Java集合常问知识点
Java集合框架
- Set
-
- HashSet
- TreeSet
- List
-
- ArrayList与LinkedList
- Map
-
- HashMap
- TreeMap
简单介绍几个常用的集合类,也是经常在面试的被问到的,所以特此收集了一些笔记,不是非常详细,文中有什么错误的地方希望指正。
集合(collection)也称为容器(container),一个集合对象可以存储、检索、操作多个不同类型的其他对象,将他们作为一个整体来管理。在Java中提出了集合框架(Collection Framework)的概念,即管理集合的统一架构。主要包括:接口、实现和操作。集合的常用类图如下图:
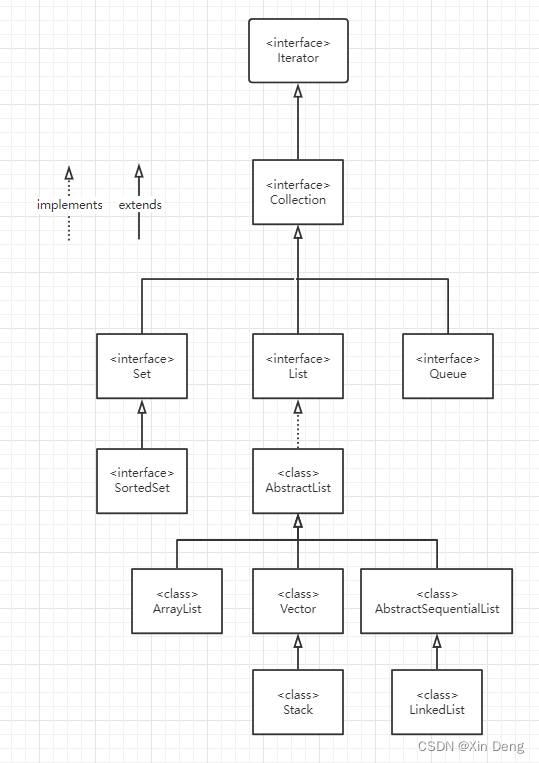
为了方便逐个访问集合元素,集合继承了接口java.util.Iterator。一个Iterator对象是一个一次性(如果想再次遍历该集合,只能再次获取一个Iterator对象)的对象,用来遍历一次集合中的所有元素。Iterator接口成员函数如下:
| 函数名称 | 功能描述 |
|---|---|
| boolean hasNext() | 判断集合中还有没有元素 |
| Obejct next() | 从集合中读取下一个元素,并将指针往后挪动一格 |
| void remove() | 删除当前元素 |
接着介绍集合,Collection是所有集合的顶层接口,因此所有的集合都支持这些成员函数。它包含了如下几个常用成员函数:
| 函数名称 | 功能描述 |
|---|---|
| int size() | 返回集合元素个数 |
| boolean isEmpty() | 判断集合是否为空 |
| boolean contains(Object element) | 判断集合是否包含某个元素 |
| boolean add(Object element) | 添加一个元素 |
| booleann remove(Object element) | 删除一个元素 |
| Iterator iterator() | 用于循环遍历集合 |
Set
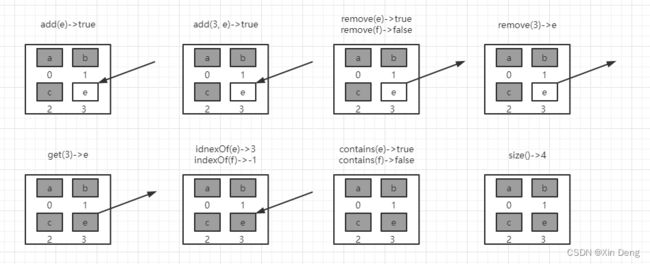
Set集合,两个重要特性:无重(无重复元素)和无序(不记录每个元素的添加顺序)。常用方法如下图:

