一文上手决策树和随机森林和KNN-python
写在前面
- 我们在数据分析或者建模中经常会用到机器学习模型中的树模型或者近邻的方法,通过本文可以使你快速搭建出一个可以运行的效果还不错的模型,但是原理可以通过其他的博客自己补一下~ 写这篇文章也是想让自己记录一下,方便以后用的时候直接拿来用。我认为这里面最好用的还是当属可视化部分代码啦~毕竟学习之前也不知道可视化竟然这么方便!
- 本文主要分为三个部分,分别是决策树的用法;KNN的用法;随机森林的用法。其实三者在sklearn里调包的话差别不大,细微差别。
- 适合像我一样的小白中的小白,可以大体了解一下~高手绕道嘿嘿嘿
- 但是这篇文章中我没有添加进处理数据部分,所以只能假象这里是有数据的,毕竟我们也都是先有数据的,所以应该问题不大~
1、决策树的用法
- 导入warnings来避免显示一些不重要的警示
- 先导入matplotlib包,方便后面直接绘图;导入pandas和numpy
- seaborn也是个比较好用的绘图包,但是我还是比较喜欢用matplotlib
import warnings
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
sns.set()
warnings.filterwarnings('ignore')
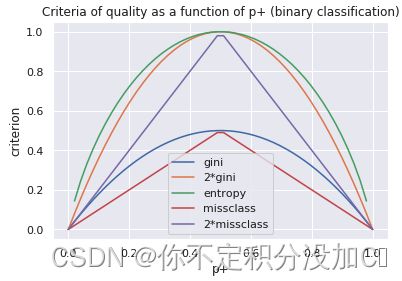
这部分其实不太重要,就是想画一下各个方面的图~忽略
# 绘制图像
plt.figure(figsize=(6, 4))
xx = np.linspace(0, 1, 50)
plt.plot(xx, [2 * x * (1-x) for x in xx], label='gini')
plt.plot(xx, [4 * x * (1-x) for x in xx], label='2*gini')
plt.plot(xx, [-x * np.log2(x) - (1-x) * np.log2(1 - x)
for x in xx], label='entropy')
plt.plot(xx, [1 - max(x, 1-x) for x in xx], label='missclass')
plt.plot(xx, [2 - 2 * max(x, 1-x) for x in xx], label='2*missclass')
plt.xlabel('p+')
plt.ylabel('criterion')
plt.title('Criteria of quality as a function of p+ (binary classification)')
plt.legend()
结果如下:
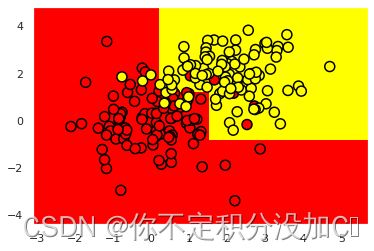
下面训练一棵Sklearn决策树
from sklearn.tree import DecisionTreeClassifier
# 编写一个辅助函数,返回之后的可视化网格
def get_grid(data):
x_min, x_max = data[:, 0].min() - 1, data[:, 0].max() + 1
y_min, y_max = data[:, 1].min() - 1, data[:, 1].max() + 1
# 这两步要限制网格的大小
return np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01))
# max_depth参数限制决策树的深度,random_state是随机种子数,而做二分类任务就用交叉熵
#步骤①
clf_tree = DecisionTreeClassifier(criterion='entropy', max_depth=6,
random_state=17)
# 步骤②:训练决策树
clf_tree.fit(train_data, train_labels)
# 按理说我们可以直接predict了,但是我们要做一下可视化
xx, yy = get_grid(train_data)#xx和yy是返回的两个边界列表
#步骤③:预测
predicted = clf_tree.predict(np.c_[xx.ravel(),
yy.ravel()]).reshape(xx.shape)
# np.c_是横向拼接两个矩阵,ravel可以拉成一维数组
#下面是画图,可有可没有
plt.pcolormesh(xx, yy, predicted, cmap='autumn')
plt.scatter(train_data[:, 0], train_data[:, 1], c=train_labels, s=100,
cmap='autumn', edgecolors='black', linewidth=1.5)
- 通过 pydotplus 和 export_graphviz 库我们可以方便的看到决策树本身是怎样的。使用
