【VGG】口罩人脸分类
文章目录
- 1. 项目准备
-
- 1.1. 问题导入
- 1.2. 数据集简介
- 2. VGG模型
- 3. 实验步骤
-
- 3.0. 前期准备
- 3.1. 数据准备
- 3.2. 网络配置
- 3.3. 模型训练
- 3.4. 模型评估
- 3.5. 模型预测
- 写在最后
1. 项目准备
1.1. 问题导入
新冠肺炎病毒在全球肆虐,武汉大学率先公开了口罩遮挡人脸数据集。我们从中选取了6000余张戴口罩的人脸图片和6000余张正常的人脸图片作为实验数据集,以训练改进版的VGG16模型,使其能够实现对人脸是否佩戴口罩的判定。
1.2. 数据集简介
本次实验采用的是武汉大学口罩遮挡人脸数据集(RMFD)的一部分,它包含6000余张戴口罩的人脸图片和6000余张正常的人脸图片。

这是数据集的下载链接:人脸口罩分类数据集 - AI Studio
2. VGG模型
VGG是由 Simonyan和Zisserman(2014)在论文中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写,它是2014年ILSVRC竞赛的第二名(第一名是GoogLeNet),但是VGG在多个迁移学习任务中的表现要优于GoogLeNet。
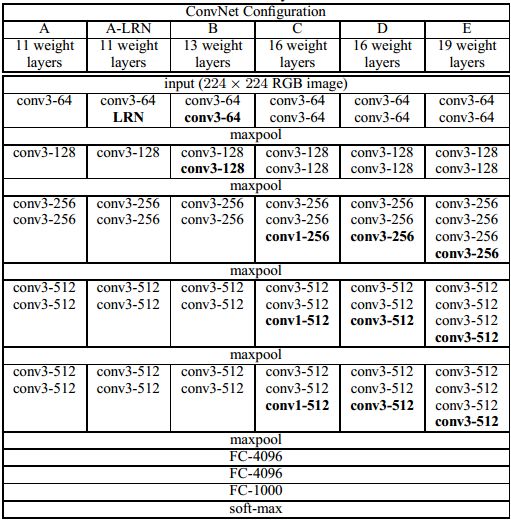
作者在论文中证明了小尺寸(3×3)卷积核的深层网络要优于大尺寸卷积核的浅层网络,因此VGG模型采用3×3的卷积核代替了其他的大尺寸卷积核。VGG中根据卷积核大小和卷积层数目的不同,可分为A、A-LRN、B、C、D、E共6个配置(ConvNet Configuration),其中以D和E两种配置较为常用,分别称为VGG16和VGG19。本实验使用的是VGG16模型(如下图D所示)。
3. 实验步骤

3.0. 前期准备
- 导入模块
注意:本案例仅适用于
PaddlePaddle 2.0+版本
import os
import zipfile
import random
import numpy as np
from PIL import Image, ImageEnhance
import matplotlib.pyplot as plt
import paddle
from paddle import nn
from paddle import metric as M
from paddle.io import DataLoader, Dataset
from paddle.nn import functional as F
from paddle.optimizer import Adam
from paddle.optimizer.lr import NaturalExpDecay
- 设置超参数
BATCH_SIZE = 64 # 每批次的样本数
EPOCHS = 8 # 训练轮数
LOG_GAP = 100 # 输出训练信息的间隔
CLASS_DIM = 2 # 图像种类
LAB_DICT = { # 记录标签和数字的关系
"0": "没戴口罩",
"1": "戴了口罩"
}
INIT_LR = 3e-4 # 初始学习率
LR_DECAY = 0.6 # 学习率衰减率
SRC_PATH = "./data/data52391/Masked_Face.zip" # 压缩包路径
DST_PATH = "./data" # 解压路径
DATA_PATH = { # 实验数据集路径
"0": DST_PATH + "/AFDB_face_dataset", # 正常人脸
"1": DST_PATH + "/AFDB_masked_face_dataset" # 口罩人脸
}
INFER_PATH = ["./work/n1.jpg", "./work/n2.jpg",
"./work/m1.jpg", "./work/m2.jpg"] # 预测数据集路径
MODEL_PATH = "VGG.pdparams" # 模型参数保存路径
3.1. 数据准备
- 解压数据集
由于数据集中的数据是以压缩包的形式存放的,因此我们需要先解压数据压缩包。
if not os.path.isdir(DATA_PATH["0"]) or not os.path.isdir(DATA_PATH["1"]):
z = zipfile.ZipFile(SRC_PATH, "r") # 打开压缩文件,创建zip对象
z.extractall(path=DST_PATH) # 解压zip文件至目标路径
z.close()
print("数据集解压完成!")
