算法实习生面试问题准备
文章目录
- 1.深度学习
-
-
-
- 1.梯度下降公式推导及代码实现
- 2.反向传播公式推导及代码实现
- 3.激活函数的种类及各自的作用
- 4.深层神经网络和浅层神经网络的区别
- 5.梯度消失、梯度爆炸及解决方式
- 6.优化算法
- 7.超参数
- 8.归一化的优点,哪些模型需要归一化
- 9.过滤器
- 10.CNN中各层
- 11.权值共享和稀疏连接
- 12.经典卷积网络
- 13.RNN和LSTM的区别
- 14.Word2Vec
- 15.注意力模型Attention Model
-
-
- 2.机器学习
-
-
-
- 1.批量梯度下降、随机梯度下降(SGD)、小批量(mini-batch)梯度下降的区别
- 2.梯度下降与正规方程的比较
- 3.逻辑回归和线性回归区别与联系
- 4.什么是过拟合,防止过拟合的方法
- 5.改进算法性能的方法
- 6.训练、验证、测试集
- 7.偏差和方差,各参数与偏差方差的关系
- 8.查准率与查全率及其之间的权衡
- 9.SVM
- 10.Kmeans及其K如何选择
- 11.PCA、SVD
- 12.异常检测算法
- 13.推荐系统
-
-
- 3.数据结构与算法
-
- 数据结构
-
-
- 1.散列表冲突的解决方式
- 2.二叉树的前中后序遍历递归法和迭代法
-
- 排序算法
- 经典算法
-
- 1.动态规划
- 2.DFS、BFS、递归、回溯
- 4.计算机基础知识
-
- Linux操作系统
- 数据库
-
- Mysql
- Redis
- 5.编程语言
-
- Python
-
-
- 版本新特性
- 赋值、浅拷贝、深拷贝
- 装饰器
- 生成器
- 广播
-
- Java
- 6.数学与思维
- 7.项目经验
-
- 编程框架
-
- TensorFlow
- 论文
-
- 传统算法
- 新兴算法
- 8.HR面
1.深度学习
1.梯度下降公式推导及代码实现
forword propagation:
z [ 1 ] = W [ 1 ] x + b [ 1 ] a [ 1 ] = σ ( z [ 1 ] ) z^{[1]}=W^{[1]}x+b^{[1]}\space \space \space a^{[1]}=\sigma(z^{[1]}) z[1]=W[1]x+b[1] a[1]=σ(z[1])
z [ 2 ] = W [ 2 ] a [ 1 ] + b [ 2 ] a [ 2 ] = g [ 2 ] ( z [ 2 ] ) = σ ( z [ 2 ] ) z^{[2]}=W^{[2]}a^{[1]}+b^{[2]}\space \space \space a^{[2]}=g^{[2]}(z^{[2]})=\sigma(z^{[2]}) z[2]=W[2]a[1]+b[2] a[2]=g[2](z[2])=σ(z[2])
back propagation:
d z [ 2 ] = A [ 2 ] − Y , Y = [ y [ 1 ] y [ 2 ] . . . y [ m ] ] dz^{[2]}=A^{[2]}-Y,Y=[y^{[1]}\space y^{[2]}\space ...\space y^{[m]}] dz[2]=A[2]−Y,Y=[y[1] y[2] ... y[m]]
d W [ 2 ] = 1 m d z [ 2 ] A [ 1 ] T dW^{[2]}=\frac{1}{m}dz^{[2]}A^{[1]T} dW[2]=m1dz[2]A[1]T
d b [ 2 ] = 1 m n p . s u m ( d z [ 2 ] , a x i s = 1 , k e e p d i m s = T r u e ) db^{[2]}=\frac{1}{m}np.sum(dz^{[2]},axis=1,keepdims=True) db[2]=m1np.sum(dz[2],axis=1,keepdims=True)
d z [ 1 ] = W [ 2 ] T d z [ 2 ] ∗ g [ 1 ] ′ ( z [ 1 ] ) dz^{[1]}=W^{[2]T}dz^{[2]}*g^{[1]'}(z^{[1]}) dz[1]=W[2]Tdz[2]∗g[1]′(z[1])
d W [ 1 ] = 1 m d z [ 1 ] x T dW^{[1]}=\frac{1}{m}dz^{[1]}x^{T} dW[1]=m1dz[1]xT
d b [ 1 ] = 1 m n p . s u m ( d z [ 1 ] , a x i s = 1 , k e e p d i m s = T r u e ) db^{[1]}=\frac{1}{m}np.sum(dz^{[1]},axis=1,keepdims=True) db[1]=m1np.sum(dz[1],axis=1,keepdims=True)
其中axis=1在python中表示水平相加求和,keepdims确保矩阵 d b [ 2 ] db^{[2]} db[2]这个向量输出的维度为 ( n , 1 ) (n,1) (n,1)这样的标准形式。
z = w T x + b z=w^Tx+b z=wTx+b y ^ = a = σ ( z ) \hat y=a=\sigma(z) y^=a=σ(z)
L ( a , y ) = − ( y l o g ( a ) + ( 1 − y ) l o g ( 1 − a ) ) L(a,y)=-(ylog(a)+(1-y)log(1-a)) L(a,y)=−(ylog(a)+(1−y)log(1−a))
d L ( a , y ) a = − y a + 1 − y 1 − a \frac{dL(a,y)}{a}=-\frac{y}{a}+\frac{1-y}{1-a} adL(a,y)=−ay+1−a1−y
进一步推导得出:
d a d z = a ⋅ ( 1 − a ) \frac{da}{dz}=a·(1-a) dzda=a⋅(1−a)
d z = d L ( a , y ) d z = d L d a ⋅ d a d z = ( y a + 1 − y 1 − a ) ⋅ a ( 1 − a ) = a − y dz=\frac{dL(a,y)}{dz}=\frac{dL}{da}·\frac{da}{dz}=(\frac{y}{a}+\frac{1-y}{1-a})·a(1-a)=a-y dz=dzdL(a,y)=dadL⋅dzda=(ay+1−a1−y)⋅a(1−a)=a−y
d w 1 = x 1 ⋅ d z dw_1=x_1·dz dw1=x1⋅dz
d w 2 = x 2 ⋅ d z dw_2=x_2·dz dw2=x2⋅dz
d b = d z db=dz db=dz
关于单个样本的梯度下降算法,需要使用公式 d z = ( a − y ) dz=(a-y) dz=(a−y)计算 d z dz dz,然后计算 d w 1 、 d w 2 、 d b dw_1、dw_2、db dw1、dw2、db,然后更新 w 1 = w 1 − α d w 1 w_1=w_1-\alpha dw_1 w1=w1−αdw1; w 2 = w 2 − α d w 1 w_2=w_2-\alpha dw_1 w2=w2−αdw1; b = b − α d w 1 b=b-\alpha dw_1 b=b−αdw1。
当存在m个样本时,关于损失函数 J ( w , b ) J(w,b) J(w,b)的函数定义: J ( w , b ) = 1 m ∑ i = 1 m L ( a ( i ) , y ( i ) ) J(w,b)=\frac{1}{m}\sum_{i=1}^{m}L(a^{(i)},y^{(i)}) J(w,b)=m1i=1∑mL(a(i),y(i))
此方法的代码如下:
J=0;dw1=0;dw2=0;db=0;# 初始化
for i = 1 to m # 遍历所有样本
z(i) = wx(i)+b;
a(i) = sigmoid(z(i));
J += -[y(i)log(a(i))+(1-y(i))log(1-a(i)];
dz(i) = a(i)-y(i);
# 遍历所有特征
dw1 += x1(i)dz(i);
dw2 += x2(i)dz(i);
