2019机器学习代码实现
Wouldn’t it be great to be able to solve complex machine learning problems quickly and without extensive knowledge of the amazing TensorFlow or PyTorch frameworks?
w ^ ouldn't它是巨大的,能够解决复杂的机器学习问题,Swift ,没有惊人的TensorFlow或PyTorch框架的广泛的知识?
Well, Libra gives you that power, and today I will give you concrete examples of machine learning projects that you can easily implement with this exciting and elegant library, along with results.
好吧,天秤座为您提供了强大的功能,今天,我将为您提供机器学习项目的具体示例 ,您可以轻松地通过这个令人兴奋且优雅的库以及结果来实现这些项目 。
In a previous article, I presented Libra, its features and downsides, so feel free to check it out before diving into examples!
在上一篇文章中,我介绍了天秤座,它的功能和缺点,因此在深入研究示例之前,请随时进行检查!
动机 (Motivation)
I got interested in Machine Learning a couple of years ago, but at the time things weren’t as easy as just creating a Python file, writing a bunch of lines of code and running it to be happy with results that you can visualize.
几年前,我对机器学习产生了兴趣,但当时事情并不像创建Python文件,编写一堆代码行并运行它以使您对可视化的 结果感到满意那样简单。
Instead, you had to go through all of PyTorch or Keras documentation to figure out how to put the components together and how they interact with each other, which was kind of overwhelming at first.
取而代之的是,您必须阅读所有PyTorch或Keras文档,以弄清楚如何将这些组件放在一起以及它们之间如何相互作用,这乍一看让人有些不知所措 。
This article’s goal is to give you an overview of how easy it is to get acquainted with Machine Learning thanks to a framework that can ease your way in eventually learning complex processes.
本文的目的是给您一个概述,使您能够轻松熟悉机器学习,这要归功于其可以简化最终学习复杂过程的方式的框架。
Libra’s client class is central and implements a number of methods (called queries) that you can easily call to train models, infer results, etc.
Libra的客户端类是中心类,它实现了许多方法(称为query ),您可以轻松地调用它们来训练模型,推断结果等。
Here is a list of the currently available models and tasks in Libra 1.1.2, which I will cover in more detail in this article:
这是Libra 1.1.2中当前可用的模型和任务的列表,我将在本文中对其进行详细介绍:
- Neural networks (classification) 神经网络(分类)
- Support Vector Machines 支持向量机
- Decision trees 决策树
- Nearest neighbors 最近的邻居
- Neural networks (regression) 神经网络(回归)
- XGBoost XGBoost
- K-means clustering K均值聚类
- Convolutional neural networks 卷积神经网络
- Text classification 文字分类
- Text summarization 文字摘要
- Caption Generation 字幕生成
- Text generation 文字产生
- Named entity recognition 命名实体识别
Along with each query, I will link some documentation so that you can have a more detailed view of the task/model. Let me specify that I am running every model on Google Colab.
与每个查询一起,我将链接一些文档,以便您可以更详细地了解任务/模型。 让我指定我正在Google Colab上运行所有模型。
I will try as much as possible to use a variety of datasets and problems to solve for the different tasks. Personally, Libra got me extremely excited with the NLP-related queries, so don’t hesitate to check out the queries that interest you the most!
我将尽可能尝试使用各种数据集和问题来解决不同的任务。 就个人而言,天秤座让我对与NLP相关的查询感到非常兴奋,所以请立即检查最感兴趣的查询!
分类 (Classification)
1.神经网络(分类) (1. Neural networks (classification))
Before anything, make sure to understand to core components of neural networks as well as their mechanisms. There is a ton of online documentation about feedforward neural networks in their most basic form (here, here and here), make sure to check it out.
在开始之前,请务必了解神经网络的核心组件及其机制 。 有大量关于前馈神经网络的最基本形式的在线文档( 此处 , 此处和此处 ),请务必检查一下。
To demonstrate classification, I will model constructiveness in Amazon reviews (4000 reviews) with Libra’s neural network. I have worked on a similar task in a previous article and in my master’s thesis (in which I describe the dataset in more details), in case you are interested.
为了演示分类,我将使用Libra的神经网络对亚马逊评论 (4000条评论)中的构造性进行建模 。 如果您有兴趣的话, 我在上一篇文章和我的硕士论文中 (我在其中更详细地描述了数据集)从事过类似的任务。
This this what the dataset looks like:
这就是数据集的样子:
You can perform classification in Libra with the classification_query_ann() method from the client object. It automatically calls a data reader, fits your data, evaluates performance on a subset of your data, and displays plots of the training process.
您可以在Libra中使用来自客户端对象的category_query_ann()方法执行分类。 它会自动调用数据读取器,拟合您的数据,评估部分数据的性能,并显示训练过程的图。
The following code calls the neural network. Notice that you can drop .csv columns with the drop argument and embed text columns with the text argument:
以下代码称为神经网络。 请注意,您可以使用drop参数放置.csv列 ,并使用text参数嵌入文本列 :

