python加载模型包_pytorch-保存和加载模型
简介
pytorch与保存、加载模型有关的常用函数3个:
torch.save(): 保存一个序列化的对象到磁盘,使用的是Python的pickle库来实现的。
torch.load(): 解序列化一个pickled对象并加载到内存当中。
torch.nn.Module.load_state_dict(): 加载一个解序列化的state_dict对象
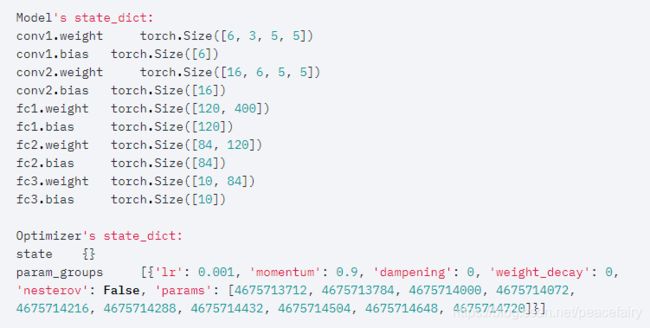
1、state_dict是什么?
在pytorch中所有可学习的参数保存在model.parameters()中。state_dict是一个python中的字典,保存了各层与其参数张量之间的映射。torch.optim对象也有一个state_dict,它包含了optimizer的state,以及一些超参数。
2、在预测过程中保存和加载模型
2.1仅保存模型参数(推荐存储方式)
# save
torch.save(model.state_dict(), PATH)
# load
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.eval()#切换为测试模式,防止参数更新
注意:
PyTorch 的1.6版本修改了 torch.save(),使用了一种新的基于 zipfile 的文件格式。Load 仍然保留以旧格式加载文件的能力。如果出于任何原因希望 torch.save() 使用旧格式,请传递 kwarg _ use _ new _ zipfile _ serialization = False。
load _ state _ dict ()函数接受一个 dictionary 对象,而不是保存对象的路径。这意味着在将保存的state_ dict 传递给 load _ state _ dict ()函数之前,必须对其进行反序列化。例如,您不能使用 model.load _ state _ dict (PATH)加载。
在保存模型进行inference时,只需保存训练好的模型的学习参数。使用 torch.save ()函数保存模型的 state_dict 将为以后恢复模型提供最大的灵活性,这就是为什么它是保存模型的推荐方法。一个常见的 PyTorch 约定是使用.pt或.pth 文件扩展名。请记住,在进行inference之前,必须调用 model.eval ()将 dropout 和批量规范化层设置为测试模式。不这样做将导致不一致的inference结果。
2.2 保存整个模型(不推荐的)
# save
torch.save(model, PATH)
# load
# Model class must be defined somewhere
model = torch.load(PATH)
model.eval()
3、保存和加载常规检查点(针对测试和恢复训练)
# save
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
...
}, PATH)
# load
model = TheModelClass(*args, **kwargs)
optimizer = TheOptimizerClass(*args, **kwargs)
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
model.eval()
# - or -
model.train()
保存
在测试和恢复训练时,保存一个检查点,不仅要存储模型的参数(model.state_dict),还要存储优化器的参数(optimizer.state_dict-其中包含在模型训练时更新的缓冲区和参数
),还有中断的epoch,最新记录的训练损失或其他你认为重要的东西。一般这个checkpoint的存储量是单单一个模型的2~3倍。
若要保存多个组件配置,请将它们组织到字典中,并使用 torch.save ()序列化字典。一个常见的 PyTorch 约定是使用.tar 文件扩展名。
加载
首先初始化模型和优化器
之后使用torch,load()加载本地的字典配置
最后根据之前定义的字典结构,轻松获取自己想恢复的数据
4、在一个文件中保存多个模型
# sava
torch.save({
'modelA_state_dict': modelA.state_dict(),
'modelB_state_dict': modelB.state_dict(),
'optimizerA_state_dict': optimizerA.state_dict(),
'optimizerB_state_dict': optimizerB.state_dict(),
...
}, PATH)
# load
modelA = TheModelAClass(*args, **kwargs)
modelB = TheModelBClass(*args, **kwargs)
optimizerA = TheOptimizerAClass(*args, **kwargs)
optimizerB = TheOptimizerBClass(*args, **kwargs)
checkpoint = torch.load(PATH)
modelA.load_state_dict(checkpoint['modelA_state_dict'])
modelB.load_state_dict(checkpoint['modelB_state_dict'])
optimizerA.load_state_dict(checkpoint['optimizerA_state_dict'])
optimizerB.load_state_dict(checkpoint['optimizerB_state_dict'])
modelA.eval()
modelB.eval()
# - or -
modelA.train()
modelB.train()
此情况可能在GAN,Sequence-to-sequence,或ensemble models中使用
保存方式同上面讲的checkpoints的保存方式类似,且.tar文件扩展名
5、使用一个不同模型的参数来预训练模型
# save
torch.save(modelA.state_dict(), PATH)
# load
modelB = TheModelBClass(*args, **kwargs)
modelB.load_state_dict(torch.load(PATH), strict=False)
加载部分模型是迁移学习或训练新的复杂模型时常见的场景。利用经过训练的参数,即使只有少数是可用的,将有助于热身开始训练过程,并有希望帮助您的模型比从零开始的训练更快地收敛。
无论是从缺少一些键的部分 state_dict 加载,还是在拥有更多键的state_dict加载。可以通过设置参数strict = False来忽略与模型不匹配的键。
如果您希望将参数从一个层加载到另一个层,但有些键不匹配,只需更改要加载的state _ dict 中的参数键的名称,以匹配要加载到的模型中的键。
6、跨设备保存和加载模型
6.1 保存在GPU上,在CPU上加载
# save
torch.save(model.state_dict(), PATH)
# load
device = torch.device('cpu')
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH, map_location=device))
6.2保存在 GPU 上,加载在 GPU 上
# save
torch.save(model.state_dict(), PATH)
# load
device = torch.device("cuda")
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.to(device)
# Make sure to call input = input.to(device) on any input tensors that you feed to the model
6.3保存在CPU上,加载到GPU上
# save
torch.save(model.state_dict(), PATH)
# load
device = torch.device("cuda")
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH, map_location="cuda:0")) # Choose whatever GPU device number you want
model.to(device)
# Make sure to call input = input.to(device) on any input tensors that you feed to the model
6.4保存torch.nn.DataParallel模型
# save
torch.save(model.module.state_dict(), PATH)
# load
# Load to whatever device you want
torch.nn.DataParallel是一个支持并行 GPU 使用的模型包装器。通过torch.load()中参数map_location 灵活设置想要的设备。