db += dz(i);
J/= m;
dw1/= m;
dw2/= m;
db/= m;
w=w-alpha*dw
b=b-alpha*db
2.反向传播公式推导及代码实现
前向传播:
Input a [ l − 1 ] a^{[l-1]} a[l−1],Output a [ l ] = g [ l ] ( z [ l ] ) a^{[l]}=g^{[l]}(z^{[l]}) a[l]=g[l](z[l]),cache z [ l ] = W [ l ] ⋅ a [ l − 1 ] + b [ l ] z^{[l]}=W^{[l]}·a^{[l-1]}+b^{[l]} z[l]=W[l]⋅a[l−1]+b[l]
向量化实现:
Z [ l ] = W [ l ] ⋅ A [ l − 1 ] + b [ l ] Z^{[l]}=W^{[l]}·A^{[l-1]}+b^{[l]} Z[l]=W[l]⋅A[l−1]+b[l], A [ l ] = g [ l ] ( Z [ l ] ) A^{[l]}=g^{[l]}(Z^{[l]}) A[l]=g[l](Z[l])
反向传播:
( 1 ) d z [ l ] = d a [ l ] ∗ g [ l ] ′ ( z [ l ] ) (1)dz^{[l]}=da^{[l]}*g^{[l]'}(z^{[l]}) (1)dz[l]=da[l]∗g[l]′(z[l])
( 2 ) d w [ l ] = d z [ l ] ⋅ a [ l − 1 ] (2)dw^{[l]}=dz^{[l]}·a^{[l-1]} (2)dw[l]=dz[l]⋅a[l−1]
( 3 ) d b [ l ] = d z [ l ] (3)db^{[l]}=dz^{[l]} (3)db[l]=dz[l]
( 4 ) d a [ l − 1 ] = w [ l ] T ⋅ d z [ l ] (4)da^{[l-1]}=w^{[l]T}·dz^{[l]} (4)da[l−1]=w[l]T⋅dz[l]
( 5 ) d z [ l ] = w [ l + 1 ] T d z [ l + 1 ] ⋅ g [ l ] ′ ( z [ l ] ) (5)dz^{[l]}=w^{[l+1]T}dz^{[l+1]}·g^{[l]'}(z^{[l]}) (5)dz[l]=w[l+1]Tdz[l+1]⋅g[l]′(z[l])式4代入式1得到
向量化实现:
( 1 ) d Z [ l ] = d A [ l ] ∗ g [ l ] ′ ( Z [ l ] ) (1)dZ^{[l]}=dA^{[l]}*g^{[l]'}(Z^{[l]}) (1)dZ[l]=dA[l]∗g[l]′(Z[l])
( 2 ) d W [ l ] = 1 m d Z [ l ] ⋅ A [ l − 1 ] T (2)dW^{[l]}=\frac{1}{m}dZ^{[l]}·A^{[l-1]T} (2)dW[l]=m1dZ[l]⋅A[l−1]T
( 3 ) d b [ l ] = 1 m n p . s u m ( d z [ l ] , a x i s = 1 , k e e p d i m s = T r u e ) (3)db^{[l]}=\frac{1}{m}np.sum(dz^{[l]},axis=1,keepdims=True) (3)db[l]=m1np.sum(dz[l],axis=1,keepdims=True)
( 4 ) d A [ l − 1 ] = W [ l ] T ⋅ d Z [ l ] (4)dA^{[l-1]}=W^{[l]T}·dZ^{[l]} (4)dA[l−1]=W[l]T⋅dZ[l]
隐藏层如果有三层,第一层的激活函数可以使用ReLU,第二层可以使用ReLU,第三层可以使用sigmoid(如果做二分类)。
3.激活函数的种类及各自的作用
如果你是用线性激活函数或者叫恒等激励函数,那么神经网络只是把输入线性组合再输出。不能在隐藏层用线性激活函数,可以用ReLU或者tanh或者leaky ReLU或者其他的非线性激活函数,唯一可以用线性激活函数的通常就是输出层。
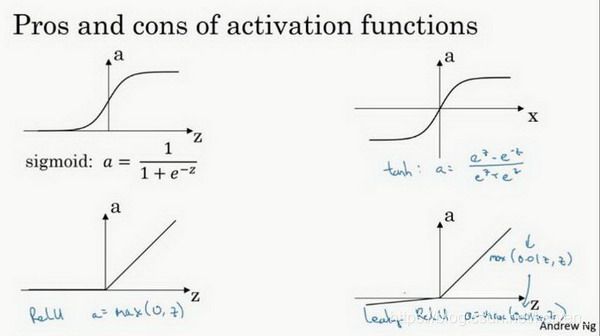
1.Sigmoid activation function
a = σ ( z ) = 1 1 + e − z a=\sigma (z)=\frac{1}{1+e^{-z}} a=σ(z)=1+e−z1
d d z g ( z ) = d d z g ( 1 1 + e − z ) = 1 1 + e − z ( 1 − 1 1 + e − z ) = g ( z ) ( 1 − g ( z ) ) \frac{d}{dz}g(z)=\frac{d}{dz}g(\frac{1}{1+e^{-z}})=\frac{1}{1+e^{-z}}(1-\frac{1}{1+e^{-z}})=g(z)(1-g(z)) dzdg(z)=dzdg(1+e−z1)=1+e−z1(1−1+e−z1)=g(z)(1−g(z))
当 z = ± 10 z=±10 z=±10时, g ( z ) ′ ≈ 0 g(z)'≈0 g(z)′≈0
当 z = 0 z=0 z=0时, g ( z ) ′ = 1 4 g(z)'=\frac{1}{4} g(z)′=41
在神经网络中, a = g ( z ) , g ( z ) ′ = a ( 1 − a ) a=g(z),g(z)'=a(1-a) a=g(z),g(z)′=a(1−a)
2.Tanh activation function双曲正切函数
a = t a n h ( z ) = e z − e − z e z + e − z a=tanh(z)=\frac{e^z-e^{-z}}{e^z+e^{-z}} a=tanh(z)=ez+e−zez−e−z
d d z g ( z ) = d d z g ( e z − e − z e z + e − z ) = 1 − ( t a n h ( z ) ) 2 \frac{d}{dz}g(z)=\frac{d}{dz}g(\frac{e^z-e^{-z}}{e^z+e^{-z}})=1-(tanh(z))^2 dzdg(z)=dzdg(ez+e−zez−e−z)=1−(tanh(z))2
当 z = ± 10 z=±10 z=±10时, g ( z ) ′ ≈ 0 g(z)'≈0 g(z)′≈0
当 z = 0 z=0 z=0时, g ( z ) ′ = 0 g(z)'=0 g(z)′=0
在神经网络中, a = g ( z ) , g ( z ) ′ = 1 − a 2 a=g(z),g(z)'=1-a^2 a=g(z),g(z)′=1−a2
tanh函数的值域在-1到1之间,数据的平均值接近0而不是0.5,这会使下一层的学习更加简单。sigmoid函数和tanh函数共同的缺点:在z特别大或特别小时导数的梯度或者函数的斜率接近于0,导致降低梯度下降的速度降低。
3.Rectified linear unit(ReLu) 修正线性单元函数
在z是正数时导数恒等于1,在z是负数时,导数恒等于0。
a = R e L u ( z ) = m a x ( 0 , z ) a=ReLu(z)=max(0,z) a=ReLu(z)=max(0,z)
g ( z ) = m a x ( 0 , z ) g(z)=max(0,z) g(z)=max(0,z)
g ( z ) ′ = { 0 i f z < 0 1 i f z > 0 u n d e f i n e d i f z = 0 g(z)'=\left\{\begin{matrix} 0 & if\space z<0\\ 1 & if\space z>0\\ undefined & if\space z=0 \end{matrix}\right. g(z)′=⎩⎨⎧01undefinedif z<0if z>0if z=0
通常在 z = 0 z=0 z=0时给定其导数1,0;当然 z = 0 z=0 z=0的情况很少。
4.Leaky Rectified linear unit(Leaky ReLu)
g ( z ) = m a x ( 0.01 z , z ) g(z)=max(0.01z,z) g(z)=max(0.01z,z)
