python 算法基础
目录
- 基础算法
-
- 一元回归算法
-
-
- 多项式回归
-
- 预测
- 任意函数回归
-
- 分类算法
-
-
- kNN k最邻近算法
-
- 聚类算法
-
-
- k-means
- DBSCAN
-
- 推荐算法(暂时不写)
- 降维算法
-
-
- 数据预处理
- 主成分分析 PCA
- 因子分析 FactorAnalysis
-
- sklearn.decomposition.FactorAnalysis
- 检验是否适合因子分析
- factor_analyzer.FactorAnalyzer
-
- 时间序列预测算法
-
-
- ADF检验
- AIC 定阶
- ARIMA 自回归滑动平均模型
-
基础算法
需要先掌握 numpy 库、pandas 库、matplotlib 库的基础知识。部分内容需要使用到 scipy 库和 sklearn 库。
一元回归算法
当需要对一组离散的数据(y, t) ,预测两个变量间的线性或非线性关系时,可以使用回归算法预测 y、t 之间的关系。
多项式回归
np.polyfit(x, y, deg) 函数可以对形如 y ( t ) = t n + t n − 1 + . . . + t + c y(t) = t^n + t ^{n-1}+...+t+c y(t)=tn+tn−1+...+t+c 的多项式关系进行最小二乘回归分析。x、y为需要拟合的横纵坐标,deg 代表拟合多项式的最高维度。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
t = np.arange(1,21,1)
y = t*t*(1+0.1*np.random.randn(20))
model = np.polyfit(t,y,deg=2)
tt = np.arange(1,22,0.05)
yy = model[0]*tt*tt+model[1]*tt+model[2]
print(model)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(t,y)
ax.plot(tt,yy)
plt.show()
结果为:
[ 0.76591722 4.56328739 -14.08452626]
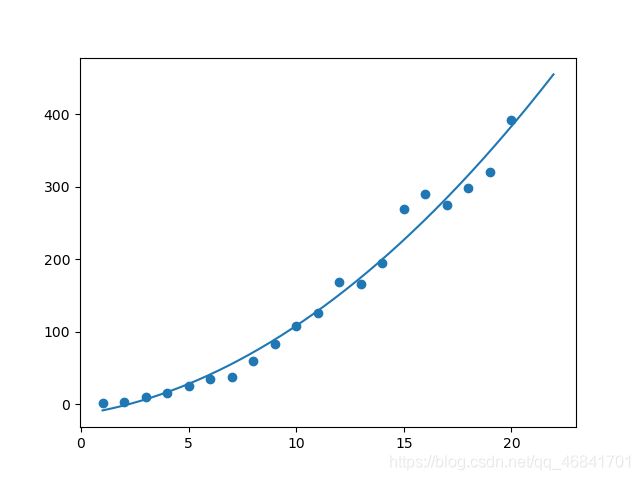
返回值是一个数组,包含从最高次到常数项的系数。
预测
实际使用过程中,可以不需要自己手动输入拟合后的多项式。
np.polyval(p,x) 传入两个参数,p 为多项式从最高次到常数项参数值的列表,x 因变量的值或数组。返回结果值或数组。
>>> np.polyval(model,[5,10])
array([ 27.87984111, 108.14006926])
任意函数回归
当需要拟合指数函数、三角函数或其他复杂函数时,需要导入 scipy.optimize 库的 curve_fit 函数进行回归拟合。
curve_fit(f, xdata, ydata, p0=None, sigma=None, absolute_sigma=False, check_finite=True, bounds=(-inf, inf), method=None, jac=None, **kwargs)
- 对自定义函数的要求
def fun(x,a,b,...):
'''
传入的参数,第一个为自变量,后面均为需要拟合参数变量。
'''
pass
- curve_fit() 函数部分参数含义
| 参数 | 含义 |
|---|---|
| f | 传入一个函数对象,代表要拟合的函数 |
| xdata | 传入一个数组,代表要拟合函数的自变量数组 |
| ydata | 传入一个数组,代表要拟合函数的因变量数组 |
| p0 | 传入一个数组,代表各参数的初始值 |
| bounds | 传入二维元组,包含代表每个参数上下界的列表或数值 |
| method | 拟合优化的方法,有’lm’, ‘trf’, ‘dogbox’三种,默认’lm’ |
- 返回值为 (popt,pcov)格式的二维元组,其中 popt 是一维数组,pcov 是二维数组
popt 为参数估计值
pcov 为参数协方差矩阵估计值
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
def fun(x,a,b,c):
return a*x*x+b*x+c
t = np.arange(1,21,1)
y = t*t*(1+0.1*np.random.randn(20))
model = curve_fit(fun,t,y)
tt = np.arange(1,22,0.05)
yy = model[0][0]*tt*tt+model[0][1]*tt+model[0][2]
print(model)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(t,y)
ax.plot(tt,yy)
plt.show()
结果为:
(array([ 0.9790701 , 0.55588744, -1.73852326]), array([[ 1.86627193e-02, -3.91917018e-01, 1.43702902e+00],