StringIO()函数开辟一个缓存空间保存决策树,通过export_graphviz()函数以 DOT 格式导出决策树的 GraphViz 表示,然后将其写入 out_file 中。使用graph_from_dot_data()函数读入数据并通过Image()函数显示决策树。
!pip install pydotplus # 安装必要模块
from ipywidgets import Image
from io import StringIO#缓存
import pydotplus
from sklearn.tree import export_graphviz#展示树的细节,以DOT格式导出
dot_data = StringIO()
export_graphviz(clf_tree, feature_names=['x1', 'x2'],
out_file=dot_data, filled=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(value=graph.create_png())

sklearn的决策树:DecisionTreeClassifier
主要三个参数:
- max_depth 树的最大深度;
- max_features 搜索最佳分区时的最大特征数(特征很多时,设置这个参数很有必要,因为基于所有特征搜索分区会很「昂贵」);
- min_samples_leaf 叶节点的最少样本数。
n_train = 150
n_test = 1000
noise = 0.1
def f(x):
x = x.ravel()
return np.exp(-x ** 2) + 1.5 * np.exp(-(x - 2) ** 2)
def generate(n_samples, noise):
X = np.random.rand(n_samples) * 10 - 5
X = np.sort(X).ravel()
y = np.exp(-X ** 2) + 1.5 * np.exp(-(X - 2) ** 2) + \
np.random.normal(0.0, noise, n_samples)
X = X.reshape((n_samples, 1))
return X, y
#可以直接跳到这里,下面两行是要处理好我们要训练和测试的数据~具体什么格式根据事实情况定。
X_train, y_train = generate(n_samples=n_train, noise=noise)
X_test, y_test = generate(n_samples=n_test, noise=noise)
# 步骤①:用树模型
reg_tree = DecisionTreeRegressor(max_depth=5, random_state=17)
#步骤②:训练
reg_tree.fit(X_train, y_train)
#步骤③:预测
reg_tree_pred = reg_tree.predict(X_test)
# 下面是做了一些可视化
plt.figure(figsize=(10, 6))#这一步相当做了一个画布的样子,指定了大小
plt.plot(X_test, f(X_test), "b")#直接plt.plot,其中有两个参数需要传入,第三个参数是“B"
plt.scatter(X_train, y_train, c="b", s=20)#散点图
plt.plot(X_test, reg_tree_pred, "g", lw=2)
plt.xlim([-5, 5])
plt.title("Decision tree regressor, MSE = %.2f" %
(np.sum((y_test - reg_tree_pred) ** 2) / n_test))
plt.show()
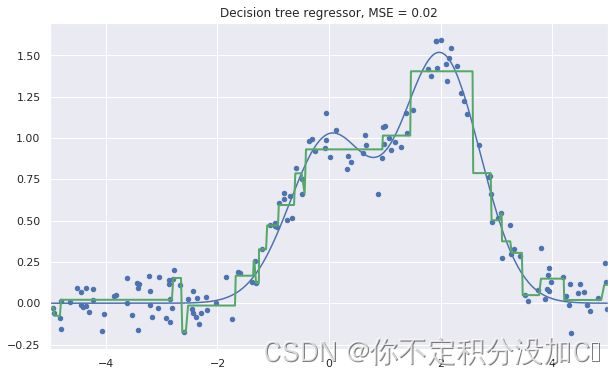
2、最近邻KNN的用法
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
#处理数据
X_train, X_holdout, y_train, y_holdout = train_test_split(df.values, y, test_size=0.3,
random_state=17)
#使用树和KNN模型,因为后续要比较一下
tree = DecisionTreeClassifier(max_depth=5, random_state=17)
knn = KNeighborsClassifier(n_neighbors=10)
#训练两个模型
tree.fit(X_train, y_train)
knn.fit(X_train, y_train)
from sklearn.metrics import accuracy_score
#分别预测和看一下得分
tree_pred = tree.predict(X_holdout)
accuracy_score(y_holdout, tree_pred)
nn_pred = knn.predict(X_holdout)
accuracy_score(y_holdout, knn_pred)
如何交叉验证得出树的最优参数?