这个图形象说明set接口中的常用函数的特点,对于add函数,如果集合中存在要添加的元素,则添加失败;使用remove函数时,删除集合中不存在元素就会操作失败。
HashSet
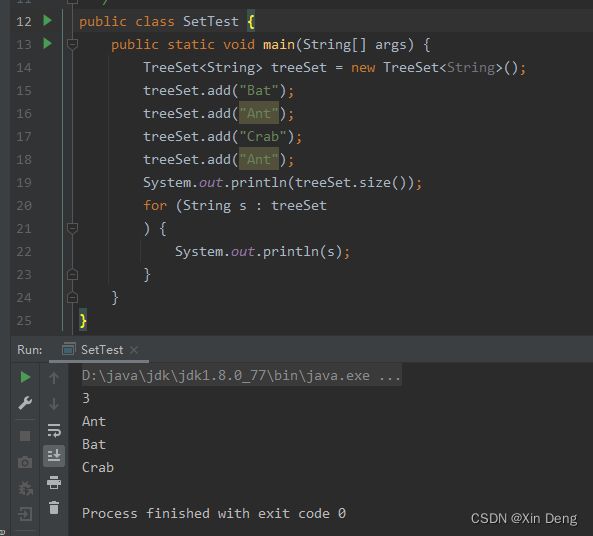
HashSet就是使用了哈希表来存储集合数据,同样具有Set集合的特点,无重无序。观看下面代码的运行结果:
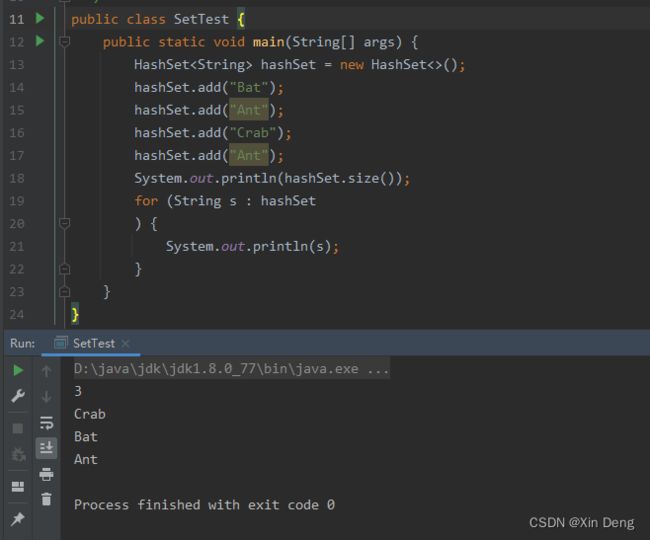
从运行结果可以看出:由于add了两次“Ant”,但是第二次添加是无效的,并且输出的顺序也不是我们添加前后的顺序,这个顺序是不确定的。
TreeSet
除了HashSet,还有另一种Set——TreeSet。它的特点概括:
- 有序,按元素的值从小到大排序
- 元素的存放按照二叉树形式存储,每个父节点最多有两个子节点,并且左大右小
- 要求存入的元素具有比较性,即相应的类实现了Comparable接口,如String和Integer类等
同上面的代码,使用TreeSet集合保存输出,结果如下:
List
按照存入的顺序进行存储,允许重复元素,每个元素都有一个对应的下标(从0开始)。常用函数如下图:
| 函数名称 | 功能描述 |
|---|---|
| add(i, o) | 在第i个位置插入对象o |
| add(o) | 把对象o添加到集合的末尾 |
| addAll(i, c) | 在第i个位置插入集合c中的所有元素 |
| addAll(e) | 把集合e中的所有元素都添加到集合的末尾 |
| remove(i) | 删除第i个元素 |
| remove(o) | 删除对象o的第一次出现 |
| set(i, o) | 将第i个元素替换为对象o |
| get(i) | 返回第i个元素 |
| indexOf(o) | 返回对象o的第一次出现的下标 |
| lastIndexOf(o) | 返回对象o的最后一次出现的下标 |
| listIterator() | 返回一个list iterator |
| subList(i, j) | 返回下标i到j之间的元素所构成的子列表 |
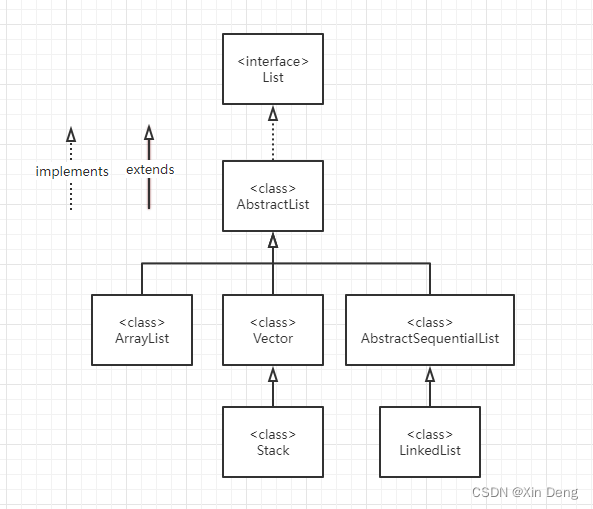
List只是一个接口,不过它有3各常用的实体类:ArrayList、Stack、LinkedList。
