实战 | 教你快速爬取热门股票,辅助量化交易!

大家好,我是安果!
之前有写过 2 篇关于价值投资方面的文章
教你用 Python 快速获取相关概念股,辅助价值投资!
教你用 Python 快速获取行业板块股,辅助价值投资!
量化交易有一个非常重要的指标 AR,它是通过固定公式计算出的,用于反映市场买卖人气的技术指标
一般用在多支股票的对比,通过 AR 技术指标能获取相应股票的热门指数,辅助我们进行选择
本篇文章将结合滚动市盈率 PE 爬取热门股票,筛选出适合投资的股票
1. 实战
目标对象:
aHR0cHMlM0EvL2d1YmEuZWFzdG1vbmV5LmNvbS9yYW5rLw==
具体操作步骤如下
1-1 安装依赖
# 安装依赖
pip3 install selenium
pip3 install pandas1-2 ChromeDriver 及打开首页
根据 Chrome 浏览器的版本号下载对应版本的驱动,并放置到本地
http://chromedriver.storage.googleapis.com/index.html
然后使用 Selenium 打开目标网页
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
chrome_options = Options()
# 无头模式运行
chrome_options.add_argument('--headless')
s = Service(r"C:\work\chromedriver.exe")
browser = webdriver.Chrome(service=s, options=chrome_options)
browser.implicitly_wait(5)
@calc_run_time
def start():
url = '主页地址'
browser.get(url)
browser.maximize_window(1-3 爬取热门股票列表数据
首先,利用显式等待直到设定的页面元素完全加载出来
然后,对页面元素进行分析,利用 Xpath 爬取热门股票的名称、价格、涨幅、URL、排名
最后,循环爬取每一页的数据保存到一个列表中
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
def get_rank_list():
"""
获取热门股票列表数据
:return:
"""
datas = []
# 股票热度排名
rank_no = 0
# 抓取所有数据
while True:
# 等待加载完成(显示等待)
WebDriverWait(browser, 120, 0.5).until(
EC.presence_of_element_located((By.XPATH, '//*[@class="stock_tbody"]/tr'))
)
# 处理数据
tr_elements = browser.find_elements(By.XPATH, '//*[@class="stock_tbody"]/tr')
for tr_element in tr_elements:
name = tr_element.find_element(By.XPATH, './/div[@class="nametd_box"]/a').text
price = tr_element.find_element(By.XPATH, './/td[7]/div').text
up_rate = tr_element.find_element(By.XPATH, './/td[9]/div').text # 涨跌幅度
stock_home_url = tr_element.find_element(By.XPATH, './/td[4]//a').get_attribute("href")
rank_no = rank_no + 1
datas.append({
"name": name,
"price": price,
"up_rate": up_rate,
"stock_home_url": stock_home_url,
"rank_no": rank_no,
"pe": 0.0
})
# 点击下一页
try:
page_next = browser.find_element(By.XPATH, '//a[contains(text(), "下一页")]')
except:
page_next = None
# 如果是最后一页,就中断
if page_next:
page_next.click()
else:
break1-4 获取个股 PE
根据上面获取的个股 URL 爬取滚动市盈率
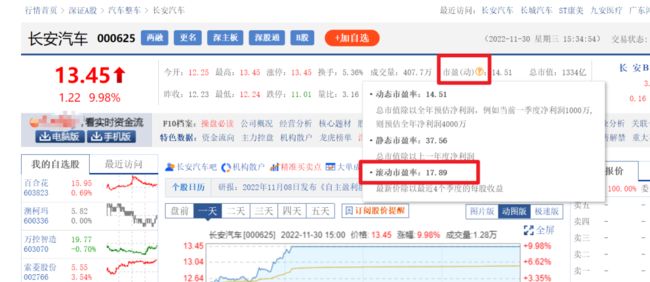
需要注意的是,滚动市盈率是鼠标 Hover 在上面 icon 处才会显示,所以我们需要模拟鼠标移动到上面图标的位置
from selenium.webdriver.common.action_chains import ActionChains
def get_stock_pe(stock_home_url):
"""
获取股票的动态PE
:param stock_home_url:
:return:
"""
browser.get(stock_home_url)
browser.maximize_window()
# 等待加载完成
WebDriverWait(browser, 120, 0.5).until(
EC.presence_of_element_located((By.XPATH, '//div[@class="ssy"]//li[5]/span'))
)
# PE ICON
pe_element = browser.find_element(By.XPATH, '//td[@class="n"]/span[@class="title_help"]')
# 动态PE
pe_dynamic = browser.find_element(By.XPATH, '//div[@class="brief_info_c"]//tr[1]/td[12]/span/span').text
# return float(pe)
# 移动鼠标位置到PE ICON处,展示滚动PE
ActionChains(browser).move_to_element(pe_element).perform()
# 获取滚动市盈率
pe_roll = browser.find_element(By.XPATH, '//span[@class="title_help"]//div[@class="ssy"]//li[5]/span').text
# 异常处理
try:
pe_roll = float(pe_roll)
except:
pe_roll = 0.0
return pe_roll
...