- 划分数据集
我们需要按1:9比例划分测试集和训练集,分别生成两个包含数据路径和标签映射关系的列表。
def get_data_list(lab_no, path): # 划分path路径下的数据集
count = 0 # 记录图片的数量,便于划分数据集
temp_train_list, temp_test_list = [], [] # 临时存放数据集位置及类别
file_folders = os.listdir(path) # 获取path路径下所有的文件夹
for folder in file_folders:
images = os.listdir(os.path.join(path, folder))
for img in images:
img_path = os.path.join(path, folder, img)
if count % 10 == 0: # 按照1:9的比例划分数据集
temp_test_list.append([img_path, lab_no])
else:
temp_train_list.append([img_path, lab_no])
count += 1
return temp_train_list, temp_test_list
train_lt1, test_lt1 = get_data_list(0, DATA_PATH["0"]) # 划分“正常人脸”
train_lt2, test_lt2 = get_data_list(1, DATA_PATH["1"]) # 划分“口罩人脸”
train_list = train_lt1 + train_lt2
test_list = test_lt1 + test_lt2
- 数据增强
由于实验模型较为复杂,直接训练容易发生过拟合,故在处理实验数据集时采用数据增强的方法扩充数据集的多样性。数据増广(Data Augmentation),即数据增强,数据增强的目的主要是减少网络的过拟合现象,通过对训练图片进行变换可以得到泛化能力更强的网络,更好地适应应用场景。本实验中用到的数据增强方法有:随机改变亮度,随机改变对比度,随机改变饱和度,随机改变清晰度,随机翻转图像,随机加高斯噪声等。
def random_brightness(img, low=0.5, high=1.5):
''' 随机改变亮度(0.5~1.5) '''
x = random.uniform(low, high)
img = ImageEnhance.Brightness(img).enhance(x)
return img
def random_contrast(img, low=0.5, high=1.5):
''' 随机改变对比度(0.5~1.5) '''
x = random.uniform(low, high)
img = ImageEnhance.Contrast(img).enhance(x)
return img
def random_color(img, low=0.5, high=1.5):
''' 随机改变饱和度(0.5~1.5) '''
x = random.uniform(low, high)
img = ImageEnhance.Color(img).enhance(x)
return img
def random_sharpness(img, low=0.5, high=1.5):
''' 随机改变清晰度(0.5~1.5) '''
x = random.uniform(low, high)
img = ImageEnhance.Sharpness(img).enhance(x)
return img
def random_flip(img, prob=0.5):
''' 随机翻转图像(p=0.5) '''
if random.random() < prob: # 左右翻转
img = img.transpose(Image.FLIP_LEFT_RIGHT)
# if random.random() < prob: # 上下翻转
# img = img.transpose(Image.FLIP_TOP_BOTTOM)
return img
def random_rotate(img, low=-30, high=30):
''' 随机旋转图像(-30~30) '''
angle = random.choice(range(low, high))
img = img.rotate(angle)
return img
def random_noise(img, low=0, high=10):
''' 随机加高斯噪声(0~10) '''
img = np.asarray(img)
sigma = np.random.uniform(low, high)
noise = np.random.randn(img.shape[0], img.shape[1], 3) * sigma
img = img + np.round(noise).astype('uint8')
# 将矩阵中的所有元素值限制在0~255之间:
img[img > 255], img[img < 0] = 255, 0
img = Image.fromarray(img)
return img
def image_augment(img, prob=0.5):
''' 叠加多种数据增强方法 '''
opts = [random_brightness, random_contrast, random_color, random_flip,
random_rotate, random_noise, random_sharpness,] # 数据增强方法
random.shuffle(opts)
for opt in opts:
img = opt(img) if random.random() < prob else img # 处理图像
return img
- 数据预处理
我们需要对数据集图像进行缩放和归一化处理。
class MyDataset(Dataset):
''' 自定义的数据集类 '''