ArrayList与LinkedList
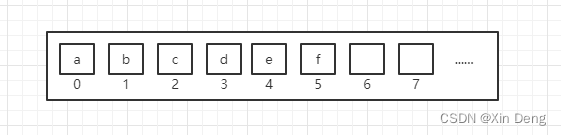
便于区别比较,我将ArrayList和LinkedList放一起,面试的时候也经常问这两个之间的区别。ArrayList的存储方式如List差不多,属于直接访问结构,可以通过下标直接访问任意一个元素。并且,与普通的数组相比,ArrayList的长度是可变的。ArrayList示意图如下图:
LinkedList是链表,属于顺序访问结构,正因为链表的各结点不是连续存放的(后一个结点的地址存放在前一个结点中),如果要访问其中的第i个结点,就必须从第一个结点一个个一次往后访问。LinkedList示意图如下图:

此外,对于remove函数,其功能是从列表中删除一个对象。对于ArrayList,由于它的元素是在内存中连续存放的,因此,如果它要删除一个元素,就必须把该元素右边的所有元素都往左移动一个位置,时间开销较大。而对于LinkedList,如果他要删除一个元素,则只要把该元素的左右相邻的元素调整一个即可,时间开销小。而如果要随机访问一个元素,ArrayList就要比LinkedList快很多。那对于删除和添加,LinkedList就比ArrayList快吗?
使用代码测试一下它俩的性能,具体代码为:
public class ArrayListAndLinkedList {
public static void main(String[] args) {
int[] num_1 = getRandomNum(10000);
int[] num_2 = getRandomNum(10000);
ArrayList<Double> arrayList = new ArrayList<>();
// 测试LinkedList时将下面代码注解打开,并将上面一行代码注释
//LinkedList arrayList = new LinkedList<>();
Double element;
long start, end;
// 添加列表元素
for (int i = 0; i < 10000; i++) {
arrayList.add(new Double(i));
}
start = System.nanoTime();
for (int i = 1; i < 10000; i++) {
