass HG模块级联到所有尺度的自下而上和自上而下的过程特征,以捕获各种空间相关性,然后整合最佳的重建表示。我们在我们提出的网络中采用反投影块来提供误差相关的上下采样过程,以取代简单的反卷积和合并过程,以便更好地进行估计。基于Softmax的新加权重建WR过程用于组合HG模块的输出,以进一步提高超分辨率。包括真实图像超分辨率挑战的验证数据集NTIRE2019在内的各种数据集的实验结果表明,我们提出的方法可以实现并改善不同比例因子的现有技术方法的性能。 |
| NLH: A Blind Pixel-level Non-local Method for Real-world Image Denoising Authors Yingkun Hou, Jun Xu, Mingxia Liu, Guanghai Liu, Li Liu, Fan Zhu, Ling Shao 非局部自相似性NSS是用于图像去噪的自然图像的强大先验。大多数现有的去噪方法使用类似的补丁,这是补丁级NSS先验。在本文中,我们通过引入像素级NSS先前向前迈出一步,即在非局部区域上搜索相似像素。这是因为发现密切相似的像素比自然图像中的类似斑块更可行,这可以用于增强图像去噪性能。利用引入的像素级NSS先验,我们提出了一种精确的噪声水平估计方法,然后开发了基于提升Haar变换和Wiener滤波技术的盲图像去噪方法。对基准数据集的实验表明,所提出的方法在现实世界图像去噪方面比现有技术方法获得了更好的性能。代码将被释放。 |
| Spatio-Temporal Fusion Networks for Action Recognition Authors Sangwoo Cho, Hassan Foroosh 基于视频的CNN工作集中于融合外观和运动网络的有效方式,但它们通常缺乏利用视频帧上的时间信息。在这项工作中,我们提出了一个新颖的时空融合网络STFN,它集成了整个视频的外观和运动信息的时间动态。然后聚合捕获的时间动态信息以获得更好的视频级表示并通过端到端训练学习。时空融合网络由两组残余初始块组成,它们提取时间动态和外观和运动特征的融合连接。 STFN的优势在于它可以捕获互补数据的本地和全球时间动态,以学习视频广泛的信息,并且它适用于任何视频分类网络以提高性能。我们探索了STFN的各种设计选择,并验证了消融研究如何改变网络性能。我们在两个具有挑战性的人类活动数据集UCF101和HMDB51上进行实验,并通过最佳网络实现最先进的结果。 |
| A Fusion Adversarial Network for Underwater Image Enhancement Authors Jingjing Li, Hanyu Li 水下图像增强算法在水下视觉任务中引起了广泛关注。然而,这些算法主要在不同的数据集和不同的度量上进行评估。在本文中,我们建立了一个有效的公共水下测试数据集U45,包括水下降水效果的低色度,低对比度和雾霾效应,并提出了一个融合对抗网络来增强水下图像。同时,设计了包括Lgt损失和Lfe损失在内的对抗性损失,分别关注地面实况的图像特征和融合增强方法增强的图像特征。所提出的网络有效地校正了色偏,并且用更少的参数拥有更快的测试时间。 U45数据集的实验结果表明,所提出的方法在定性和定量评估方面实现了比其他现有技术方法更好或相当的性能。此外,消融研究证明了每个组件的贡献,并且应用测试进一步显示了增强图像的有效性。 |
| A Temporal Sequence Learning for Action Recognition and Prediction Authors Sangwoo Cho, Hassan Foroosh 在这项工作脚注中这项工作部分由国家科学基金会资助IIS 1212948支持。我们提出了一种方法来表示具有一系列单词的视频,并学习这些单词的时间顺序作为预测和预测的关键信息。认识到人类行为。我们利用句子分类中使用的自然语言处理NLP文献中的核心概念来解决动作预测和动作识别的问题。使用Bag of Visual Words BoW编码方法将每个帧转换为表示为向量的单词。然后将这些单词组合成一个句子来表示视频,作为一个句子。使用简单但有效的时间卷积神经网络CNN来学习不同动作中的单词序列,其捕获视频句子中的信息的时间顺序。我们证明了所提出方法的一个关键特征是其低延迟,即其用部分序列句准确预测动作的能力。对两个数据集(textit UCF101和textit HMDB51)的实验表明,该方法在视频帧的一半内平均达到95的精度。结果还表明,除了动作预测之外,我们的方法在动作识别中即在句子完成时实现了兼容的现有技术性能。 |
| Three-Dimensional Fourier Scattering Transform and Classification of Hyperspectral Images Authors Ilya Kavalerov, Weilin Li, Wojciech Czaja, Rama Chellappa 最近的研究已经产生了许多新技术,能够捕获高光谱图像分析的高光谱数据的特殊属性,高光谱图像分类是最活跃的任务之一。时频方法将光谱分解为多光谱带,而诸如神经网络的分层方法结合了尺度上的空间信息并且模拟光谱特征之间的多个依赖性水平。傅立叶散射变换是时间频率表示与神经网络架构的融合,最近已经证明这两者在频谱空间分类方面提供了显着的进步。我们在四个标准高光谱数据集上测试所提出的三维傅里叶散射方法,并且呈现的结果表明,与其他现有技术的光谱空间分类方法相比,傅立叶散射变换在表示光谱数据方面非常有效。 |
| Panoptic Image Annotation with a Collaborative Assistant Authors Jasper R. R. Uijlings, Mykhaylo Andriluka, Vittorio Ferrari 本文旨在减少为全景分割任务注释图像的时间,这需要为所有对象实例和填充区域添加分段掩码和类标签。我们将我们的方法制定为注释器和自动化助理代理之间的协作过程,后者轮流使用预定义的段池共同注释图像。注释器执行的动作充当强大的上下文信号。助手通过预测注释器的未来动作来智能地响应该信号,然后注释器自己执行。这减少了注释器所需的工作量。在COCO全景数据集Caesar18cvpr,Kirillov18arxiv,Lin14eccv上的实验表明,我们的方法比最近的Andriluka18acmmm机器辅助界面快17 27。与传统的手动多边形绘图Russel08ijcv相比,这相当于加速了4倍。 |
