StyleGAN2代码PyTorch版逐行学习(上)
详细地记录下我看StyleGAN2代码的过程,希望大家给予我一点帮助,也希望对大家有一点帮助。如果有啥错误和问题,评论区见~(私信我不咋看的)
前菜
建议大家先去自行搜索学习GAN和StyleGAN的基本原理,这里仅仅简要介绍一下StyleGAN和StyleGAN2的生成器:
StyleGAN1
以下内容的参考文献——原论文:CVPR 2019 Open Access Repository (thecvf.com)
StyleGAN的生成器主支输入是一个常量,采用渐进式结构,分层生出不同分辨率的特征图结果;侧支利用MLP将从高斯分布采样得到的噪声z映射成隐层码w。
StyleGAN的生成器在主支的每个卷积层从侧支引入隐层码w对图像进行调整,从而实现了在不同层次上控制图像的特征——最低的分辨率层控制的是高层次的属性,如人脸的形状;中间的分辨率层对应更小的方面,如发型、睁闭眼;而在最高的分辨率层控制的是最精细的方面,如脸部微观结构。再加上直接注入网络的噪声,StyleGAN的结构可以自动、无监督地分离生成图像的高层次属性与细微随机变化。
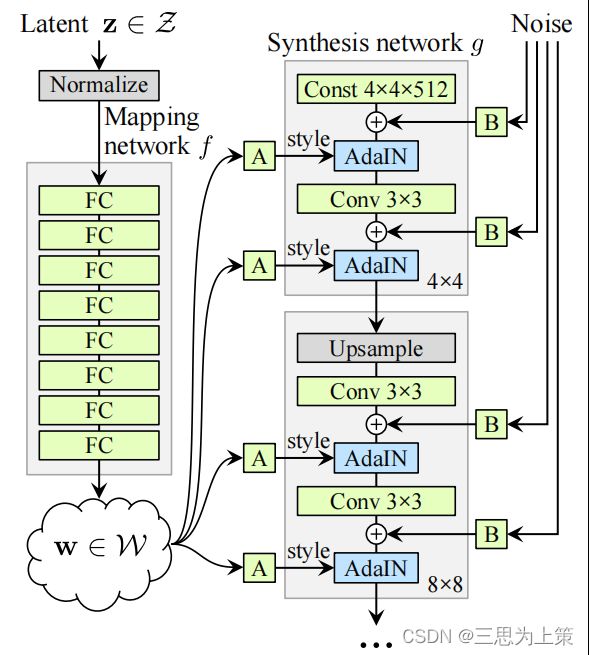
如图所示,在生成图像分辨率为1024x1024的标准情况下,z和w都是512维向量,将z映射到w的函数是一个8层的神经网络,而生成函数是一个18层的神经网络,每2层合为一个阶段,共9个生成阶段,分别对应处理的分辨率为4x4、8x8、16x16、32x32、64x64、128x128、256x256、512x512、1024x1024。
每个生成阶段都会受由1个w仿射变换产生的2个控制向量ys、yb影响(也就是图中的style),影响方式为AdaIN:将ys、yb作为缩放和偏移因子,与标准化后的卷积输出做一个加权求和,就完成了一次w影响原始输出x的过程。当影响每层的w各不相同时,将这18个w合并为w+,w+是18x512维张量。
StyleGAN2
以下内容的参考文献——原论文:CVPR 2020 Open Access Repository (thecvf.com)
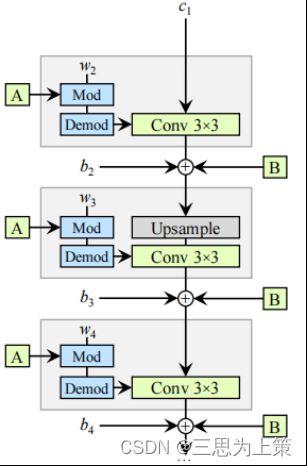
图中略去了侧支从z到w的映射部分,标注的c、w、b分别指代常量(constant)、需要学习的权重(weight)与偏差(bias),图中标出来的w不是隐层码w、仅仅是权重的意思。
与StyleGAN最初的模型版本相比,StyleGAN2的模型改进有:
(1)简化了对常量输入最开始的处理
(2)将噪声模块移出了风格模块
(3)用一种根据隐层码对各层卷积核参数调制解调的操作替代了AdaIN,该操作如以下两个公式所示:
![]()
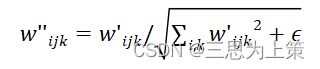
公式一中,隐层码w仿射变换为s,而后乘在卷积核参数w上。公式二中j和k分别枚举了卷积的通道数和空间维度数目,ε是一个很小的常量。
StyleGAN2的提出主要是为了消除StyleGAN产生图片中的水印缺陷,而AdaIN正是导致这个问题的主要原因,经过模型修改后,水印问题成功被解决。
正餐
以下代码出处——rosinality/stylegan2-pytorch
详细学习的代码就是model.py中的所有内容,(上)只来得及写下Generator的__init__函数以及相关的大小函数,具体forward过程且看下回分解。
1、self.size是生成图像大小,self.style_dim是隐层码维度,由输入参数指定。
class Generator(nn.Module):
def __init__(
self,
size,
style_dim,
n_mlp,
channel_multiplier=2,
blur_kernel=[1, 3, 3, 1],
lr_mlp=0.01,
):
super().__init__()
self.size = size
self.style_dim = style_dimStyleGAN2生成器创建实例时的必需参数有size(生成图像大小),style_dim(隐层码维度),n_mlp(z到w的映射网络层数),常在实际任务调用StyleGAN2生成器时如下设置:
decoder = nn.DataParallel(Generator(1024, 512, 8))2、接上段:
self.style是由PixelNorm层和8个EqualLinear层组成的MLP,也就是将噪声z映射为隐层码w的网络。
layers = [PixelNorm()]
for i in range(n_mlp): # n_mlp=8, style_dim=512, lr_mlp=0.01
layers.append(
EqualLinear(
style_dim, style_dim, lr_mul=lr_mlp, activation='fused_lrelu'
)
)
self.style = nn.Sequential(*layers)(2.1)PixelNorm函数:
class PixelNorm(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
