TiDB的逸闻趣事
周末了,来轻松一下。聊聊TiDB的逸闻趣事。
TiDB 是什么?
TiDB 是一个分布式 NewSQL 数据库。它支持水平弹性扩展、ACID 事务、标准 SQL、MySQL 语法和 MySQL 协议,具有数据强一致的高可用特性,是一个不仅适合 OLTP 场景还适适合OLAP 场景的混合数据库。
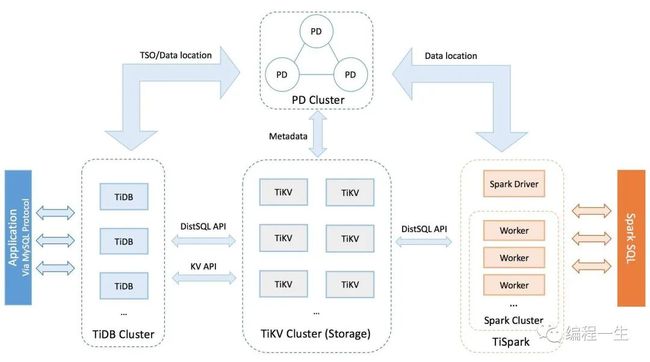
个人使用TiDB时,从开发角度看,确实只需要换个数据源IP,就可以做到从mysql到TiDB的无缝迁移,这点确实很爽。但是它不是mysql,很多功能不支持,比如:存储过程、视图、触发器、自定义函数、外键约束、全文索引、空间索引和非 UTF8 字符集。
TiDB怎么来的?
开源分布式缓存服务 Codis 的作者,PingCAP 联合创始人& CTO ,资深 infrastructure 工程师的黄东旭,擅长分布式存储系统的设计与实现,开源狂热分子的技术大神级别人物。即使在互联网如此繁荣的今天,在数据库这片边界模糊且不确定地带,他还在努力寻找确定性的实践方向。
2012 年底,他看到 Google 发布的两篇论文,得到了很大的触动,这两篇论文描述了 Google 内部使用的一个海量关系型数据库 F1/Spanner ,解决了关系型数据库、弹性扩展以及全球分布的问题,并在生产中大规模使用。“如果这个能实现,对数据存储领域来说将是颠覆性的”,黄东旭为完美方案的出现而兴奋, PingCAP 的 TiDB 在此基础上诞生了。
如何评价TiDB?
TiDB为了避免单点故障没有引入全局事务管理器,像InnoDB一样维护一个活跃事务列表。这样的代价是比较大的,比如一个事务的DML会先存在TiDB节点的内存里,而且在Prewrite/Commit的时候无法像传统MVCC一样避免读写阻塞,TiDB在GA 3.0之后的悲观锁并没有解决这个问题。而且为了兼容MySQL也像是掉入了一个大坑(虽然这也是成功的因素之一),要知道很多分布式数据库都没有选择兼容MySQL。首先MySQL有很多屎山设计,而且因为底层实现的巨大差异,你始终无法做到100%完全兼容,只能是99%。
但是三个人辞职创业从零写一个分布式DB,这个故事本身的传奇性就值得敬畏,尤其是技术喷子很多的中国。团队也很有执行力,定下了Rust写KV层的方案就坚定不渝。要知道那可是16年,20年用Rust写链表都还写不利索。当然还有从0写一个SQL层,而且能完全解析MySQL语法。这项工作量是巨大的,也是兼容MySQL的分布式数据库必要的,因为分布式环境下,很多查询优化有了新变化,原来的计划不适用了。为啥新型分布式数据库支持MySQL的少?我猜很大原因就有查询处理背后巨大的工作量。
当然它最大的贡献不是它的架构,而是让中国人看到了开源商业化的可能性,还有怎么成功运营一个开源社区。你永远不知道,它养活了多少技术公司内部的分布式数据库组,无论是自研的,还是拿过来直接做方案的。(包括鼓舞了多少对数据库感兴趣的学生,研究的氛围等等)
说回前景,肯定是大大的有。infra底层类开源是大势所趋,除了star数,团队的布局也很厉害,无论是湾区设office,发VLDB提高reputation,用Rust写存储层做网红,D轮融资不断推进,同时做TP/AP甚至融合成一个HTAP(虽然说Hybrid现在更多是一个学术上的噱头,但是解决方案确实很新,学术上我认为是超过了Google那篇的),开源周边工具(其实这些轮子大公司都在造,但是PingCAP有开源的优势,比较新的比如TiCDC和Chaos Mesh),注重社区技术布道提升话语权和影响力,都让这个公司变得像一个综合性数据库公司,这点和Snowflake等等把一个产品雕得更精细是不一样的。和其他人聊天,有人喜欢这种包罗万象,有人不喜欢。但我是觉得利大于弊,对比其他做infra开源的,你会发现PingCAP真的做得很好。甚至TiDB开始做分布式Cache或者Stream Service或者networking library我都不奇怪。中美脱钩的大环境下,保证自主知识产权的基础软件非常难得。
TiDB的一些坑
问题1:TiDB线上报 “pd server timeout”
处理:业务侧在代码中加上相关超时重试的处理,将 TiDB 机器上 min_free_kbytes 从默认的 66M 调成 512M,留更多内存给内核用。
问题2:TIDB 生产环境发生 OOM问题。
处理方案1:将OLAP频繁的SQL业务放到一个单独的TiDB集群,与现有的一套TiDB集群进行隔离,防止一个业务的OLAP SQL 影响到其他的业务;
处理方案2:oom-action 配置为 cancel,kill 使用内存超过阈值的 SQL,单条SQL使用的内存阈值调整配置文件;
问题3:TiDB线上内存使用过大
处理:抓取内存 profile 分析,怀疑是 TiDB 2.1.8 版本一个 goroutine 泄漏的 bug 引起,后面通过升级TiDB版本到2.1.11 版本。
问题4:TiKV 热点问题,region 分布不均匀
处理:某一个周末发现有3台TiKV的CPU使用率均达到100%,最终定位到原因为PD各个调度器抢占的问题,升级TiDB版本到2.1.11 版本。
问题5:重启TiKV调整参数,业务侧出现”tikv timeout“的异常
处理:由于强制关闭了tikv集群,造成region 的自动选主,”tikv timeout“属于正常现象。
问题6:Pd Server Timeout
处理:etcd bug引起。TiDB已经向etcd开发提出issue,等待回复及改进。issue地址:https://github.com/etcd-io/etcd/issues/10713
问题7:tidb 实例频繁重启
处理:txn-latch-local 是一个关于事务内存锁,缓解事务冲突的功能,这个功能在 tidb 产品后续优化了事务的并发且引入了悲观锁机制之后,已经不再维护了。需要关闭 txn-local-latch ,即设置 txn-local-latch = false
问题8:tidb实例网卡流量巨大20Gbps 持续将网卡打满
处理:改写sql 逻辑,调整每次拉取的记录大小;
问题9:tidb 某些 sql 会出现索引失效
处理:对于发现失效的SQL,使用HINT这种方式强制指定索引解决。
问题10:tidb用户权限问题只有增删改查权限却可以truncate表
处理:truncate权限未做好隔离,问题在2.1.7版本中进行了修复
参考:
https://www.pianshen.com/article/97571966089/
https://www.zhihu.com/question/58767602
总结
TiDB和其他比较新的数据库一样,靠着TPC-H benchmark 测试打榜赚了一些噱头。这些陈旧的技术指标并不符合每个公司的具体情况。换技术栈需谨慎。