g ( z ) ′ = { 0.01 i f z < 0 1 i f z > 0 u n d e f i n e d i f z = 0 g(z)'=\left\{\begin{matrix} 0.01 & if\space z<0\\ 1 & if\space z>0\\ undefined & if\space z=0 \end{matrix}\right. g(z)′=⎩⎨⎧0.011undefinedif z<0if z>0if z=0
通常在 z = 0 z=0 z=0时给定其导数1,0.01;当然 z = 0 z=0 z=0的情况很少。
激活函数选择的经验法则:
- 若输出是0、1值(二分类问题),则输出层选择sigmoid函数,其余所有单元选择ReLu函数
- 若隐藏层不确定使用哪个激活函数,通常选择ReLu函数
还有另一版本的ReLu函数Leaky ReLu,当z是负值时函数值不为0,而是微微倾斜,这个函数的激活效果优于ReLu,尽管使用不多。
4.深层神经网络和浅层神经网络的区别
深度神经网络的这许多隐藏层中,较早的前几层能学习一些低层次的简单特征,后几层就能把简单的特征结合起来,去探测更加复杂的东西。
Small:隐藏单元的数量相对较少
Deep:隐藏层数目比较多
深层的网络隐藏单元数量相对较少,隐藏层数目较多,如果浅层的网络想要达到同样的计算结果则需要指数级增长的单元数量才能达到。
5.梯度消失、梯度爆炸及解决方式
训练神经网络时,深度神经网络通常会面临梯度消失或梯度爆炸的问题,就是导数或坡度有时会变得非常大或非常小,加大了训练难度。
实施梯度检验的过程,英语简称“grad check。
Take W [ 1 ] , b [ 1 ] , . . . , W [ L ] , b [ L ] W^{[1]},b^{[1]},...,W^{[L]},b^{[L]} W[1],b[1],...,W[L],b[L] and reshape into a big vector θ \theta θ,即 J ( W [ 1 ] , b [ 1 ] , . . . , W [ L ] , b [ L ] ) = J ( θ ) = J ( θ 1 , θ 2 , θ 3 , . . . ) J(W^{[1]},b^{[1]},...,W^{[L]},b^{[L]})=J(\theta)=J(\theta _1,\theta _2,\theta _3,...) J(W[1],b[1],...,W[L],b[L])=J(θ)=J(θ1,θ2,θ3,...)
Take d W [ 1 ] , d b [ 1 ] , . . . , d W [ L ] , d b [ L ] dW^{[1]},db^{[1]},...,dW^{[L]},db^{[L]} dW[1],db[1],...,dW[L],db[L] and reshape into a big vector d θ d\theta dθ
循环执行,对每一个 i i i也就是每个 θ \theta θ组成元素计算 d θ a p p r o x [ i ] d\theta_{approx}[i] dθapprox[i]的值,使用双边误差:
d θ a p p r o x [ i ] = J ( θ 1 , θ 2 , . . . θ 1 + ϵ , . . . ) − J ( θ 1 , θ 2 , . . . θ 1 − ϵ , . . . ) 2 ϵ d\theta_{approx}[i]=\frac{J(\theta _1,\theta _2,...\theta_1+\epsilon,...)-J(\theta _1,\theta _2,...\theta_1-\epsilon,...)}{2\epsilon} dθapprox[i]=2ϵJ(θ1,θ2,...θ1+ϵ,...)−J(θ1,θ2,...θ1−ϵ,...)
只对 θ i \theta_i θi增加 ϵ \epsilon ϵ, θ \theta θ其他项不变,对另一边减去 ϵ \epsilon ϵ, θ \theta θ其他项不变。 d θ a p p r o x [ i ] d\theta_{approx}[i] dθapprox[i]应该接近 d θ [ i ] = ∂ J ∂ θ i d\theta[i]=\frac{\partial J}{\partial \theta_i} dθ[i]=∂θi∂J, d θ [ i ] d\theta[i] dθ[i]是代价函数的偏导数,需要对 i i i的每个值都执行这个运算,最后得到逼近值 d θ a p p r o x d\theta_{approx} dθapprox,取 ϵ = 1 0 − 7 \epsilon=10^{-7} ϵ=10−7时,求出 ∥ d θ a p p r o x − d θ ∥ 2 ∥ d θ a p p r o x ∥ 2 + ∥ d θ ∥ 2 \frac{\left \|d\theta_{approx}-d\theta\right \|_2}{\left \|d\theta_{approx}\right \|_2+\left \|d\theta\right \|_2} ∥dθapprox∥2+∥dθ∥2∥dθapprox−dθ∥2的值,若其在 1 0 − 7 10^{-7} 10−7范围内,则结果正确,若在 1 0 − 5 10^{-5} 10−5范围内,可能存在bug。
6.优化算法
1.动量梯度下降法(Momentum):计算梯度的指数加权平均数,利用该梯度更新权重。
2.RMSprop(root mean square prop)算法可以加速梯度下降。实现步骤: S d W = β S d W + ( 1 − β ) d W 2 S_{dW}=\beta S_{dW}+(1-\beta)dW^2 SdW=βSdW+(1−β)dW2
S d b = β S d b + ( 1 − β ) d b 2 S_{db}=\beta S_{db}+(1-\beta)db^2 Sdb=βSdb+(1−β)db2
W : = W − α d W S d W W:=W-\alpha\frac{dW}{\sqrt{S_{dW}}} W:=W−αSdWdW
b : = b − α d b S d b b:=b-\alpha\frac{db}{\sqrt{S_{db}}} b:=b−αSdbdb
其中 d W 2 dW^2 dW2和 d b 2 db^2 db2是指对整个微分进行平方
3.Adam(Adaptive Moment Estimation)优化算法将Momentum和RMSprop结合起来。
初始化: V d w = 0 , S d W = 0 , v d b = 0 , S d b = 0 V_{dw}=0,S_{dW}=0,v_{db}=0,S_{db}=0 Vdw=0,SdW=0,vdb=0,Sdb=0
在第 t t t次迭代中,使用当前的mini-bratch计算 d W , d b dW,db dW,db:
v d W = β 1 v d W + ( 1 − β 1 ) d W , v d b = β 1 v d b + ( 1 − β 1 ) d b v_{dW}=\beta_1v_{dW}+(1-\beta_1)dW,\space v_{db}=\beta_1v_{db}+(1-\beta_1)db vdW=β1vdW+(1−β1)dW, vdb=β1vdb+(1−β1)db
S d W = β 2 S d W + ( 1 − β 2 ) d W 2 , S d b = β 2 S d b + ( 1 − β 2 ) d b 2 S_{dW}=\beta_2 S_{dW}+(1-\beta_2)dW^2,\space S_{db}=\beta_2 S_{db}+(1-\beta_2)db^2 SdW=β2SdW+(1−β2)dW2, Sdb=β2Sdb+(1−β2)db2
v d W c o r r e c t e d = v d W 1 − β 1 t , v d b c o r r e c t e d = v d b 1 − β 1 t v^{corrected}_{dW}=\frac{v_{dW}}{1-\beta_1^t},\space v^{corrected}_{db}=\frac{v_{db}}{1-\beta_1^t} vdWcorrected=1−β1tvdW, vdbcorrected=1−β1tvdb