return input * torch.rsqrt(torch.mean(input ** 2, dim=1, keepdim=True) + 1e-8)return这里的一长行公式如下,有点像前面对卷积核w调制解调时的公式二诶?
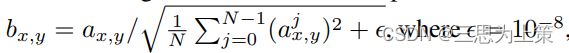
原来这个叫PixelNorm(PIXELWISE FEATURE VECTOR NORMALIZATION IN GENERATOR),出自ProgressiveGAN,为了避免幅度失控,在每个卷积层后将每个像素的特征向量归一到单位长度。
(2.2)EqualLinear函数:
调的函数本质还是torch.nn.functional.linear(此处的F.linear),只是封装了以下,对weight和bias做了一些缩放,且不同于torch.nn.linear对F.linear的封装方式。
这同样出自ProgressiveGAN,weight从标准正态分布随机采样,而将何凯明初始化放到之后动态地进行,这对RMSProp、Adam等优化方式有帮助,保证所有的weight都是一样的学习速度。
class EqualLinear(nn.Module):
def __init__(
self, in_dim, out_dim, bias=True, bias_init=0, lr_mul=1, activation=None
):
super().__init__()
self.weight = nn.Parameter(torch.randn(out_dim, in_dim).div_(lr_mul))
if bias:
self.bias = nn.Parameter(torch.zeros(out_dim).fill_(bias_init))
else:
self.bias = None
self.activation = activation
self.scale = (1 / math.sqrt(in_dim)) * lr_mul
self.lr_mul = lr_mul
def forward(self, input):
if self.activation:
out = F.linear(input, self.weight * self.scale)
out = fused_leaky_relu(out, self.bias * self.lr_mul)
else:
if self.bias is not None:
out = F.linear(
input, self.weight * self.scale, bias=self.bias * self.lr_mul
)
else:
out = F.linear(
input, self.weight * self.scale, bias=None)
return out
def __repr__(self):
return (
f'{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]})'
)3、接上段:
self.channels是各分辨率对应卷积层的输出维度列表。
self.input是主支的常量输入,self.conv1和self.to_rgb1分别是第一个卷积层和第一个to_rgb层,也就是对常量输入进行卷积和to_rgb操作。卷积核3x3,卷积层输入输出维度都是512,输入输出空间维度不变(stride=1, padding=kernel_size//2)。
self.log_size=10,self.num_layers=17表示主支除了上面的对常量输入的第一个卷积层外,还有17层。
self.channels = {
4: 512,
8: 512,
16: 512,
32: 512,
64: 256 * channel_multiplier, # channel_multiplier=2
128: 128 * channel_multiplier,
256: 64 * channel_multiplier,
512: 32 * channel_multiplier,
1024: 16 * channel_multiplier,
}
self.input = ConstantInput(self.channels[4]) # self.channels[4]=512
self.conv1 = StyledConv(
self.channels[4], self.channels[4], 3, style_dim, blur_kernel=blur_kernel
) # style_dim=512, blur_kernel=[1, 3, 3, 1]
self.to_rgb1 = ToRGB(self.channels[4], style_dim, upsample=False)
self.log_size = int(math.log(size, 2)) # 10
self.num_layers = (self.log_size - 2) * 2 + 1 # 17(3.1)ConstantInput:
return一个正态分布采样、参数化的tensor,维度为(batchsize,512,4,4)
class ConstantInput(nn.Module):