The Keras neural network is composed of an input Dense layer, a main Dense layer with 64 neurons and ReLU activation, and an output softmax layer. Pretty straight forward, unless…
Keras神经网络由一个输入密集层,一个具有64个神经元和ReLU激活的主密集层以及一个输出softmax层组成。 挺直截了当的,除非…
After the first training, re-training are performed by adding more Dense layers to the architecture until we have maximized the validation accuracy.
在第一次训练之后, 通过向体系结构添加更多的密集层来执行重新训练,直到我们使验证准确性最大化。

The model is then available in your client object for predictions and analysis. You can of course run a new query to tweak the epochs hyperparameter, the resulting model will also be stored in the client object!
然后可以在客户对象中使用该模型进行预测和分析。 您当然可以运行新查询来调整历元超参数,生成的模型也将存储在客户端对象中!
The analyze() method gives us statistics about best trained model:
analytics()方法为我们提供了有关最佳训练模型的统计信息:

Results seem to be rather good on the test set (20% of the original .csv file by default). Test statistics are really comprehensible and quite visual, which is another one of Libra’s strengths.
测试集上的结果似乎不错(默认情况下,原始.csv文件的20%)。 测试统计信息确实可以理解并且非常直观,这是天秤座的另一项长处。
2.支持向量机 (2. Support Vector Machines)
SVMs have consistently been used to solve machine learning problems in the past decades, especially in regression and classification tasks.
在过去的几十年中,SVM一直用于解决机器学习问题,尤其是在回归和分类任务中。
They basically rely on the following simple geometric concept: draw a line (or hyperplane in higher dimensions) so that the space between the data points of each class in the dataset and this line is maximized.
他们基本上依赖于以下简单的几何概念:画一条线(或在更高维度上的超平面),以便使数据集中每个类的数据点与该线之间的空间最大化 。
Support Vectors are of course well documented (here, here). I will repeat it through the rest of the article, make sure to understand the math behind the models, it will help you on the long run.
支持向量当然有据可查( 此处 此处 )。 我将在本文的其余部分中重复一遍,确保了解模型背后的数学原理 ,从长远来看将为您提供帮助。
Libra relies on Scikit-learn’s implementation in its query, which is widely used by data scientists and engineers. This great documentation will teach you what you need to know.
Libra在其查询中依赖Scikit-learn的实现,该查询已被数据科学家和工程师广泛使用。 这份出色的文档将教您需要了解的内容。
Once again, the strength of this framework is the wrapping technique that allows your to process your raw document all at once. Check the code to know more about the different query arguments.
同样,此框架的强项是包装技术,使您可以一次处理所有原始文档 。 检查代码以了解有关不同查询参数的更多信息。
I will again use the Amazon Reviews dataset to compare performance with the neural networks. The code below is very similar to the previous one, with drop and embed the same columns, and I simply switched the kernel from “linear” to “rbf”, sklearn’s default.
我将再次使用Amazon Reviews数据集将性能与神经网络进行比较。 下面的代码与上一个代码非常相似,只不过在 drop并嵌入了相同的列,我只是将内核从 sklearn的默认设置从“ linear”切换为“ rbf ” 。
The following results show that the non-neural Support Vector Machine is slightly less effective with this hyperparameter combination than the feedforward neural network, on this particular dataset. I leave you the pleasure to tune your model as best as you can on your own dataset.
以下结果表明,在该特定数据集上,这种超参数组合的非神经支持向量机的有效性略低于前馈神经网络 。 我很高兴能在自己的数据集上尽可能地优化模型。