[-3.91917018e-01, 8.72295050e+00, -3.53509004e+01],
[ 1.43702902e+00, -3.53509004e+01, 1.81352985e+02]]))

分类算法
我们已经有一些样本数据,并且知道这些样本分别属于哪一类(即知道样本的标签值)。现在有一些新的不知道标签的样本,我们需要用分类算法对其进行分类。
kNN k最邻近算法
参考:
Python_机器学习_算法篇(K-近邻算法) by 魔法 • 革
原理是,找距离待分类样本最近的 k 个已知分类的样本,根据这些样本的标签进行投票,决定新样本属于哪一类。
使用该方法前,需要先将样本数据分为训练集和测试集,且应将样本特征数据和样本标签数据分开。即分为 X_train, Y_train, X_test, Y_test 四个部分,并将最后测试集的预测分类结果保存至 Y_predict,和 Y_test 中的数据进行比较,得到分类模型的准确率。
可以使用 sklearn 库下 neighbors 模块的 KNeighborsClassifier 类,传入一些模型设定参数后得到 kNN分类模型对象。
KNeighborsClassifier(n_neighbors=5, weights=‘uniform’, algorithm=‘auto’, leaf_size=30, p=2, metric=‘minkowski’, metric_params=None, n_jobs=None, **kwargs)
几个重要参数:
| 参数 | 含义 |
|---|---|
| n_neighbors | k值 |
| algorithm | 搜索最邻近点用的算法,{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’} |
| p | 当 metric 参数为默认值 ‘minkowski’ 闵可夫斯基距离时,用此参数决定该距离计算的参数,默认为 2,即欧式距离 |
| metric | 决定距离计算方法,from sklearn.neighbors import DistanceMetric ,打印 DistanceMetric 类的 doc 文档,查看可传入的参数和这些距离的定义 |
| n_jobs | 并行处理设置。默认为1,临近点搜索并行工作数。如果为-1,那么CPU的所有cores都用于并行工作 |
model = KNeighborsClassifier()
使用数据集前,一般要对数据进行标准化处理,可以利用 sklearn 库 preprocessing 模块的 StandardScaler 类生成标准化处理对象。
此外,还可以利用 sklearn 库 model_selection 模块的 train_test_split 函数将数据集随机划分为训练集和测试集。
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
x_train, x_test, y_train, y_test = train_test_split(data, target,
test_size=0.2, random_state=22)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
之后使用这个对象的 .fit() 方法,输入训练集的数据和标签,训练模型。再使用 .predict() 方法,输入测试集的数据,返回预测的结果。也可以使用 .score() 方法,输入测试集的数据和标签,返回测试的准确率。
model.fit(X_train,Y_train)
Y_predict = model.predict(X_test)
score = model.score(X_test,Y_test)
聚类算法
有一堆样本,需要被分为几个类,此时需要用聚类算法来将其归类。
注意,聚类算法与分类算法不同之处在于,事先不知道任何样本的标签,而是由机器提取样本的特征后将其分为一些类别,之后如若需要,再由人去给这些类别分配标签。因此,聚类算法一般不用作预测。
聚类后的各类别,在 .labels_ 属性里会用 0、1、2……的标签区分,预测后的返回值会用 1、2、3……的标签区分。如果算法舍弃部分点,则分类标签为 -1 代表离散点。
如果要画聚类后的分类图,建议用 .labels_ 属性直接得到预测值,否则需要将 .predict() 返回值 -1。
k-means
参考:
Python_机器学习_算法篇(聚类算法) by 魔法 • 革
k均值聚类的原理如下:
- 随机设置K个特征空间内的点作为初始的聚类中心
- 对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
- 接着对着标记的聚类中心之后,重新计算出每个簇的新中心点(平均值)
- 如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程
使用 k均值聚类算法前,先从 sklearn 库的 cluster 模块导入 KMeans 类。
from sklearn.cluster import KMeans
