ByteTrack多目标追踪论文阅读
paper:ByteTrack: Multi-Object Tracking by Associating Every Detection Box
code:ByteTrack
一.摘要
多目标追踪的目的是识别视频中物体或对象的位置和身份,也就是说,不同于目标检测的是,追踪问题可以分为两个任务:1)确定当前帧所有对象的bounding box;2)确定当前帧中这些bounding box是之前帧中的谁,即身份的确定。
大部分追踪算法获取当前帧中的对象身份是将那些当前帧中高置信度的检测框(高置信度代表此检测框有物体的可能性更大)与当前帧之前那些帧的追踪结果进行身份匹配,这些高置信度检测框可以通过设置置信度阈值进行筛选得到。而那些低置信度检测框,即小于置信度阈值的那些检测框将被简单的丢弃掉,因为认为这些检测框中可能根本不存在物体,但这是不合理的,因为这些低置信度可能是由于运动模糊或对象被遮挡而导致的。如果由于某个对象被遮挡或运动模糊就将其删除,会导致此对象追踪的中断。
为了解决由于直接将低置信度检测框删除而导致的追踪中断现象,提出了一个新的身份关联方法,这个方法是通过关联当前帧几乎所有的检测框,而非仅仅关联那些高置信度检测框。对于那些低置信度检测框,通过使用其与之前帧的追踪对象的相似度进行身份匹配,从而通过相似度筛选出这些低置信度检测框哪些是真正的对象(有可能被遮挡,亦有可能运动模糊),而哪些又是背景。
二.数据关联
数据关联(或我本人习惯称之为身份关联或身份匹配)是多目标追踪中的核心,首先计算当前帧中所有检测框和之帧每个追踪目标的相似度。其次根据得到的相似度,利用不同的匹配策略来进行和之前帧追踪对象的身份关联。
(1)相似度指标
位置,运动以及外观对于相似度的计算来说都是有用的线索。例如,不同bounding box的距离可以作为相似度;不同bounding box中的对象的特征(颜色,轮廓等)相似度;不同bounding box的iou值也可以作为相似度。
SORT追踪算法首先通过使用卡尔曼滤波估计前一帧中所有追踪目标在当前帧的位置(bounding box,也就是卡尔曼滤波中的状态估计值),然后运用卡尔曼滤波得到的bounding box估计值和目标检测器(例如yolo,rcnn等)在当前帧中的实际检测结果中所有bounding box(卡尔曼滤波中称为观测值)的iou作为相似度。
这里简单对卡尔曼滤波进行介绍,如果想要深入了解可以自行对相关知识进行补充,卡尔曼滤波是一个用来进行状态(这里的状态可以是速度,坐标等)预测的算法,其可以简单的分为两步:1>运用预设的运动方程(例如假设物体都是匀速运动)以及前一帧中的状态预测值进行状态估计,从而得到状态估计值;2>使用当前时刻的观测值(在目标追踪中就是当前帧中使用目标检测器得到的检测结果)对状态估计值进行修正得到最终的状态预测值。这样说可能不太直观,通过下图来进行简单的解释:

其实也比较容易理解,单纯用运动方程以及上一帧中的目标位置估计当前帧中的目标位置可能会有误差,例如上图中的橙色框。而当前帧中使用目标检测器检测到的目标位置也存在一定误差,例如上图中的黑色框,那么我们将两者进行“中和”一下就可以得到比较准确的预测结果,例如上图中的绿色框。
那可能会存在这样的疑问,当前帧检测到的目标bounding box(观测值,上图中的黑色框)存在很多个,例如一张图中有多个人,并且状态估计值(上图中的橙色框)也有很多个,如何确定多个观测值和多个状态估计值的对应关系呢,只有确定了对应关系才能进行“中和”得到状态预测值呢,这就涉及到匹配策略。
(2)匹配策略
当计算得到相似度之后,匹配策略为当前帧的每一个检测框进行身份匹配。可以通过匈牙利算法进行匹配。这里匈牙利算法就步展开讲了,简单介绍一下,匈牙利算法本身用来进行任务分配,即有多个人去完成多项任务,每个人完成每项任务所需时间不同,匈牙利算法用来找出总耗时最短的任务分配策略。这里当前帧的检测框(卡尔曼滤波中的观测值)可以看作多项任务(或多个人),上一帧得到的当前帧的状态估计值可以看作为多个人(或多项任务),1-相似度类似于任务耗时,使用匈牙利算法即可完成身份匹配。
现有追踪算法大都聚焦于如何构建更好的匹配策略,而作者认为检测框的使用方式决定了数据匹配的上限,并且作者聚焦在数据匹配过程中于如何充分的使用从高置信度到低置信度的检测框。
三.BYTE
BYTE是作者提出的一种新的数据关联方法,不同于以往那些只对高置信度边界框进行数据关联的方法,作者提出的方法几乎保留所有的边界框并为其进行身份匹配,并将其划分为高置信度和低置信度两组。
作者首先将高置信度边界框与之前帧的追踪轨迹进行匹配从而确定每个高置信度边界框的身份。然而有部分追踪轨迹可能匹配不到当前帧的一些边界框,这是因为那些追踪轨迹在这些高置信度边界框中并没有找到合适的匹配对象,这是因为那些轨迹对应的物体可能被遮挡或运动模糊而导致在当前帧中目标检测框为低置信度,从而被划分到低置信度那一组。
高置信度边界框匹配完成后再进行低置信度边界框的匹配,低置信度边界框和那些剩余的未匹配到对应边界框的之前帧的追踪目标进行匹配,匹配完成后那些仍然未匹配到追踪目标的低置信度边界框则可以认为是背景从而被丢弃。
通过下图来进一步说明:

整个BYTE算法的伪代码如下图所示:

其实从整个伪代码就可以了解BYTE算法的整个流程及思路。
从伪代码中可以看出,BYTE算法的输入由3部分组成:视频序列,目标检测器,置信度阈值。
输出为整个视频中各个目标的追踪轨迹,每个追踪轨迹包含此轨迹目标在每一帧中的边界框信息以及目标的身份信息。
BYTE的整个流程如下:
遍历视频的每一帧,然后使用输入的目标检测器对每一帧进行目标检测,得到一系列检测框和每一个检测框的置信度。对应伪代码中的第3行。将检测框按照置信度阈值划分为高置信度检测框和低置信度检测框,对应伪代码中的6至13行。
使用卡尔曼滤波根据之前帧的各个目标的追踪结果来估计当前帧中目标的位置,对应伪代码的14到16行。
第一次数据关联将那些当前帧高置信度检测框和卡尔曼滤波估计的结果进行匹配(包括那些之前跟丢了的轨迹也参与匹配,这里跟丢的轨迹表示和高置信度以及低置信度检测框都未匹配成功的那些轨迹,如果连续固定帧数都未被匹配到对应的检测框则删除对应的跟踪轨迹,当然伪代码中为了简化是将那些跟踪丢失的轨迹直接删除掉了,见伪代码第22行,所以原文这里的描述和伪代码并是不对应的)。匹配过程使用到了边界框和卡尔曼滤波估计结果之间的相似度,这里可以采用IoU或Re-ID特征间距离来作为相似度度量。然后基于相似度采用匈牙利算法进行匹配,并保留那些未匹配到轨迹的高置信度检测框以及未匹配到检测框的轨迹。这部分对应伪代码中的17到19行。
第二次数据关联是关联那些第一次关联剩下的轨迹以及低置信度检测框。之后保留那些第二次匹配过后仍然未匹配到边界框的轨迹,并删除那些低置信度边界框中在第二次匹配过后未找到对应轨迹的边界框,因为这些边界框被认定为是不包含任何物体的背景。对应伪代码中的第20到21行。
两次数据关联之后,未匹配到边界框的轨迹(相当于对应轨迹在当前帧未找到其目标,即目标跟踪丢失了)将被删除,原文中这里描述和第一次数据关联中的描述实际上是冲突的,但是和伪代码第22行的处理是一致的,实际上之后作者也说明了,这样写是为了简化流程,如果想要保证目标在某一帧或某几帧追踪丢失后目标再次出现时能够恢复追踪,是不应当将其删除的。应当保留那些追踪丢失目标的轨迹,如果这些轨迹连续固定帧数(例如30帧)均追踪丢失才会将其彻底删除。否则仍然将其保留并参与后续的数据匹配。
最后将那些未匹配到对应轨迹的高置信度边界框作为新出现的轨迹进行保存,对应伪代码的23到27行。
最终输出每一帧中每条轨迹的身份以及其边界框,注意这里不输出最终为追踪丢失的轨迹的信息。
四.个人注解补充
伪代码中未体现出卡尔曼滤波的状态修正,其只有状态估计,在伪代码第14到16行,而实际在源码中是存在状态修正的,如下图进行第一次数据关联的代码:

在第二次数据关联时也存在状态修正这一步,从如下源码图中可看出:
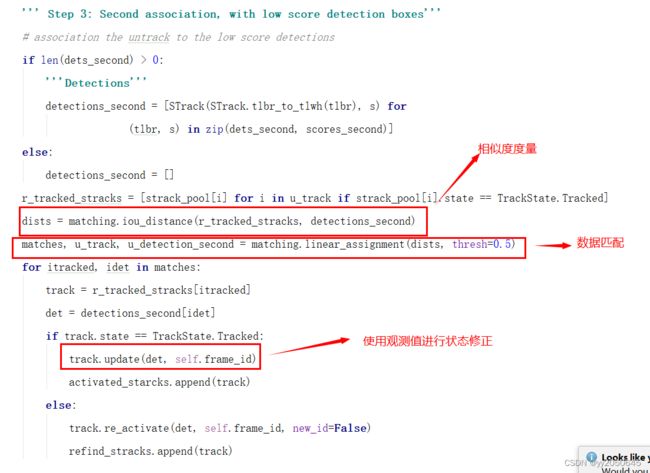
因此,匹配只是作为卡尔曼滤波中的一个环节用来获取之前追踪轨迹对应当前帧中的那些检测框(状态观测值),从而来对状态估计值进行修正。