【三维语义分割】PointNet++ (二):模型结构详解
本节主要介绍PointNet++语义分割,其中主干网络和代码环境等PointNet++详细介绍请参考三维目标分类 — PointNet++详解(二)_Coding的叶子的博客-CSDN博客,这里不再进行重复介绍。 PointNet文章作者关于三维物体检测的讲解请参考3D物体检测的发展与未来 - 深蓝学院 - 专注人工智能与自动驾驶的学习平台。
1 代码环境部署
请参考三维目标分类 — PointNet详解(一)_Coding的叶子的博客-CSDN博客。
2 数据介绍
2.1 原始数据
S3DIS(Stanford Large-Scale 3D Indoor Spaces Dataset )数据集是斯坦福大学开发的室内点云数据集,含有像素级语义标注信息。官方下载地址为http://buildingparser.stanford.edu/dataset.html,需要简单填一下信息,填完即可出现下载链接,不需要进行邮箱验证确认。
这里下载的数据集为Stanford3dDataset_v1.2_Aligned_Version.zip,解压之后有Area_1(44个场景)、Area_2(40个场景)、Area_3(23个场景)、Area_4(49个场景)、Area_5(68个场景)、Area_6(48个场景)六个文件夹,即6个不同区域。S3DIS在6个区域的271个房间中共采集了272个场景。每个场景包含一个txt点云文件和一个Annotations文件夹。这个txt文件是该场景的全部点云,每个点云含xyzrgb六个维度数据。Annotations文件夹下为各个类别的txt点云文件,同样存储了xyzrgb六个维度的数据。显然。各个类别的点云应该是总的场景点云的一部分。场景和语义类别共分为:
11种场景:Office(办公室)、conference room(会议室)、hallway(走廊)、auditorium(礼堂)、(open space开放空间)、 lobby(大堂)、lounge(休息室)、pantry(储藏室)、(复印室)、copy room(储藏室)和storage and WC(卫生间)。
13个语义元素: ceiling(天花板)、floor(地板)、wall(墙壁)、beam(梁)、column(柱)、window(窗)、door(门)、table(桌子)、chair(椅子)、sofa(沙发)、bookcase(书柜)、board(板)、clutter (其他)。
2.2 数据预处理
数据预处理脚本如下:
cd data_utils
python collect_indoor3d_data.py/data_utils/meta/anno_paths.txt存储了全部272个场景下的Annotations文件夹路径。/data_utils/meta/class_names.txt列举了上面13个语义元素的标签名称。将Annotations文件夹下的每个txt文件与语义标签类别进行合并,这样每一个点的数据组成为xyzrgbl,l表示标签序号labelid。将合并的文件再次合并到一起,例如Area_1/Conference_room_1/Annotations/文件夹下的33个文件内容加上标签后全部合并到一起,得到Nx7维度的点云数据,N表示该场景中的点云数量。
每个Annotations合并后的文件以numpy形式保存到data/stanford_indoor3d文件夹下,名称为区域_场景.npy,共271个文件,这说明其中1个场景未采集数据。这里并不去细究是哪一个场景没有数据。
2.3 模型输入数据
样本选取:区域Area_5中数据用作评估测试,其他区域数据用于训练。预处理会对每个房间采样4096个点,并且采样后所有样本的点的总数量与原始271个场景房间中点的总数量相等。在总数量保持不变的情况下,采样点的数量下降导致需要增加样本数量,因而同一个场景会多次采样,并且同个场景被采样的概率大小其点云占总数量的比例成正比。经过采样后,训练样本数量为47623,测试样本数量为18923。
4096个点的采样过程:随机选择点云中的一个点作为样本中心点,选取该点xy方圆1米内的点,z方向上不做限制。算法中限制这一步必须至少采样到1024个点。接着对采样出来的点随机选择4096个点,如果前一步点的数量大于等于4096则无重复选择,否则可重复选择出4096个点。
归一化:
(1)将采样出来的4096个点坐标减去上述采样的样本中心点坐标,得到Point[:3],并且输入模型前会进行旋转增强。
(2)将rgb颜色信息除以255,得到Point[3:6]。
(3)将采样出来的4096个点坐标除以房间中坐标的最大值,得到Point[6:9]。
最终模型的输入为的归一化点信息(4096x9)和类别标签(4096)。
3 模型结构
3.1 上采样插值
