【ResNet】肺炎CT影像识别
文章目录
- 1. 项目准备
-
- 1.1. 问题导入
- 1.2. 数据集简介
- 2. ResNet模型
-
- 2.1. 模型背景
- 2.2. 模型介绍
- 3. 实验步骤
-
- 3.0. 前期准备
- 3.1. 数据准备
- 3.2. 网络配置
- 3.3. 模型训练
- 3.4. 模型评估
- 3.5. 模型预测
- 4. 内容总结
- 写在最后
1. 项目准备
1.1. 问题导入
图像分类是计算机视觉的重要领域,它的目标是将图像分类到预定义的标签。许多研究者提出了很多不同种类的神经网络,并极大地提升了分类算法的性能。本次实践将训练ResNet模型实现对胸部CT影像的分类,以区分新冠肺炎患者、病毒性肺炎患者以及正常人。
1.2. 数据集简介
新冠肺炎在全球爆发以后,来自卡塔尔、孟加拉国、巴基斯坦以及马来西亚的研究人员与医生合作,建立了一个包含正常人、病毒性肺炎患者、新冠肺炎患者的胸部CT影像的数据集。数据集包含1200个新冠阳性患者的影像、1341个正常人的影像和1345个病毒性肺炎患者的影像。
这是数据集的下载链接:COVID-19胸部X射线图像数据库 - AI Studio
2. ResNet模型
2.1. 模型背景
VGG和GoogleNet等模型证明,更深的网络可以抽象出表达能力更强的特征,进而获得更强的分类能力。从理论上说,在没有残差的深度网络中,随着网络层数的加深,网络的表征能力越来越强,但是在实际操作过程中,这么做会导致模型效果越来越差。一方面,在深度网络中进行反向传播时,过长的反向传播链会使得近输入端的梯度接近0,从而导致梯度消失,使得网络的训练失效;另一方面,深度网络存在退化问题(Degradation of Deep Network),这使得网络表征能学习到的最优点与实际的最优点往往是越来越远的。
为了解决上述问题,何恺明和孙剑等人(2015)在论文中提出了ResNet,这是一种深度残差卷积网络。下图展示了VGG-19与ResNet-34的网络结构,我们可以看到,与VGG模型的各层网络直接简单串接不同的是,ResNet模型会将残差块的输入也作为下一个残差块的输入,这样可以使得深层网络能够融合浅层网络所提取的特征,提升深度卷积网络的整体性能。

2.2. 模型介绍
ResNet由一系列残差块(如下图Figure 2所示)构成,它会把每个残差块的输入 x x x与卷积层输出 F ( x ) F(x) F(x)进行相加,在使用ReLU函数处理相加结果之后,我们便得到了该残差块的输出。需要注意的是,如果 x x x与 F ( x ) F(x) F(x)的通道数不一样,那么在进行相加之前,我们还需对 x x x进行相应的卷积运算,以实现下采样(downsample),统一 x x x与 F ( x ) F(x) F(x)的通道数。
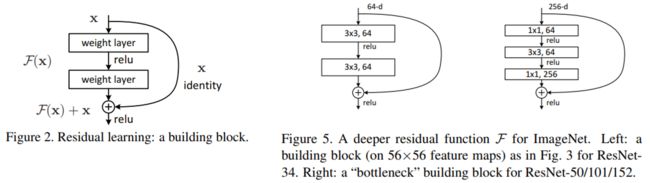
如上图Figure 5所示,ResNet模型一共有两种不同的残差块。其中,50层以下的ResNet采用的是左侧的Basic残差块,而50层及以上的ResNet采用的是右侧的Bottleneck残差块。
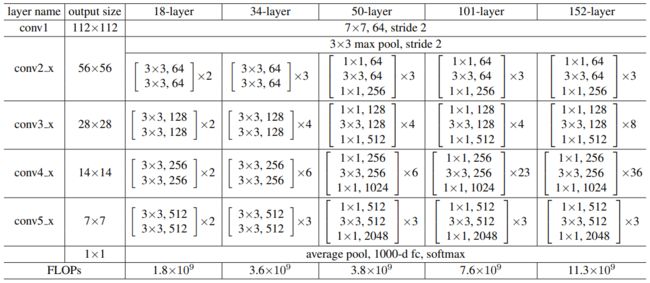
下表展示了ResNet模型的网络结构,其中, [ 3 × 3 , a 3 × 3 , a ] \left[\begin{array}{c} 3×3, a \\ 3×3, a \end{array}\right] [3×3,a3×3,a]代表Basic残差块, [ 1 × 1 , b 3 × 3 , b 1 × 1 , 4 b ] \left[\begin{array}{c} 1×1, b \\ 3×3, b \\ 1×1, 4b \end{array}\right] ⎣⎡1×1,b3×3,b1×1,4b⎦⎤代表Bottleneck残差块。ResNet一共有五个版本,即ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152,其中最常用的版本是ResNet-50和ResNet-101。
3. 实验步骤

3.0. 前期准备
- 导入模块
注意:本案例仅适用于
PaddlePaddle 2.0+版本
import os
import zipfile
import random
import numpy as np
from PIL import Image, ImageEnhance
import matplotlib.pyplot as plt
import paddle
from paddle import nn
from paddle import metric as M
from paddle.io import DataLoader, Dataset
from paddle.nn import functional as F
from paddle.optimizer import Adam
from paddle.optimizer.lr import NaturalExpDecay
- 设置超参数
BATCH_SIZE = 64 # 每批次的样本数
EPOCHS = 8 # 训练轮数
LOG_GAP = 30 # 输出训练信息的间隔
CLASS_DIM = 3 # 图像种类
LAB_DICT = { # 记录标签和数字的关系
"0": "正常肺部",
"1": "病毒性肺炎",
"2": "新冠肺炎",
}
INIT_LR = 3e-4 # 初始学习率
LR_DECAY = 0.6 # 学习率衰减率
SRC_PATH = "./data/input_data.zip" # 压缩包路径
DST_PATH = "./data" # 解压路径