3.决策树 (3. Decision trees)
Continuing with classification, decision trees are widely used because of a great possibility to interpret results.
继续进行分类,由于很有可能解释结果 ,因此决策树被广泛使用。
Indeed, unlike neural networks or other algorithms like SVM, decision trees rely on a series of simple YES/NO questions to progressively divide the data points in and make predictions, hence forming a tree shape.
确实,与神经网络或其他算法(如SVM)不同,决策树依靠一系列简单的是/否问题来逐步将数据点划分并做出预测,从而形成树形。
A lot of literature is available online for decision trees(here, here), which are the base for more complex models like Gradient Boosting, which I will talk about later on.
网上有很多关于决策树的文献( 这里是here ),它们是更复杂的模型(例如Gradient Boosting)的基础,我将在稍后讨论。
Decision trees usually allow a series of interesting hyperparameter to tweak, like the maximum depth of the tree, the maximum number of nodes, etc. Since Libra uses Scikit-learn to train the model, you have access to these.
决策树通常允许调整一系列有趣的超参数,例如树的最大深度,最大节点数等。由于Libra使用Scikit-learn训练模型,因此您可以使用它们。
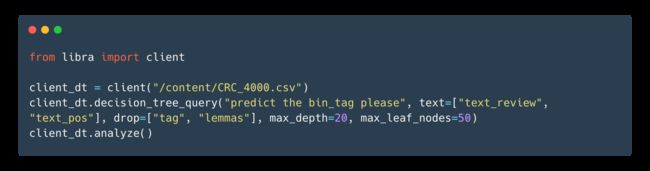

Okay, it seems like DT are not adapted to classifying something as complex and subjective as the constructiveness of a review. Neural networks usually manage to better capture textual relationship, so perhaps more feature engineering would boost the DT results.
好的,似乎DT不适合将评论的建设性归类为复杂和主观的事物 。 神经网络通常设法更好地捕获文本关系 ,因此也许更多的功能工程将提高DT结果。
4.最近的邻居 (4. Nearest neighbors)
As its name suggests, the nearest neighbors algorithm relies on distances between data points. It can be used either for clustering (unsupervised), classification or regression (supervised), making it an extremely simple yet versatile model.
顾名思义,最近邻居算法依赖于数据点之间的距离。 它可以用于聚类(无监督),分类或回归(有监督),使其成为极其简单而通用的模型 。
For more explanations about nearest neighbors, check out the great documentation by scikit-learn. Libra uses this framework to train and run a classification nearest neighbors algorithm, so I’ll only focus on this part here.
有关最近邻居的更多说明,请查看scikit-learn的出色文档 。 天秤座使用此框架来训练和运行分类最近邻居算法,因此在这里我仅关注这部分。
To illustrate the nearest neighbor algorithm in Libra, I will again use the Amazon review constructiveness dataset to compare results with the previously evaluated neural network, SVM and DT queries.
为了说明天秤座中最接近的邻居算法,我将再次使用Amazon评论构造性数据集将结果与先前评估的神经网络,SVM和DT查询进行比较。
Don’t hesitate to tweak the available hyperparameters to your convenience and depending on your input data!
不要犹豫,根据您的输入数据来调整可用的超参数,以方便您使用!

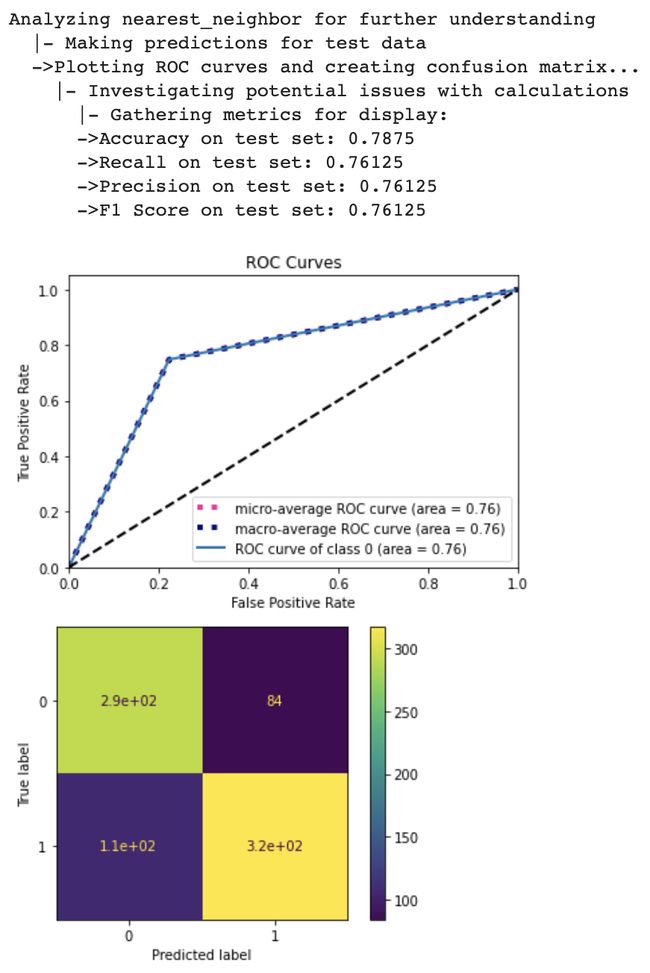
It looks like nearest neighbors are performing better than decision trees but worst than support vectors and neural networks on this particular dataset.
在这个特定数据集上,最近邻居的表现似乎比决策树要好,但比支持向量和神经网络要差。
You can access the resulting model’s configuration with the following line of code:
您可以使用以下代码行访问生成的模型的配置:
client_classif.models["nearest_neighbor"]Note that the test set varies from one model to another, since the Libra client does not keep track of the the test instance indices from one model to another.
请注意, 测试集因一个模型而异 ,因为Libra客户端不会跟踪从一个模型到另一个模型的测试实例索引。
回归 (Regression)
5.神经网络(回归) (5. Neural networks (regression))
When performing a regression task, we want to predict a continuous variable on unseen data.
在执行回归任务时,我们希望对看不见的数据预测连续变量 。
Let’s use this dataset I found on Kaggle, where the variable to predict is the housing price in the King County, USA, depending on several variables. Here is a Pandas description of the set:
让我们使用我在Kaggle上找到的数据集 ,其中要预测的变量是美国金县的房价 ,具体取决于几个变量。 这是该集的熊猫描述:

With Libra, you can either use the neural_network_query() method that will deduce by itself that you are requesting a regression task from your target variable. You can also use the regression_query_ann() directly.
使用Libra,您可以使用Neuro_network_query()方法,该方法将自己推断出您正在从目标变量中请求回归任务。 您也可以直接使用gression_query_ann() 。
Here is the code to load the data, train a feedforward neural network (running a Keras model and techniques similar to the classification NN under the hood), and analyze/visualize the results:
这是加载数据,训练前馈神经网络( 运行Keras模型和类似于引擎盖下的分类NN的技术 )以及分析/可视化结果的代码:

For the sake of convenience, I did not perform an in-depth EDA, feature engineering, imputing, etc. I simply removed the columns that I judged non-essential.
为了方便起见, 我没有进行深入的EDA ,功能工程,估算等工作。我只是删除了我认为不重要的列。
The query automatically imputes missing values and scales the different variables, meaning that you are relatively free to feed the network with non flawless datasets.
该查询会自动估算缺失值并缩放不同的变量 ,这意味着您可以相对自由地为网络提供无缺陷的数据集。
This is the output of the three lines of code:
这是三行代码的输出:
Not bad! Libra outputs a series of testing statistics (MSE, MEA) as well a training/evaluation loss plot. Your model and several variables are automatically saved in your client instance, which makes it easy to reuse.
不错! 天秤座输出一系列测试统计数据(MSE,MEA)以及训练/评估损失图。 是的, 我们的模型和几个变量会自动保存在您的客户端实例中,这使得重用变得容易。
You can set aside part of the data for more inference, I let you try by yourself. Remember that Libra is still in development, so please be patient if you encounter bugs, or not yet implemented features.
您可以保留部分数据以进行更多推断,我让您自己尝试。 请记住, Libra仍在开发中 ,因此如果遇到错误或尚未实现的功能,请耐心等待。
6. XGBoost (6. XGBoost)
If you know Kaggle and its competitions, then you must be somewhat familiar with the XGBoost and Gradient Boosting Machine algorithms (here is the difference between these two).
如果您了解Kaggle及其竞争对手 ,那么您必须对XGBoost和Gradient Boosting Machine算法有所了解 ( 这是这两者之间的区别)。
In the past years, boosting algorithms have largely contributed to result enhancement for regression and classification tasks, making them practically inevitable.
在过去的几年中,增强算法在很大程度上增强了回归和分类任务的结果, 实际上使其不可避免 。
This amazing documentation explains everything you need to know to understand and use XGBoost.
这个惊人的文档解释了理解和使用XGBoost所需的一切。
Libra uses the XGBoost library adapted for the Scikit-learn API, so if you have already implemented and run a Gradient Boosting Machine with sklearn you shouldn’t be confused by the available hyperparameters.
Libra使用适合Scikit-learn API的XGBoost库,因此,如果您已经使用sklearn实现并运行了Gradient Boosting Machine,则不要为可用的超参数感到困惑。
Since XGB is extremely powerful on regression tasks, I will load and use the same data as with neural networks, about housing prices.
由于XGB在回归任务上非常强大,因此我将加载和使用与神经网络相同的数据,用于房价。