KMeans(n_clusters=8, init=‘k-means++’, n_init=10, max_iter=300, tol=0.0001, precompute_distances=‘auto’, verbose=0, random_state=None, copy_x=True, n_jobs=None, algorithm=‘auto’)
主要参数:
| 参数 | 含义 |
|---|---|
| n_clusters | 分类簇数,即聚集点数 |
| init | 初始聚集点选取方法,默认即可,也可传入数组 |
| precompute_distances | 是否预先计算距离,可使计算速度更快但需要更多内存,默认n_samples * n_clusters>100M时不计算 |
| n_jobs | 并行处理设置。默认为1,临近点搜索并行工作数。如果为-1,那么CPU的所有cores都用于并行工作 |
将 KMeans() 函数返回值赋值给 model,生成 KMeans 聚类模型对象。
model = KMeans()
该对象有如下常用方法:
| 方法 | 作用 |
|---|---|
| .fit(X) | 训练模型,输入训练集X |
| .predict(X) | 在模型被训练好的基础上,输入数据并预测其分类,为确保其意义,一般输入训练时使用的数据 |
| .fit_predict(X) | 相当于对一个训练集先调用 .fit() 再调用 .predict() |
| .transform(X) | 在模型被训练好的基础上,输入数据,返回其到每一个聚类中心的距离,即将原本的 n_samples 个维度替换为到各个聚类中心距离的 n_clusters 个维度 |
| .fit_transform(X) | 相当于对一个训练集先调用 .fit() 再调用 .transform() |
| .score(X) | 返回 K-均值目标的负数 |
其中 K-均值目标指样本到其最近的聚类中心的距离的平方之和,即J平方误差函数。可以用 model.inertia_ 属性查看。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
from sklearn.cluster import KMeans
X = pd.DataFrame([[1,2],[1,3],[2,1],[4,6],[5,5]])
model = KMeans(2)
model.fit(X)
X_n = model.transform(X)
Y = model.predict(X)
print(model.score(X))
print(model.inertia_)
print(X_n)
print(Y)
结果为
-3.6666666666666687
3.666666666666667
[[4.94974747 0.33333333]
[4.30116263 1.05409255]
[5.14781507 1.20185043]
[0.70710678 4.8074017 ]
[0.70710678 4.7375568 ]]
[1 1 1 0 0]
DBSCAN
k-means 由于其聚类的原理,导致其只能对呈现球形聚集的数据进行聚类,而无法对于环状、条状数据进行聚类。
其原理为:
- 在样本中随机选择一个未被分类的点,作为一个新簇的第一个点。
- 以这个点为半径,取距离在这个范围内且离当前点距离最近的几个点加入当前簇。
- 对新加入的点重复 2 的步骤。
- 直到没有新点加入时,重复 1~3 的步骤。若当前簇点数少于设定最小簇长度,代表这些点为离散点,不作分类。
- 所有点都被分类或只剩下离散点时,聚类结束。
使用 DBSCAN 聚类算法前,先从 sklearn 库的 cluster 模块导入 DBSCAN 类。
from sklearn.cluster import DBSCAN
DBSCAN(eps=0.5, min_samples=5, metric=‘euclidean’, metric_params=None, algorithm=‘auto’, leaf_size=30, p=None, n_jobs=None)
主要参数:
| 参数 | 含义 |
|---|---|
| eps | 求临近点的距离最大值,即半径 |
| min_samples | 簇的最小长度,形成聚类的最小样本数 |
| metric | 距离参数,同 kNN 算法中 |
| algorithm | 搜索最邻近点用的算法,同 kNN 算法中 |
| p | 当 metric 参数为默认值 ‘minkowski’ 闵可夫斯基距离时,用此参数决定该距离计算的参数,同 kNN 算法中 |
| n_jobs | 并行处理设置。默认为1,临近点搜索并行工作数。如果为-1,那么CPU的所有cores都用于并行工作 |
需要注意,DBSCAN 类的方法只有 .fit() 和 .fit_predict() ,用法同 k-means 算法。
推荐算法(暂时不写)
目前有一堆用户和一堆项目,已知每个用户关注的项目,要为所有用户推荐其可能喜欢的项目时,需要用到推荐算法。推荐算法有两种:一种需要根据项目寻找相似用户,即先观察每个用户关注的项目,再算出相似的用户,最后为每个用户推荐其相似用户关注的项目(基于用户的协同过滤);另一种需要根据用户寻找相似项目,即先观察每个项目被关注的用户,再算出相似的项目,最后将每个项目推荐给其相似项目被关注的用户(基于项目的协同过滤)。