DATA_PATH = { # 实验数据集路径
"0": DST_PATH + "/input_data/NORMAL",
"1": DST_PATH + "/input_data/Viral_Pneumonia",
"2": DST_PATH + "/input_data/COVID",
}
MODEL_PATH = "ResNet.pdparams" # 模型参数保存路径
3.1. 数据准备
- 解压数据集
由于数据集中的数据是以压缩包的形式存放的,因此我们需要先解压数据压缩包。
if not os.path.isdir(DATA_PATH["0"]) or\
not os.path.isdir(DATA_PATH["1"]) or\
not os.path.isdir(DATA_PATH["2"]):
z = zipfile.ZipFile(SRC_PATH, "r") # 打开压缩文件,创建zip对象
z.extractall(path=DST_PATH) # 解压zip文件至目标路径
z.close()
print("数据集解压完成!")
- 划分数据集
我们需要按1:9比例划分测试集和训练集,分别生成两个包含数据路径和标签映射关系的列表。
def get_data_list(lab_no, path): # 划分path路径下的数据集
tmp_train_list, tmp_test_list = [], [] # 临时存放数据集位置及标签
for idx, img in enumerate(os.listdir(path)[:-1]):
img_path = os.path.join(path, img)
if idx % 10 == 0: # 按照1:9的比例划分数据集
tmp_test_list.append([img_path, lab_no])
else:
tmp_train_list.append([img_path, lab_no])
return tmp_train_list, tmp_test_list
def get_infer_data(data_path): # 将数据集中最后一个数据作为预测集
tmp_infer_list = []
for lab_no in data_path.keys():
path, lab_no = data_path[lab_no], int(lab_no)
img_path = os.path.join(path, os.listdir(path)[-1])
tmp_infer_list.append([img_path, lab_no])
return tmp_infer_list
train_lt0, test_lt0 = get_data_list(0, DATA_PATH["0"]) # 划分“正常肺部”
train_lt1, test_lt1 = get_data_list(1, DATA_PATH["1"]) # 划分“病毒性肺炎”
train_lt2, test_lt2 = get_data_list(2, DATA_PATH["2"]) # 划分“新冠肺炎”
train_list = train_lt0 + train_lt1 + train_lt2
test_list = test_lt0 + test_lt1 + test_lt2
infer_list = get_infer_data(DATA_PATH)
- 数据增强
数据増广(Data Augmentation),即数据增强,数据增强的目的主要是减少网络的过拟合现象,通过对训练图片进行变换可以得到泛化能力更强的网络,更好地适应应用场景。
由于实验模型较为复杂,直接训练容易发生过拟合,故在处理实验数据集时采用数据增强的方法扩充数据集的多样性。本实验中用到的数据增强方法有:随机改变亮度,随机改变对比度,随机改变饱和度,随机改变清晰度,随机旋转图像,随机翻转图像,随机加高斯噪声等。
def random_brightness(img, low=0.5, high=1.5):
''' 随机改变亮度(0.5~1.5) '''
x = random.uniform(low, high)
img = ImageEnhance.Brightness(img).enhance(x)
return img
def random_contrast(img, low=0.5, high=1.5):
''' 随机改变对比度(0.5~1.5) '''
x = random.uniform(low, high)
img = ImageEnhance.Contrast(img).enhance(x)
return img
def random_color(img, low=0.5, high=1.5):
''' 随机改变饱和度(0.5~1.5) '''
x = random.uniform(low, high)
img = ImageEnhance.Color(img).enhance(x)
return img
def random_sharpness(img, low=0.5, high=1.5):
''' 随机改变清晰度(0.5~1.5) '''
x = random.uniform(low, high)
img = ImageEnhance.Sharpness(img).enhance(x)
return img
def random_flip(img, prob=0.5):
''' 随机翻转图像(p=0.5) '''
if random.random() < prob: # 左右翻转
img = img.transpose(Image.FLIP_LEFT_RIGHT)