def __init__(self, label_list, transform, augment=None):
'''
* `label_list`: 标签与文件路径的映射列表
* `transform`: 数据处理函数
* `augment`: 数据增强函数(默认为空)
'''
super(MyDataset, self).__init__()
random.shuffle(label_list) # 打乱映射列表
self.label_list = label_list
self.transform = transform
self.augment = augment
def __getitem__(self, index):
''' 根据位序获取对应数据 '''
img_path, label = self.label_list[index]
img = self.transform(img_path, self.augment)
return img, int(label)
def __len__(self):
''' 获取数据集样本总数 '''
return len(self.label_list)
def data_mapper(img_path, augment=None, show=False):
''' 图像处理函数 '''
img = Image.open(img_path).convert("RGB") # 以RGB模式打开图片
# 将其缩放为224*224的高质量图像:
img = img.resize((224, 224), Image.ANTIALIAS)
if show: # 展示图像
display(img)
if augment is not None: # 数据增强
img = augment(img)
# 把图像变成一个numpy数组以匹配数据馈送格式:
img = np.array(img).astype("float32")
# 将图像矩阵由“rgb,rgb,rbg...”转置为“rr...,gg...,bb...”:
img = img.transpose((2, 0, 1))
# 将图像数据归一化,并转换成Tensor格式:
img = paddle.to_tensor(img / 255.0)
return img
train_dataset = MyDataset(train_list, data_mapper, image_augment) # 训练集
test_dataset = MyDataset(test_list, data_mapper, augment=None) # 测试集
- 定义数据提供器
我们需要分别构建用于训练和测试的数据提供器,其中训练数据提供器是乱序、按批次提供数据的。
train_loader = DataLoader(train_dataset, # 训练数据集
batch_size=BATCH_SIZE, # 每批读取的样本数
num_workers=0, # 加载数据的子进程个数
shuffle=True, # 打乱训练数据集
drop_last=False) # 不丢弃不完整的样本
test_loader = DataLoader(test_dataset, # 测试数据集
batch_size=BATCH_SIZE, # 每批读取的样本数
num_workers=0, # 加载数据的子进程个数
shuffle=False, # 不打乱测试数据集
drop_last=False) # 不丢弃不完整的样本
3.2. 网络配置
- 模型改进
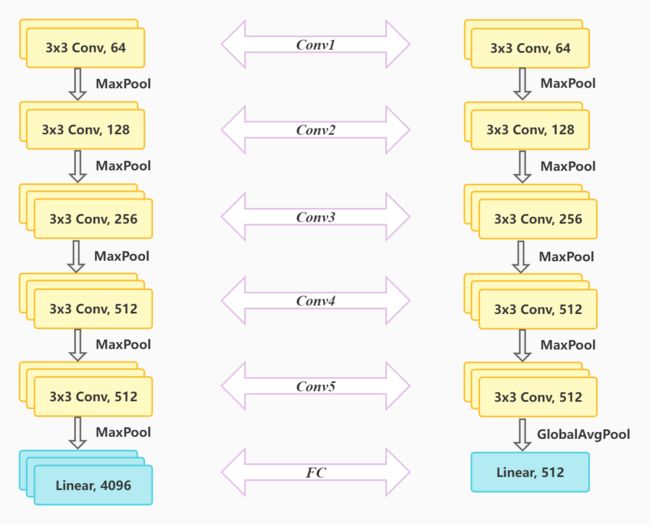
原始的VGG16包含13个卷积层、5个池化层、3个全连接层,它常常被用于分类问题。由于本实验的数据集并不是特别大,而实验模型又比较复杂,因此需要改进VGG16模型。为了减少模型的复杂程度,我们选择用一层全局池化层来取代VGG16模型的前两层全连接层(模型结构如下图所示),这样可以大大减少我们需要训练的参数。这对于简化实验模型、防止出现过拟合、提升模型训练速度等,均有很大的帮助。
class ConvBN2d(nn.Layer):
''' Conv2D with BatchNorm2D and ReLU '''
def __init__(self, in_channels: int, out_channels: int,
kernel_size: int, stride=1, padding=0):
'''
* `in_channels`: 输入通道数
* `out_channels`: 输出通道数
* `kernel_size`: 卷积核大小
* `stride`: 卷积运算的步长
* `padding`: 卷积填充的大小
'''
super(ConvBN2d, self).__init__()
self.net = nn.Sequential(
nn.Conv2D(in_channels, out_channels, kernel_size, stride, padding),
nn.BatchNorm2D(out_channels),
nn.ReLU()
)
def forward(self, x):
return self.net(x)
class ConvPool(nn.Layer):
''' Conv-Pool Block '''
def __init__(self, conv_args: tuple, pool_args: tuple,
conv_num=1, pool_type="max"):
'''
* `conv_args`: 卷积层参数([输入通道数,输出通道数,卷积核大小,卷积步长,填充长度])
* `pool_args`: 池化层参数([池化核大小,池化步长,填充长度] or [])
* `conv_num`: 卷积层的个数
* `pool_type`: 池化类型(max or avg or global)
'''
super(ConvPool, self).__init__()