(具体以后再记)
降维算法
降维算法可以将高维数据变为低维数据,且保留其原始数据的全部信息。
使用降维算法前,需要对原始数据进行标准化处理。
数据预处理
python 机器学习库有专门的数据处理模块 sklearn.preprocessing,有以下常用类:
| 类 | 含义 |
|---|---|
| StandardScaler | 标准归一化,使平均值为0,方差为1,减去平均值除以标准差 |
| MinMaxScaler | MinMax 归一化,使最小值为0,最大值为1 |
| MaxAbsScaler | MaxAbs 归一化,使最小值为-1,最大值为1 |
| Normalizer | 正则化,缩放到0和1之间,保留原始数据的分布,对每个样本计算其p-范数,然后对该样本中每个元素除以该范数,主要应用于文本分类和聚类 |
| RobustScaler | 鲁棒性归一化,减去中位数除以四分位距,可用于应对数据中包含很多异常值的情况 |
生成对应对象后,调用对象的 .fit_transform() 方法传入数据集,即可返回归一化后的数据。
具体不同归一化方法的效果,修改自(已标出处)代码如下:
作者:thothsun
链接:https://www.zhihu.com/question/20467170/answer/839255695
来源:知乎
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
def plot(data, title,subid):
global fig
sns.set_style('dark')
ax = fig.add_subplot(subid)
ax.set(ylabel='frequency')
ax.set(xlabel='height(blue) / weight(green)')
ax.set(title=title)
sns.distplot(data[:, 0:1], color='blue')
sns.distplot(data[:, 1:2], color='green')
np.random.seed(42)
height = np.random.normal(loc=168, scale=5, size=1000).reshape(-1, 1)
weight = np.random.normal(loc=70, scale=10, size=1000).reshape(-1, 1)
fig = plt.figure(figsize=(12,10))
original_data = np.concatenate((height, weight), axis=1)
plot(original_data, 'Original',231)
standard_scaler_data = preprocessing.StandardScaler().fit_transform(original_data)
plot(standard_scaler_data, 'StandardScaler',232)
min_max_scaler_data = preprocessing.MinMaxScaler().fit_transform(original_data)
plot(min_max_scaler_data, 'MinMaxScaler',233)
max_abs_scaler_data = preprocessing.MaxAbsScaler().fit_transform(original_data)
plot(max_abs_scaler_data, 'MaxAbsScaler',234)
normalizer_data = preprocessing.Normalizer().fit_transform(original_data)
plot(normalizer_data, 'Normalizer',235)
robust_scaler_data = preprocessing.RobustScaler().fit_transform(original_data)
plot(robust_scaler_data, 'RobustScaler',236)
plt.savefig('scalter.png')
plt.show()
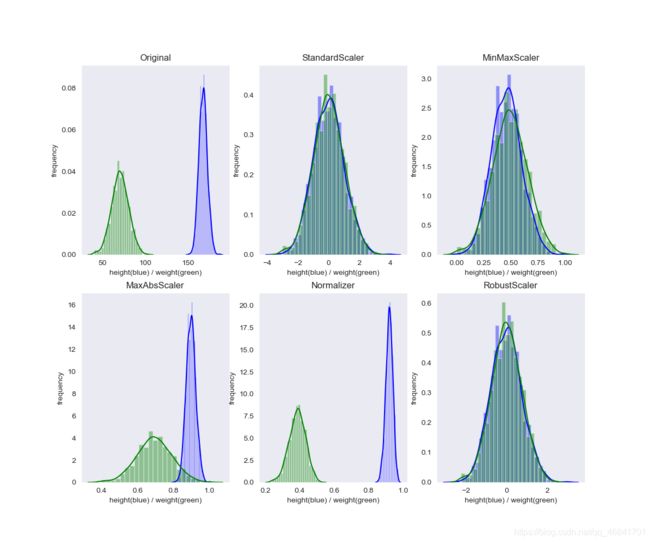
提一下Normalizer 中的 p-范数。
| p | 传入 norm 参数 | 计算方法 |
|---|---|---|
| 0 | 未实现 | 向量中非0个数 |
| 1 | ‘l1’ | 向量各维度绝对值之和 |
| 2 | ‘l2’ 或 default | 向量距离 |
| 正无穷 | ‘max’ | 向量各维度绝对值的最大值 |
主成分分析 PCA
原理见《多元统计分析》,使用 PCA 需要从 sklearn 库的 decomposition 模块导入 PCA 类。
from sklearn.decomposition import PCA