| Back-Projection based Fidelity Term for Ill-Posed Linear Inverse Problems Authors Tom Tirer, Raja Giryes 在许多图像处理应用中出现了病态的线性逆问题,例如去模糊,超分辨率和压缩感知。许多恢复策略涉及最小化成本函数,其由保真度和先前项组成,由正则化参数平衡。虽然大量研究都集中在不同的先验模型上,但保真度项几乎总是被选择为最小二乘LS目标,这鼓励将线性变换的优化变量拟合到观察中。在这项工作中,我们研究了一个不同的保真度项,最近提出的迭代去噪和后向投影IDBP框架已经隐含地使用了这个术语。该术语鼓励优化变量的投影到线性算子的行空间和应用于观察的线性算子反投影的伪逆之间的一致。我们分析地检验了Tikhonov正则化的两个保真度项之间的差异,并确定了新术语优于标准LS术语的情况。此外,我们在经验上证明了复杂凸和非凸先验的两个诱导成本函数的行为,例如总变差,BM3D和深度生成模型,与所获得的理论分析相关。 |
| Floors are Flat: Leveraging Semantics for Real-Time Surface Normal Prediction Authors Steven Hickson, Karthik Raveendran, Alireza Fathi, Kevin Murphy, Irfan Essa 我们提出了4个有助于显着改善深度学习模型性能的见解,这些模型可以从单个RGB图像中预测表面法线和语义标签。这些见解是训练集中的地面真实表面法线的1个去噪,以确保与实际和合成数据的混合上同时训练的语义标签2的一致性,而不是在实际3上预处理合成和微调,使用a来共同预测法线和语义。共享模型,但只有具有有效训练标签的像素的反向传播错误4使模型变细并使用灰度而不是颜色输入。尽管这些步骤非常简单,但我们使用在标准手机上以12 fps运行的模型,在几个数据集上展示了持续改进的结果。 |
| On the Self-Similarity of Natural Stochastic Textures Authors Samah Khawaled, Yehoshua Y. Zeevi 自相似性是分形图像的本质,因此,表征自然随机纹理。本文关注的是在包含随机纹理和结构主要确定性信息的完全纹理图像的情况下统计意义上的自相似性。我们首先将纹理图像分解为与其纹理和结构相对应的两层,并且表明表示随机纹理的层的特征在于均匀分布的随机相位,而不是相干的结构化信息的相位。通过使用合适的假设检验框架来验证随机相的均匀分布。我们继续提出两种评估自相似性的方法。第一种是基于互补信息的补丁计算,而第二种是衡量跨尺度存在的互信息。通过互信息量化自相似程度对于在医学成像,地质学,农业和计算机视觉算法中遇到的自然随机纹理的分析是至关重要的,所述自然随机纹理被设计用于在完全纹理图像上应用。 |
| Defending Against Adversarial Attacks Using Random Forests Authors Yifan Ding, Liqiang Wang, Huan Zhang, Jinfeng Yi, Deliang Fan, Boqing Gong 随着深度神经网络DNN变得越来越重要和流行,DNN的稳健性是互联网和物理世界安全的关键。不幸的是,最近的一些研究表明,难以与实际例子区别开来的对抗性例子很容易欺骗DNN并操纵他们的预测。在观察到对抗性示例主要是通过基于梯度的方法生成时,在本文中,我们首先提出使用一种简单但非常有效的非可微混合模型,该模型结合了DNN和随机森林,而不是隐藏攻击者的渐变,以抵御攻击。我们的实验表明,我们的模型可以成功地完全抵御白盒攻击,具有较低的可转移性,并且对三种代表性的黑盒攻击类型具有很强的抵抗力,同时,我们的模型实现了与原始DNN类似的分类精度。最后,我们调查并建议一个标准来定义在DNN中种植随机森林的位置。 |
| Deep Recurrent Quantization for Generating Sequential Binary Codes Authors Jingkuan Song, Xiaosu Zhu, Lianli Gao, Xin Shun Xu, Wu Liu, Heng Tao Shen 量化由于其高精度和快速搜索速度,已成为ANN近似最近邻搜索中的有效技术。为了满足不同应用的要求,在检索精度和速度之间总是存在折衷,这反映在可变代码长度上。但是,要将数据集编码为不同的代码长度,现有方法需要训练多个模型,其中每个模型只能生成特定的代码长度。这导致相当大的训练时间成本,并且在很大程度上降低了在实际应用中部署的量化方法的灵活性。为了解决这个问题,我们提出了一种深度递归量化DRQ架构,它可以生成顺序二进制码。最后,当训练模型时,可以生成一系列二进制代码,并且可以通过调整循环迭代次数来容易地控制代码长度。共享码本和标量因子被设计为深度递归量化块中的可学习权重,并且可以以端到端方式训练整个框架。据我们所知,这是第一种可以训练一次并生成顺序二进制代码的量化方法。基准数据集上的实验结果表明,与图像检索的现有技术相比,我们的模型实现了可比较的甚至更好的性能。但它需要的参数和训练时间明显减少。我们的代码在线发布 |
| Beyond Product Quantization: Deep Progressive Quantization for Image Retrieval Authors Lianli Gao, Xiaosu Zhu, Jingkuan Song, Zhou Zhao, Heng Tao Shen 产品量化PQ长期以来一直是以非常低的内存时间成本生成指数级大型码本的主流。尽管PQ成功,但对于高维向量空间的分解仍然很棘手,并且当代码长度改变时,模型的重新训练通常是不可避免的。在这项工作中,我们提出了深度渐进量化DPQ模型,作为PQ的替代,用于大规模图像检索。 DPQ顺序学习量化代码并逐步逼近原始特征空间。因此,我们可以同时训练具有不同码长的量化码。具体而言,我们首先利用标签信息来指导视觉特征的学习,然后应用几个量化块逐步接近视觉特征。每个量化块被设计为卷积神经网络的一层,并且整个框架可以以端到端的方式进行训练。基准数据集上的实验结果表明,我们的模型明显优于图像检索的最新技术水平。我们的模型针对不同的代码长度进行一次训练,因此需要较少的计算时间额外的消融研究证明了我们提出的模型的每个组成部分的效果。我们的代码发布于 |