element = arrayList.get(num_1[i]);
arrayList.set(num_2[i], element);
}
end = System.nanoTime();
System.out.println(arrayList.getClass());
System.out.println("获取和修改平均所花时间 = " + (end - start) / 10000 + " ns");
System.out.println("总花时 = " + (end - start) + " ns");
}
/**
* 返回一个0~length-1不重复的随机数
* @param length
* @return
*/
private static int[] getRandomNum(int length) {
Random random = new Random();
ArrayList<Integer> integers = new ArrayList<>();
int[] nums = new int[length];
for (int i = 0; i < length; i++) {
integers.add(random.nextInt(i + 1), new Integer(i));
}
for (int i = 0; i < length; i++) {
nums[i] = integers.get(i);
}
return nums;
}
}
运行结果如下图:


从这两个结果来看,对于获取和修改元素操作,LinkedList花费的时间远远大于ArrayList。因为它无法随机访问,让它要访问某一个元素时,只能从头开始,一个个往后访问。更新一个元素的时间复杂度为O(N)。实际上,插入操作本身是很快的,只涉及相邻的几个结点的链接操作,时间复杂度是O(1),问题是,需要找到操作元素的具体位置需要时间,所以时间复杂度为O(N)。删除操作同理。
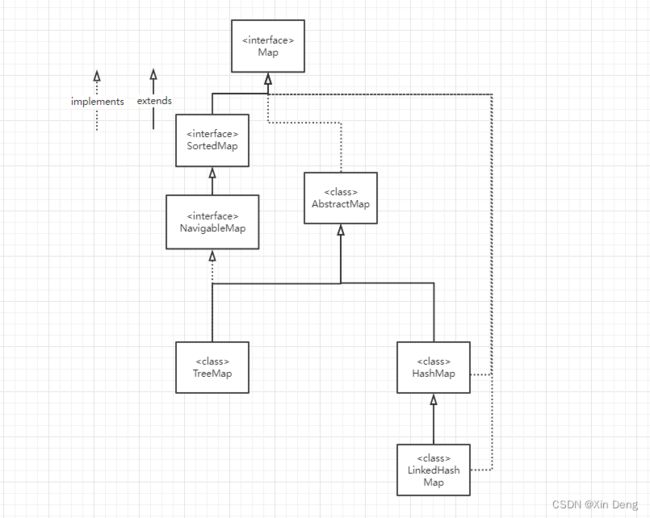
Map
所谓Map,即映射,形式为Map
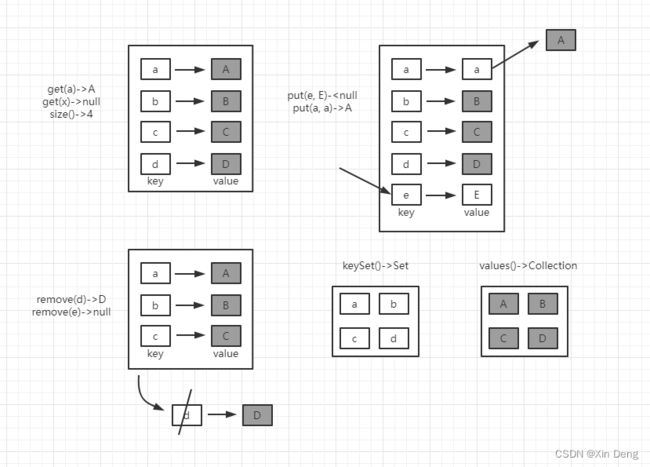
| 函数名称 | 功能描述 |
|---|---|
| V put(K key, V value) | 将key键所对应的值修改为value |
