pytorch版本基于vgg16的迁移学习实现kaggle猴子分类
Vgg16的基本网络结构
代码可直接在cpu上运行,但是速度会比较慢,若是想要在GPU运行,可以添加一些语句。
Vgg16的网络结构由13层卷积层+3层全连接层组成
kaggle上猴子的数据源:https://pan.baidu.com/s/1Y15Tsm_hmP6pMHnGpOA4qg 提取码:6ass
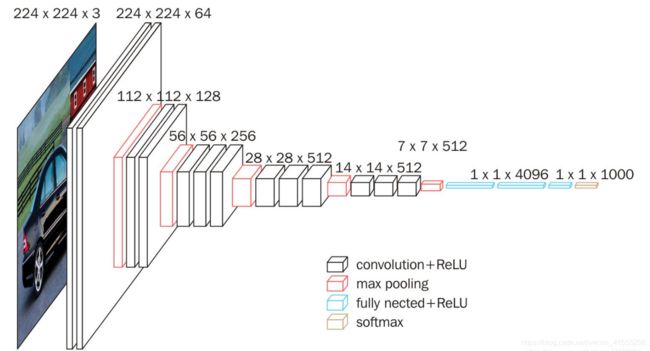
首先通过torchvision导入模型vgg16(也可以通过import torchvision.models.vgg,按ctrl查看vgg的pytorch代码)
module.py文件
import numpy as np
import pandas as pd
from sklearn.metrics import accuracy_score,confusion_matrix,classification_report
import matplotlib.pyplot as plt
import seaborn as sns
import hiddenlayer as h1
import torch
import torch.nn as nn
from torch.optim import Adam
import torch.utils.data as Data
from torchvision import models
import torchvision.models.vgg
##使用VGG16特征提取层+新的全连接层组成新的网络
class MyVggModel(nn.Module):
def __init__(self):
super(MyVggModel, self).__init__()
##导入训练好的VGG16网络
vgg16 = models.vgg16(pretrained=True)
##获取VGG16的特征提取层
vgg = vgg16.features
##将VGG16的特征提取层参数进行冻结,不对其进行更新
for param in vgg.parameters():
param.requires_grad_(False)
##预训练的VGG16特征提取层
self.vgg=vgg
#添加新的全连接层
self.classifier=nn.Sequential(
nn.Dropout(p=0.5), # 按照一定的比例将网络中的神经元丢弃,可以防止模型训练过度
nn.Linear(512*7*7,512),
nn.ReLU(),
nn.Dropout(p=0.5),#按照一定的比例将网络中的神经元丢弃,可以防止模型训练过度
nn.Linear(512,256),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(256,10),#10为输出的类别
nn.Softmax(dim=1)
)
##定义网络的前向传播
def forward(self,x):
x=self.vgg(x)
x=x.view(x.size(0),-1)
output=self.classifier(x)
return output #[b,10]
def main():
my=MyVggModel()
print(my)
if __name__ == '__main__':
main()若要修改成自己所要训练的类别,可以修改其中的classifier下最后一个Linear文件:
self.classifier=nn.Sequential(
nn.Dropout(p=0.5), # 按照一定的比例将网络中的神经元丢弃,可以防止模型训练过度
nn.Linear(512*7*7,512),
nn.ReLU(),
nn.Dropout(p=0.5),#按照一定的比例将网络中的神经元丢弃,可以防止模型训练过度
nn.Linear(512,256),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(256,10),#10为输出的类别,这里可以修改为自己想要做的分类数量
nn.Softmax(dim=1)
)train.py文件
import torch
import torchvision
from torchvision import datasets
from torchvision import transforms
from torch import nn, optim
from torch.utils.data import DataLoader
# from lenet5 import Lenet5
from torchvision.datasets import ImageFolder
import torch.utils.data as Data
import torchvision.models.resnet
from module_00 import MyVggModel
def main():
train_data_transforms = transforms.Compose([
transforms.RandomResizedCrop(224), # 随机长宽比裁剪为224*224
transforms.RandomHorizontalFlip(), # 依概率p=0.5水平翻转
transforms.ToTensor(), # 转化为张量并归一化为[0-1]
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
##对验证集的处理
val_data_transforms = transforms.Compose([
transforms.Resize(256), # 重置图像分辨率
transforms.CenterCrop(224), # 依据给定的中心进行裁剪
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 因为每一类图像放在一个单独的文件夹,故可以尝试使用ImageFolder()函数从文件中读取
train_data_dir = "D:/python_data/monkey/training"
train_data = ImageFolder(train_data_dir, transform=train_data_transforms)
##数据加载器
train_data_sum = Data.DataLoader(train_data, batch_size=32, shuffle=True)
val_data_dir = "D:/python_data/monkey/validation"
val_data = ImageFolder(val_data_dir, transform=val_data_transforms)
##数据加载器
val_data_sum = Data.DataLoader(val_data, batch_size=32, shuffle=True)
x, label = iter(train_data_sum).next()
print("x:", x.shape, 'label:', label.shape)
print("训练集的样本数:", len(train_data.targets))
print("测试集的个数:", len(val_data.targets))
model = MyVggModel()
criteon = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
save_path = './resNet.pth'
for epoch in range(10):
train_loss_epoch=0
val_loss_epoch=0
train_corrects=0
val_corrects=0
model.train()
for step,(x,label) in enumerate(train_data_sum):
output=model(x)
loss=criteon(output,label)
pred=output.argmax(dim=1)
#backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss_epoch+=loss.item()*x.size(0)
train_corrects+=torch.sum(pred==label.data)
train_loss=train_loss_epoch/len(train_data.targets)
train_acc=train_corrects.double()/len(train_data.targets)
print("train_acc",train_acc)
####
model.eval()
with torch.no_grad():
for step, (x, label) in enumerate(val_data_sum):
output = model(x)
loss = criteon(output, label)
pred = output.argmax(dim=1)
val_loss_epoch += loss.item() * x.size(0)
val_corrects += torch.sum(pred == label.data)
val_loss = train_loss_epoch / len(train_data.targets)
val_acc = train_corrects.double() / len(train_data.targets)
print("val_acc:",val_acc)
if(epoch ==9):
torch.save(model.state_dict(),save_path)
if __name__ == '__main__':
main()