| On training deep networks for satellite image super-resolution Authors Michal Kawulok, Szymon Piechaczek, Krzysztof Hrynczenko, Pawel Benecki, Daniel Kostrzewa, Jakub Nalepa 近来,通过使用深度卷积神经网络,显着改善了用于增强图像空间分辨率的超分辨率重建SRR技术的能力。通常,这种网络是使用由原始图像组成的大型训练集以及它们的低分辨率对应物来学习的,这些训练集通过双三次下采样获得。在本文中,我们研究了SRR性能如何受到获得这种低分辨率训练数据的方式的影响,这种数据尚未被研究过。我们广泛的实验研究表明,训练数据特征对重建精度有很大影响,广泛采用的方法对于处理卫星图像并不是最有效的。总的来说,我们认为开发更好的培训数据准备程序可能是使SRR适合现实世界应用的关键。 |
| Learning Part Generation and Assembly for Structure-aware Shape Synthesis Authors Jun Li, Chengjie Niu, Kai Xu 学习用于3D形状合成的深度生成模型在很大程度上受到难以生成具有正确拓扑和合理几何形状的合理形状的限制。实际上,即使在相同的形状类别中,考虑到3D物体的显着拓扑变化,学习似乎合理的3D形状的分布对于大多数现有的,结构遗忘形状表示来说似乎是艰巨的任务。基于三维形状分析的共识,形状结构被定义为零件组成和零件之间的相互关系,我们建议使用深度生成网络(部分意识和关系意识)对3D形状变化进行建模,命名为PARANet。网络由每个部分的VAE GAN阵列组成,生成构成完整形状的语义部分,然后是部件组装模块,其估计每个部件的变换以将它们关联并组装成合理的结构。通过将零件组成和零件关系的生成分成单独的网络,大大减少了对三维形状的结构变化进行建模的难度。我们通过大量实验证明,PARANet生成具有合理,多样和详细结构的3D形状,并展示了两种原型应用的语义形状分割和形状集演化。 |
| STAR: A Structure and Texture Aware Retinex Model Authors Jun Xu, Mengyang Yu, Li Liu, Fan Zhu, Dongwei Ren, Yingkun Hou, Haoqian Wang, Ling Shao Retinex理论主要是通过分析局部图像导数将图像分解为光照和反射分量。在该理论中,较大的导数归因于分段恒定反射率的变化,而较小的导数出现在平滑照明中。在本文中,我们建议利用带有观测图像的指数伽马的指数导数,当用γ1放大时产生结构图,当用γ1收缩时产生纹理图。为此,我们设计了局部导数的指数滤波器,并展示了它们提取精确结构和纹理图的能力,受到局部导数上指数γ选择的影响。提取的结构和纹理图用于调整Retinex分解中的照明和反射分量。还提出了一种新颖的结构和纹理感知Retinex STAR模型,用于单个图像的照射和反射分解。我们以交替最小化的方式解决STAR模型。每个子问题都转换为带有闭合形式解的矢量化最小二乘回归。综合实验表明,与先前的竞争方法相比,所提出的STAR模型在照明和反射率估计,低光图像增强和颜色校正方面产生更好的定量和定性性能。该代码将公开发布。 |
| Mixture separability loss in a deep convolutional network for image classification Authors Trung Dung Do, Cheng Bin Jin, Hakil Kim, Van Huan Nguyen 在机器学习中,成本函数至关重要,因为它衡量系统的好坏。在图像分类中,众所周知的网络仅考虑修改网络结构并在网络末端应用交叉熵损失。然而,仅使用交叉熵损失导致网络在所有训练图像被正确分类时停止更新权重。这是早期饱和的问题。本文提出了一种新的成本函数,称为混合分离性损失MSL,即使在大多数训练图像被准确预测时,它也会更新网络的权重。 MSL由班级和班级损失组成。在类丢失之间最大化类间图像之间的差异,而在类丢失内最小化类内图像之间的相似性。我们设计了所提出的损失函数以附加到网络中的不同卷积层,以便利用中间特征映射。实验表明,具有MSL的网络加深了学习过程,并通过一些公共数据集获得了有希望的结果,例如Street View House Number SVHN,加拿大高级研究CIFAR研究所和我们自己收集的Inha计算机视觉实验室ICVL性别数据集。 |
| Image Captioning with Integrated Bottom-Up and Multi-level Residual Top-Down Attention for Game Scene Understanding Authors Jian Zheng, Sudha Krishnamurthy, Ruxin Chen, Min Hung Chen, Zhenhao Ge, Xiaohua Li 近年来,图像字幕引起了相当多的关注。然而,对于具有一些独特特征和要求的游戏图像字幕的工作很少。在这项工作中,我们提出了一种新颖的游戏图像字幕模型,它将自下而上的注意力与新的多级残留自上而下的注意机制相结合。首先,将较低级别的残留自上而下注意网络添加到基于快速R CNN的自下而上注意网络,以解决后者在提取区域特征时可能丢失重要空间信息的问题。其次,在字幕生成网络中实现上层残留自上而下注意网络,以更好地融合所提取的区域特征以用于后续字幕预测。我们创建了两个游戏数据集来评估所提出的模型。大量实验表明,我们提出的模型优于现有的基线模型。 |
| Uncovering Why Deep Neural Networks Lack Robustness: Representation Metrics that Link to Adversarial Attacks Authors Danilo Vasconcellos Vargas, Shashank Kotyan, Moe Matsuki 神经网络已被证明易受对抗样本的影响。略微扰动的输入图像能够改变准确模型的分类,表明所学习的表示不如以前好 |
