python实现基于用户的的协同过滤算法
本周学习内容汇报:
学习协同过滤,逻辑回归,因子分解机等传统推荐模型,熟悉了每种模型的思想以及它们的优缺点。使用MovieLens数据集用Python实现基于用户的协同过滤算法和基于物品的协同过滤算法和使用pytorch复现FM。
- python实现基于用户的的协同过滤算法
算法流程:
-
- 数据集处理
使用MovieLens数据集 数据集中每个变量代表的意思
userId : 用户 ID
movieId : 用户看过的电影 ID
rating : 用户对所看电影的评分
timestap : 用户看电影的时间戳
-
- 定义变量
N : 记录用户看过的电影数量,如: N[“1”] = 10 表示用户 ID 为 “1” 的用户看过 10 部电影;
W : 相似矩阵,存储两个用户的相似度,如:W[“1”][“2”] = 0.66 表示用户 ID 为 “1” 的用户和用户 ID 为 “2” 的用户相似度为 0.66 ;
train : 用户记录数据集中的数据, 格式为: train= { user : [[item1, rating1], [item2, rating2], …], …… }
item_users : 将数据集中的数据转换为 物品_用户 的倒排表,这样做的原因是在计算用户相似度的时候,可以只计算看过相同电影的用户之间的相似度(没看过相同电影的用户相似度默认为 0 ),倒排表的形式为: item_users = { item : [user1, user2, …], ……}
k : 使用最相似的 k 个用户作推荐
n : 为用户推荐 n 部电影
-
- 加载数据
从数据集中读出数据,将数据以 { user : [[item1, rating1], [item2, rating2], …],……} 的形式存入 train 中,并整理成形如 { item : [user1, user2, …], ……} 的倒排表,存入 item_users 中。
-
- 计算相似度矩阵
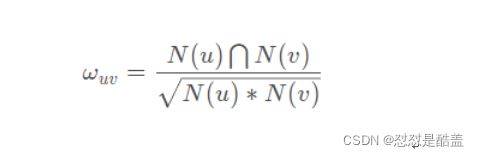
基于用户的协同过滤算法的思想是有相似兴趣的用户(user)可能会喜欢相同的物品(item)。因此,计算用户的相似度成为该算法的关键步骤。实现过程中使用的相似度公式如下:
其中 N(u) 表示用户 u 看过的电影个数。
遍历 item_users ,统计每个用户看过的电影 item 的次数,同时遍历 item_users 中的 users ,先计算用户 u 和用户 v 看过相同电影的个数存在 W 中, 然后遍历 W ,使用上述公式计算用户 u 和用户 v 的相似度。
-
- 推荐
最后为用户 u 推荐,首先从 item_users 中获得用户 u 已经看过的电影,然后将用户按相似度排序,并取前 k 个用户,对这 k 个用户看过但用户 u 没有看过的电影计算加权评分和,计算公式为:用户相似度 * 用户对电影的评分。
-
- 代码运行结果
程序随机选择一位用户,根据和他最相似的 30 个用户,为其推荐 10 部电影,打印出推荐电影的 ID 和加权评分 [[电影ID, 加权评分],[电影ID,加权评分],……]。
[('8368', 18.62732007530837), ('68954', 18.56220733375745), ('6377', 17.15104837332028), ('58559', 15.323360864347197), ('8961', 14.729418859494816), ('56367', 14.609493525827729), ('5989', 14.579143788113251), ('2959', 14.574110342046716), ('318', 14.450046074595624), ('4963', 13.78373564820972)]
- python 实现基于物品的协同过滤算法
与基于用户的协同过滤算法的算法流程类似区别之处:
-
- 计算物品相似矩阵
物品相似度的计算公式为: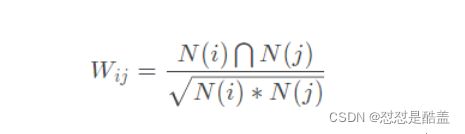
其中N ( i ) 表示电影 i 被看过的次数,N ( i ) ⋂ N ( j ) 表示同时看过电影 i 和电影 j 的用户数。
具体计算如下:
首先遍历 train 变量 { user : [[item1, rating1], [item2, rating2], …],……} ,取出用户看过的电影列表,使用变量 i 遍历该用户看过的电影 ,对看过该电影的用户数(即变量 N(i) )加一,同时使用变量 j 遍历该用户看过的电影,如果 i 和 j 不同,则 W[i][j] 加一(此时W[i][j]记录的是同时看过电影 i 和电影 j 的用户数)。
遍历 W 矩阵,对 W 中的每一个元素进行如下计算:得到的 W 矩阵就是物品之间的相似度矩阵。
2.2. 推荐
首先获得用户已经看过的电影列表,遍历该电影列表,对于用户看过的电影 i ,找出与电影 i 最相似的前 k 个电影(对 W[i] 按照相似度排序),计算这 k 个电影各自的加权评分(rank):对rank按照评分倒序排序,取前 n 个推荐给用户即可。
2.3 实验结果展示
start loading data from ratings.csv
loading data successfully
start caculating similarity matrix ...
