ResNet及其变体ResNeXt学习笔记
ResNet及其变体ResNeXt
1. ResNet
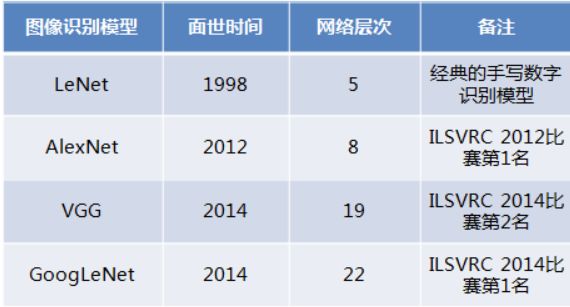
ResNet作为分类网络赢得了2015年ILSVRC冠军,且将top-5 error降低到了3.57%。这一年,深度学习第一次在这个任务上打败了人类(top-5 95%)。
同时作者还测试了ResNet对于计算机视觉下游任务中的提升效果,仅仅通过替换方法中的backbone(比如将faster rcnn中的vgg-16网络换成了resnet-101),ResNet就在2015的ImageNet 目标检测、ImageNet 图像定位、COCO 目标检测、COCO 语义分割等多个赛道获得了冠军。
想法来源:训练一个深度比较深的深度神经网络是非常难的,可以看到在resnet之前,这些世界级的深度神经网络其实都不太“深”。
当深度达到一定深度后,简单地堆叠层数并不能带来性能的提升
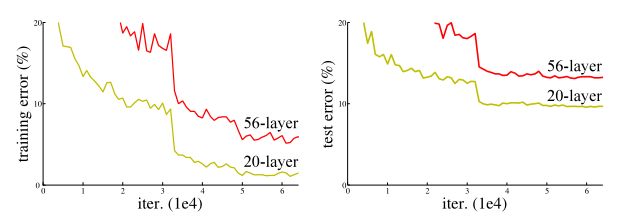
上图表示简单地增加网络层数后的神经网络在cifar-10上训练后的结果,可以看到56-layer在训练集以及测试上的错误率都明显高于20-layer,这已经不仅仅是由于参数过多所带来的过拟合问题(因为更深的网络在训练集上表现也很差),这是由于网络的加深会造成梯度爆炸和梯度消失的问题,可以理解为网络发生了退化。
虽然从理论上来说,更深的网络可以试图让在靠近输出层的网络层学习到的参数全为1,这样即使经过这些层也不会发生任何变化,使得它的准确率相比不增加网络层数至少不会变得更坏,从而得到一个相对比较好的结果。但遗憾的是,随机梯度下降法(SGD)是一种比较容易陷入局部最优的优化方法,在实际训练中,它往往学不到这样的解。
(对输入数据和中间层的数据进行归一化操作,如添加BN层,可以保证网络在反向传播中采用随机梯度下降(SGD),从而让网络达到收敛。但是,这个方法仅对几十层的网络有用,当网络再往深处走的时候,这种方法就无用武之地了)。
如下图左所示,简单地添加更多的网络层也许会让解空间变得更大,但也会更容易陷入局部最优,使得偏离之前的解空间。
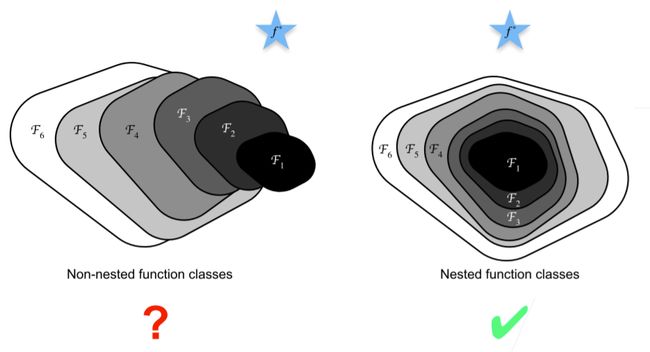
一种直接的想法是显式地给网络传达这种模式,让网络在添加深度后,即使在最差的情况下也能够学到这种恒等映射,使得网络效果至少不会变得更坏
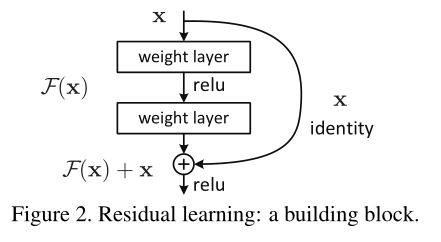
即将上一层的输出加到下一层的输出上,如上图所示,原论文中将这种方法称为跳跃连接 (Skip connection),以此组成的块称为残差块(Residual block)。
假设希望学习到的目标函数H(x),添加之前F(x)学习的是H(x),添加之后F(x)等价于学习H(x)-x,即残差,所以将这种结构称为残差结构。
需要说明的是,这种方法并不是在resnet中第一次提出,早在上世纪90年代就有相关的研究,甚至在resnet提出之前,caffe中就有对应的函数可以直接调用实现。这其实也说明了科研中真正有影响力的工作大多数时候并不是提出了一个新方法,而是用这个方法去很好地解决了某个问题,并把这种方法教会给大家。