| REMAP: Multi-layer entropy-guided pooling of dense CNN features for image retrieval Authors Syed Sameed Husain, Miroslaw Bober 本文讨论了大规模图像检索的问题,着重于提高其准确性和鲁棒性。我们将搜索的增强稳健性定位到诸如照明变化,对象外观和比例,部分遮挡以及杂乱背景等因素,这些因素在具有显着可变性的非常大的数据集上执行搜索时尤为重要。我们提出了一种新的基于CNN的全局描述符,称为REMAP,它学习并聚合来自多个CNN层的深层特征的层次结构,并且以三元组丢失进行端到端训练。 REMAP明确地学习了在视觉抽象的各种语义层面上相互支持和互补的判别特征。在聚合成单个图像级别描述符之前,这些密集的局部特征在多层重叠区域内的每一层在空间上最大地汇集。为了识别用于检索的语义上有用的区域和层,我们建议使用KL散度来测量每个区域和层的信息增益。我们的系统在培训期间有效地学习各种区域和层的有用性并相应地加权。我们证明这种相对熵引导的聚合优于由SGD控制的经典的基于CNN的聚合。整个框架以端到端的方式进行培训,优于最新的最新技术成果。在图像检索数据集Holidays,Oxford和MPEG上,REMAP描述符分别达到95.5,91.5和80.1的mAP,优于迄今发布的任何结果。 REMAP还成为了Kaggle Google Landmark Retrieval Challenge的获奖提交的核心。 |
| DeepMOT: A Differentiable Framework for Training Multiple Object Trackers Authors Yihong Xu, Yutong Ban, Xavier Alameda Pineda, Radu Horaud 多目标跟踪精度和精度MOTA和MOTP是评估多个目标跟踪器质量的两个标准和广泛使用的指标。它们专门用于编码跟踪多个对象的挑战和困难。基于MOTA和MOTP直接优化跟踪器是很困难的,因为这两个指标都非常依赖匈牙利算法,这是不可微分的。我们为MOTA和MOTP提出了一个可微分的代理,从而允许通过直接优化标准MOT度量的代理来训练深度多目标跟踪器。所提出的近似是基于双向递归网络,其将对象输入到假设距离矩阵并将最优假设输出到对象关联,从而模拟匈牙利算法。在可微分模块之后,估计的关联用于计算MOTA和MOTP。实验研究证明了这种可区分框架对两个最近的深度跟踪器相对于MOT17数据集的好处。此外,该代码可从公开获得 |
| IMP: Instance Mask Projection for High Accuracy Semantic Segmentation of Things Authors Cheng Yang Fu, Tamara L. Berg, Alexander C. Berg 在这项工作中,我们提出了一个名为Instance Mask Projection IMP的新算子,它将预测的实例分割作为语义分割的新特征。它还支持反向传播,因此可以端到端训练。我们的实验显示了IMP对具有复杂分层,大变形和非凸对象的服装解析以及具有许多重叠实例和小对象的街道场景分割的有效性。在各种服装解析数据集VCP上,我们展示了实例掩模投影可以通过最先进的Panoptic FPN分割方法在mIOU上提高3个点。在ModaNet服装解析数据集上,与现有的基线语义分割结果相比,我们显示出绝对的20.4的显着改进。此外,实例蒙版投影算子在其他非服装数据集上运行良好,在城市景观的Thing类上提供了3个点的改进,这是一种自驱动数据集,基于最先进的方法。 |
| EXTD: Extremely Tiny Face Detector via Iterative Filter Reuse Authors YoungJoon Yoo, Dongyoon Han, Sangdoo Yun 在本文中,我们提出了一种新的多尺度人脸检测器,它具有极少数参数EXTD,小于10万,并且具有与深重探测器相当的性能。虽然现有的多尺度人脸检测器从单个骨干网络中提取具有不同尺度的特征图,但是我们的方法通过迭代地重用共享的轻量级和浅层骨干网来生成特征图。骨干网络的这种迭代共享显着减少了参数的数量,并且还提供了从网络层的较高级捕获到较低级别的特征映射的抽象图像语义。所提出的想法被各种模型架构采用并通过大量实验进行评估。通过WIDER FACE数据集的实验,我们证明了所提出的人脸探测器可以处理具有不同尺度和条件的面,并且实现了与更大质量的面部探测器相当的性能,这些探测器在模型尺寸和浮点操作中重量只有几百倍和几十倍。 |
| Single Image Super-resolution via Dense Blended Attention Generative Adversarial Network for Clinical Diagnosis Authors Kewen Liu, Yuan Ma, Hongxia Xiong, Zejun Yan, Zhijun Zhou, Chaoyang Liu, Panpan Fang, Xiaojun Li, Yalei Chen 在临床诊断中,医生能够在高分辨率HR医学图像的帮助下更清晰地看到生物组织和早期病变,这对提高诊断准确性至关重要。为了解决医学图像由于缺乏高频细节而导致严重模糊的问题,本文通过密集神经网络和混合注意机制开发了一种新的图像超分辨率SR算法SR DBAN。具体地,提出了一种新的混合注意块并将其引入到密集神经网络DenseNet中,使得神经网络可以自适应地将更多的注意力集中在具有足够高频细节的区域和信道上。在SR DBAN的框架中,原始DenseNet中的批量标准化层被移除以避免高频纹理细节的丢失,最终的HR图像通过网络的最末端的解卷积获得。此外,受生成对抗网络令人印象深刻的表现的启发,本文通过密集的混合注意生成对抗网络开发了一种名为SR DBAGAN的新型图像SR算法。 SR DBAGAN包括一个生成器和一个鉴别器,生成器使用我们提出的SR DBAN生成HR图像并试图欺骗鉴别器,同时基于Wasserstein GAN WGAN设计鉴别器来区分。我们在模糊的前列腺MRI图像上部署了我们的算法,实验结果表明,与主流插值相比,我们提出的算法产生了相当大的清晰度和纹理细节,并且分别在峰值信噪比PSNR和结构相似性指数SSIM上有显着改善。基于深度学习的图像SR算法,充分证明了我们提出的算法的有效性和优越性。 |
| Mask Based Unsupervised Content Transfer Authors Ron Mokady, Sagie Benaim, Lior Wolf, Amit Bermano 我们考虑以无人监督的方式在两个域之间进行翻译的问题,其中一个域包含一些与另一个相比的附加信息。所提出的方法解开了这些域的共同和独立部分,并且通过生成掩模,将底层网络的注意力集中在期望的增强上,而不会浪费地重建整个目标。这通过广泛的定量和定性评估显示了现有技术的质量和各种内容翻译。此外,基于掩模的新颖公式和正则化足够精确以在弱监督分割领域中实现现有技术性能,其中仅给出类别标签。据我们所知,这是第一个解决域解除问题和弱监督分割问题的报告。我们的代码是公开的 |