介绍模型结构之前,先简要介绍PointNet++的上采样原理。SA结构对点云采样后会降低点云中点的数量,而语义分割是像素级别的分类,即要对每个点进行分类。因此,点云中的点需要和原始点云中的点一一对应才能够进行损失计算和模型训练,也就是点云中的点的数量要恢复到原始数量。
PointNet++的上采样是通过插值来实现的,并且插值依赖于前后两层特征。假设前一层的点数M=64,后一层点数N=16,那么插值的任务就是把后一层的点数插值成64。主要步骤如下:
(1)以前一层的64个点为参考点,分别计算这64个点和待插值的16个点的距离,得到64x16的距离矩阵。
(2)分别在待插值的16个点中选择k=3个最接近各个参考点的点,然后将这k个点特征的加权平均值作为插值点的特征。每个参考点都会得到一个新的特征,新的特征来自于后一层点特征的加权平均。加权系数等于各个点的距离倒数除以3个点的距离倒数之和。距离越近,加权系数越大。
插值的效果直观描述为:使得前一层的点数能够获得类似后一层的特征。PointNet++的上采样模块为PointNetFeaturePropagation,即FP层。
3.2 模型计算
PointNet结构如下图所示,图中下半部分为分类网络并已经在三维目标分类 — PointNet++详解(二)_Coding的叶子的博客-CSDN博客详细介绍,特别具体介绍了SA模块的计算过程。上半部分为分割网络,也是本节重点介绍的内容。
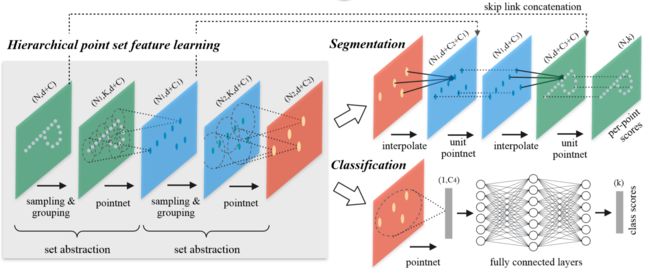
(1)SA1:输入数据l0_points的特征维度为9x4096,具体介绍请参考2.3节。首先通过SA模块得到1024个采样点,特征维度l1_points为64x1024。
(2)SA2:输入数据为l1_points,通过SA模块得到256个采样点,特征维度l2_points为128x256。
(3)SA3:输入数据为l2_points,通过SA模块得到64个采样点,特征维度l3_points为256x64。
(4)SA4:输入数据为l3_points,通过SA模块得到16个采样点,特征维度l4_points为512x16。
(5)FP4:根据l3_points对l4_points进行插值,插值后l4_points为512x64,将插值后特征与l3_points进行拼接,并经过卷积Conv1d(768, 256)和Conv1d(256, 256)后得到新的l3_points特征256x64。
(6)FP3:根据l2_points对新的l3_points进行插值,插值后l3_points为256x256,将插值后特征与l2_points进行拼接,并经过卷积Conv1d(384, 256)和Conv1d(256, 256)后得到新的l2_points特征256x256。
(7)FP2:根据l1_points对新的l2_points进行插值,插值后l2_points为256x1024,将插值后特征与l1_points进行拼接,并经过卷积Conv1d(320, 256)和Conv1d(256, 128)后得到新的l1_points特征128x1024。
(8)FP1:根据l0_points对新的l1_points进行插值,插值后l1_points为128x4096,并经过卷积Conv1d(128, 128)和Conv1d(128, 128)后得到新的l0_points特征128x4096。
(9)新的l0_points特征中输出特征经过卷积conv1d(128, 128)、conv1d(128, 13)、log_softmaxt得到13维度的输出,即13个类别log softmax(4096x13),即图中下方的per-point scores。
4 损失函数
与PointNet不一样的地方在于,PointNet++不含特征变换矩阵。因此。损失函数仅由交叉熵损失函数组成,不再包括64维特征的变换矩阵的损失。这里考虑到类别的均衡性,交叉熵损失函数会为每个类别分配一个权重。在全部原始点云中,同一类别的空间点数量最多的权重最小,取值为1。其他,类别的权重是最大点数量与该类别数量的比值的三分之一次方,显然其他类别的权重大于1。
5 训练评估程序
首先运行2.2中的数据预处理脚本,data文件夹需要新建,默认是没有的。将model参数设置为pointnet2_semseg,然后直接运行train_classification.py和test_classdification.py即可完成训练和测试。
更多三维、二维感知算法和金融量化分析算法请关注“乐乐感知学堂”微信公众号,并将持续进行更新。
python三维点云从基础到深度学习_Coding的叶子的博客-CSDN博客_3d点云 python从三维基础知识到深度学习,将按照以下目录持续进行更新。https://blog.csdn.net/suiyingy/article/details/124017716