不使用残差块 使用残差块
(在ImageNet上训练,粗线代表训练集误差,细线代表测试集误差)

可以看到,在使用残差结构(这里采用填充0实现,不增加任何额外参数去对比)以后,34-layer的效果明显由于18-layer效果,与添加之前相反。

作者还在cifar-10上测试了这种结构的有效性,可以看到即使在这种小型数据集上,使用残差结构将网络提高到110层,仍然有微小提升,将网络提高到一千层,效果也只是下降一点点。
对于即使提高到1000层,为什么依然有效果,没有出现明显的过拟合,也没有变得特别坏,是一个比较开放的问题。现在的一种解释是显式地给网络传达这种恒等映射模式,可能会降低模型的内在复杂度,因为如果最后靠近输出层的那些层学到的参数全是恒等映射,那么其实就等价于学到一个更简单的网络模型。
关于残差块的实现:
ResNet使用4个由残差块组成的模块(第一个stage是7x7的卷积层),每经过一个stage,特征图的大小都会发生变化,即每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半,通道数翻倍(第一个模块的通道数同输入通道数一致。 由于之前已经使用了步幅为2的最大汇聚层,所以无须减小高和宽)。而x+f(x)需要保证二者的通道数和特征图大小都相等。

作者这里在ImageNet数据集上试验了三种方法
Plan A:通过填充0(padding)来增加维度,保证二者维度一样,这种方法skin connect不带任何参数,不带来额外的计算量。
PlanB:对于发生维度改变的层在skip connect中使用1x1卷积进行通道升维,对维度不发生改变的层采用直接相加,可以看到效果更好,带来的额外计算量也不多(只增加4个1x1卷积层)
PlanC:对每个残差块都在skip connect中使用1x1卷积层,大大提高了计算量,但收效甚微。
因此最终选择PlanB,如下图所示

此外为了降低增强网络层数所带来计算量骤增,作者提出在每个残差块使用1x1卷积先降低通道的维度,再进行3x3卷积,最后再使用1x1卷积还原通道数,从而有效降低计算量,这就是瓶颈结构(bottleneck),这样做会带来一定的信息损失,但这也意味着你可以在同样的计算量下将网络变得更深,从而弥补这种损失

BasicBlock BottleNeck

作者对resnet50乃至更深的网络均使用了瓶颈结构(bottleneck),这使得计算量大大减少,可以看到34-layer与50-layer相差16层,但两者的理论计算量却相差不大(实际上1x1卷积在gpu上的实现没有3x3卷积高效,resnet-50实际中还是比resnet-34贵不少)
作者在另一篇论文《Identity Mappings in Deep Residual Networks》中尝试调整BN和relu的顺序,也即所谓resnet v2(即下图中的full pre-activation),理由是:①ReLU作为“residual”分支的结尾,我们不难发现“residual”分支的结果永远非负,这样前向的时候输入会单调递增,从而会影响特征的表达能力 ②BN改变了“identity”分支的分布,影响了信息的传递,在训练的时候会阻碍loss的下降。
实际中貌似没多大区别,目前pytorch源码中仍然使用original版本来进行代码实现

对于每个图左侧部分我们称作“identity”分支,右侧部分我们称作“residual”分支
最后,关于残差结构为什么有效,其实大家不怎么买原作者的账,即从函数解空间这个角度去解释。因为论文中没有任何的公式,只是做了一些实验,并且这个角度也不太能完全解释实验结果。
现在更流行的解释角度认为,效果好主要是因为残差结构将训练时的梯度保持的比较好。如下图所示,在简单堆叠的情况下,如果底层(靠近输出的层)学到了比较好的参数,那么梯度就会比较小,反向传播到上一层,上一层的梯度就会更小,最终可能导致上面的层(靠近输入的层)无法更新,只有最后几层有效,发生网络退化。
而在残差结构中,将梯度传播中的乘法变成了加法,导致上一层的梯度并不会变的更小,这样SGD也能对这些层进行有效的更新和训练,从而取得比较好的效果。