| Image-based 3D Object Reconstruction: State-of-the-Art and Trends in the Deep Learning Era Authors Xian Feng Han, Hamid Laga, Mohammed Bennamoun 3D重建是一个长期存在的不良问题,数十年来一直由计算机视觉,计算机图形学和机器学习社区进行探索。自2015年以来,使用卷积神经网络CNN的基于图像的3D重建已引起越来越多的关注并且表现出令人印象深刻的性能。鉴于这个快速发展的新时代,本文对该领域的最新发展进行了全面的调查。我们专注于使用深度学习技术从单个或多个RGB图像估计通用对象的3D形状的工作。我们根据形状表示,网络架构和他们使用的培训机制组织文献。虽然本调查旨在用于重建通用对象的方法,但我们还回顾了一些最近的工作,这些工作主要关注特定的对象类,如人体形状和面部。我们对一些重要论文的表现进行了分析和比较,总结了该领域的一些开放性问题,并讨论了未来研究的有希望的方向。 |
| MV-C3D: A Spatial Correlated Multi-View 3D Convolutional Neural Networks Authors Qi Xuan, Fuxian Li, Yi Liu, Yun Xiang 随着深度神经网络的发展,3D对象识别在计算机视觉领域越来越受欢迎。提出了许多基于多视图的方法来提高类别识别准确度。这些方法主要依赖于以整个圆周渲染的多视图图像。然而,在现实世界的应用中,3D对象主要是在较小范围内的部分视点中观察到的。因此,我们提出了一种基于多视图的3D卷积神经网络,其仅将连续多视图图像的一部分作为输入并且仍然可以保持高精度。此外,我们的模型将这些视图图像作为联合变量,以使用3D卷积和3D最大池化层更好地学习空间相关特征。 ModelNet10和ModelNet40数据集上的实验结果表明,我们的MV C3D技术可以在多视图图像中实现出色的性能,这些图像是从具有较小范围的部分角度捕获的。 3D旋转真实图像数据集MIRO的结果进一步证明了MV C3D在现实世界场景中更具适应性。随着观看图像数量的增加,可以进一步提高分类精度。 |
| Delving into 3D Action Anticipation from Streaming Videos Authors Hongsong Wang, Jiashi Feng 旨在通过部分观察来识别行动的行动预期由于广泛的应用而变得越来越流行。在本文中,我们研究了流媒体视频中3D动作预期的问题,目的是了解解决此问题的最佳实践。我们首先介绍几种互补的评估指标,并提出基于框架动作分类的基本模型。为了获得更好的性能,我们接着研究了两个重要因素,即训练剪辑的长度和剪辑采样方法。我们还通过从完整动作表示和类不可知动作标签两个方面合并辅助信息来探索多任务学习策略。我们的综合实验揭示了3D动作预测的最佳实践,因此我们提出了一种具有多任务丢失的新方法。所提出的方法明显优于最近的方法,并且在标准基准上展示了现有技术的性能。 |
| VRED: A Position-Velocity Recurrent Encoder-Decoder for Human Motion Prediction Authors Hongsong Wang, Jiashi Feng 人体运动预测,旨在预测过去姿势的未来人体姿势,最近看到了更多的兴趣。许多最近的方法基于递归神经网络RNN,其使用指数图来模拟人类姿势。这些方法忽略了姿势速度以及不同姿势的时间关系,并倾向于收敛到平均姿势或者不能产生自然的姿势。因此,我们提出了一种用于人体运动预测的新型位置速度递归编码器解码器PVRED,其充分利用姿势速度和时间位置信息。提出了一种时间位置嵌入方法,并提出了位置速度RNN PVRNN。我们还强调姿势的四元数参数化的好处,并设计了一个新的可训练的四元数变换QT层,它与训练期间的鲁棒损失函数相结合。对两个人体运动预测基准的实验表明,我们的方法明显优于短期预测和长期预测的现有技术方法。特别是,我们提出的方法可以在4000毫秒内预测未来的人类喜欢和有意义的姿势。 |
| Improving temporal action proposal generation by using high performance computing Authors Tian Wang, Shiye Lei, Youyou Jiang, Zihang Deng, Xin Su, Hichem Snoussi, Chang Choi 提出时间行动建议是计算机视觉中一个重要且具有挑战性的问题。该任务面临的最大挑战是生成具有精确时间边界的提案。为了解决这些困难,我们改进了基于边界敏感网络的算法。今天流行的时间卷积网络忽略了单个视频特征向量的原始含义。我们提出了一种新的时间卷积网络,称为Multipath Temporal ConvNet MTN,它由两部分组成,即Multipath DenseNet和SE ConvNet,可以从视频数据库中提取更多有用的信息。此外,为了响应大容量存储和大量视频,我们放弃了传统的参数服务器并行体系结构,并将高性能计算引入到时间动作提议生成中。为实现这一目标,我们通过按摩传递接口MPI实现环形并行架构,作用于我们的方法。与参数服务器架构相比,我们的并行架构在具有多个GPU的时间动作检测任务上具有更高的效率,这对于处理大规模视频数据库具有重要意义。我们在ActivityNet 1.3和THUMOS14上进行实验,其中我们的方法优于其他具有高召回率和高时间精度的现有技术时间动作检测方法。 |
| RECAL: Reuse of Established CNN classifer Apropos unsupervised Learning paradigm Authors Jayasree Saha, Jayanta Mukhopadhyay 最近,深度网络框架聚类引起了计算机视觉界的一些研究人员的关注。深度框架因其对大规模和高维数据的效率和可扩展性而受到广泛关注。在本文中,我们将监督的CNN分类器架构转换为无监督的聚类模型,称为RECAL,它共同学习判别嵌入子空间和聚类标签。 RECAL由卷积的特征提取层组成,接着是完全连接的无监督分类器层。在分类器层之上堆叠的多项逻辑回归函数softmax。我们使用随机梯度下降SGD优化器训练此网络。然而,我们模型的成功实施围绕着损失函数的设计。我们的损失函数使用启发式算法,假设类分布没有严重偏差,真正的分区需要较低的熵。这是偏态分布和低熵的情况之间的权衡。为了解决这个问题,我们提出了分类熵和类熵,它们是我们损失函数的两个组成部分。在这种方法中,小批量的大小应该保持很高。实验结果表明我们的模型用于聚类众所周知的数字,多视角对象和面部数据集的一致和竞争行为。更重要的是,我们使用该模型为多光谱LISS IV图像生成无监督的斑块分割。我们观察到它能够将建筑区域,湿地,植被和水体与下面的场景区分开来。 |