- 因为我们上面是随机给的参数,但是并不是最优的,所以可以交叉验证和网格搜索找到最优的参数,这里可能会稍微慢一点点
from sklearn.model_selection import GridSearchCV, cross_val_score
#以字典的形式传入参数的范围,内部是列表的格式
tree_params = {'max_depth': range(5, 7),
'max_features': range(16, 18)}
#这个GridSearchCV就是我们的网格搜索了,得到这个tree_grid之后我们可以进行很多操作
tree_grid = GridSearchCV(tree, tree_params,
cv=5, n_jobs=-1, verbose=True)
#比如可以fit训练
tree_grid.fit(X_train, y_train)
#还可以得到最佳的参数和训练集准确率均值
print(tree_grid.best_params_)
print(tree_grid.best_score_)
print(accuracy_score(y_holdout, tree_grid.predict(X_holdout))
- 绘制得到的决策树!
dot_data = StringIO()
export_graphviz(tree_grid.best_estimator_, feature_names=df.columns,
out_file=dot_data, filled=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(value=graph.create_png())

使用交叉验证确定KNN的最佳参数~
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
#这里使用pipeline管道把模型封装起来用,其实不需要理解太多,我觉得就是把这俩参数放在一个管道里,处理完一个再一个的~
knn_pipe = Pipeline([('scaler', StandardScaler()),
('knn', KNeighborsClassifier(n_jobs=-1))])
knn_params = {'knn__n_neighbors': range(6, 8)}
knn_grid = GridSearchCV(knn_pipe, knn_params,
cv=5, n_jobs=-1,
verbose=True)
knn_grid.fit(X_train, y_train)
knn_grid.best_params_, knn_grid.best_score_
accuracy_score(y_holdout, knn_grid.predict(X_holdout))
3、再训练一个随机森林
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=100, n_jobs=-1,
random_state=17)
np.mean(cross_val_score(forest, X_train, y_train, cv=5))
forest_params = {'max_depth': range(8, 10),
'max_features': range(5, 7)}
forest_grid = GridSearchCV(forest, forest_params,
cv=5, n_jobs=-1, verbose=True)
forest_grid.fit(X_train, y_train)
print(forest_grid.best_params_, forest_grid.best_score_)
print(accuracy_score(y_holdout, forest_grid.predict(X_holdout)))
决策树的优劣势:
优势
- 生成容易理解的分类规则,这一属性称为模型的可解释性。例如它生成的规则可能是「如果年龄不满 25 岁,并对摩托车感兴趣,那么就拒绝发放贷款」。
- 很容易可视化,即模型本身(树)和特定测试对象的预测(穿过树的路径)可以「被解释」。
- 训练和预测的速度快。
- 较少的参数数目。
- 支持数值和类别特征。
劣势
- 决策树对输入数据中的噪声非常敏感,这削弱了模型的可解释性。
- 决策树构建的边界有其局限性:它由垂直于其中一个坐标轴的超平面组成,在实践中比其他方法的效果要差。
- 我们需要通过剪枝、设定叶节点的最小样本数、设定树的最大深度等方法避免过拟合。
- 不稳定性,数据的细微变动都会显著改变决策树。这一问题可通过决策树集成方法来处理(以后的实验会介绍)。
- 搜索最佳决策树是一个「NP 完全」(NP-Complete)问题。了解什么是 NP-Complete 请点击 这里。实践中使用的一些推断方法,比如基于最大信息增益进行贪婪搜索,并不能保证找到全局最优决策树。