def __init__(self, channel, size=4):
super().__init__()
self.input = nn.Parameter(torch.randn(1, channel, size, size))
def forward(self, input):
batch = input.shape[0]
out = self.input.repeat(batch, 1, 1, 1)
return out(3.2)StyledConv:
ModulatedConv+NoiseInjection
class StyledConv(nn.Module):
def __init__(
self,
in_channel,
out_channel,
kernel_size,
style_dim,
upsample=False,
blur_kernel=[1, 3, 3, 1],
demodulate=True,
):
super().__init__()
self.conv = ModulatedConv2d(
in_channel,
out_channel,
kernel_size,
style_dim,
upsample=upsample,
blur_kernel=blur_kernel,
demodulate=demodulate,
)
self.noise = NoiseInjection()
self.activate = FusedLeakyReLU(out_channel)
def forward(self, input, style, noise=None):
out = self.conv(input, style)
out = self.noise(out, noise=noise)
out = self.activate(out)
return out((3.2.1))ModulatedConv2d:
类似EqualLinear,对于卷积核权重,先从标准正态分布采样、参数化,再在forward过程中通过缩放进行调整。而后按照前述原理,将隐层码映射为style,再对卷积核进行调制解调。
class ModulatedConv2d(nn.Module):
def __init__(
self,
in_channel,
out_channel,
kernel_size,
style_dim,
demodulate=True,
upsample=False,
downsample=False,
blur_kernel=[1, 3, 3, 1],
):
super().__init__()
self.eps = 1e-8
self.kernel_size = kernel_size
self.in_channel = in_channel
self.out_channel = out_channel
self.upsample = upsample
self.downsample = downsample
if upsample:
factor = 2
p = (len(blur_kernel) - factor) - (kernel_size - 1) # p=3-kernel_size
pad0 = (p + 1) // 2 + factor - 1
pad1 = p // 2 + 1
self.blur = Blur(blur_kernel, pad=(pad0, pad1), upsample_factor=factor)
if downsample:
factor = 2
p = (len(blur_kernel) - factor) + (kernel_size - 1) # p=kernel_size+1
pad0 = (p + 1) // 2
pad1 = p // 2
self.blur = Blur(blur_kernel, pad=(pad0, pad1))
fan_in = in_channel * kernel_size ** 2
self.scale = 1 / math.sqrt(fan_in)
self.padding = kernel_size // 2
self.weight = nn.Parameter(
torch.randn(1, out_channel, in_channel, kernel_size, kernel_size)
)
self.modulation = EqualLinear(style_dim, in_channel, bias_init=1)
self.demodulate = demodulate # True
def __repr__(self):
return (
f'{self.__class__.__name__}({self.in_channel}, {self.out_channel}, {self.kernel_size}, '
f'upsample={self.upsample}, downsample={self.downsample})'
)
def forward(self, input, style): # style:(batch,1,512)