# if random.random() < prob: # 上下翻转
# img = img.transpose(Image.FLIP_TOP_BOTTOM)
return img
def random_rotate(img, low=-30, high=30):
''' 随机旋转图像(-30~30) '''
angle = random.choice(range(low, high))
img = img.rotate(angle)
return img
def random_noise(img, low=0, high=10):
''' 随机加高斯噪声(0~10) '''
img = np.asarray(img)
sigma = np.random.uniform(low, high)
noise = np.random.randn(img.shape[0], img.shape[1], 3) * sigma
img = img + np.round(noise).astype('uint8')
# 将矩阵中的所有元素值限制在0~255之间:
img[img > 255], img[img < 0] = 255, 0
img = Image.fromarray(img)
return img
def image_augment(img, prob=0.5):
''' 叠加多种数据增强方法 '''
opts = [random_brightness, random_contrast, random_color, random_flip,
random_rotate, random_noise, random_sharpness,] # 数据增强方法
random.shuffle(opts)
for opt in opts:
img = opt(img) if random.random() < prob else img # 处理图像
return img
- 数据预处理
我们需要对数据集图像进行缩放和归一化处理。
class MyDataset(Dataset):
''' 自定义的数据集类 '''
def __init__(self, label_list, transform, augment=None):
'''
* `label_list`: 标签与文件路径的映射列表
* `transform`: 数据处理函数
* `augment`: 数据增强函数(默认为空)
'''
super(MyDataset, self).__init__()
random.shuffle(label_list) # 打乱映射列表
self.label_list = label_list
self.transform = transform
self.augment = augment
def __getitem__(self, index):
''' 根据位序获取对应数据 '''
img_path, label = self.label_list[index]
img = self.transform(img_path, self.augment)
return img, int(label)
def __len__(self):
''' 获取数据集样本总数 '''
return len(self.label_list)
def data_mapper(img_path, augment=None, show=False):
''' 图像处理函数 '''
img = Image.open(img_path).convert("RGB") # 以RGB模式打开图片
# 将其缩放为224*224的高质量图像:
img = img.resize((224, 224), Image.ANTIALIAS)
if show: # 展示图像
display(img)
if augment is not None: # 数据增强
img = augment(img)
# 把图像变成一个numpy数组以匹配数据馈送格式:
img = np.array(img).astype("float32")
# 将图像矩阵由“rgb,rgb,rbg...”转置为“rr...,gg...,bb...”:
img = img.transpose((2, 0, 1))
# 将图像数据归一化,并转换成Tensor格式:
img = paddle.to_tensor(img / 255.0)
return img
train_dataset = MyDataset(train_list, data_mapper, image_augment) # 训练集
test_dataset = MyDataset(test_list, data_mapper, augment=None) # 测试集
- 定义数据提供器
我们需要分别构建用于训练和测试的数据提供器,其中训练数据提供器是乱序、按批次提供数据的。
train_loader = DataLoader(train_dataset, # 训练数据集
batch_size=BATCH_SIZE, # 每批读取的样本数
num_workers=0, # 加载数据的子进程个数
shuffle=True, # 打乱训练数据集
drop_last=False) # 不丢弃不完整的样本
test_loader = DataLoader(test_dataset, # 测试数据集
batch_size=BATCH_SIZE, # 每批读取的样本数
num_workers=0, # 加载数据的子进程个数
shuffle=False, # 不打乱测试数据集
drop_last=False) # 不丢弃不完整的样本
3.2. 网络配置
- 注意事项