| V get(Object key) | 返回key对应的值 |
| V remove(Object key) | 从集合中删除一个键值对 |
| int size() | 返回集合中元素个数 |
| Set keySet() | 返回一个Set集合,包含所有键(从小) |
| Collection values() | 返回一个Collection集合,包含所有值 |
HashMap
常用的Map集合是HashMap,它等同于另一个类HashTable,两者在功能上差不多,但是HashTable已经过时,尽量不要使用。下面看一个简单的例子。
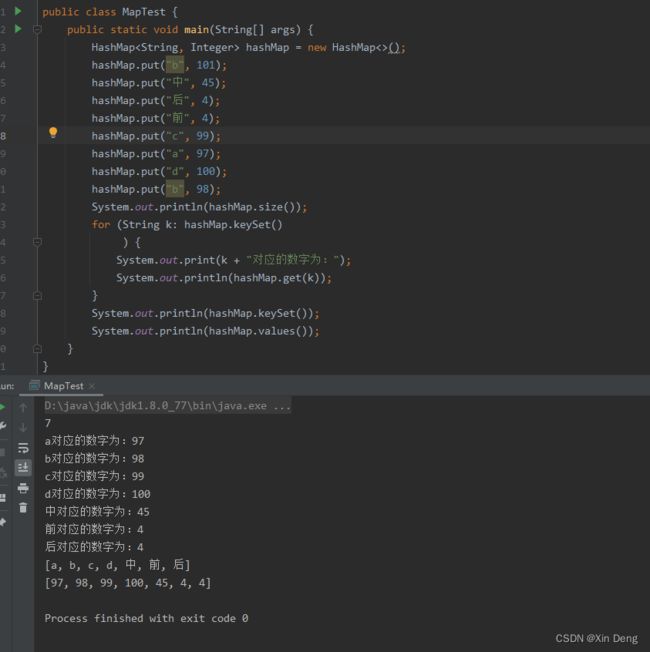
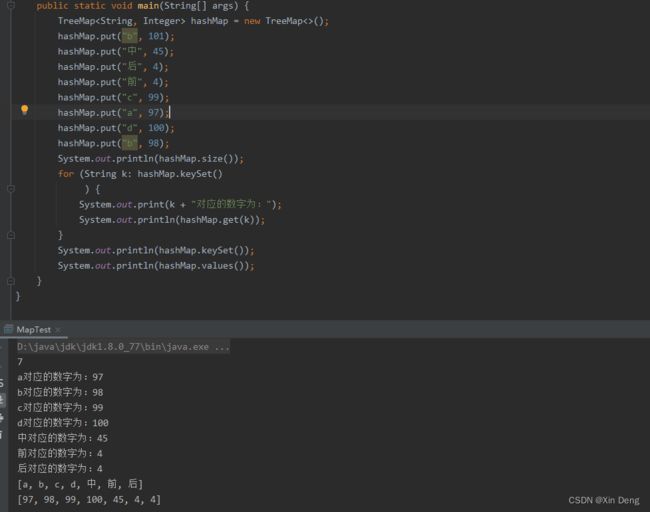
首先不难看出对于在同一个key上添加重复的值,是执行的更新操作,会覆盖原先的值,还可以看到键的输出并不是按照插入的顺序输出的,那到底是按照什么顺序呢?我又添加了几个小数格式的字符串,先后输出了每个键的ASCII码和hash值,发现只有hash值的大小顺序能够和值的顺序对应。开始的时候并没有想到它会在put添加的时候就以hash大小存放,而是从keySet()方法探究,但是查看源码发现,此方法并没有对键进行排序。原文截图如下:

翻译如下:

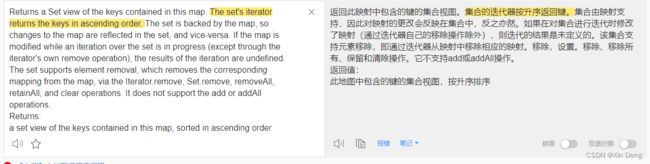
而唯一有排序字眼的seySet()方法是在SortedMap接口中,原文截图如下:
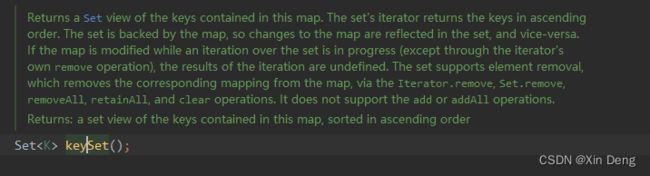
翻译如下:
HashMap以及下面介绍的TreeMap继承的是AbstractMap抽象类,而在AbstractMap类中也没有明显的与SortedMap关系。最后我查看了put方法,发现了原因:

先不看putVal(见名知意),直接点击hash函数:
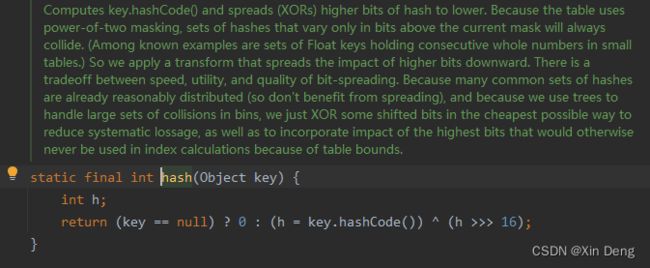
所以,排序操作是putVal方法利用哈希值完成的。
TreeMap
TreeMap是Map接口的另一个实体类,它和TreeSet一样,都是对集合元素进行了排序。即按照键的大小排序。在keySet方法明确说明了按照返回的key集合是排序的,但是他们对应的值就不要是按照顺序的了。