Unfortunately, at the time I write this article, the XGBoost query seems to be running indefinitely on Google Colab, so I am currently unable to provide an output for this. Stay tuned for results, or simply try it out on your own environment!
不幸的是,在我撰写本文时,XGBoost查询似乎在Google Colab上无限期运行,因此我目前无法提供输出。 请继续关注结果,或者只是在自己的环境中尝试一下 !
聚类 (Clustering)
7. K-均值聚类 (7. K-means clustering)
Clustering is an unsupervised machine learning technique used to group data points into an arbitrary number of clusters.
群集是一种无监督的机器学习技术,用于将数据点分组为任意数量的群集 。
‘Unsupervised’ techniques assume that you data is unlabeled, therefore these algorithms won’t be precise when classifying data or modeling a continuous variable, but are very useful to detect patterns in the data, hence drawing the boundaries between several groups/clusters.
“无监督”技术假定您的数据没有标签,因此在对数据进行分类或对连续变量建模时,这些算法并不精确,但是对于检测数据中的模式非常有用 ,因此可以绘制多个组/群集之间的边界。
Although it is less popular than classification, QA or NER, it is still interesting to see how you can get insights on your data with 3 simple lines of code.
尽管它不如分类,QA或NER流行,但仍然有趣的是,您如何通过3条简单的代码行就能洞悉数据。
You can find more detailed information about the K-means clustering algorithm in this article. Basically, the “K” in K-means decides on the number of centroids to which the data points can be assigned.
你可以找到关于K-手段聚类算法更详细的信息, 这篇文章 。 基本上,K均值中的“ K”决定可以分配数据点的质心数 。
I will use the Credit Card dataset found on Kaggle to hopefully find patterns in the data. Make sure to check it out and to try it out yourself.
我将使用Kaggle上的信用卡数据集来希望找到数据中的模式。 确保检查出来并自己尝试。
The best would be to perform feature engineering in order to properly scale each feature, remove potential outsiders, imputing missing values, etc. Libra of course handles these parts in a generic way, but understanding features and how to get more out of them is a great exercise.
最好的方法是进行特征工程设计,以正确缩放每个特征,删除潜在的局外人,插补缺失值等。天秤座当然会以通用方式处理这些零件,但是了解特征以及如何从中获得更多收益是很好的锻炼。
As usual, we can simply feed our client object with our unprocessed dataset. Since the task is unsupervised, you do not need to tell Libra which target variable you want to model, there is none!
像往常一样,我们可以简单地将未处理的数据集提供给客户对象。 由于任务是不受监督的,因此您无需告诉Libra您要建模的目标变量,就没有了!
The algorithm has found that 18 was the number of clusters that minimized inertia, which the the metric Libra uses for clustering.
该算法发现,有18个是使 惯性 最小化的簇数,该度量是天秤座用于聚类的度量。
Once again, as of today I was unable to perform inference with Libra models since the framework is still in development and unfinished, so let’s be patient.
再次,由于该框架仍在开发中并且尚未完成,因此直到今天,我仍无法使用Libra模型进行推断,所以请耐心等待。
图像处理 (Image Processing)
8.卷积神经网络 (8. Convolutional neural networks)

If convolutional neural networks have been around for a while now and are still offering good results, it is not due to chance.
如果卷积神经网络已经存在了一段时间并且仍能提供良好的结果,那不是偶然的。
The convolution technique in neural networks, very well explained in this article, allows to pick up patterns in different types of data, more specifically images (hence videos) and text.
本文非常详细地介绍了神经网络中的卷积技术,该技术允许拾取不同类型的数据中的模式,尤其是图像(因此是视频)和文本。
Libra implements CNNs for image classification, and is quite convenient in order to automatically preprocess your data. You can basically pass the paths to all your images to the query, and it will do the rest.
Libra实现CNN用于图像分类,并且非常方便地自动预处理数据 。 您基本上可以将所有图像的路径传递给查询,其余的将由它完成。
The documentation says that there are 3 possible modes to read your data depending on how your image data folders are arranged, if you have divided training and test sets, etc.
该文档说,根据图像数据文件夹的排列方式(如果您将训练和测试集分开)等三种方式可以读取数据。
Another cool thing is that you can choose to use an already existing model architecture such as ResNet50, VGG19… along with pre-trained weights from ImageNet.
另一个很酷的事情是,您可以选择使用现有的模型架构,例如ResNet50,VGG19…以及ImageNet的预训练权重 。
To demonstrate, I will use the data found in the Libra GitHub repository, which consists in pictures of 42 written letters (a, A, b, B, c, d in Libra 1.1.2). The amount of images is really small and therefore not sufficient to train a good or great image classification model, but this will do for now.
为了演示,我将使用在Libra GitHub存储库中找到的数据,该数据包含42个书面字母(在Libra 1.1.2中为a , A , b , B , c , d )的图片。 图像的数量确实很小,因此不足以训练一个好的或很好的图像分类模型,但是现在就可以了。
The show_feature_map argument allows you to actually see what’s going on inside each layer of the model, which is really nice and can inform you about the inner workings of a CNN (I do not include it here since the display is quite large).
使用show_feature_map参数,您可以实际查看模型各层内部的情况,这非常好,并且可以通知您CNN的内部工作原理 (由于显示很大,因此在此不包括它)。
As usual, you can access the trained model in your client object, along with test statistics.
像往常一样,您可以在客户对象中访问经过训练的模型以及测试统计信息。