- 倘若数据中出现缺失值,将难以创建决策树模型。Friedman 的 CART 算法中大约 50% 的代码是为了处理数据中的缺失值(现在 sklearn 实现了这一算法的改进版本)。
- 这一模型只能内插,不能外推(随机森林和树提升方法也是如此)。也就是说,倘若你预测的对象在训练集所
KNN的方法优劣
优势
- 实现简单。
- 研究很充分。
- 通常而言,在分类、回归、推荐问题中第一个值得尝试的方法就是最近邻方法。
- 通过选择恰当的衡量标准或核,它可以适应某一特定问题。
劣势
- 和其他复合算法相比,这一方法速度较快。但是,现实生活中,用于分类的邻居数目通常较大(100-150),在这一情形下,k-NN 不如决策树快。
- 如果数据集有很多变量,很难找到合适的权重,也很难判定哪些特征对分类/回归不重要。
- 依赖于对象之间的距离度量,默认选项欧几里得距离常常是不合理的。你可以通过网格搜索参数得到良好的解,但在大型数据集上的耗时很长。
- 没有理论来指导我们如何选择邻居数,故而只能进行网格搜索(尽管基本上所有的模型,在对其超参数进行调整时都使用网格搜索的方法)。在邻居数较小的情形下,该方法对离散值很敏感,也就是说,有过拟合的倾向。
- 由于「维度的诅咒」,当数据集存在很多特征时它的表现不佳。
当需要处理一些数据时,还可能会用到下面的代码
- 对数据进行一下可视化处理,对每一个维度的数据进行一下统计
fig = plt.figure(figsize=(25, 15))
cols = 5
rows = np.ceil(float(data_train.shape[1]) / cols)
for i, column in enumerate(data_train.columns):
ax = fig.add_subplot(rows, cols, i + 1)
ax.set_title(column)
if data_train.dtypes[column] == np.object:
data_train[column].value_counts().plot(kind="bar", axes=ax)
else:
data_train[column].hist(axes=ax)
plt.xticks(rotation="vertical")
plt.subplots_adjust(hspace=0.7, wspace=0.2)
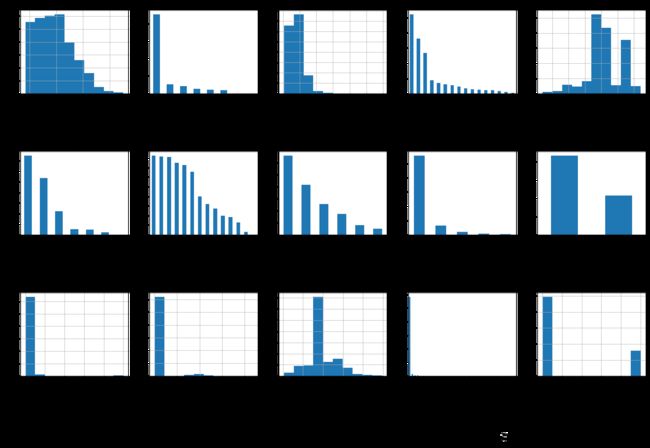
- 在下一步进行数据分析的时候,还要检查一下数据的类型~
data_train.dtypes
看到某一项应该为int的但是实际上为object的,要修复一下
data_test['Age'] = data_test['Age'].astype(int)
- 这里还需要继续对数据预处理,首先区分数据集中的类别和连续特征。
# 从数据集中选择类别和连续特征变量
categorical_columns = [c for c in data_train.columns
if data_train[c].dtype.name == 'object']
numerical_columns = [c for c in data_train.columns
if data_train[c].dtype.name != 'object']
print('categorical_columns:', categorical_columns)
print('numerical_columns:', numerical_columns)
- 然后,对连续特征使用中位数对缺失数据进行填充,而类别特征则使用众数进行填充。
# 填充缺失数据
for c in categorical_columns:
data_train[c].fillna(data_train[c].mode(), inplace=True)
data_test[c].fillna(data_train[c].mode(), inplace=True)
for c in numerical_columns:
data_train[c].fillna(data_train[c].median(), inplace=True)
data_test[c].fillna(data_train[c].median(), inplace=True)
- 接下来,我们需要对类别特征进行独热编码,以保证数据集特征全部为数值类型方便后续传入模型。
data_train = pd.concat([data_train[numerical_columns],
pd.get_dummies(data_train[categorical_columns])], axis=1)
data_test = pd.concat([data_test[numerical_columns],
pd.get_dummies(data_test[categorical_columns])], axis=1)
好啦,总结完了,希望对大家有用,对自己也是一个进步~~~~~