| ***Efficient Neural Network Approaches for Leather Defect Classification Authors Sze Teng Liong, Y.S. Gan, Kun Hong Liu, Tran Quang Binh, Cong Tue Le, Chien An Wu, Cheng Yan Yang, Yen Chang Huang 真皮,如牛,鳄鱼,蜥蜴和山羊的皮革通常含有天然和人工缺陷,如洞,叮咬,蜱痕,纹理,割伤,皱纹等。识别缺陷的传统解决方案是通过手动缺陷检查,其涉及熟练的专家。这是耗时的并且可能导致高错误率并导致低生产率。本文提出了一系列自动图像处理过程,通过采用深度学习方法对皮革缺陷进行分类。特别地,皮革图像首先被划分为小块,然后它经历预处理技术,即Canny边缘检测以增强缺陷可视化。接下来,采用人工神经网络ANN和卷积神经网络CNN来提取丰富的图像特征。获得的最佳分类结果是80.3,在由2000个样本组成的数据集上进行评估。此外,报告了诸如混淆矩阵和接收器操作特性ROC的性能度量以证明所提出的方法的效率。 |
| Detecting Bias with Generative Counterfactual Face Attribute Augmentation Authors Emily Denton, Ben Hutchinson, Margaret Mitchell, Timnit Gebru 我们引入了一个简单的框架来识别微笑属性分类器的偏差。我们的方法提出了形式的反事实问题,如果这个面部特征不同,预测会如何变化我们利用生成对抗网络的最新进展来构建面部图像的真实生成模型,其提供对特定图像特征的受控操纵。我们引入了一组度量,用于衡量操作图像的特定属性对训练分类器输出的影响。根据经验,我们确定了几种不同的变异因素,这些因素会影响在CelebA训练的微笑分类器的预测。 |
| Fixing the train-test resolution discrepancy Authors Hugo Touvron, Andrea Vedaldi, Matthijs Douze, Herv J gou 数据增强是用于图像分类的神经网络训练的关键。本文首先表明,现有的增强会导致分类器在列车和测试时看到的物体的典型尺寸之间存在显着差异。我们通过实验验证,对于目标测试分辨率,使用较低的列车分辨率可在测试时提供更好的分类。 |
| Instance Segmentation with Point Supervision Authors Issam H. Laradji, Negar Rostamzadeh, Pedro O. Pinheiro, David Vazquez, Mark Schmidt 实例分割方法通常需要昂贵的每像素标签。我们提出了一种只需要点级注释的方法。在训练期间,模型只能访问每个对象的单个像素标签,但任务是输出完整的分割蒙版。为了应对这一挑战,我们构建了一个具有两个分支的网络1,一个预测每个对象位置的定位网络L Net和一个嵌入网络E Net,用于学习同一个对象的像素接近的嵌入空间。通过对具有相似嵌入的像素进行分组来获得所定位对象的分割掩模。在训练时,虽然L Net仅需要点级注释,但E Net使用由类不可知对象提议方法生成的伪标签。我们评估了我们对PASCAL VOC,COCO,KITTI和CityScapes数据集的方法。实验表明,在某些情景中,与完全监督方法相比,我们的方法1获得了竞争结果.2具有固定注释预算的完全和弱监督方法,3是具有点级监督的实例分割的第一强基线。 |
| Realistic Speech-Driven Facial Animation with GANs Authors Konstantinos Vougioukas, Stavros Petridis, Maja Pantic 语音驱动的面部动画是基于语音信号自动合成说话人物的过程。此域中的大多数工作都会创建从音频功能到视觉功能的映射。这种方法通常需要使用计算机图形技术进行后处理,以产生尽管依赖于主体的现实结果。我们提出了一种端到端系统,它只使用人的静止图像和包含语音的音频剪辑生成会话头的视频,而不依赖于手工制作的中间特征。我们的方法生成的视频具有与音频同步的唇部动作和b自然的面部表情,例如眨眼和眉毛动作。我们的时间GAN使用3个鉴别器,专注于实现详细的帧,视听同步和逼真的表达。我们使用消融研究量化了我们模型中每个组件的贡献,并且我们提供了对模型潜在表示的见解。生成的视频基于清晰度,重建质量,唇读精度,同步以及它们产生自然眨眼的能力来评估。 |
| DeepTemporalSeg: Temporally Consistent Semantic Segmentation of 3D LiDAR Scans Authors Ayush Dewan, Wolfram Burgard 了解环境的语义特征是自主机器人操作的关键推动因素。在本文中,我们提出了一种深度卷积神经网络DCNN,用于将LiDAR扫描的语义分段分类为汽车,行人或骑车人。该架构基于密集块并有效地利用深度可分离卷积来限制参数的数量,同时仍保持最先进的性能。为了使DCNN的预测在时间上一致,我们提出了一种基于贝叶斯滤波器的方法。该方法使用来自神经网络的预测来递归地估计扫描中的点的当前语义状态。该递归估计使用从先前扫描获得的知识,从而使得预测在时间上一致并且对于孤立的错误预测是鲁棒的。我们将我们提出的架构的性能与其他最先进的神经网络架构进行比较,并报告实质性的改进。对于建议的贝叶斯滤波器方法,我们在KITTI跟踪基准测试中显示各种序列的结果。 |
| Improving Black-box Adversarial Attacks with a Transfer-based Prior Authors Shuyu Cheng, Yinpeng Dong, Tianyu Pang, Hang Su, Jun Zhu 我们考虑黑匣子对抗性设置,其中对手必须产生对抗性扰动而无需访问目标模型来计算梯度。以前的方法试图通过使用代理白盒模型的转移梯度或基于查询反馈来近似梯度。然而,这些方法经常遭受低攻击成功率或低查询效率,因为用有限信息估计高维空间中的梯度是非常重要的。为了解决这些问题,我们提出了一种先验引导的随机梯度自由P RGF方法来改进黑盒对抗性攻击,它同时利用了基于传递的先验和查询信息的优势。由替代模型的梯度给出的基于先验的转移通过理论分析导出的最优系数适当地整合到我们的算法中。大量实验表明,与替代的现有技术方法相比,我们的方法需要更少的查询来攻击具有更高成功率的黑盒模型。 |
