对于神经网络的边缘计算以及嵌入式等应用
引言
对于神经网络的边缘计算以及嵌入式等应用,目前市场的前景广阔;各个头部企业对于物联网的布局和国家工业2.0时代的到来,为神经网络在实地场景中的应用带来了更为可观的经济价值。而对于现有的神经网络进行压缩,从而实现在小型低功耗设备上边缘计算的应用,意义也变得更为深远。本文针对现有的常见神经网络压缩进行简单的概括和阐述,并在笔者的理解上对于未来神经网络的发展方向给出自己的看法。
1.各种压缩方法概述
1.1权重裁剪
对于压缩模型而言,部分研究认为很多卷积核对于最终输出的贡献是较少的,通过一些简单的判断(例如范数的排序)之后,去除对于模型影响较小的部分,从而实现对于模型体积和运算速度的提升。
这里简单介绍几种具体思路:
- 对于逐层的滤波器进行范数排序之后,去除范数最小的卷积核,再重新对于模型进行训练从而恢复精度。
- 为了防止在梯度下降时层间权值的改变导致层间输入量的分布情况发生变化,以至于对于协变量的比重进一步提高(使得模型的效果不可控),我们需要对于逐层的输入的均值和方差加以确定,从而缓解对于梯度下降时对于参数的依赖以及偏向协变量的趋势。而在这样的一个归一化过程中,我们可以通过一种L1稀疏化的压缩算法使得部分归一化层中的scale参数趋向于0,从而删除这些节点并且同时保证模型的精度不会受到过大的影响。
- 通过输出的结果接近0的占比来判断单个神经元的重要性。
4.通过算法实现对于分类影响最大的权重甄别,并据此对于占比不高的权重进行剪裁,从而实现对于针对性模型的较高压缩比。
1.2量化等
这里介绍几种常见的压缩方法:
1.2.1 将浮点运算转化为定点计算:
对于神经网络的高精度计算一直时最大的挑战之一,而为了进行高精度的浮点数运算,很多GPU会在设计时专门考量这一部分。
但是,很多的便携式设备和嵌入式系统其实并不具备上述的硬件条件,从而无法进行高精度的浮点型运算。但是,需求依然存在,一方面,训练的需求随着模型数量的增长而快速上升;另一方面,推断的计算需求也随着用户数量的增长而成比例的增加。
这时,我们可以将浮点数(比如32位的)转化为8位或者是16位的定点数进行计算,从而加快模型的运行速度以及降低功耗。这里,我们采用类似归一化的处理方法,将浮点数映射到对应的定点数上,这里,下位溢出较之于上位溢出具有更大的优势(要尽量防止上位溢出)。
这里谈一下定点量化的优势:
- 所占用的磁盘空间更小。我们针对每一层中分布在一定范围内的权重,可以存储每层中最大和最小的权重,然后将浮点型转化为最接近的8位定点型,从而对于文件的大小进行压缩。
- 在模型实际进行推断的过程中,由于转化为8位定点数,所需要的计算资源相较于浮点数大幅度减少。虽然在训练的过程中可能会增加更多的浮点型计算,但是在进行模型推断时速度会大幅提升。
- 对于运算速度而言,很大的瓶颈就是内存的限制,定点数相对于浮点数所占用的更小的内存显然可以带来更好的并行计算效率。
1.2.2 DEEP COMPRESSION: 剪枝算法、权重量化+霍夫曼编码的网络压缩
相关背景需求和思路来源在上一小节已经进行过探讨了,这里不过多赘述。总的来说,一是压缩存储的开销;二是提高运行速度,降低能耗;三就是尽可能保持原有的精度。
这里,我们通过剪去不重要的连接来进行操作,使用权重共享来量化网络,然后应用霍夫曼编码。
这里介绍几个简单的概念:
- 网络剪枝:
这里可以看作是权重剪裁的若干种特殊情况:总得来说,就是从卷积层到全连接层存在大量参数冗余,而神经元激活值靠近于0,我们可以将这些神经元去除而获得相近的模型表达能力。
模型剪枝技术常见的有dropout和dropconnect:
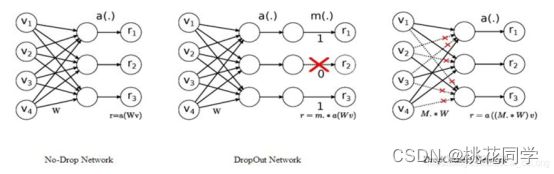
(1) Dropout中随机的将一些 神经元的输出置零 ,这就是神经元剪枝。
(2) DropConnect则随机的将一些 神经元之间的连接置零 ,使得权重连接矩阵变得稀疏,这便是权重连接剪枝。
这两种剪枝都对应这最小单位的剪枝(单个神经元或是单个连接),除此之外,剪枝还有其他不同的粒度:
• 细粒度剪枝(fine-grained):即对连接或者神经元进行剪枝 ,它是粒度最小的剪枝。
• 向量剪枝(vector-level):它相对于细粒度剪枝粒度更大,属于对 卷积核内部(intra-kernel) 的剪枝。
• 核剪枝(kernel-level):即去除某个卷积核 ,它将丢弃对输入通道中对应计算通道的响应。
• 滤波器剪枝(Filter-level):对整个卷积核组进行剪枝 ,会造成推理过程中输出特征通道数的改变。
- 权值共享
我们可以通过使多个连接共享相同的权重,限制需要存储的有效权重数量,然后对那些共享权重进行微调。