# 获取前级feature map的维度信息
batch, in_channel, height, width = input.shape
# 将隐层码w映射为s(style):(batch,1,in_channel)再拉为(batch,1,in_channel,1,1)
style = self.modulation(style).view(batch, 1, in_channel, 1, 1)
# 用s调制卷积核权重(前菜-StyleGAN2-(3)公式一)
# self.weight:(1,out_channel, in_channel, kernel_size, kernel_size)
# weight:(batch,out_channel,in_channel,kernel_size,kernel_size)
weight = self.scale * self.weight * style
# 解调(前菜-StyleGAN2-(3)公式二)
if self.demodulate:
demod = torch.rsqrt(weight.pow(2).sum([2, 3, 4]) + 1e-8)
weight = weight * demod.view(batch, self.out_channel, 1, 1, 1)
weight = weight.view(
batch * self.out_channel, in_channel, self.kernel_size, self.kernel_size
)
if self.upsample:
input = input.view(1, batch * in_channel, height, width)
weight = weight.view(
batch, self.out_channel, in_channel, self.kernel_size, self.kernel_size
)
weight = weight.transpose(1, 2).reshape(
batch * in_channel, self.out_channel, self.kernel_size, self.kernel_size
)
#
out = F.conv_transpose2d(input, weight, padding=0, stride=2, groups=batch)
_, _, height, width = out.shape
out = out.view(batch, self.out_channel, height, width)
out = self.blur(out)
elif self.downsample:
input = self.blur(input)
_, _, height, width = input.shape
input = input.view(1, batch * in_channel, height, width)
out = F.conv2d(input, weight, padding=0, stride=2, groups=batch)
_, _, height, width = out.shape
out = out.view(batch, self.out_channel, height, width)
else:
input = input.view(1, batch * in_channel, height, width)
# weight:(batch*out_channel, in_channel, kernel_size, kernel_size)
# padding:kernel_size // 2, stride=1
out = F.conv2d(input, weight, padding=self.padding, groups=batch)
_, _, height, width = out.shape
out = out.view(batch, self.out_channel, height, width)
return out(((3.2.1.1)))Blur:
class Blur(nn.Module):
def __init__(self, kernel, pad, upsample_factor=1): # kernel=[1,3,3,1]
super().__init__()
kernel = make_kernel(kernel)
if upsample_factor > 1:
kernel = kernel * (upsample_factor ** 2)
# kernel不被更新但又像参数一样保存下来
self.register_buffer('kernel', kernel)
self.pad = pad
def forward(self, input):
out = upfirdn2d(input, self.kernel, pad=self.pad) # 过采样、FIR滤波和抽样
return out((((3.2.1.1.1))))make_kernel:
def make_kernel(k):
k = torch.tensor(k, dtype=torch.float32)
if k.ndim == 1:
k = k[None, :] * k[:, None]