| Differentiated Backprojection Domain Deep Learning for Conebeam Artifact Removal Authors Yoseob Han, Junyoung Kim, Jong Chul Ye 使用圆形轨迹的Conebeam CT由于其相对简单的几何形状而经常用于各种应用。对于锥束几何,Feldkamp,Davis和Kress算法被认为是标准重建方法,但是随着锥角增加,该算法遭受所谓的锥束伪影。已经开发了各种基于模型的迭代重建方法来减少锥束伪影,但是这些算法通常需要计算昂贵的前向和后向投影的多种应用。在本文中,我们开发了一种新颖的深度学习方法,用于精确的锥束伪影去除。特别地,我们在差分反投影域上设计的深度网络执行与希尔伯特变换相关的病态反卷积问题的数据驱动反演。然后使用光谱混合技术将沿冠状和矢状方向的重建结果组合以最小化光谱泄漏。实验结果表明,尽管运行时复杂度显着降低,但我们的方法优于现有的迭代方法。 |
| Sample-Efficient Neural Architecture Search by Learning Action Space Authors Linnan Wang, Saining Xie, Teng Li, Rodrigo Fonseca, Yuandong Tian 神经架构搜索NAS已经成为一种有前途的自动神经网络设计技术。然而,现有的NAS方法通常利用手动设计的动作空间,其与要优化的性能度量(例如,准确性)不直接相关。因此,使用手动设计的动作空间来执行NAS通常会导致样本低效的体系结构探索,因此可能是次优的。为了提高样本效率,本文提出潜在行为神经架构搜索LaNAS,其学习动作空间以递归地将架构搜索空间划分为区域,每个区域具有集中的性能度量,即低方差。在搜索阶段,由于不同的体系结构搜索动作序列导致不同性能的区域,因此通过偏向具有良好性能的区域可以显着提高搜索效率。在最大的NAS数据集NasBench 101上,我们的实验结果表明,LaNAS分别比随机搜索,正则化演化和蒙特卡罗树搜索MCTS的样本效率高22倍,14.6倍和12.4倍。当应用于开放域时,LaNAS发现一种体系结构,在仅探索6,000种体系结构后,在ImageNet移动设置上实现了CIFAR 10上的SoTA 98.0准确度和75.0 top1准确度。 |
| ***Stacked Capsule Autoencoders Authors Adam R. Kosiorek, Sara Sabour, Yee Whye Teh, Geoffrey E. Hinton 可以将对象看作几何组织的相互关联的部分。明确使用这些几何关系来识别物体的系统对于视点的变化应该是自然稳健的,因为内在的几何关系是视点不变的。我们描述了一种无监督的胶囊网络版本,其中一个神经编码器,用于查看所有部分,用于推断物体胶囊的存在和姿势。编码器通过反向传播通过解码器进行训练,该解码器使用姿势预测的混合来预测每个已经发现的部分的姿势。通过使用神经编码器以类似的方式直接从图像中发现这些部分,所述神经编码器推断出部分及其仿射变换。相应的解码器将每个图像像素建模为由仿射变换部分做出的预测的混合。我们在未标记的数据上学习对象及其部分胶囊,然后聚集对象胶囊存在的向量。当告诉这些星团的名称时,我们在MNHN 98.5上对SVHN 55和近现有技术的无监督分类实现了最先进的结果。 |
| Providentia -- A Large Scale Sensing System for the Assistance of Autonomous Vehicles Authors Annkathrin Kr mmer, Christoph Sch ller, Dhiraj Gulati, Alois Knoll 自动驾驶车辆的环境感知不仅受到物理传感器范围和算法性能的限制,而且遮挡也会降低他们对当前交通状况的理解。这对安全构成了巨大的威胁,限制了他们的行驶速度,并且可能导致不方便的操作,从而降低他们的接受度。智能交通系统可以帮助缓解这些问题。通过以自己的世界的数字模型(即数字双胞胎)的形式向自动驾驶车辆提供关于当前交通的附加详细信息,智能交通系统可以填补车辆感知的空白并增强其视野。然而,详细描述这种系统的实现和工作原型证明其可行性是稀缺的。在这项工作中,我们提出了一个硬件和软件架构来构建这样一个可靠的智能交通系统。我们已经在现实世界中实现了这个系统,并表明它能够创建一个精确的数字双胞胎,延伸的公路伸展。此外,我们将这款数字双胞胎提供给自动驾驶汽车,并展示它如何将车辆的感知扩展到其车载传感器的极限之外。 |
| A tunable multiresolution smoother for scattered data with application to particle filtering Authors Gregor A. Robinson, Ian G. Grooms 提出了一种平滑算法,其可以减少在空间扩展域中的分散位置处观察到的数据的小规模内容。更平滑的工作方式是通过形成输入数据的高斯插值,然后将插值与格林函数的多分辨率高斯近似卷积到差分算子,差分算子的频谱可以针对特定问题考虑进行调整。这种更平滑的方法是针对其在粒子滤波中的潜在应用而开发的,粒子滤波通常涉及散布在空间域上的数据,因为使用更平滑的预处理观察减少了避免粒子滤波器坍塌所需的整体尺寸。一个关于气象数据的例子证实我们的平滑器可以改善粒子滤波器重量的平衡。 |
| Model Compression by Entropy Penalized Reparameterization Authors Deniz Oktay, Johannes Ball , Saurabh Singh, Abhinav Shrivastava 我们描述了端到端神经网络权重压缩方法,该方法从最近的潜在可变数据压缩方法中汲取灵感。网络参数权重和偏差在潜在空间中表示,相当于重新参数化。该空间配备有学习概率模型,其用于在训练期间对参数表示施加熵惩罚,并且在训练之后使用算术编码来压缩表示。因此,我们以端到端的方式联合最大化准确性和模型压缩性,其中由超参数指定的速率误差权衡。我们通过在MNIST,CIFAR 10和ImageNet分类基准上压缩六种不同的模型架构来评估我们的方法。我们的方法在VGG 16,LeNet300 100和几种ResNet架构上实现了最先进的压缩,并且在LeNet 5上具有竞争力。 |