PCA(n_components=None, copy=True, whiten=False, svd_solver=‘auto’, tol=0.0, iterated_power=‘auto’, random_state=None)
常用参数含义为:
| 参数 | 含义 |
|---|---|
| n_components | 输入为正整数时,代表降维后的维度,输入为 ‘mle’ 时,会用MLE算法根据特征的方差分布情况自己去选择一定数量的主成分特征来降维。若不输入默认为样本数和维度中的较小值 |
| whiten | 是否对降维后的数据的每个特征进行归一化,让方差都为1,默认 False,一般不需要传入参数 |
常用方法为:
| 方法 | 作用 |
|---|---|
| .fit() | 输入要进行降维的数据进行训练,返回训练后的模型 |
| .transform() | 输入要进行降维的数据,返回降维后的各样本各维度数值 |
| .fit_transform |
常用属性为:
| 属性 | 含义 |
|---|---|
| n_components_ | 降维后的维度,配合MLE方法使用 |
| explained_variance_ | 降维后各维度方差(贡献度) |
| explained_variance_ratio_ | 降维后各维度方差占比(贡献率) |
| components_ | 降维后各维度和原维度的关系,返回一个二维数组,每一行代表降维后每个维度和原维度的线性关系(降维矩阵) |
| singular_values_ | 降维后各维度对应奇异值 |
| mean_,n_features_,n_samples_ | 原始各特征(维度)平均值,维数,样本数 |
因子分析 FactorAnalysis
由于 sklearn 库 decomposition 模块的 FactorAnalysis 类实现的功能实在是太太太少了,主要以 factor_analyzer 里的 FactorAnalyzer 类为例。
sklearn.decomposition.FactorAnalysis
from sklearn.decomposition import FactorAnalysis
FactorAnalysis(n_components=None, tol=0.01, copy=True, max_iter=1000, noise_variance_init=None, svd_method=‘randomized’, iterated_power=3, random_state=0)
常用参数如下:
| 参数 | 含义 |
|---|---|
| n_components | 因子个数 |
| tol | 迭代停止条件,可以理解为精度 |
| max_iter | 最大迭代次数 |
常用方法如下:
| 方法 | 作用 |
|---|---|
| .fit() | 传入训练集训练 |
| .transform() | 传入训练集,返回因子得分系数矩阵(实际是二维数组) |
| .fit_transform() | |
| .get_covariance() | 得到原各特征值的协方差矩阵 |
| .get_precision() | 得到原各特征值的精度矩阵(协方差矩阵的逆矩阵) |
常用属性如下:
| 属性 | 含义 |
|---|---|
| mean_ | 原始各维度平均值 |
| noise_variance_ | 原始各维度方差 |
| components_ | 降维后各维度和原维度的关系,返回一个二维数组,每一行代表降维后每个维度和原维度的线性关系(降维矩阵) |
没错,这个库既没实现因子旋转,甚至连因子的贡献率都需要自己写函数计算,导致我研究了半天后还是放弃这个库了。
检验是否适合因子分析
参考自:http://www.srcmini.com/24087.html
- Bartlett 球形度检验
Bartlett 球形度检验使用观察到的相关矩阵和恒等矩阵检查观察到的变量是否相互关联。如果测试发现统计上不重要, 则不应使用因子分析。
from factor_analyzer.factor_analyzer import calculate_bartlett_sphericity
chi_square_value, p_value=calculate_bartlett_sphericity(df)
# 若 p_value < 0.05,则说明数据具有统计学意义, 表明所观察到的相关矩阵不是恒等矩阵,可以进行因子分析。
- Kaiser-Meyer-Olkin 检验
Kaiser-Meyer-Olkin(KMO)测试可测量数据是否适合进行因子分析。它确定每个观察变量和完整模型的充分性。 KMO估计所有观察变量之间的方差比例。较低的比例ID更适合因子分析。 KMO值介于0到1之间。KMO值小于0.6被认为是不合适的。
from factor_analyzer.factor_analyzer import calculate_kmo
kmo_all, kmo_model=calculate_kmo(df)
# 若 kmo_model > 0.6,则认为适合做因子分析
factor_analyzer.FactorAnalyzer
from factor_analyzer import FactorAnalyzer