在ResNet的残差块中,作者采用了大量的小尺寸卷积核。其中,对于包含1×1卷积核的卷积层而言,它只能改变特征图的通道数;对于包含3×3卷积核的卷积层而言,当且仅当运算步长(stride)不为1时,它才可以改变特征图的尺寸。
class ConvBN2d(nn.Layer):
''' Conv2d with BatchNorm2d and ReLU '''
def __init__(self, in_channels: int, out_channels: int,
kernel_size: int, stride=1, padding=0, act=None):
'''
* `in_channels`: 输入通道数
* `out_channels`: 输出通道数
* `kernel_size`: 卷积核大小
* `stride`: 卷积运算的步长
* `padding`: 卷积填充的大小
* `act`: 激活函数(None / relu)
'''
super(ConvBN2d, self).__init__()
self.act = act
self.net = nn.Sequential(
nn.Conv2D(in_channels, out_channels, kernel_size, stride, padding),
nn.BatchNorm2D(out_channels)
)
def forward(self, x):
if self.act == "relu":
return F.relu(self.net(x))
else:
return self.net(x)
class BasicBlock(nn.Layer):
''' A Residual Block for ResNet-18/34 '''
expansion = 1 # 最后一层输出的通道扩展倍数
def __init__(self, in_size, out_size, stride=1):
'''
* `in_size`: 第一层卷积层的输入通道数
* `out_size`: 第一层卷积层的输出通道数
* `stride`: 第一层卷积层的运算步长
'''
super(BasicBlock, self).__init__()
end_size = self.expansion * out_size # 最后一层卷积层的输出通道数
self.layers = nn.Sequential(
ConvBN2d(in_size, out_size, 3, stride, 1, "relu"),
ConvBN2d(out_size, end_size, 3, 1, 1, None),
)
if in_size != end_size: # 进行拼接之前需要统一通道数和尺寸
self.shortcut = ConvBN2d(in_size, end_size, 1, stride, act=None)
else:
self.shortcut = None
def forward(self, x):
fx = self.layers(x)
if self.shortcut is not None:
x = self.shortcut(x)
y = F.relu(fx + x)
return y
class Bottleneck(nn.Layer):
''' A Residual Block for ResNet-50/101/152 '''
expansion = 4 # 最后一层输出的通道扩展倍数
def __init__(self, in_size, out_size, stride=1):
'''
* `in_size`: 第一层卷积层的输入通道数
* `out_size`: 第一层卷积层的输出通道数
* `stride`: 第一层卷积层的运算步长
'''
super(Bottleneck, self).__init__()
end_size = self.expansion * out_size # 最后一层卷积层的输出通道数
self.layers = nn.Sequential(
ConvBN2d(in_size, out_size, 1, act="relu"),
ConvBN2d(out_size, out_size, 3, stride, 1, "relu"),
ConvBN2d(out_size, end_size, 1, act=None),
)
if in_size != end_size: # 进行拼接之前需要统一通道数和尺寸
self.shortcut = ConvBN2d(in_size, end_size, 1, stride, act=None)
else:
self.shortcut = None
def forward(self, x):
fx = self.layers(x)
if self.shortcut is not None:
x = self.shortcut(x)
y = F.relu(fx + x)
return y
class ResNet(nn.Layer):
def __init__(self, in_channels=3, n_classes=2, mtype=50):
'''
* `in_channels`: 输入的通道数
* `n_classes`: 输出分类数量
* `mtype`: ResNet类型(18/34/50/101/152)
'''
super(ResNet, self).__init__()
if mtype == 18: # ResNet-18
self.Block, n_blocks = BasicBlock, [2, 2, 2, 2]
elif mtype == 34: # ResNet-34
self.Block, n_blocks = BasicBlock, [3, 4, 6, 3]