| Joint Visual-Textual Embedding for Multimodal Style Search Authors Gil Sadeh, Lior Fritz, Gabi Shalev, Eduard Oks 我们介绍了一种用于时装的多模式视觉文本搜索细化方法。现有搜索引擎不能基于特定产品的属性实现检索结果的直观,交互,细化。我们提出了一种基于查询项目图像和文本细化属性来检索类似项目的方法。我们相信这种方法可以用来解决许多现实生活中的客户场景,其中需要不同颜色,图案,长度或样式的类似项目。我们采用联合嵌入式培训方案,其中产品图像及其目录文本元数据在共享空间中紧密映射。这种联合视觉文本嵌入空间使得能够基于文本细化要求在语义上操纵目录图像。我们提出了一种新的训练目标函数,迷你批量匹配检索,并证明其优于常用的三联体损失。此外,我们展示了添加属性提取模块的可行性,该模块在相同的目录数据上进行了培训,并演示了如何将其集成到多模式搜索中以提高其性能。我们引入了一个带有相关基准的评估协议,并比较了几种方法。 |
| Generating Diverse and Informative Natural Language Fashion Feedback Authors Gil Sadeh, Lior Fritz, Gabi Shalev, Eduard Oks 多模态视觉和语言任务的最新进展使一组新的应用成为可能。在本文中,我们考虑在装备图像上生成自然语言时尚反馈的任务。我们收集一个独特的数据集,其中包含装备图像和相应的积极和建设性的时尚反馈。我们分别处理每种反馈类型,并用视觉注意训练深度生成编码器解码器模型,类似于标准图像字幕管道。按照这种方法,生成的句子往往过于笼统而且没有信息。我们提出了一种基于最大互信息目标函数的替代解码技术,该技术可以产生更多样化和详细的响应。我们使用通用语言指标评估我们的模型,并显示人类评估结果。这项技术应用于Alexa,我如何看待Echo Look设备中公开提供的功能。 |
| 4D X-Ray CT Reconstruction using Multi-Slice Fusion Authors Soumendu Majee, Thilo Balke, Craig A. J. Kemp, Gregery T. Buzzard, Charles A. Bouman 越来越需要在对应于空间,时间和其他独立参数的四维或更多维中重建对象。最好的4D重建算法使用正则化迭代重建方法,例如基于模型的迭代重建MBIR,其主要取决于先前建模的质量。最近,已经证明即插即用方法是使用设计用于去除加性高斯白噪声AWGN的现有技术去噪算法来结合先进的先前模型的有效方式。然而,诸如BM4D和深度卷积神经网络CNN的现有技术去噪算法主要可用于2D和有时3D图像。特别地,CNN在四维或更多维中实现是困难且计算上昂贵的,并且如果没有相关联的高维训练数据则训练可能是不可能的。 |
| ***A Statistical View on Synthetic Aperture Imaging for Occlusion Removal Authors Indrajit Kurmi, David C. Schedl, Oliver Bimber 合成孔径可用于许多领域,例如雷达,射电望远镜,显微镜,声纳,超声波,激光雷达和光学成像。它们接近单个假想的宽孔径传感器的信号,该传感器具有静态小孔径传感器阵列或单个移动小孔径传感器。合成孔径采样中的常识是需要在宽孔径内的密集采样图案来重建清晰信号。在本文中,我们表明合成孔径尺寸和应用遮挡去除的样品数量都存在实际限制。这导致了解如何以最佳和实用有效的方式设计合成孔径采样模式和传感器。我们将我们的发现应用于机载光学切片,该切片使用相机无人机和合成孔径成像来计算地去除遮挡植被或树木以检查地面。 |
| Speeding up VP9 Intra Encoder with Hierarchical Deep Learning Based Partition Prediction Authors Somdyuti Paul, Andrey Norkin, Alan C. Bovik 在VP9视频编解码器中,通过使用速率失真优化RDO递归地划分64次64个超级块来在编码期间确定块的大小。由于超级块的可能分区的组合搜索空间,该过程是计算密集的。在这里,我们提出了一种基于深度学习的替代框架,使用分层完全卷积网络H FCN以四级分区树的形式预测帧内模式超级块分区。我们创建了一个大型的VP9超级块数据库和相应的分区来训练H FCN模型,该模型随后与VP9编码器集成以减少帧内模式编码时间。实验结果表明,我们的方法平均加速帧内模式编码69.7,代价是Bjontegaard Delta比特率BD率增加1.71。虽然VP9提供了几种内置速度级别,旨在以降低速率失真性能为代价提供更快的编码,但我们发现我们的模型能够胜过参考VP9编码器的最快建议速度级别,以实现高质量的帧内编码配置,就加速和BD率而言。 |
| Multi-Adversarial Variational Autoencoder Networks Authors Abdullah Al Zubaer Imran, Demetri Terzopoulos GAN和VAE的无监督训练使他们能够生成模拟真实世界分布的真实图像,并执行基于图像的无监督聚类或半监督分类。结合这两种生成模型的强大功能,我们引入了多对抗变化自动编码器网络MAVEN,这是一种新颖的网络架构,在VAE GAN网络中集成了一组鉴别器,同时具有对抗性学习和变分推理。我们将MAVEN应用于合成图像的生成,并提出一种新的分布测量来量化生成的图像的质量。我们使用来自计算机视觉和医学成像领域的数据集的实验结果街景房号,CIFAR 10和胸部X射线数据集证明了在图像生成和分类任务中对现有技术的半监督模型的竞争性能。 |
| ***Time warping invariants of multidimensional time series Authors Joscha Diehl, Kurusch Ebrahimi Fard, Nikolas Tapia 在数据科学中,人们经常面对代表某些兴趣量的测量的时间序列。通常,在第一步中,需要提取时间序列的特征。这些数字量旨在简洁地描述数据并抑制噪声的影响。在某些应用程序中,还需要这些功能来满足某些不变性属性。在本文中,我们专注于时间扭曲不变量。我们证明了这些对应于时间序列增量的某个迭代和的一族,在数学文献中称为准坐标函数。我们在代数框架中呈现这些不变特征,并且我们开发了它们的一些基本属性。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
tips:
cvpr sisr2019
stereoSR -> PASSRnet

pic from pexels.com