2. ResNeXt
ResNeXt (suggesting the next dimension)是原作者在2016年对ResNeXt的改进工作,如下图所示,在计算量相同的情况下,ResNeXt的错误率会更低。
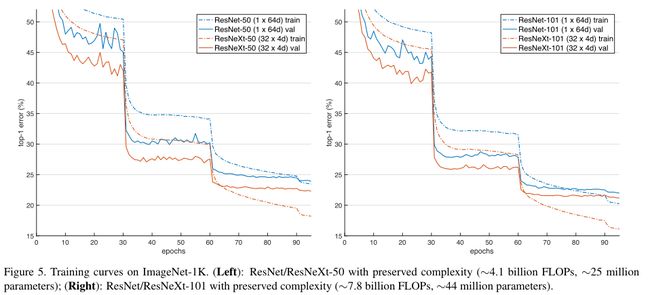
如下所示,简单来说就是将GoogleNet中的Inception块与ResNet中的残差结构结合,利用到了split-transform-merge 思想,即将原来的卷积层拆分为不同的分支分别进行卷积运算再组合,并且理论上来说cardinality(基数,即分支数,原文的解释是the size of the set of transformations)拆分的越多越好。

有意思的是,在2016年,GoogleNet团队同样将残差结构加入到Inception块中,提出了InceptionV4,主要的不同之处在于ResNeXt采用相同的分支结构,而Inception块中分支是人为调参试出来的,不同的分支采用不同大小的卷积核。一方面来说InceptionV4较于ResNeXt块,融合了不同尺度的特征信息,效果会更好一些。另一方面来说ResNeXt的并行度更高,计算效率自然更高,并且InceptionV4是在固定的数据集上调参出来的,迁移到别的数据集上的表现会差一些。
ResNeXt还采用了一种组卷积(Group Convolution)的方式来减少参数数量和计算量,即将输入通道拆分给不同的分支进行卷积计算,这使得ResNeXt可以使用比ResNet更多的卷积核而不显著增加参数量和计算量,计算细节与参数数量对比如下图所示。
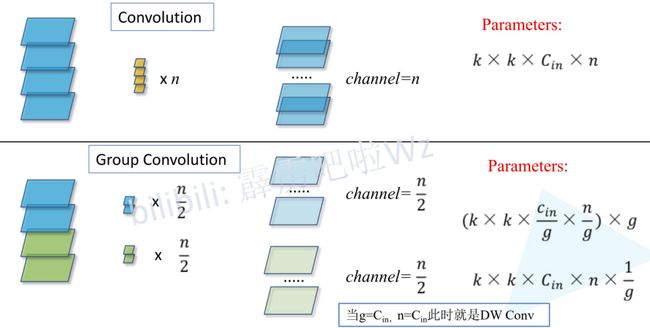
将每个输入通道都分为一个组时,就是所谓的深度可分离卷积(Depthwise Separable Convolution)


如上图所示,作者经过实验将ResNeXt中的group设置为32,即每个块拆分为32个分支(ResNeXt50每个分支分配4个通道,ResNeXt101每个分支分配8个通道),可以看到在使用更多的卷积核的情况下,参数和计算量ResNeXt和ResNet基本一样。
实际上,这种分组卷积的方式最早可以追溯到AlexNet中,正如我们在上一篇文章中提到的,由于单个GPU显存不足,作者不得不将AlexNet中的通道拆分到两个GPU上,在每个GPU分别进行卷积操作后再进行交互,“被迫”进行分组卷积。
不同的组之间实际上是不同的子空间(subspace),这样的拆分使得它们能学到更多样(diverse)的表示。正如AlexNet作者所可视化的那样,两组sub-networks一组倾向于学习黑白的信息(下图上半部分),而另一组倾向于学习到彩色的信息 (下图下半部分)。这种分组的操作大大降低了每个sub-network的复杂度,使得卷积核学到的关系更加稀疏(相关性更低),在复杂度不变的情况下,模型的泛化性会更高,过拟合的风险也会更低,可能起到了一种网络正则化的效果。

此外,只有当块具有一定深度(>=3)时,这种拆分才会带来稀疏性,由于resnet18和34每个残差块仅有两层(没有使用BottleNeck),这种分组拆分就没有太大意义,因此ResNeXt仅对resnet50以及更深的网络做了改进。
后来,在2019年作者加大了ResNeXt中的通道数,使用ResNeXt-101(32x48d)在更大的数据集上做了弱监督预训练,再在imageNet进行微调,成为了当时的SOTA模型(top-1:85.4%),进一步表明了分组卷积的有效性。
ResNet还有很多别的变体,如WideResNet、Dilated ResNet、Dual Path Networks、SENet、ResNest等等,本质上都是像ResNeXt:ResNet的主体结构+一些新东西。相信聪明的你在深入了解了ResNet后,在需要用到某个变体的时候,从ResNet的基础上出发,自然也能快速地掌握它。