S d W c o r r e c t e d = S d W 1 − β 2 t , S d b c o r r e c t e d = S d b 1 − β 2 t S^{corrected}_{dW}=\frac{S_{dW}}{1-\beta_2^t},\space S^{corrected}_{db}=\frac{S_{db}}{1-\beta_2^t} SdWcorrected=1−β2tSdW, Sdbcorrected=1−β2tSdb
W : = W − α V d W c o r r e c t e d S d W c o r r e c t e d + ϵ , b : = b − α V d b c o r r e c t e d S d b c o r r e c t e d + ϵ W:=W-\alpha\frac{V^{corrected}_{dW}}{\sqrt{S^{corrected}_{dW}+\epsilon}},\space b:=b-\alpha\frac{V^{corrected}_{db}}{\sqrt{S^{corrected}_{db}+\epsilon}} W:=W−αSdWcorrected+ϵVdWcorrected, b:=b−αSdbcorrected+ϵVdbcorrected
Momentum: β 1 \beta_1 β1的缺省值为0.9,这是 d W dW dW的移动加权平均值(第一矩)
Adam: β 2 \beta_2 β2的缺省值为0.999,这是 d W 2 dW^2 dW2和 d b 2 db^2 db2的移动加权平均值(第二矩)
ϵ \epsilon ϵ取值多少不重要,通常为 1 0 − 8 10^{-8} 10−8
7.超参数
- 学习速率 α \alpha α
- 动量梯度下降法(Momentum)中的 β \beta β
- 不同层中隐藏单元数量 h i d d e n u n i t s hidden \space units hidden units
- m i n i − b a t c h s i z e mini-batch \space size mini−batch size
- 网络层数 l a y e r s layers layers
- 学习率衰减 l e a r i n g r a t e d e c a y learing \space rate \space decay learing rate decay
- Adam中的 β 1 , β 2 , ϵ \beta_1,\beta_2,\epsilon β1,β2,ϵ
搜索超参数的方式:
- Babysitting one model熊猫方式
- Training many models in parallel鱼子酱方式
8.归一化的优点,哪些模型需要归一化
归一化输入可以加速训练
均值归一化(Mean normalization): x n = x n − μ n s n x_n=\frac{x_n-\mu_n}{s_n} xn=snxn−μn μ n \mu_n μn 平均值, s n s_n sn 标准差。
Batch归一化使得参数搜索问题变得容易,使神经网络对超参数的选择更加稳定,超参数的范围会更加庞大,工作效果也很好,也会使得训练更加容易,甚至是深层网络。当训练一个模型,如logistic回归时,归一化输入特征 x x x可以加快学习过程。归一化 a [ l − 1 ] a^{[l-1]} a[l−1]的平均值和方差可以使 w [ l ] w^{[l]} w[l]和 b [ l ] b^{[l]} b[l]的训练更有效率,实际是对 z [ l − 1 ] z^{[l-1]} z[l−1]的归一化。
针对 l l l层进行归一化: μ = 1 m ∑ i m z ( i ) \mu = \frac{1}{m}\sum^m_iz^{(i)} μ=m1i∑mz(i)
σ = 1 m ∑ i m ( z ( i ) − μ ) 2 \sigma = \frac{1}{m}\sum^m_i(z^{(i)}-\mu)^2 σ=m1i∑m(z(i)−μ)2
z n o r m ( i ) = z ( i ) − μ σ 2 + ϵ z^{(i)}_{norm}=\frac{z^{(i)}-\mu}{\sqrt{\sigma^2+\epsilon}} znorm(i)=σ2+ϵz(i)−μ
z z z标准化后化为含平均值0和标准单位方差, z z z的每一个分量都含有平均值0和方差1,但我们不想让隐藏单元总是含有平均值0和方差1,隐藏单元有了不同的分布会有意义。下面计算 z ~ ( i ) \tilde z^{(i)} z~(i):
z ~ ( i ) = γ z n o r m ( i ) + β \tilde z^{(i)}=\gamma z^{(i)}_{norm}+\beta z~(i)=γznorm(i)+β
γ \gamma γ和 β \beta β是模型的学习参数,我们使用梯度下降或一些其它类似梯度下降的算法,比如Momentum或者Nesterov,Adam更新 γ \gamma γ和 β \beta β,正如更新神经网络的权重一样。可以随意设置 z ~ ( i ) \tilde z^{(i)} z~(i)的平均值,如果 γ = σ 2 + ϵ \gamma=\sqrt{\sigma^2+\epsilon} γ=σ2+ϵ, β = μ \beta=\mu β=μ,则 z ~ ( i ) = z ( i ) \tilde z^{(i)}=z^{(i)} z~(i)=z(i)。通过赋予 γ \gamma γ和 β \beta β其它值可以构造含其它平均值和方差的隐藏单元值。在网络匹配这个单元的方式,之前可能是用 z ( 1 ) , z ( 2 ) z^{(1)},z^{(2)} z(1),z(2)等等,现在则会用 z ~ ( i ) \tilde z^{(i)} z~(i)取代 z ( i ) z^{(i)} z(i),方便神经网络中的后续计算。
9.过滤器
Sobel过滤器: [ 1 0 − 1 2 0 − 2 1 0 − 1 ] \begin{bmatrix} 1 & 0 & -1 \\ 2 & 0 & -2 \\ 1 & 0 & -1 \end{bmatrix} ⎣⎡121000−1−2−1⎦⎤优点在于增加了中间一行元素的权重,这使得结果的鲁棒性会更高一些。
Scharr过滤器: [ 3 0 − 3 10 0 − 10 3 0 − 3 ] \begin{bmatrix} 3 & 0 & -3 \\ 10 & 0 & -10 \\ 3 & 0 & -3 \end{bmatrix} ⎣⎡3103000−3−10−3⎦⎤它有着和之前完全不同的特性,实际上也是一种垂直边缘检测,如果将其翻转90度就能得到对应水平边缘检测。
10.CNN中各层
如果 l l l是一个卷积层:
f [ l ] = f i l t e r s i z e f^{[l]}=filter \space size f[l]=filter size
p [ l ] = p a d d i n g p^{[l]}=padding p[l]=padding
s [ l ] = s t r i d e s^{[l]}=stride s[l]=stride
n c [ l ] = n u m b e r o f f i l t e r s n_c^{[l]}=number\space of\space filters nc[l]=number of filters
I n p u t : n H [ l − 1 ] × n W [ l − 1 ] × n c [ l − 1 ] Input:n_H^{[l-1]}×n_W^{[l-1]}×n_c^{[l-1]} Input:nH[l−1]×nW[l−1]×nc[l−1]
O u t p u t : n H [ l ] × n W [ l ] × n c [ l ] Output:n_H^{[l]}×n_W^{[l]}×n_c^{[l]} Output:nH[l]×nW[l]×nc[l]