caculating similarity matrix successfully
start recommending items for user whose userId is 360
items recommeded for user whose userId is 360 :
[('2115', 12.599387984936264), ('2762', 12.390314342878924), ('1580', 10.178598234142198), ('2628', 8.72413463199201), ('1240', 8.69518606413058), ('2126', 8.503179297247316), ('1100', 7.644982642223123), ('1610', 7.503336083694675), ('1573', 7.458142040761965), ('2110', 6.956617382760688)]
Process finished with exit code 0
- pytorch 复现 FM
factorization machines 提出了将特征进行交叉,以达到从特征中学习到更多有价值的信息。它的思想是为每个特征学习一个隐向量。使用 MovieLens 数据集复现 FM 的过程如下:
- 数据预处理 引入需要的包
- 处理 users 数据 将用户数据读入 将用户的 userId, gender, age, occupation, zipCode Label Encoding 编码
- 处理用户评分数据 读入用户评分数据 将数据 label encoding 编码
将用户数据和评分数据合并
- 然后完成数据处理(dataset) 模型 训练 & 测试 main 文件模块
- 模型复现运行结果展示
- 学习收获归纳总结
本周主要对传统推荐模型的发展脉络有了清晰地认识,对各种传统推荐模型的基本思想有了基本的了解,推荐算法在发现问题解决问题中不断演进,对传统的推荐模型进行了相关归纳总结:
( 1 ) 协同过滤算法。从物品相似度和用户相似度角度出发,协同过滤衍生出物品协同过滤( ItemCF ) 和用户协同过滤( UserCF )两种算法。为了使协同过滤能够更好地处理稀疏共现矩阵问题、增强模型的泛化能力,从协同过滤衍生出矩阵分解 模型( Matrix Factorization, MF ),并发展出矩阵分解的各分支模型。
( 2 )逻辑回归模型。与协同过滤仅利用用户和物品之间的显式或隐式反馈信息相比,逻辑回归能够利用和融合更多用户、物品及上下文特征。从 LR 模型衍生出的模型同样 “枝繁叶茂”,包括增强了非线性能力的大规模分片线性模型
( Large Scale Piece-wise Linear Model, LS-PLM ), 由逻辑回归发展出来的 FM 模型,以及与多种不同模型配合使用后的组合模型,等等。
( 3 ) 因子分解机模型。因子分解机在传统逻辑回归的基础上,加入了二阶部分,使模型具备了进行特征组合的能力。更进一步,在因子分解机基础上发展出来的域感知因子分解机( Field-aware Factorization Machine, FFM )则通过加入特征域的概念,进一步加强了因子分解机特征交叉的能力。
( 4 )组合模型。为了融合多个模型的优点,将不同模型组合使用是构建推荐模型常用的方法。Facebook 提出了 GBDT+LR[ 梯度提升决策树( Gradient Boosting Decision Tree )+逻辑回归 ]
- 下周学习计划
- 继续完成传统推荐模型的复现工作,加深对传统推荐模型的理解与认识。
- 学习深度学习在推荐系统中的应用
- 加强阅读相关文献论文
- 相关代码展示
- 基于用户的的协同过滤算法
import random
import operator
class UserBasedCF:
def __init__(self):
self.N = {} # number of items user interacted, N[u] = the number of items user u interacted
self.W = {} # similarity of user u and user v
self.train = {} # train = { user : [[item1, rating1], [item2, rating2], …], …… }
self.item_users = {} # item_users = { item : [user1, user2, …], …… }
# recommend n items from the k most similar users
self.k = 30
self.n = 10
def get_data(self, file_path):
"""
@description: load data from dataset
@file_path: path of dataset
"""
with open(file_path, 'r') as f:
for i, line in enumerate(f, 0):
if i != 0: # remove the title of the first line
line = line.strip('\n')
user, item, rating, timestamp = line.split(',')
self.train.setdefault(user, [])
self.train[user].append([item, rating])
self.item_users.setdefault(item, [])
self.item_users[item].append(user)
def similarity(self):
"""
@description: calculate similarity between user u and user v
"""
for item, users in self.item_users.items():
for u in users:
self.N.setdefault(u, 0)
self.N[u] += 1
for v in users:
if u != v:
self.W.setdefault(u, {})
self.W[u].setdefault(v, 0)
self.W[u][v] += 1 # number of items which both user u and user v have interacted
for u, user_cnts in self.W.items():
for v, cnt in user_cnts.items():
self.W[u][v] = self.W[u][v] / (self.N[u] * self.N[v]) ** 0.5 # similarity between user u and user v
def recommendation(self, user):
"""
@description: recommend items for user
@param user : the user who is recommended, we call this user u
@return : items recommended for user u
"""
watched = [i[0] for i in self.train[user]] # items that user have interacted