FactorAnalyzer(n_factors=3, rotation=‘promax’, method=‘minres’, use_smc=True, is_corr_matrix=False, bounds=(0.005, 1), impute=‘median’, rotation_kwargs=None)
常用参数如下:
| 参数 | 含义 |
|---|---|
| n_factors | 因子个数 |
| rotation | 因子旋转方法 |
| method | 求因子载荷矩阵的方法 |
rotation 有如下可选参数:
(1) varimax (orthogonal rotation) 方差最大化矩阵,常用
(2) promax (oblique rotation) 默认
(3) oblimin (oblique rotation)
(4) oblimax (orthogonal rotation)
(5) quartimin (oblique rotation)
(6) quartimax (orthogonal rotation)
(7) equamax (orthogonal rotation)
(orthogonal rotation 正交旋转,oblique rotation 斜交旋转)
method 有如下可选参数:
(1) minres 最小残差法
(2) ml 最大似然法
(3) principal 主轴因素法
常用方法如下:
| 方法 | 作用 |
|---|---|
| .fit() | 传入训练集训练 |
| .transform() | 传入训练集,返回因子得分系数矩阵(实际是二维数组) |
| .fit_transform() | |
| .get_factor_variance() | 返回含有三个数组的元组,分别是各因子的方差贡献度、方差贡献率、累积方差贡献率 |
| .get_communalities() | 降维后的因子对原始各个维度的共性方差 |
| .get_uniquenesses() | 降维后的因子对原始各个维度的特殊方差 |
常用属性如下:
| 属性 | 含义 |
|---|---|
| loadings_ | 因子载荷矩阵 |
| corr_ | 原始数据各维度的协方差矩阵 |
| rotation_matrix_ | 因子旋转矩阵 |
| phi_ | 因子协方差矩阵 |
时间序列预测算法
python 中统计模型由 statsmodels 库提供。
这部分内容,感觉目前写的方法并不好,就只放可套用的代码了,以后再补充吧。
ADF检验
对于很多时间序列预测模型,会要求时间序列必须是平稳的,因此每一步都需要做平稳性检验。最常用的平稳性检验是 ADF检验(单位根检验)。
详细参考:https://www.pianshen.com/article/5826219147/
具体使用时,可简单用以下代码:
from statsmodels.tsa.stattools import adfuller
dftest = adfuller(ts) # ts为 series对象
dftest[1]
# 若 dftest[1](即 p-value)小于 0.05,则拒绝序列存在单位根的假设,即可以认为序列平稳
若检验结果为不平稳,往往需要对原始数据作差分(一般不超过二阶差分),再次作检验。对差分后的数据进行预测。
ts_diff=ts.diff(1)
ts_diff.dropna(inplace=True) #由于差分之后第一位是空值,因此需要去掉空值
AIC 定阶
import statsmodels.api as sm
res = sm.tsa.arma_order_select_ic(ts_diff,max_ar = 5,max_ma = 5, ic=['aic'])
p = res.aic_min_order[0]
q = res.aic_min_order[1]
ARIMA 自回归滑动平均模型
from statsmodels.tsa.arima_model import ARIMA
# 第一种:使用原数据,在模型中d参数设置为1阶差分
model1 = ARIMA(ts, order=(p,1,q))
res_arima1 = model1.fit() #
pre1 = res_arima1.predict(start=str('1960-01'),end=str('1960-12'),dynamic=False)
# 第二种:使用差分后的数据
model2 = ARIMA(ts_diff, order=(p,0,q))
res_arima2 = model2.fit()
pre2 = res_arima2.predict(start=str('1960-01'),end=str('1960-12'),dynamic=False)
以第一种方法为例,下面为还原预测数据的代码。
pre1.iloc[0] = pre1.iloc[0] + data.loc['1959-12','#Passengers'][0] #先将第一个数据还原
pre_cumsum1 = pre1.cumsum() #累计求和 比如一个列表是这样[1,2,3,4,5] 返回是这样[1,3,6,10,15]