n H [ l ] = [ n H [ l − 1 ] + 2 p [ l ] − f [ l ] s [ l ] + 1 ] n_H^{[l]}=[\frac{n_H^{[l-1]}+2p^{[l]}-f^{[l]}}{s^{[l]}}+1] nH[l]=[s[l]nH[l−1]+2p[l]−f[l]+1]
n W [ l ] = [ n W [ l − 1 ] + 2 p [ l ] − f [ l ] s [ l ] + 1 ] n_W^{[l]}=[\frac{n_W^{[l-1]}+2p^{[l]}-f^{[l]}}{s^{[l]}}+1] nW[l]=[s[l]nW[l−1]+2p[l]−f[l]+1]
E a c h f i l t e r i s : f [ l ] × f [ l ] × n c [ l − 1 ] Each \space filter \space is:f^{[l]}×f^{[l]}×n_c^{[l-1]} Each filter is:f[l]×f[l]×nc[l−1]
A c t i v a t i o n s : a [ l ] → m × n H [ l ] × n W [ l ] × n c [ l ] Activations:a^{[l]}\to m×n_H^{[l]}×n_W^{[l]}×n_c^{[l]} Activations:a[l]→m×nH[l]×nW[l]×nc[l](m个例子)
A [ l ] → n H [ l ] × n W [ l ] × n c [ l ] A^{[l]}\to n_H^{[l]}×n_W^{[l]}×n_c^{[l]} A[l]→nH[l]×nW[l]×nc[l]
W i g h t s : f [ l ] × f [ l ] × n c [ l − 1 ] × n c [ l ] Wights:f^{[l]}×f^{[l]}×n_c^{[l-1]}×n_c^{[l]} Wights:f[l]×f[l]×nc[l−1]×nc[l]
b i a s : n c [ l ] → ( 1 , 1 , 1 , n c [ l ] ) bias:n^{[l]}_c\to (1,1,1,n^{[l]}_c) bias:nc[l]→(1,1,1,nc[l])
池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性。
最大池化的输入是 n H × n W × n c n_H×n_W×n_c nH×nW×nc,假设没有padding,则输出为 [ n H − f s + 1 ] × [ n W − f s + 1 ] × n c [\frac{n_H-f}{s}+1]×[\frac{n_W-f}{s}+1]×n_c [snH−f+1]×[snW−f+1]×nc。执行反向传播时,反向传播没有参数适用于最大池化。只有这些设置过的超参数,可能是手动设置的,也可能是通过交叉验证设置的。
全连接层
11.权值共享和稀疏连接
和只用全连接层相比,卷积网络映射参数较少,有两个原因:参数共享和稀疏连接。神经网络可以通过这两种机制减少参数,以便用更小的训练集来训练它,从而预防过度拟合。
12.经典卷积网络
- LeNet-5
- AlexNet
- VGG
- 1 X 1 卷积
- ResNet
- Inception
13.RNN和LSTM的区别

14.Word2Vec
softmax模型要预测不同目标词的概率: S o f t m a x : p ( t ∣ c ) = e θ t T e c ∑ j = 1 10000 e θ j T e c Softmax:p(t|c)=\frac{e^{\theta^T_te_c}}{\sum^{10000}_{j=1}e^{\theta^T_je_c}} Softmax:p(t∣c)=∑j=110000eθjTeceθtTec
softmax的损失函数为: L ( y ^ , y ) = − ∑ i = 1 10000 y i l o g y ^ i L(\hat y,y)=-\sum^{10000}_{i=1}y_ilog\hat y_i L(y^,y)=−i=1∑10000yilogy^i
15.注意力模型Attention Model
2.机器学习
1.批量梯度下降、随机梯度下降(SGD)、小批量(mini-batch)梯度下降的区别
批量梯度下降:
J ( θ 0 , θ 1 . . . θ n ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J\left( {\theta_{0}},{\theta_{1}}...{\theta_{n}} \right)=\frac{1}{2m}\sum\limits_{i=1}^{m}{{{\left( h_{\theta} \left({x}^{\left( i \right)} \right)-{y}^{\left( i \right)} \right)}^{2}}} J(θ0,θ1...θn)=2m1i=1∑m(hθ(x(i))−y(i))2
其中: h θ ( x ) = θ T X = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n h_{\theta}\left( x \right)=\theta^{T}X={\theta_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}}+...+{\theta_{n}}{x_{n}} hθ(x)=θTX=θ0+θ1x1+θ2x2+...+θnxn
在随机梯度下降法中,定义代价函数为一个单一训练实例的代价:
c o s t ( θ , ( x ( i ) , y ( i ) ) ) = 1 2 ( h θ ( x ( i ) ) − y ( i ) ) 2 cost\left( \theta, \left( {x}^{(i)} , {y}^{(i)} \right) \right) = \frac{1}{2}\left( {h}_{\theta}\left({x}^{(i)}\right)-{y}^{{(i)}} \right)^{2} cost(θ,(x(i),y(i)))=21(hθ(x(i))−y(i))2
随机梯度下降算法:首先对训练集随机“洗牌”,然后:
Repeat (usually anywhere between1-10){
for i = 1 : m i = 1:m i=1:m{
θ : = θ j − α ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \theta:={\theta}_{j}-\alpha\left( {h}_{\theta}\left({x}^{(i)}\right)-{y}^{(i)} \right){{x}_{j}}^{(i)} θ:=θj−α(hθ(x(i))−y(i))xj(i)
(for j = 0 : n j=0:n j=0:n)
}
}
随机梯度下降算法在每一次计算之后便更新参数 θ {{\theta }} θ ,而不需要首先将所有的训练集求和,在梯度下降算法还没有完成一次迭代时,随机梯度下降算法便已经走出了很远。但是这样算法存在的问题是,不是每一步都是朝着”正确”的方向迈出。因此算法虽然会逐渐走向全局最小值的位置,但是可能无法站到那个最小值的那一点,而是在最小值点附近徘徊。
小批量梯度下降算法是介于批量梯度下降算法和随机梯度下降算法之间的算法,每计算常数 b b b次训练实例,便更新一次参数 θ {{\theta }} θ 。
Repeat {
for i = 1 : m i = 1:m i=1:m{
θ : = θ j − α 1 b ∑ k = i i + b − 1 ( h θ ( x ( k ) ) − y ( k ) ) x j ( k ) \theta:={\theta}_{j}-\alpha\frac{1}{b}\sum_{k=i}^{i+b-1}\left( {h}_{\theta}\left({x}^{(k)}\right)-{y}^{(k)} \right){{x}_{j}}^{(k)} θ:=θj−αb1∑k=ii+b−1(hθ(x(k))−y(k))xj(k)