# (1) 定义卷积层:
for i in range(conv_num): # 定义conv_num个卷积层
conv = ConvBN2d(*conv_args)
conv_args[0] = conv_args[1]
self.add_sublayer("conv_%d" % i, conv)
# (2) 定义池化层:
pool_type = pool_type.lower()
if pool_type == "max": # 最大池化
pool = nn.MaxPool2D(*pool_args)
elif pool_type == "avg": # 平均池化
pool = nn.AvgPool2D(*pool_args)
else: # 全局平均池化
pool = nn.AdaptiveAvgPool2D(1)
self.add_sublayer("pool", pool)
def forward(self, x):
for name, sublayer in self.named_children():
x = sublayer(x)
return x
class VGG(nn.Layer):
def __init__(self, in_channels=3, n_classes=2, mtype=16, global_pool=False):
'''
* `in_channels`: 输入的通道数
* `n_classes`: 输出分类数量
* `mtype`: VGG类型 (11 or 13 or 16 or 19)
* `global_pool`: 是否用全局平均池化改进VGG
'''
super(VGG, self).__init__()
if mtype == 11: # Type A => VGG-11
nums = [1, 1, 2, 2, 2]
elif mtype == 13: # Type B => VGG-13
nums = [2, 2, 2, 2, 2]
elif mtype == 16: # Type D => VGG-16
nums = [2, 2, 3, 3, 3]
elif mtype == 19: # Type E => VGG-19
nums = [2, 2, 4, 4, 4]
else:
raise NotImplementedError("The [mtype] must in [11, 13, 16, 19].")
self.conv1 = ConvPool([in_channels, 64, 3, 1, 1], [2, 2], nums[0], "max")
self.conv2 = ConvPool([64, 128, 3, 1, 1], [2, 2], nums[1], "max")
self.conv3 = ConvPool([128, 256, 3, 1, 1], [2, 2], nums[2], "max")
self.conv4 = ConvPool([256, 512, 3, 1, 1], [2, 2], nums[3], "max")
if global_pool:
self.conv5 = ConvPool([512, 512, 3, 1, 1], [], nums[4], "global")
self.linear = nn.Sequential(nn.Flatten(1, -1),
nn.Linear(512, n_classes))
else:
self.conv5 = ConvPool([512, 512, 3, 1, 1], [2, 2], nums[4], "max")
self.linear = nn.Sequential(nn.Flatten(1, -1),
nn.Linear(512*7*7, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, n_classes))
def forward(self, x):
x = self.conv1(x) # conv1 => 64*112*112
x = self.conv2(x) # conv2 => 128*56*56
x = self.conv3(x) # conv3 => 256*28*28
x = self.conv4(x) # conv4 => 512*14*14
x = self.conv5(x) # conv5 => 512*7*7
y = self.linear(x) # linear => n_classes
return y
- 实例化模型
model = VGG(in_channels=3, n_classes=CLASS_DIM,
mtype=16, global_pool=True) # VGG-16
3.3. 模型训练
model.train() # 开启训练模式
scheduler = NaturalExpDecay(
learning_rate=INIT_LR,
gamma=LR_DECAY
) # 定义学习率衰减器
optimizer = Adam(
learning_rate=scheduler,
parameters=model.parameters()
) # 定义Adam优化器
loss_arr, acc_arr = [], [] # 用于可视化
for ep in range(EPOCHS):
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
y_data = y_data[:, np.newaxis] # 增加一维维度
y_pred = model(x_data) # 预测结果
acc = M.accuracy(y_pred, y_data) # 计算准确率
loss = F.cross_entropy(y_pred, y_data) # 计算交叉熵
if batch_id != 0 and batch_id % LOG_GAP == 0: # 定期输出训练结果
print("Epoch:%d,Batch:%3d,Loss:%.5f,Acc:%.5f"\
% (ep, batch_id, loss, acc))