这里,我们将不同的权重存储在不同的二进制文件里,每次调用权重,只需要调取相应的索引即可。在更新时,所有的梯度根据权重所在的bin范围进行组合并相加,乘以学习率后被上次迭代中的权值重心值减去,最终得到微调后的权重重心值。
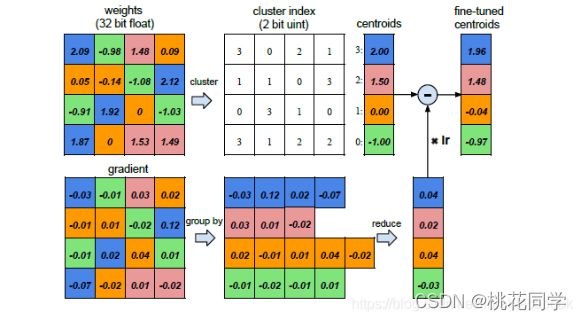
霍夫曼编码这里,使用k聚类算法来得出每个层所对应的共享权重,这是一种很常见的聚类算法,就是通过若干次的迭代,得出k个中心点位置(不同集合的重心),对应着的索引编码位数为:ln k / ln 2。(当然,k-means所一开始取的k个初始点会对聚类结果产生影响,但是这个目前就超出我的理解范畴了,应该时使用线性初始化的方法)
这个就比较常见了,压缩图片文件时这就是常用方法,就是通过对于给定字节的重新规定(使用较少的bits)来代替原有的编码。然后注意一下较短的编码不能被包含于较长编码的头部就可以。
深度压缩后这些网络的大小也有利于部署在能耗更小的设备上,使在移动设备上运行更节能。这种压缩方法也有利于复杂神经网络在大小和下载带宽都具有一定限制的移动应用程序上的使用。
1.3低秩分解
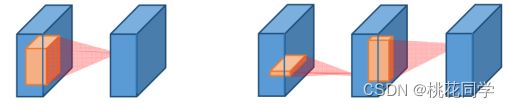
其实卷积运算当中很多运算都是重复的,我们可以通过对于矩阵的分解来减少这一部分的重复计算。其实这里的操作和原先的轻量级模型中的神经网络模型非常相似,就是对于卷积进行拆解来实现(例如将若干个3*3的卷积核来替代5*5的卷积核),这里不但可以减少原先所需要的参数量,还可以大幅度减少计算量。目前常见的压缩方法包括SVD分解,Tucker分解和CP分解等。
1.4知识蒸馏
知识本质上就是从输入向量到输出变量的映射,因此,如果学生模型能够学习到教师模型的映射,就可以认为学到了教师模型的知识。这里,我们采用soft target来指导学生模型的训练。
这里,soft target相较于原先的hard target而言,是对于可能结果的概率分布;此外,soft target还具有一个在分母上的参数T,使得原先的模型具有了更好的泛化能力。
最终我们进行考量时,需要将hard target(原先的 0-1 变量)以及soft target(由teacher得到的概率分布)同时以一定比例放在目标函数里。
同时,如果我们想要提高学生模型的深度,我们还需要选取教师模型的中间层作为hint,对于学生模型的中间层进行监督学习。
2.对于未来发展的想法
近些年,云计算俨然被推上了市场的风口浪尖,高带宽传输,低延迟通信,边缘计算设备仿佛也正如同它的名字一样,越来越边缘化。
但是,仔细一想,这个论调似乎又不是那样的靠得住。
- 我们站在发展的角度看问题,倘若所有企业都占在节省成本,减少固定资产的投入上放入过多的考量,届时,这样的带宽还可以承受如此海量的数据及时相应的需求吗?届时,效率降低,延时增大,相较于节约的成本,对于云计算的过度依赖造成的损失真的划得来吗?
- 在某些特定的高带宽和低延迟的通信网络无法覆盖的特定情形之下,边缘设备使用神经网络进行推断时,这样的需求真的可以忽略不计吗?更有甚者,在这些环境下进行模型训练的需求真的不存在吗?
- 云计算所带来的数据隐私被平台端利用的风险,对于一些企业或者用户而言,是否真的可以接受呢?将信息泄露的风险成本纳入考量,这时使用云计算时的成本真的更低吗?
- 在神经网络的训练和推断的过程,有没有一些处理过程,是成本较低,硬件要求较低的,可以在边缘设备上进行初步处理的呢?倘若有,那么对于这一部分计算需求的云计算资源占用算不算得上是一种资源浪费呢?
当今大多数对于边缘计算的应用,都是基于对于低延迟的快速处理的需求而言,但是往往训练的过程主体仍是云端的平台。其实在我们的大多数压缩方法中,对于这样需求的迎合也非常明显——对于模型的压缩鲜有对于全新模型的训练,而大多是针对推断这样的一个过程进行模型的简化和压缩。
前几天,华为刚刚发布了HarmonyOS,这让我的眼前一亮——一个做通信的厂商,在分布式系统的布局上做出了里程碑的一步,或许未来,就真的如华为的那句:万物互联。多个拥有同一个操作系统的不同主体,在逻辑上通过物联网构成了单一的逻辑主体。
引入分布式,打个不那么好听的比方,就好比哈利波特里,伏地魔的灵魂碎片分布在了不同的魂器上,单个个体可以拥有弱化后的主体能力(压缩后的模型),并且具备主体的部分思考能力(对于模型部分训练的边缘处理)。我相信,在这样的一个分布式框架下,随着现在硬件设备的计算能力的不断迭代,以后在某些情景下的训练以及推断需求,可以借由物联网+云端的混合模式加以实现,实现各类硬件资源协同工作的效率最大化。