推荐系统—基于用户的协同过滤算法简单实现
前言
- 目的:实现一个基于用户(user-based)的协同过滤算法
- 数据集:用户对电影的评分
- 最终结果:为用户推荐电影
- 算法评价:用户预估评分与真实评分的差距
数据集介绍
- 训练集:实现简单的推荐,训练集只用到如下框选出的三个数据

- 测试集:评价算法只需要如下三个框选出的数据集
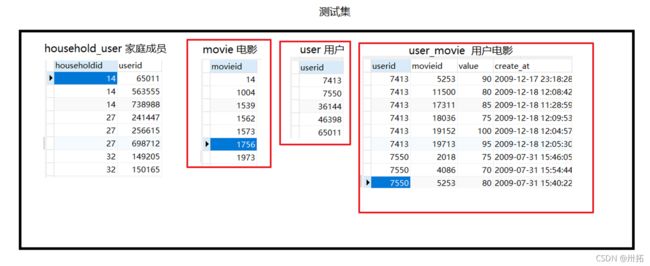
- 数据集简述:训练集可以合并为一个user_movie_train.shape = 58×1625的数据集,测试集可以合并为一个user_movie_test.shape = 58×146的数据集,两个数据集中不包含重复打分!
一、推荐算法流程
-
是什么
基于用户(user-based)的协同过滤主要考虑的是用户和用户之间的相似度,只要找出相似用户喜欢的物品,并预测目标用户对对应物品的评分,就可以找到评分最高的若干个物品推荐给用户。
-
为什么
推荐呗~~~

-
怎么做:
①首先:我们需要知道目标用户A看过哪些电影,没看过哪些电影,这样才能推荐。所以我们需要一个user_movie表。
②其次:我们要知道与目标用户A相似度高的用户在看什么电影,这样才能推荐。这里需要一个user_user表记录用户间相似度。
③怎么实现推荐?可以根据邻居用户(相似度高的前n个用户)对目标用户A未看过的电影的打分,来预测目标用户A所有未看过的电影的可能评分,并将估分最高的电影优先推荐
二、分步实现
2.1 构建user_movie表

这一步就是简单的读表:读取user表作为列,读取movie表作为行,根据user_movie表填充矩阵。然后可以对矩阵中可能存在的情况进行简单分析~
2.2 构建user_user表
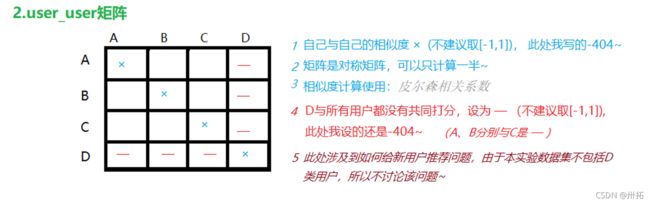
此处可以参考的计算相似度代码:
def getSimilarity(a, b):
vectorA = pd.DataFrame(np.array(a))
vectorB = pd.DataFrame(np.array(b))
# 找两个向量同时非-404的元素重新组成两个向量
y = np.where(vectorA + vectorB >= 0)
#print(y[0]) 这里需要打印出来看看到底是啥鬼玩意
if len(y[0]) == 0: # 如果完全没有共同看过的电影,返回-404
return -404
return vectorA[y[1][0]].corr(vectorB[y[1][0]])
a = [-404, 20, 30, -404, 80, -404]
b = [-404, 80, 90, -404, 0, -404]
c = [0, -404, -404, 70, -404, 40]
d = [-404, -404, -404, -404, -404, -404]
print(getSimilarity(a,b)) #0.9792308883055543
print(getSimilarity(a,c)) #-404 a与c直接无共同评分的电影
print(getSimilarity(a,d),getSimilarity(b,c),getSimilarity(b,d),getSimilarity(c,d)) #-404 同上
#嘿嘿代码仅供参考,作者的实验用的都不完全是这份代码哈哈哈哈
计算完两两间相似度后,填充到user_user表中即可~
2.3 找到邻居用户和该用户未评分电影
- 取出user_user中每行,排个序取前n个(此处作者取的是前15个)作为该用户的邻居用户
- 获取目标用户的未观看电影id集合
#可参考一下代码逻辑~
movie_list = user_movie.loc[[user_id]] #user_id是整形
movie_list = movie_list.iloc[0] # dataframe转成series
movie_unrated_index = np.where(movie_list < 0)[0] # (在这附近踩到了坑,补个博客pandas通过索引数组,获取对应值数组)
2.4 预测未看过电影的喜好程度
公式:其中I 是与目标用户相似度较高(且对该电影有评分的邻居用户集合)(可以灵活选择I的个数~)
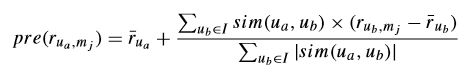
2.4 对未看过电影评分进行排序,然后推荐
- 上文已经获得k为电影名,v为电影喜好程度的字典movie_prevalue_dict,想按值对字典进行降序排序,然后排第一的(大概率)是最先推荐的啦~
sorted(movie_prevalue_dict.items(),key=lambda x:x[1],reverse=True)
"""
第一个参数是需要排序的列表,第二个参数是指定key(列表中每一项的第几个元素)来进行排序。
解释这句代码:d.items()返回的是一个列表 [('a', 74), ('b', 90), ('c', 84), ('d', 85), ('e', 64), ('f', 66), ('g', 88)]
sorted会对d.items()这个list进行遍历,把list中的每一个元素,也就是每一个tuple()当做x传入匿名函数lambda x:x[1],函数返回值为x[1],
也就是key=x[1]=tuple()[1]=('a', 74)[1],也就是说按照里表中每个项的第二个元素进行排序(第一个是想x[0])
"""
#感谢:https://www.cnblogs.com/zhuminghui/p/9251968.html
三、算法评估
3.1 由于预测喜好程度的计算公式无上限(上限不是100分),所以不能通过预测值与真实值的误差评估算法,可以通过预测喜好程度排序与真实排序比较评估。例如,计算P值等
3.2 本实验用了一个不是很标准的评估方法,如有更好的方法,欢迎大佬推荐、指正!