# [1,3,3,1]变为
# ([[1., 3., 3., 1.],
# [3., 9., 9., 3.],
# [3., 9., 9., 3.],
# [1., 3., 3., 1.]])
k /= k.sum()
# ([[0.0156, 0.0469, 0.0469, 0.0156],
# [0.0469, 0.1406, 0.1406, 0.0469],
# [0.0469, 0.1406, 0.1406, 0.0469],
# [0.0156, 0.0469, 0.0469, 0.0156]])
return k((((3.2.1.1.2))))upfirdn2d: 好像是过采样、FIR滤波和抽样的意思,但StyleGAN2/op/fupfirdn2d.py那个文件我看不明白,然后也没能搜到,就先放着吧。
((3.2.2))NoiseInjection:
class NoiseInjection(nn.Module):
def __init__(self):
super().__init__()
self.weight = nn.Parameter(torch.zeros(1)) # 初始为[0],learnable
def forward(self, image, noise=None):
if noise is None:
batch, _, height, width = image.shape
noise = image.new_empty(batch, 1, height, width).normal_()
# 返回一个新size的张量,填充未初始化的数据,默认返回的张量与image同dtype和device
# 向特征图加噪
return image + self.weight * noise((3.2.3))FusedLeakyReLU:
来自StyleGAN2/op/fused_act.py恕我再次没能搞明白这个文件,反正大致是个激活呗。
(3.3)ToRGB:
class ToRGB(nn.Module):
def __init__(self, in_channel, style_dim, upsample=True, blur_kernel=[1, 3, 3, 1]):
super().__init__()
if upsample:
self.upsample = Upsample(blur_kernel)
# 将输入feature map的channel变为3(即rgb三通道图),kernel_size=1x1,不变空间维度
self.conv = ModulatedConv2d(in_channel, 3, 1, style_dim, demodulate=False)
self.bias = nn.Parameter(torch.zeros(1, 3, 1, 1))
def forward(self, input, style, skip=None):
out = self.conv(input, style) #(batch, 3, h, w)
out = out + self.bias
# 如果要跳连,则先上采样再residual
if skip is not None:
skip = self.upsample(skip)
out = out + skip
return out((3.3.1))Upsample:
这和Blur(见(((2.1.1))))长得好像,但就是没太整明白。
class Upsample(nn.Module):
def __init__(self, kernel, factor=2):
super().__init__()
self.factor = factor
kernel = make_kernel(kernel) * (factor ** 2)
self.register_buffer('kernel', kernel)
p = kernel.shape[0] - factor
pad0 = (p + 1) // 2 + factor - 1
pad1 = p // 2
self.pad = (pad0, pad1)
def forward(self, input):
out = upfirdn2d(input, self.kernel, up=self.factor, down=1, pad=self.pad)
return out4、接上段:
组装了17层的noise,16层的self.convs、8层的self.to_rgbs。
self.n_latent=18意味着共18层卷积层需要18个latent code w去分别调制每一层的卷积核。
self.convs = nn.ModuleList()
self.upsamples = nn.ModuleList()
self.to_rgbs = nn.ModuleList()
self.noises = nn.Module()
in_channel = self.channels[4]
for layer_idx in range(self.num_layers): # self.num_layers=17
res = (layer_idx + 5) // 2 # 2,3,3,4,4,5,5,...,10,10
shape = [1, 1, 2 ** res, 2 ** res] #17层对应4x4~1024x1024共9种分辨率
# 高斯分布采(1,1,h,w)大小的噪声,每层对应存下
self.noises.register_buffer(f'noise_{layer_idx}', torch.randn(*shape))
for i in range(3, self.log_size + 1): # self.log_size=10, i取值范围[3,10]
# 取列表中设好的对应分辨率的channel数
out_channel = self.channels[2 ** i]
# 一种分辨率对应两个卷积层,第一个变通道数且上采样、第二个并不
self.convs.append(
StyledConv(
in_channel,
out_channel,
3,
style_dim,
upsample=True,
blur_kernel=blur_kernel,
)
)
self.convs.append(
StyledConv(
out_channel, out_channel, 3, style_dim, blur_kernel=blur_kernel
)
)
self.to_rgbs.append(ToRGB(out_channel, style_dim)) # 一种分辨率一个ToRGB层
in_channel = out_channel
self.n_latent = self.log_size * 2 - 2 # 18
5、接上段:
定义了一些小函数,功能如注释所示。
def make_noise(self):
device = self.input.input.device
noises = [torch.randn(1, 1, 2 ** 2, 2 ** 2, device=device)]
for i in range(3, self.log_size + 1): # i的范围[3,10]
for _ in range(2): # 重复2次
noises.append(torch.randn(1, 1, 2 ** i, 2 ** i, device=device))
return noises #制造17个noise map
def mean_latent(self, n_latent):
# 随机采18x512的噪声
latent_in = torch.randn(
n_latent, self.style_dim, device=self.input.input.device
)
# 先将噪声映射为隐层码w,再取平均得到1x512的结果
latent = self.style(latent_in).mean(0, keepdim=True)
return latent
def get_latent(self, input):
# 将噪声映射为隐层码w
return self.style(input)下面就是forward函数了耶,写到(下)里去吧!~
StyleGAN2代码PyTorch版逐行学习(下)