自然语言处理 (Natural Language Processing)
9.文字分类 (9. Text classification)
Text classification is one of the most popular machine learning tasks for several reasons:
文本分类是最受欢迎的机器学习任务之一,原因如下:
- Text is everywhere, especially online, which gives us a good excuse to do things with it. 文本无处不在,尤其是在线文本,这为我们提供了处理文本的良好借口。
The task itself is rather rudimentary and asks for a simple output.
任务本身很基本 ,需要简单的输出。
The data is unstructured by nature, and therefore challenging to process and learn from with non-complex tools.
数据本质上是非结构化的,因此使用非复杂工具进行处理和向其学习具有挑战性 。
- The real world applications are numerous (sentiment analysis, spam detection, polarity detection, language detection, etc.) 现实世界中的应用程序很多(情感分析,垃圾邮件检测,极性检测,语言检测等)。
What Libra calls text classification corresponds to sentiment analysis. It implements a Keras LSTM-based model, composed of an embedding layer, a recurrent layer with 128 units, and an output layer for classification.
天秤座所说的文本分类与情感分析相对应。 它实现了基于 Keras LSTM 的模型 ,该模型由嵌入层,具有128个单位的循环层和用于分类的输出层组成。
I will use the super famous IMDb sentiment analysis dataset to illustrate Libra’s text classification query.
我将使用超级著名的IMDb情感分析数据集来说明Libra的文本分类查询。

I had to adapt the dataset a tiny bit, shorten it and replace the target column name, but the essential is here.
我不得不稍微修改一下数据集,将其缩短并替换目标列名称,但是关键在这里。
Training typically takes a very long time even though the model is rather small, because Libra currently allows an argument “max_features” to limit the vocabulary size, but does not actually use this limit during tokenization, therefore causing errors when set too low and memory inefficiency when set high enough.
即使模型很小,训练通常也要花费很长时间,因为Libra当前允许参数“ max_features”限制词汇量,但实际上在标记化过程中并未使用此限制,因此,在设置得太低时会导致错误,并且内存效率低下当设置得足够高时。