(for j = 0 : n j=0:n j=0:n)
i + = 10 i +=10 i+=10
}
}
需要确定mini-bratch的大小, m m m为训练集大小,极端情况下
- 若mini-bratch=m,即bratch梯度下降法,其成本函数曲线相对噪声小,下降幅度大,若训练样本大,单次迭代耗时长。
- 若mini-bratch=1,称为随机梯度下降法,每个样本都是独立的mini-bratch,其成本函数曲线存在很多噪声,最终会靠近最小值,有时也会方向错误,永远无法收敛。通过减小学习速率,噪声会有所减小,整体效率低。
实际要取合适的mini-bratch尺寸,若训练集很小(m<2000)直接使用batch梯度下降法,若训练集很大,一般取mini-bratch为64到512,是2的 n n n次方。
2.梯度下降与正规方程的比较
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率 α \alpha α | 不需要 |
| 需要多次迭代 | 一次运算得出 |
| 当特征数量 n n n大时也能较好适用 | 需要计算 ( X T X ) − 1 {{\left( {{X}^{T}}X \right)}^{-1}} (XTX)−1 如果特征数量n较大则运算代价大,因为矩阵逆的计算时间复杂度为 O ( n 3 ) O\left( {{n}^{3}} \right) O(n3),通常来说当 n n n小于10000 时还是可以接受的 |
| 适用于各种类型的模型 | 只适用于线性模型,不适合逻辑回归模型等其他模型 |
| θ = ( X T X ) − 1 X T y \theta ={{\left( {X^T}X \right)}^{-1}}{X^{T}}y θ=(XTX)−1XTy |
3.逻辑回归和线性回归区别与联系
代价函数均为 J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) log ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] J\left( \theta \right)=-\frac{1}{m}\sum\limits_{i=1}^{m}{[{{y}^{(i)}}\log \left( {h_\theta}\left( {{x}^{(i)}} \right) \right)+\left( 1-{{y}^{(i)}} \right)\log \left( 1-{h_\theta}\left( {{x}^{(i)}} \right) \right)]} J(θ)=−m1i=1∑m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
最小化代价函数的方法,是使用梯度下降法(gradient descent): θ j : = θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) {\theta_j}:={\theta_j}-\alpha \frac{1}{m}\sum\limits_{i=1}^{m}{({h_\theta}({{x}^{(i)}})-{{y}^{(i)}}){x_{j}}^{(i)}} θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i)
对于线性回归假设函数: h θ ( x ) = θ T X = θ 0 x 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n {h_\theta}\left( x \right)={\theta^T}X={\theta_{0}}{x_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}}+...+{\theta_{n}}{x_{n}} hθ(x)=θTX=θ0x0+θ1x1+θ2x2+...+θnxn
逻辑回归假设函数: h θ ( x ) = 1 1 + e − θ T X {h_\theta}\left( x \right)=\frac{1}{1+{{e}^{-{\theta^T}X}}} hθ(x)=1+e−θTX1
即使更新参数的规则看起来基本相同,但由于假设的定义发生了变化,所以逻辑函数的梯度下降,跟线性回归的梯度下降实际上不同。
4.什么是过拟合,防止过拟合的方法
解决过拟合的方案:
- 丢弃一些不能帮助正确预测的特征。可以手工选择保留哪些特征,或使用一些模型选择的算法来帮忙(如PCA)。
- 正则化。 保留所有的特征,但是减少参数的大小(magnitude)。
- 数据扩增:翻转、旋转、扭曲图片以增大数据集
- early stopping在迭代过程和训练过程中 w w w的值会变得越来越大,通过early stopping在中间点停止迭代过程得到一个 w w w值中等大小的弗罗贝尼乌斯范数。
正则化:增加一个正则化的表达式得到代价函数:
J ( θ ) = 1 m ∑ i = 1 m [ − y ( i ) log ( h θ ( x ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n θ j 2 J\left( \theta \right)=\frac{1}{m}\sum\limits_{i=1}^{m}{[-{{y}^{(i)}}\log \left( {h_\theta}\left( {{x}^{(i)}} \right) \right)-\left( 1-{{y}^{(i)}} \right)\log \left( 1-{h_\theta}\left( {{x}^{(i)}} \right) \right)]}+\frac{\lambda }{2m}\sum\limits_{j=1}^{n}{\theta _{j}^{2}} J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj2
要最小化该代价函数,通过求导,得出梯度下降算法为:
R e p e a t Repeat Repeat u n t i l until until c o n v e r g e n c e convergence convergence{
θ 0 : = θ 0 − a 1 m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) x 0 ( i ) ) {\theta_0}:={\theta_0}-a\frac{1}{m}\sum\limits_{i=1}^{m}{(({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{0}^{(i)}}) θ0:=θ0−am1i=1∑m((hθ(x(i))−y(i))x0(i))
θ j : = θ j − a [ 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) + λ m θ j ] {\theta_j}:={\theta_j}-a[\frac{1}{m}\sum\limits_{i=1}^{m}{({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{j}^{\left( i \right)}}+\frac{\lambda }{m}{\theta_j}] θj:=θj−a[m1i=1∑m(hθ(x(i))−y(i))xj(i)+mλθj]
f o r for for j = 1 , 2 , . . . n j=1,2,...n j=1,2,...n
}
L 2 r e g u l a r i z a t i o n : ∥ w ∥ 2 2 = ∑ j = 1 n x w j 2 = w T w L_2\space regularization:\left\| w\right\|^{2}_2=\sum^{n_x}_{j=1}w^{2}_j=w^Tw L2 regularization:∥w∥22=j=1∑nxwj2=wTw