acc_arr.append(acc.item())
loss_arr.append(loss.item())
optimizer.clear_grad()
loss.backward()
optimizer.step()
scheduler.step() # 每轮衰减一次学习率
paddle.save(model.state_dict(), MODEL_PATH) # 保存训练好的模型
模型训练结果如下:
Epoch:0,Batch: 0,Loss:0.65380,Acc:0.59375
Epoch:0,Batch:100,Loss:0.35155,Acc:0.76562
Epoch:1,Batch: 0,Loss:0.10918,Acc:0.96875
Epoch:1,Batch:100,Loss:0.17284,Acc:0.90625
Epoch:2,Batch: 0,Loss:0.09818,Acc:0.95312
Epoch:2,Batch:100,Loss:0.12185,Acc:0.95312
Epoch:3,Batch: 0,Loss:0.24998,Acc:0.95312
Epoch:3,Batch:100,Loss:0.10257,Acc:0.93750
Epoch:4,Batch: 0,Loss:0.16910,Acc:0.98438
Epoch:4,Batch:100,Loss:0.09855,Acc:0.98438
Epoch:5,Batch: 0,Loss:0.06119,Acc:0.98438
Epoch:5,Batch:100,Loss:0.09231,Acc:0.95312
Epoch:6,Batch: 0,Loss:0.08556,Acc:0.96875
Epoch:6,Batch:100,Loss:0.02138,Acc:1.00000
Epoch:7,Batch: 0,Loss:0.06875,Acc:0.98438
Epoch:7,Batch:100,Loss:0.05027,Acc:0.98438
- 可视化训练过程
fig = plt.figure(figsize=[10, 8])
# 训练误差图像:
ax1 = fig.add_subplot(211, facecolor="#E8E8F8")
ax1.set_ylabel("Loss", fontsize=18)
plt.tick_params(labelsize=14)
ax1.plot(range(len(loss_arr)), loss_arr, color="orangered")
ax1.grid(linewidth=1.5, color="white") # 显示网格
# 训练准确率图像:
ax2 = fig.add_subplot(212, facecolor="#E8E8F8")
ax2.set_xlabel("Training Steps", fontsize=18)
ax2.set_ylabel("Accuracy", fontsize=18)
plt.tick_params(labelsize=14)
ax2.plot(range(len(acc_arr)), acc_arr, color="dodgerblue")
ax2.grid(linewidth=1.5, color="white") # 显示网格
fig.tight_layout()
plt.show()
plt.close()

3.4. 模型评估
model.eval() # 开启评估模式
test_costs, test_accs = [], []
for batch_id, data in enumerate(test_loader()):
x_data, y_data = data
y_data = y_data[:, np.newaxis] # 增加一维维度
y_pred = model(x_data) # 预测结果
acc = M.accuracy(y_pred, y_data) # 计算准确率
loss = F.cross_entropy(y_pred, y_data) # 计算交叉熵
test_accs.append(acc.item())
test_costs.append(loss.item())
test_loss = np.mean(test_costs) # 每轮测试的平均误差
test_acc = np.mean(test_accs) # 每轮测试的平均准确率
print("Eval \t Loss:%.5f,Acc:%.5f" % (test_loss, test_acc))
模型评估结果如下:
Eval Loss:0.03680,Acc:0.98849
3.5. 模型预测
model.eval() # 开启评估模式
model.set_state_dict(
paddle.load(MODEL_PATH)
) # 载入预训练模型参数
for idx, img_path in enumerate(INFER_PATH):
image = data_mapper(img_path, show=True) # 获取预测图片
image = image[np.newaxis, :, :, :]
result = model(image).numpy() # 开始模型预测
lab = str(np.argmax(result)) # 获取result数组最大值的索引
print("图%d的预测结果:%s" % (idx+1, LAB_DICT[lab]))
模型预测结果如下:

图1的预测结果为:没戴口罩

图2的预测结果为:没戴口罩

图3的预测结果为:戴了口罩

图4的预测结果为:戴了口罩
写在最后
- 如果您发现项目存在问题,或者如果您有更好的建议,欢迎在下方评论区中留言讨论~
- 这是本项目的链接:实验项目 - AI Studio,点击
fork可直接在AI Studio运行~- 这是我的个人主页:个人主页 - AI Studio,来AI Studio互粉吧,等你哦~
- 【友链滴滴】欢迎大家随时访问我的个人博客~