智能优化算法:回溯搜索优化算法-附代码
智能优化算法:回溯搜索优化算法
文章目录
- 智能优化算法:回溯搜索优化算法
-
- 1.算法原理
-
- 1.1 初始化种群
- 1.2 选择I
- 1.3 变异
- 1.4 交叉
- 1.5 选择II
- 2.算法结果
- 3.参考文献
- 4.Matlab代码
摘要:回溯搜索优化算法(BSA)是 Civicioglu于2013年提出 的 一种 基 于种群的元启发式算法。被广泛应用于寻优问题中,具有收敛速度快等特点。
1.算法原理
BSA是一种基于种群的新型启发式算法,与大多数元启发式算法类似,该算法通过种群的变异、交叉和选择来达到寻优的目的。BSA有着一个记忆种群的功能,该功能赋予了BSA一个强大的挖掘历史信息能力。BSA的繁殖算子即变异和交叉算子,作为自身算法的标志性特征,与其他进化算法有着本质的区别。BSA算法的基本流程图如图1所示,由5个步骤构成:初始化种群、选择I、变异、交叉和选择II。每个步骤的具体内
容如下:
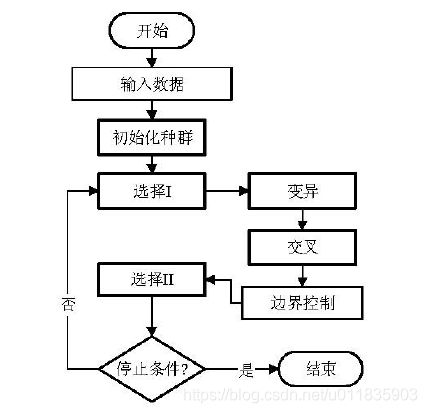
1.1 初始化种群
BSA 随机产生种群 P P P 和历史种群 o l d P oldP oldP,如式(1)所示:
P i , j − U ( l o w j , u p j ) , o l d P − U ( l o w j , u p j ) (1) P_{i,j}-U(low_j,up_j),oldP-U(low_j,up_j) \tag{1} Pi,j−U(lowj,upj),oldP−U(lowj,upj)(1)
式(1)中: i ∈ [ 1 , 2 , . . . , N ] , j ∈ [ 1 , 2 , . . . , D ] i\in [1,2,...,N],j\in [1,2,...,D] i∈[1,2,...,N],j∈[1,2,...,D], N N N和 D D D分别代表种群 个 体 数 和 种 群 维 数;体数和种群维数; l o w j low_j lowj和 u p j up_j upj分别表示第 j j j维分量的下界和上界; U U U为随机均匀分布函数。该步骤仅为算法提供随机的初始数据,不参与后面的迭代过程。
1.2 选择I
BSA的选择I过程是算法迭代起点。首先更新历史种群 o l d P oldP oldP,如(2)所示;再利用式(3)对其中个体位置进行随机排序。
i f a < b , t h e n o l d P = P (2) if \, a
o l d P = p e r m u t i n g ( o l d P ) (3) oldP = permuting(oldP) \tag{3} oldP=permuting(oldP)(3)
式(2)中: a a a与 b b b是(0,1)中产生的两个均匀分布随机数。
该步骤相当于是以0.5的概率从前 n n n代历史种群 o l d P oldP oldP和上代种群 P P P中选出新的 o l d P oldP oldP,由此形成了独特的依概率记忆前代种群功能,这是算法能够进行“回溯”搜索的前提。该选择机制有一个特点:随着算法的迭代次数增多,选择前代历史种群 o l d P oldP oldP的概率会越来越小,而选择前代种群 P P P的概率一直保持0.5不变,显然,选择前代种群 P P P作为当代历史种群 o l d P oldP oldP的可能性更大。
1.3 变异
BSA采用式(4)对种群 P P P进行扰动,得到变异种群 M M M。
M = P + F ∗ ( o l d P − P ) (4) M = P +F*(oldP - P) \tag{4} M=P+F∗(oldP−P)(4)
式(4)中: F F F为变异控制参数, F = 3. r a n d n F= 3.randn F=3.randn , r a n d n randn randn是标准正态分布随机数。该过程从生物学角度看,表示当代种群 P P P向前代种群 o l d P oldP oldP 进行