elif mtype == 50: # ResNet-50
self.Block, n_blocks = Bottleneck, [3, 4, 6, 3]
elif mtype == 101: # ResNet-101
self.Block, n_blocks = Bottleneck, [3, 4, 23, 3]
elif mtype == 152: # ResNet-152
self.Block, n_blocks = Bottleneck, [3, 8, 36, 3]
else:
raise NotImplementedError("`mtype` must in [18, 34, 50, 101, 152]")
self.e = self.Block.expansion # 残差结构输出通道数的扩展倍数
self.conv1 = ConvBN2d(in_channels, 64, 7, 2, 3, "relu")
self.pool1 = nn.MaxPool2D(3, 2, 1)
self.conv2 = self._res_blocks(n_blocks[0], 64, 64, 1) # 本层不改变尺寸
self.conv3 = self._res_blocks(n_blocks[1], 64 * self.e, 128, 2)
self.conv4 = self._res_blocks(n_blocks[2], 128 * self.e, 256, 2)
self.conv5 = self._res_blocks(n_blocks[3], 256 * self.e, 512, 2)
self.pool2 = nn.AdaptiveAvgPool2D((1, 1))
self.linear = nn.Sequential(nn.Flatten(1, -1),
nn.Linear(512 * self.e, n_classes))
def forward(self, x):
x = self.conv1(x) # 64*112*112
x = self.pool1(x) # 64*56*56
x = self.conv2(x) # 64*56*56 or 256*56*56
x = self.conv3(x) # 128*28*28 or 512*28*28
x = self.conv4(x) # 256*14*14 or 1024*14*14
x = self.conv5(x) # 512*7*7 or 2048*7*7
x = self.pool2(x) # 512*1*1 or 2048*1*1
y = self.linear(x) # n_classes
return y
def _res_blocks(self, n_block, in_size, out_size, stride):
'''
* `n_block`: 残差块的数量
* `in_size`: 第一层卷积层的输入通道数
* `out_size`: 第一层卷积层的输出通道数
* `stride`: 第一个残差块卷积运算的步长
'''
blocks = [self.Block(in_size, out_size, stride),]
in_size = out_size * self.e # 后续残差块的输入通道数
for _ in range(1, n_block):
blocks.append( self.Block(in_size, out_size, stride=1) )
return nn.Sequential(*blocks)
- 实例化模型
model = ResNet(in_channels=3, n_classes=CLASS_DIM, mtype=50) # ResNet-50
3.3. 模型训练
model.train() # 开启训练模式
scheduler = NaturalExpDecay(
learning_rate=INIT_LR,
gamma=LR_DECAY
) # 定义学习率衰减器
optimizer = Adam(
learning_rate=scheduler,
parameters=model.parameters()
) # 定义Adam优化器
loss_arr, acc_arr = [], [] # 用于可视化
for ep in range(EPOCHS):
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
y_data = y_data[:, np.newaxis] # 增加一维维度
y_pred = model(x_data) # 预测结果
acc = M.accuracy(y_pred, y_data) # 计算准确率
loss = F.cross_entropy(y_pred, y_data) # 计算交叉熵
if batch_id % LOG_GAP == 0: # 定期输出训练结果
print("Epoch:%d,Batch:%2d,Loss:%.5f,Acc:%.5f"\
% (ep, batch_id, loss, acc))
acc_arr.append(acc.item())
loss_arr.append(loss.item())
optimizer.clear_grad()
loss.backward()
optimizer.step()
scheduler.step() # 每轮衰减一次学习率
paddle.save(model.state_dict(), MODEL_PATH) # 保存训练好的模型
模型训练结果如下:
Epoch:0,Batch: 0,Loss:1.28814,Acc:0.40625
Epoch:0,Batch:30,Loss:0.50501,Acc:0.81250