此方法利用了欧几里得范数(2范数),称为 L 2 L2 L2正则化。此处只正则化 w w w而不正则化 b b b,因为 w w w通常是高维参数矢量,已经可以表达高偏差问题,加了参数 b b b并没有什么影响。 λ \lambda λ也是一个超参数 。
L 1 r e g u l a r i z a t i o n : λ 2 m ∑ j = 1 n x ∣ w j ∣ = λ 2 m ∥ w ∥ 1 L_1\space regularization:\frac{\lambda}{2m}\sum^{n_x}_{j=1}|w_j|=\frac{\lambda}{2m}\left\| w\right\|_1 L1 regularization:2mλj=1∑nx∣wj∣=2mλ∥w∥1
L 1 L1 L1正则化 w w w最终是稀疏的,即 w w w向量中有很多0,实际上这样也并没有降低太多的存储内存,一般在训练网络时选择 L 2 L2 L2正则化。
J ( w [ 1 ] , b [ 1 ] , . . . , w [ L ] , b [ L ] ) = 1 m ∑ i = 1 m L ( y ^ ( i ) , y ( i ) ) + λ 2 m ∑ l = 1 L ∥ w [ l ] ∥ F 2 J(w^{[1]},b^{[1]},...,w^{[L]},b^{[L]})=\frac{1}{m}\sum^m_{i=1}L(\hat y^{(i)},y^{(i)})+\frac{\lambda}{2m}\sum^L_{l=1}\left\| w^{[l]}\right\|^{2}_F J(w[1],b[1],...,w[L],b[L])=m1i=1∑mL(y^(i),y(i))+2mλl=1∑L∥∥∥w[l]∥∥∥F2
∥ w [ l ] ∥ F 2 = ∑ i = 1 n l − 1 ∑ j = 1 n l ( w i j l ) 2 \left\| w^{[l]}\right\|^{2}_F=\sum^{n^{l-1}}_{i=1}\sum^{n^{l}}_{j=1}(w^{l}_{ij})^2 ∥∥∥w[l]∥∥∥F2=i=1∑nl−1j=1∑nl(wijl)2
∥ w [ l ] ∥ F 2 \left\| w^{[l]}\right\|^{2}_F ∥∥w[l]∥∥F2矩阵范数被称作“弗罗贝尼乌斯范数”,用下标 F F F标注,代表矩阵中所有元素的平方求和,其中 W : ( n [ l − 1 ] , n [ l ] ) W:(n^{[l-1]},n^{[l]}) W:(n[l−1],n[l]), l l l为神经网络层数。
∂ J ∂ w [ l ] = d w [ l ] = ( f r o m b a c k p r o p ) + λ m w [ l ] \frac{\partial J}{\partial w^{[l]}}=dw^{[l]}=(from\space backprop)+\frac{\lambda}{m}w^{[l]} ∂w[l]∂J=dw[l]=(from backprop)+mλw[l]
w [ l ] : = w ( l ) − α d w [ l ] = w ( l ) − α [ ( f r o m b a c k p r o p ) + λ m w [ l ] ] = w [ l ] − α λ m w [ l ] − α ( f r o m b a c k p r o p ) w^{[l]}:=w^{(l)}-\alpha dw^{[l]}=w^{(l)}-\alpha [(from\space backprop)+\frac{\lambda}{m}w^{[l]}]=w^{[l]}-\frac{\alpha \lambda}{m}w^{[l]}-\alpha(from\space backprop) w[l]:=w(l)−αdw[l]=w(l)−α[(from backprop)+mλw[l]]=w[l]−mαλw[l]−α(from backprop)
矩阵 W W W前面的系数为 ( 1 − α λ m ) < 1 (1-\alpha \frac{\lambda}{m})<1 (1−αmλ)<1,因此 L 2 L2 L2正则化有时被称为“权重衰减”。
dropout(随机失活)正则化会遍历网络的每一层,并设置消除网络中节点的概率。
最常用的方法实施dropout,即Inverted dropout(反向随机失活),定义向量 d d d, d [ 3 ] d^{[3]} d[3]表示一个三层的dropout向量:
d3=np.random.rand(a3.shape[0],a3.shape[1])
判断 d 3 d3 d3是否小于keep-prob,keep-prob是一个具体的数字,表示保留某个隐藏单元的概率。若 k e e p − p r o b = 0.8 keep-prob=0.8 keep−prob=0.8,表示消除任意一个隐藏单元的概率是0.2, d [ 3 ] d^{[3]} d[3]是一个矩阵,每个样本和每个隐藏单元, d [ 3 ] d^{[3]} d[3]中对应值为1的概率为0.8,对应为0的概率为0.2。
从第三层中获取激活函数 a [ 3 ] a^{[3]} a[3]:
a3=np.multiply(a3,d3) 或者a3 *= d3
最后向外扩展 a [ 3 ] a^{[3]} a[3],以便不影响后面的期望值。
a3 /= keep-prob
5.改进算法性能的方法
-
获得更多的训练样本——通常是有效的,但代价较大,下面的方法也可能有效,可考虑先采用下面的几种方法。
-
尝试减少特征的数量
-
尝试获得更多的特征
-
尝试增加多项式特征
-
尝试减少正则化程度 λ \lambda λ
-
尝试增加正则化程度 λ \lambda λ
6.训练、验证、测试集
- 训练集(training set):尝试不同的模型框架训练数据(80%)
- 验证集(development set):通过验证集或简单交叉验证集选择最好的算法模型(10%)
- 测试集(test set):正确评估分类器的性能,对最终选定的神经网络系统做无偏估计(10%)
7.偏差和方差,各参数与偏差方差的关系
训练集误差和交叉验证集误差近似时:偏差/欠拟合
交叉验证集误差远大于训练集误差时:方差/过拟合
• 当 λ \lambda λ 较小时,训练集误差较小(过拟合)而交叉验证集误差较大
• 随着 λ \lambda λ 的增加,训练集误差不断增加(欠拟合),而交叉验证集误差则是先减小后增加
-
获得更多的训练样本——解决高方差
-
尝试减少特征的数量——解决高方差
-
尝试获得更多的特征——解决高偏差
-
尝试增加多项式特征——解决高偏差
-
尝试减少正则化程度λ——解决高偏差
-
尝试增加正则化程度λ——解决高方差
使用较小的神经网络,类似于参数较少的情况,容易导致高偏差和欠拟合,但计算代价较小;使用较大的神经网络,类似于参数较多的情况,容易导致高方差和过拟合,虽然计算代价比较大,但是可以通过正则化来调整而更加适应数据。
通常选择较大的神经网络并采用正则化处理会比采用较小的神经网络效果要好。
8.查准率与查全率及其之间的权衡
查准率=TP/(TP+FP)。例,在所有预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
查全率=TP/(TP+FN)。例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。
权衡查准率和查全率之间的方法:计算F1 值(F1 Score),公式为:
F 1 S c o r e : 2 P R P + R {{F}_{1}}Score:2\frac{PR}{P+R} F1Score:2P+RPR
选择使得F1值最高的阀值。
9.SVM
左边的函数称之为 cos t 1 ( z ) {\cos}t_1{(z)} cost1(z),右边函数称为 cos t 0 ( z ) {\cos}t_0{(z)} cost0(z)。这里的下标是指在代价函数中,对应的 y = 1 y=1 y=1 和 y = 0 y=0 y=0 的情况。