学习,通过因子 F F F加以控制,从而达到变异效果。该操作赋予了算法强大的全局搜索能力。
1.4 交叉
BSA的交叉过程较同类算法更为精密,可以分为两步。第一步,产生一个N*D大小的映射矩阵map,其初始元素值均为0,然后采用两种策略等概率更新映射矩阵map,如式(5)所示;第二步,根据生成的矩阵map确定种群P中交叉个体元素的位置,然后将P中的此类个体元素与种群M中对应位置元素进行互换,进而得到试验种群T,如式(6)或(7)所示。
简单来讲,该交叉过程由0-1矩阵map决定。当map中元素为1时,将M中对应元素赋给种群T;否则,将P中对应元素赋给种群T。
{ m a p i , u ( 1 , c e i l ( m i x r a t e ∗ r a n d ∗ D ) ) = 1 , i f c < d u = p e r m u t i n g ( 1 , 2 , . . . , D ) m a p i , r a n d i ( D ) = 0 , e l s e (5) \begin{cases} map_{i,u(1,ceil(mixrate*rand*D))} = 1,if \, c
T i , j = { M i , j , i f m a p i , j = 1 P i , j , e l s e (6) T_{i,j} = \begin{cases} M_{i,j},if\,map_{i,j}=1\\ P_{i,j}, \, else \end{cases} \tag{6} Ti,j={Mi,j,ifmapi,j=1Pi,j,else(6)
T i , j = P i , j + m a p i , j ∗ F ∗ ( o l d P i , j − P i , j ) (7) T_{i,j} = P_{i,j} + map_{i,j}*F*(oldP_{i,j} - P_{i,j})\tag{7} Ti,j=Pi,j+mapi,j∗F∗(oldPi,j−Pi,j)(7)
式(5)中: c c c和 d d d为(0,1)上的均匀随机数; c e i l ( . ) ceil(.) ceil(.)是向上取整函数; r a n d ( . ) rand(.) rand(.)为均匀分布的随机整数函数; m i x r a t e mixrate mixrate表示交叉概率参数,在原始BSA中其值设置为1。式(6)和(7)在数学表达上不同,但具体交叉操作过程一致。式(6)偏向更直观理解交叉过程的原理,而式(7)则更清晰地描
述了试验种群 T T T与种群 P P P之间的关系。边界控制:交叉结束后,对试验种群 T T T中个体进行边界控制,若 T T T个体中存在越界元素,则这些元素均采用式(1)重新生成。
1.5 选择II
BSA的选择II过程由个体适应度决定。通过比较种群 P P P和试验种群 T T T 中对应个体适应度值的大小,选择出具有更优适应度的个体,进而产
生新的种群 P P P,如式(8)所示。
P i = { T i , f i t n e s s ( T i ) < f i t n e s s ( P i ) P i , e l s e (8) P_i = \begin{cases} T_i,\,fitness(T_i)
BSA 利用选择II这一步骤更新种群 P P P,再回到选择I步骤参与下一次迭代,直至满足终止条件,输出最优解。
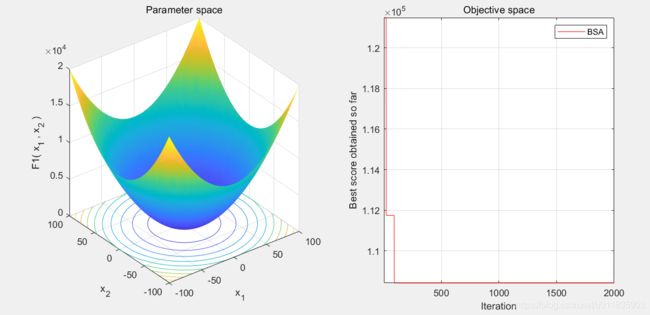
2.算法结果
3.参考文献
[1]王海龙,苏清华,胡中波.回溯搜索优化算法研究进展[J].湖北工程学院学报,2018,38(03):33-42.
4.Matlab代码
https://mianbaoduo.com/o/bread/aJaWk50=