rank = {}
for v, similar in sorted(self.W[user].items(), key=operator.itemgetter(1), reverse=True)[
0:self.k]: # order user v by similarity between user v and user u
for item_rating in self.train[v]: # items user v have interacted
if item_rating[0] not in watched: # item user hvae not interacted
rank.setdefault(item_rating[0], 0.)
rank[item_rating[0]] += similar * float(item_rating[1])
return sorted(rank.items(), key=operator.itemgetter(1), reverse=True)[0:self.n]
if __name__ == "__main__":
file_path = "ratings.csv"
userBasedCF = UserBasedCF()
userBasedCF.get_data(file_path)
userBasedCF.similarity()
user = random.sample(list(userBasedCF.train), 1)
rec = userBasedCF.recommendation(user[0])
print(rec)
-
- 基于物品的的协同过滤算法
import random
import operator
class ItemBasedCF:
def __init__(self):
self.N = {} # number of item user have interacted
self.W = {} # similarity matrix to store similarity of item i and item j
self.train = {}
# recommend n items from the k most similar to the items user have interacted
self.k = 30
self.n = 10
def get_data(self, file_path):
"""
@description: load data from file
@param file_path: path of file
"""
print('start loading data from ', file_path)
with open(file_path, "r") as f:
for i, line in enumerate(f, 0):
if i != 0: # remove the first line that is title
line = line.strip('\r')
user, item, rating, timestamp = line.split(',')
self.train.setdefault(user, [])
self.train[user].append([item, rating])
print('loading data successfully')
def similarity(self):
"""
@description: caculate similarity between item i and item j
"""
print('start caculating similarity matrix ...')
for user, item_ratings in self.train.items():
items = [x[0] for x in item_ratings] # items that user have interacted
for i in items:
self.N.setdefault(i, 0)
self.N[i] += 1 # number of users who have interacted item i
for j in items:
if i != j:
self.W.setdefault(i, {})
self.W[i].setdefault(j, 0)
self.W[i][j] += 1 # number of users who have interacted item i and item j
for i, j_cnt in self.W.items():
for j, cnt in j_cnt.items():
self.W[i][j] = self.W[i][j] / (self.N[i] * self.N[j]) ** 0.5 # similarity between item i and item j
print('caculating similarity matrix successfully')
def recommendation(self, user):
"""
@description: recommend n item for user
@param user: recommended user
@return items recommended for user
"""
print('start recommending items for user whose userId is ', user)
rank = {}
watched_items = [x[0] for x in self.train[user]]
for i in watched_items:
for j, similarity in sorted(self.W[i].items(), key=operator.itemgetter(1), reverse=True)[0:self.k]:
if j not in watched_items:
rank.setdefault(j, 0.)
rank[j] += float(self.train[user][watched_items.index(i)][
1]) * similarity # rating that user rate for item i * similarity between item i and item j
return sorted(rank.items(), key=operator.itemgetter(1), reverse=True)[0:self.n]
if __name__ == "__main__":
file_path = "ratings.csv"
itemBasedCF = ItemBasedCF()
itemBasedCF.get_data(file_path)
itemBasedCF.similarity()
user = random.sample(list(itemBasedCF.train), 1)
rec = itemBasedCF.recommendation(user[0])
print('\nitems recommeded for user whose userId is', user[0], ':')
print(rec)
-
- 使用pytorch复现FM模型
相关代码模块太多不再展示