# 获取股票的滚动PE,设置进去
for item in datas:
item['pe'] = get_stock_pe(item.get("stock_home_url"))
# 随机休眠
random_sleep()
...另外,为了应对反爬,这里使用 random 模块内置函数模拟随机的休眠等待
import random
import time
def random_sleep(mu=1, sigma=0.4):
"""随机睡眠
:param mu: 平均值
:param sigma: 标准差,决定波动范围
"""
secs = random.normalvariate(mu, sigma)
if secs <= 0:
secs = mu # 太小则重置为平均值
print("休眠时间:", secs)
time.sleep(secs)1-5 数据清洗
然后利用 Pandas 对数据键值对进行重命名,并通过 PE 值对数据进行一次过滤
PS:这里过滤出滚动市盈率大于 0 且小于 30 的股票
import pandas as pd
# 重命名
code = {"name": "名称", "price": "价格", "up_rate": "涨跌幅", "stock_home_url": "URL", "rank_no": "排名",
"pe": "动态PE"}
result = pd.DataFrame(datas).rename(columns=code)
# 数据转换
# 将Series列字符串转为Float数据类型
# result["动态PE"] = result["动态PE"].astype(float)
# 过滤出PE为正,且数据小于30的数据
result = result[(0 < result["动态PE"]) & (result["动态PE"] <= 30)]1-6 排序、保存
接着,按 PE 列进行升序排列,最后保存到 CSV 文件
import pandas as pd
...
# 按PE升序排列,并重新标记索引
result = result.sort_values(by="动态PE", ascending=True, ignore_index=True)
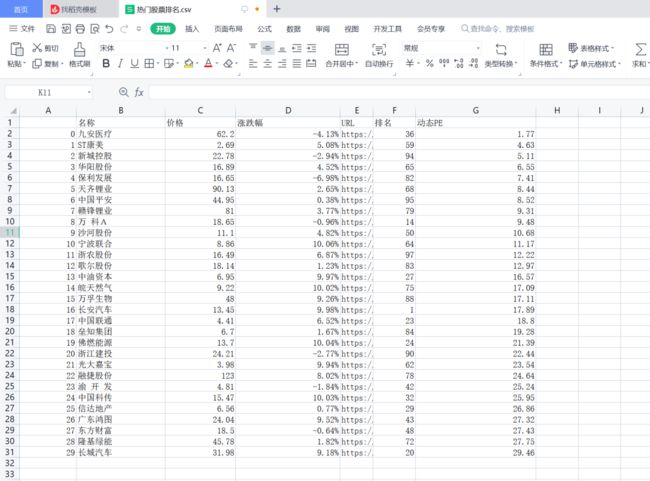
result.to_csv("热门股票排名.csv")
...最后打开 CSV 文件,发现股票名称、排名、PE、价格等关键数据写入到文件中了,这些数据可以辅助我们进行量化投资
当然,我们可以将爬虫部署到服务器,并将数据写入到数据库,方便我们后期进行数据分析及可视化
如果你对量化交易有自己的想法,欢迎在评论区交流!
推荐阅读
教你用 Python 快速获取相关概念股,辅助价值投资!
教你用 Python 快速获取行业板块股,辅助价值投资!
实战 | 如何利用 Scrapy 编写一个完整的爬虫!
END
好文和朋友一起看~