Well, the results are not great and this would deserve some hyperparameter tuning among other things, but you get the idea. Simply try it out yourself with your own dataset!
好吧,结果不是很好,这值得进行一些超参数调整,但是您明白了。 只需使用自己的数据集尝试一下 !
Once your model is trained and stored in the client object, you can actually use it with the predict() method or the classify_text() method (the former calls the latter), as such:
一旦训练好模型并将其存储在客户端对象中, 您就可以将其实际用于 predict()方法或classify_text()方法(前者调用后者),如下所示:
>>> text_class_client.classify_text("I loved this movie!!!")
# 'positive'10.文字摘要 (10. Text summarization)
There are two main types of summarization:
汇总有两种主要类型:
Extractive summarization: spotting the interesting parts of a given text and concatenating them.
摘录摘要 : 发现给定文本的有趣部分并将其连接起来。
Abstractive summarization: Actually understanding (NLU) what the text is about and expressing it thanks to Natural Language Generation (NLG).
抽象性摘要 : 实际理解 (NLU)文本的含义并通过自然语言生成 (NLG)进行表达。
No need to say that abstractive summarization is way harder to perform since it relies on making actual sense of what is happening in the text and encapsulate the whole thing in an understandable way.
不必说抽象摘要很难执行,因为它依赖于实际理解文本中发生的事情并以一种可理解的方式封装整个内容。
With abstractive summarization we enter the world of AI, that doesn’t care about probabilities but only tries to reproduce humans’ ability to understand, create, reason.
通过抽象总结, 我们进入了AI领域,它不在乎概率,而仅试图重现人类理解,创造和推理的能力。
With the rapid rise of Transformers and Transfer-learning, text summarization is making big steps forward (keep track of the field’s research here).
随着变形金刚的Swift崛起和转让学习,文摘正在大步向前(该领域的研究,跟踪在这里 )。
Libra uses the T5 pre-trained model (small) [1] implemented in HuggingFace’s transformers library to perform summarization.
天秤座使用在HuggingFace的转换器库中实现的T5预训练模型(小)[1]进行汇总。
Datasets for abstractive text summarization are currently hard to find, but you can already try it with the sample provided by Libra. Let’s download it from their GitHub repository and fine-tune the T5 model on it. On Google Colab, this is easily doable with:
当前很难找到用于抽象文本摘要的数据集,但是您已经可以使用Libra提供的示例进行尝试。 让我们从其GitHub存储库下载它,并在其上微调T5模型。 在Google Colab上,这很容易做到:
!git clone https://github.com/Palashio/libra.gitNow let’s fine-tune that beast on the available couple of samples:
现在让我们在可用的几个样本上微调该野兽:
Keep in mind that this is merely an example aiming at teaching Libra’s mechanism, I am definitely not trying to reach state-of-the-art performance.
请记住,这只是一个旨在教授天秤座机制的示例,我绝对不会试图达到最先进的性能。
Nevertheless, the huge advantage of pre-trained transfer learning-based models is that even with very few fine-tuning, the model will still be able to have a global language understanding and will probably perform decently on most tasks.
尽管如此, 基于预训练的基于转移学习的模型的巨大优势在于, 即使进行了很少的微调,该模型仍将具有全局语言理解能力,并且可能会在大多数任务上表现出色。

Inference time!
推断时间!
You can access the model in you client object with the get_summary() method. To illustrate, I will summarize the first 3 paragraphs from J.K. Rowling’s Harry Potter and the Sorcerer’s Stone.
您可以使用get_summary()方法访问客户端对象中的模型。 为了说明这一点,我将总结JK罗琳的《 哈利·波特》和《魔法石》的前三段 。
Here is the result:
结果如下:

I find it pretty impressive how the generation model handled coreferences. “…were the last people you’d expect to be involved in anything strange or mysterious, because they just didn’t hold with such nonsense” appears in both original and inferred samples, but the model used “the Dursleys” instead of “they” or “Mr. and Mrs. Dursley”.
我发现令人印象深刻的是,生成模型如何处理共指 。 “ …是您最后希望参与到任何奇怪或神秘的事情上的人,因为他们只是对这些胡说八道不抱有诚意 ”出现在原始样本和推断样本中,但模型使用“ Dursleys”代替“他们”或“先生 和杜斯利夫人”。
Similarly, the pronoun“they” is used in the second sentence and refers to the noun phrase “the Dursleys” from the first sentence, hence forming perfectly ordered English sentences.
同样,第二句中使用了代词“ they”,并从第一句中引用了名词短语“ Dursleys”,从而形成了完全有序的英语句子 。
The rest is simply extracted from the original text, and unfortunately we currently have no control over the maximum output length. I strongly encourage you to read the paper [1] to understand how T5 works, and try it yourself with the Transformers library.
其余的只是从原始文本中提取的,不幸的是,我们目前无法控制最大输出长度。 我强烈建议您阅读论文 [1]以了解T5的工作原理,并在Transformers库中自己尝试一下。
11.字幕生成 (11. Caption Generation)
Caption generation is a pretty interesting task that mixes image analysis and natural language generation, two of the currently hottest research topics.
字幕生成是一项非常有趣的任务,它将图像分析和自然语言生成 (当前最热门的两个研究主题)混合在一起。
Libra uses InceptionV3 to perform this task and implements a CNN-RNN architecture to infer textual descriptions from visual patterns (the CNN is the encoder while the RNN is the decoder).
Libra使用InceptionV3来执行此任务,并实现了CNN-RNN体系结构以从视觉模式推断文本描述 (CNN是编码器,而RNN是解码器)。
This article explains well how the model works internally, as described in the original paper [2] Make sure to read it if you’re interested in the task and want to implement something of that kind!
本文很好地解释了该模型如何在内部工作,如原始论文所述[2]。如果您对任务感兴趣并想实现这种类型,请务必阅读它!
Don’t hesitate to check the code directly in Libra’s repository to better understand how the caption generator is trained. This query contains a lot of custom code although it heavily relies on TensorFlow and Keras, which is interesting if you want to take it as an example to implement your own project.
不要犹豫,直接在Libra的存储库中检查代码,以更好地了解字幕生成器的训练方式。 尽管此查询很大程度上依赖于TensorFlow和Keras ,但它包含很多自定义代码,如果您希望以它为例来实现自己的项目,这将很有趣。
Several datasets are publicly available for that task, like the VizWiz dataset or the COCO dataset, along with challenges.
可以针对该任务公开使用多个数据集,例如VizWiz 数据集或COCO数据集 ,以及挑战。
Unfortunately, at the time of writing the implementation of the caption generation query is unsuccessful for me, but hopefully the issue will soon be solved. The implementation is supposed to work as follows:
不幸的是,在撰写本文时,字幕生成查询的实现对我来说是不成功的,但希望该问题能尽快解决。 该实现应按以下方式工作:
You can pass a .csv file to the client object, which holds a column with paths to the images, and a column with captions.
您可以将.csv文件传递到客户端对象,该对象包含一列包含图像路径 的列和一列具有标题的列 。