Epoch:1,Batch: 0,Loss:0.47952,Acc:0.79688
Epoch:1,Batch:30,Loss:0.28905,Acc:0.87500
Epoch:2,Batch: 0,Loss:0.53422,Acc:0.78125
Epoch:2,Batch:30,Loss:0.23787,Acc:0.89062
Epoch:3,Batch: 0,Loss:0.21741,Acc:0.92188
Epoch:3,Batch:30,Loss:0.21679,Acc:0.93750
Epoch:4,Batch: 0,Loss:0.22656,Acc:0.90625
Epoch:4,Batch:30,Loss:0.29999,Acc:0.89062
Epoch:5,Batch: 0,Loss:0.14857,Acc:0.95312
Epoch:5,Batch:30,Loss:0.07505,Acc:1.00000
Epoch:6,Batch: 0,Loss:0.18624,Acc:0.89062
Epoch:6,Batch:30,Loss:0.10810,Acc:0.96875
Epoch:7,Batch: 0,Loss:0.16827,Acc:0.93750
Epoch:7,Batch:30,Loss:0.11762,Acc:0.95312
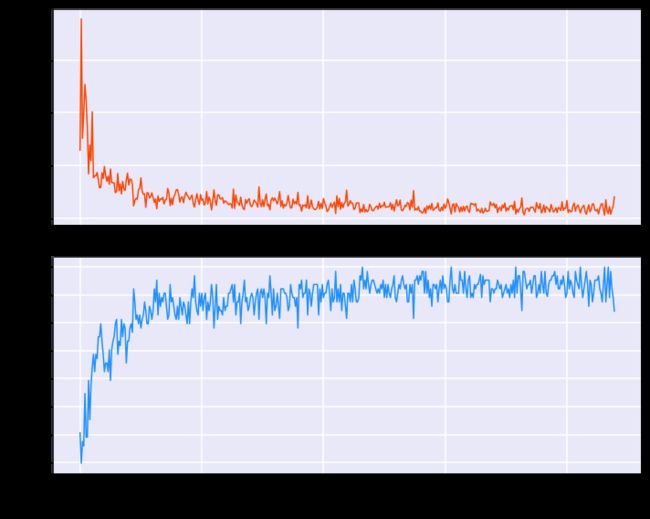
- 可视化训练过程
fig = plt.figure(figsize=[10, 8])
# 训练误差图像:
ax1 = fig.add_subplot(211, facecolor="#E8E8F8")
ax1.set_ylabel("Loss", fontsize=18)
plt.tick_params(labelsize=14)
ax1.plot(range(len(loss_arr)), loss_arr, color="orangered")
ax1.grid(linewidth=1.5, color="white") # 显示网格
# 训练准确率图像:
ax2 = fig.add_subplot(212, facecolor="#E8E8F8")
ax2.set_xlabel("Training Steps", fontsize=18)
ax2.set_ylabel("Accuracy", fontsize=18)
plt.tick_params(labelsize=14)
ax2.plot(range(len(acc_arr)), acc_arr, color="dodgerblue")
ax2.grid(linewidth=1.5, color="white") # 显示网格
fig.tight_layout()
plt.show()
plt.close()
3.4. 模型评估
model.eval() # 开启评估模式
test_costs, test_accs = [], []
for batch_id, data in enumerate(test_loader()):
x_data, y_data = data
y_data = y_data[:, np.newaxis] # 增加一维维度
y_pred = model(x_data) # 预测结果
acc = M.accuracy(y_pred, y_data) # 计算准确率
loss = F.cross_entropy(y_pred, y_data) # 计算交叉熵
test_accs.append(acc.item())
test_costs.append(loss.item())
test_loss = np.mean(test_costs) # 每轮测试的平均误差
test_acc = np.mean(test_accs) # 每轮测试的平均准确率
print("Eval \t Loss:%.5f,Acc:%.5f" % (test_loss, test_acc))
模型评估结果如下:
Eval Loss:0.12486,Acc:0.95536
3.5. 模型预测
model.eval() # 开启评估模式
model.set_state_dict(
paddle.load(MODEL_PATH)
) # 载入预训练模型参数
for idx, (img_path, label) in enumerate(infer_list):
truth_lab = LAB_DICT[str(label)] # 获取真实标签
image = data_mapper(img_path, show=True) # 获取预测图片
result = model(image[np.newaxis, :, :, :]) # 开始模型预测
infer_lab = LAB_DICT[str(np.argmax(result))] # 获取预测结果
print("图%d的真实标签:%s,预测结果:%s" % (idx+1, truth_lab, infer_lab))
模型预测结果如下:

图1的真实标签:正常肺部,预测结果:正常肺部
图2的真实标签:病毒性肺炎,预测结果:病毒性肺炎
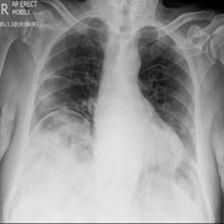
图3的真实标签:新冠肺炎,预测结果:新冠肺炎
4. 内容总结

写在最后
- 如果您发现项目存在问题,或者如果您有更好的建议,欢迎在下方评论区中留言讨论~
- 这是本项目的链接:实验项目 - AI Studio,点击
fork可直接在AI Studio运行~- 这是我的个人主页:个人主页 - AI Studio,来AI Studio互粉吧,等你哦~
- 【友链滴滴】欢迎大家随时访问我的个人博客~