darknet框架GPU编译安装
Darknet: Open Source Neural Networks in C
1、darknet下载
git clone https://github.com/pjreddie/darknet.git
cd darknet
设置makefile
gpu=1
cudnn=1
opencv=1
【1】GPU=1;需要设置显卡驱动、cuda
- 使用
nvidia-smi查看显卡型号和支持的cuda版本号
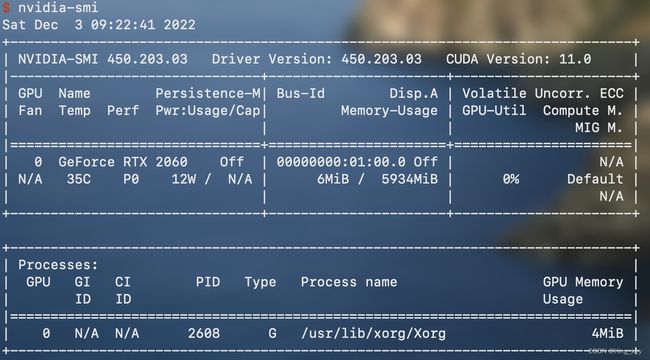
- nvidia官网下载cuda,以及cudnn

安装cuda若提示
Existing package manager installation of the driver found. It is strongly recommended that you remove this before continuing
原因是驱动重复安装,卸载掉其他驱动
dpkg -l | grep Nvidia //查看驱动
sudo apt-get purge "nvidia*" //卸载旧版本驱动
然后再次安装就正常了。成功之后显示
===========
= Summary =
===========
Driver: Not Selected
Toolkit: Installed in /usr/local/cuda-11.6/
Please make sure that
- PATH includes /usr/local/cuda-11.6/bin
- LD_LIBRARY_PATH includes /usr/local/cuda-11.6/lib64, or, add /usr/local/cuda-11.6/lib64 to /etc/ld.so.conf and run ldconfig as root
To uninstall the CUDA Toolkit, run cuda-uninstaller in /usr/local/cuda-11.6/bin
***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 510.00 is required for CUDA 11.6 functionality to work.
To install the driver using this installer, run the following command, replacing <CudaInstaller> with the name of this run file:
sudo <CudaInstaller>.run --silent --driver
Logfile is /var/log/cuda-installer.log
添加cuda到系统路径,vim ~/.zshrv
export PATH=/usr/local/cuda-11.6/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-11.6/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
运行source ~/.zshrc 让路径生效,此时可以输入命令nvcc -V验证一下cuda
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Thu_Feb_10_18:23:41_PST_2022
Cuda compilation tools, release 11.6, V11.6.112
Build cuda_11.6.r11.6/compiler.30978841_0
【2】cudnn=1
- nvidia官网选择相应版本的cudnn,进行下载(建议下载可解压版本的,方便自己操作)
将解压出来的cudnn文件copy到cuda路径中(usl/local中会有两个cuda路径,一个带版本号,一个不带,记得是copy到不带版本号的cuda路径中)
sudo cp include/cudnn*.h /usr/local/cuda/include
sudo cp lib/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
copy完成之后用cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2 验证一下
#define CUDNN_MAJOR 8
#define CUDNN_MINOR 7
#define CUDNN_PATCHLEVEL 0
--
#define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)
2、darknet编译
由于版本问题,需要先修改几个文件
- 用
https://github.com/arnoldfychen/darknet/blob/master/src/convolutional_layer.c直接替换darknet/src/convolutional_laye.c文件,老版本不支持cudnn8以上的
#include "convolutional_layer.h"
#include "utils.h"
#include "batchnorm_layer.h"
#include "im2col.h"
#include "col2im.h"
#include "blas.h"
#include "gemm.h"
#include - 修改
/src/gemm.c中的cudaThreadSynchronize为cudaDeviceSynchronize - Makefile中添加,并删除掉低版本的信息
-gencode arch=compute_70,code=[sm_70,compute_70] \
-gencode arch=compute_75,code=[sm_75,compute_75] \
-gencode arch=compute_86,code=[sm_86,compute_86]
最后,用make命令编译
3、编译出错
/bin/sh: 1: nvcc: not found
sudo
修改Makefile中nvcc 的路径
NVCC=/usr/local/cuda/bin/nvcc