min θ C ∑ i = 1 m [ y ( i ) cos t 1 ( θ T x ( i ) ) + ( 1 − y ( i ) ) cos t 0 ( θ T x ( i ) ) ] + 1 2 ∑ i = 1 n θ j 2 \min_{\theta}C\sum_{i=1}^{m}\left[y^{(i)}{\cos}t_{1}\left(\theta^{T}x^{(i)}\right)+\left(1-y^{(i)}\right){\cos}t_0\left(\theta^{T}x^{(i)}\right)\right]+\frac{1}{2}\sum_{i=1}^{n}\theta^{2}_{j} minθC∑i=1m[y(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i))]+21∑i=1nθj2
用一系列的新的特征 f f f来替换模型中的每一项
高斯核函数:
f 1 = s i m i l a r i t y ( x , l ( 1 ) ) = e ( − ∥ x − l ( 1 ) ∥ 2 2 σ 2 ) {{f}_{1}}=similarity(x,{{l}^{(1)}})=e(-\frac{{{\left\| x-{{l}^{(1)}} \right\|}^{2}}}{2{{\sigma }^{2}}}) f1=similarity(x,l(1))=e(−2σ2∥x−l(1)∥2)
C = 1 / λ C=1/\lambda C=1/λ
C C C 较大时,相当于 λ \lambda λ较小,可能会导致过拟合,高方差;
C C C 较小时,相当于 λ \lambda λ较大,可能会导致低拟合,高偏差;
σ \sigma σ较大时,可能会导致低方差,高偏差;
σ \sigma σ较小时,可能会导致低偏差,高方差。
10.Kmeans及其K如何选择
- 首先选择 K K K个随机的点,称为聚类中心(cluster centroids);
- 对于数据集中的每一个数据,按照距离 K K K个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类。
- 计算每一个组的平均值,将该组所关联的中心点移动到平均值的位置。
- 重复上述步骤直至中心点不再变化。
通常是需要根据不同的问题,人工进行选择的。有一个选择聚类数目的方法是肘部法则。肘部法则需要做的是改变 K K K值,也就是聚类类别数目的总数。用一个聚类来运行K均值聚类方法。这意味着所有的数据都会分到一个聚类里,然后计算成本函数或者计算畸变函数 J J J。
11.PCA、SVD
PCA和SVD区别和联系
主成分分析(PCA)是最常见的降维算法。在PCA中,要找到一个方向向量(Vector direction),当把所有的数据都投射到该向量上时,希望投射平均均方误差能尽可能地小。方向向量是一个经过原点的向量,而投射误差是从特征向量向该方向向量作垂线的长度。
下面给出主成分分析问题的描述:
问题是要将 n n n维数据降至 k k k维,目标是找到向量 u ( 1 ) u^{(1)} u(1), u ( 2 ) u^{(2)} u(2),…, u ( k ) u^{(k)} u(k)使得总的投射误差最小。
PCA 减少 n n n维到 k k k维步骤:
- 均值归一化。需要计算出所有特征的均值,然后令 x j = x j − μ j x_j= x_j-μ_j xj=xj−μj。如果特征是在不同的数量级上,还需要将其除以标准差 σ 2 σ^2 σ2。
- 计算协方差矩阵(covariance matrix) Σ Σ Σ:
∑ = 1 m ∑ i = 1 n ( x ( i ) ) ( x ( i ) ) T \sum=\dfrac {1}{m}\sum^{n}_{i=1}\left( x^{(i)}\right) \left( x^{(i)}\right) ^{T} ∑=m1∑i=1n(x(i))(x(i))T - 计算协方差矩阵 Σ Σ Σ的特征向量(eigenvectors):
可以利用奇异值分解(singular value decomposition)来求解,[U, S, V]= svd(sigma)。
对于一个 n × n n×n n×n维度的矩阵,上式中的 U U U是一个具有与数据之间最小投射误差的方向向量构成的矩阵。如果希望将数据从 n n n维降至 k k k维,只需要从 U U U中选取前 k k k个向量,获得一个 n × k n×k n×k维度的矩阵,用 U r e d u c e U_{reduce} Ureduce表示,然后通过如下计算获得要求的新特征向量 z ( i ) z^{(i)} z(i):
z ( i ) = U r e d u c e T ∗ x ( i ) z^{(i)}=U^{T}_{reduce}*x^{(i)} z(i)=UreduceT∗x(i)
其中 x x x是 n × 1 n×1 n×1维的,因此结果为 k × 1 k×1 k×1维度。
选择 k k k,当在Octave中调用“svd”函数的时候,获得三个参数:[U, S, V] = svd(sigma)。
其中 S S S是一个 n × n n×n n×n的矩阵,只有对角线上有值,而其它单元都是0,可以使用这个矩阵来计算平均均方误差与训练集方差的比例:
1 m ∑ i = 1 m ∥ x ( i ) − x a p p r o x ( i ) ∥ 2 1 m ∑ i = 1 m ∥ x ( i ) ∥ 2 = 1 − Σ i = 1 k S i i Σ i = 1 m S i i ≤ 1 % \dfrac {\dfrac {1}{m}\sum^{m}_{i=1}\left\| x^{\left( i\right) }-x^{\left( i\right) }_{approx}\right\| ^{2}}{\dfrac {1}{m}\sum^{m}_{i=1}\left\| x^{(i)}\right\| ^{2}}=1-\dfrac {\Sigma^{k}_{i=1}S_{ii}}{\Sigma^{m}_{i=1}S_{ii}}\leq 1\% m1∑i=1m∥∥x(i)∥∥2m1∑i=1m∥∥∥x(i)−xapprox(i)∥∥∥2=1−Σi=1mSiiΣi=1kSii≤1%
也就是: Σ i = 1 k s i i Σ i = 1 n s i i ≥ 0.99 \frac {\Sigma^{k}_{i=1}s_{ii}}{\Sigma^{n}_{i=1}s_{ii}}\geq0.99 Σi=1nsiiΣi=1ksii≥0.99
12.异常检测算法
p ( x ) = ∏ j = 1 n p ( x j ; μ j , σ j 2 ) = ∏ j = 1 1 1 2 π σ j e x p ( − ( x j − μ j ) 2 2 σ j 2 ) p(x)=\prod\limits_{j=1}^np(x_j;\mu_j,\sigma_j^2)=\prod\limits_{j=1}^1\frac{1}{\sqrt{2\pi}\sigma_j}exp(-\frac{(x_j-\mu_j)^2}{2\sigma_j^2}) p(x)=j=1∏np(xj;μj,σj2)=j=1∏12πσj1exp(−2σj2(xj−μj)2)
当 p ( x ) < ε p(x) < \varepsilon p(x)<ε时,为异常。
13.推荐系统
3.数据结构与算法
这部分主要靠LeetCode上刷的题
数据结构
1.散列表冲突的解决方式
2.二叉树的前中后序遍历递归法和迭代法
排序算法
比较排序:冒泡排序、快速排序、插入排序、希尔排序、归并排序、堆排序
非比较排序:
经典算法
1.动态规划
2.DFS、BFS、递归、回溯
并查集、KMP、双指针(滑动窗口)、分治、贪心
4.计算机基础知识
Linux操作系统
数据库
Mysql
增删改查
Redis
5.编程语言
Python
版本新特性
赋值、浅拷贝、深拷贝
装饰器
生成器
广播
Java
6.数学与思维
这部分看命,要是考到感觉完犊子了。
7.项目经验
编程框架
TensorFlow
论文
传统算法
新兴算法
8.HR面
先过了技术面再说吧