3.3流程
- 上文得到了有顺序的,类似{用户1,电影1,电影2,…电影n; 用户2,电影1,电影2,…电影n; …}的为用户推荐电影的csv文件(训练集经训练后得到的文件)
- 按同2.1的代码,读入训练集
- 预处理测试集:只保留有评分的数据,排序后得到字典:user_movie_test
- 预处理训练集:只保留测试集中有的电影,得到字典user_movie_recommend_train
- 根据电影的顺序评价模型好坏:计算余弦相似度
- 结果
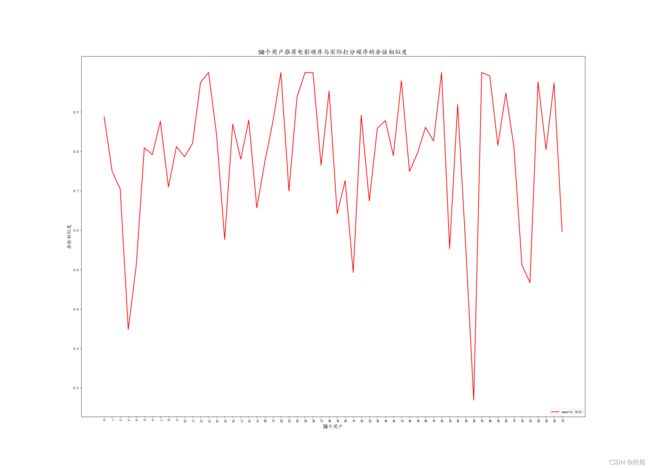
- 总结:由于测试集过小(58*146),训练集数据较稀疏,如图所示结果并不是特别好。平均余弦相似度为0.787
- 评价模型缺点
①当某用户训练集中只有一个评价电影时(ps:训练集和测试集中无重复数据!),预测的顺序一定与真实的顺序一致,相似度为1。。。如[‘1539’]与[‘1539’]余弦相似度为1
② [‘1539’, ‘4851’] 与 [‘4851’, ‘1539’]的相似度:[0.57648501]
3.4 绘制AUC曲线
可以看一下关于AUC曲线绘制的文,有代码
但上述链接中的AUC值的计算与此处的计算不同,毕竟上述链接主要是针对二分类问题,本文是针对推荐列表。


3.5 计算P值

(不是很懂怎么算,提供个思路,放个图…下同)
3.5 计算召回率
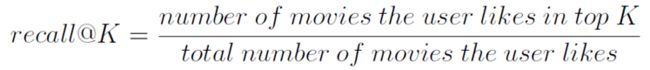
3.6 计算平均精确度MAP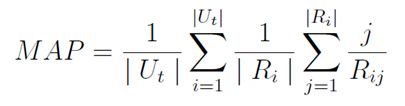

水平有限,请多指正!
恳请路过的你提供一些推荐算法的评估思路呀
![]()
四、其它
- 如果选择python语言,推荐使用numpy+pandas,比for循环好用点。

*aaa我现学的,踩了好多坑aaa。用啥功能百度啥,刺激啊* - 建议自己玩一下,其实还是挺有意思的

五、相关文文~
- pandas通过索引数组,获取对应值数组
- python绘制ROC曲线,计算AUC