Don’t hesitate to play with hyperparameters such as epochs, top_k (maximum number of words in the vocabulary), embedding_dim and units (number of recurrent units in the decoder).
不要犹豫与超参数,如时代 ,top_k(在词汇的最大数量)来播放,embedding_dim和单位 (在解码器数量复发单位)。
12.文本生成 (12. Text generation)
In my previous article about Libra, I used text generation as an example to show the framework’s user-friendliness.
在上一篇有关Libra的文章中,我以文本生成为例来说明框架的用户友好性。
Instead of spending hours learning how to use a transformer-based language models to generate text with TF or PyTorch, using the generate_text() query will allow you to call Open-AI’s GPT-2 pre-trained model (12 layers, 117M parameters) and generate as much text as you want, all that with one line of code.
无需花费大量时间来学习如何使用基于转换器的语言模型来通过TF或PyTorch生成文本,而是使用generate_text()查询可以调用Open-AI的GPT-2预训练模型( 12层,117M参数 )并用一行代码生成尽可能多的文本。
You can load a file with the .txt extension as a base for text generation, or simply use the prefix query argument as the text seed.
您可以加载扩展名为.txt的文件作为生成文本的基础,也可以简单地使用前缀查询参数作为文本种子。
Here’s a concrete example: I loaded the very beginning of Tolkien’s Silmarillion and called the text generation query.
这是一个具体示例:我加载了Tolkien的Silmarillion的开始,并称为文本生成查询。
And the results (the first paragraph of the following text is the input, the rest is generated by this pre-trained GPT-2):
和结果(以下内容的第一段为输入,其余内容由 该预训练的GPT-2生成 ):
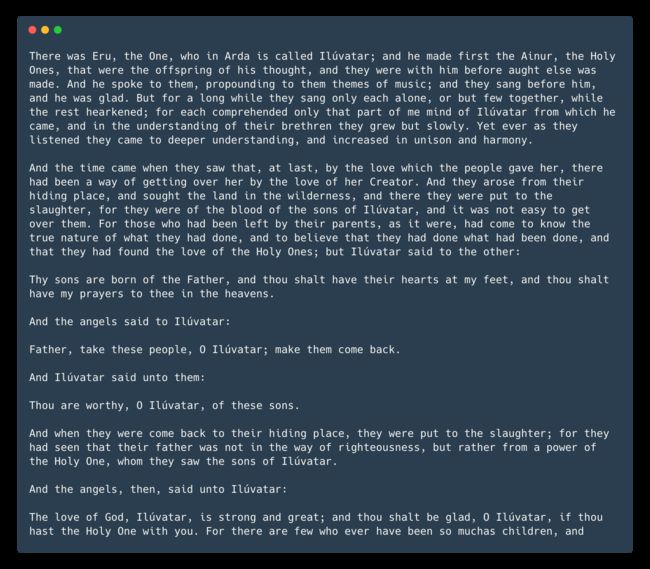
Pretty amazing, right? Even though you can tell that something is wrong with the long term meaning of the story, the grammar is quite neat and it would be hard to tell if a human or a machine wrote each sentence individually.
太神奇了吧? 即使您可以说故事的长期含义出了点问题,但语法还是很整洁的, 很难分辨是人还是机器分别写了每个句子。
You can also change the maximum output length, top-K selected words for next word prediction, etc. Libra’s GPT-2 uses Top-K sampling decoding coupled with Top-P sampling, on which you can find more information [xx].
您还可以更改最大输出长度,用于下一单词预测的top-K个选定单词等。Libra的GPT-2使用Top-K采样解码和Top-P采样相结合 ,可在其中找到更多信息[xx] 。
13.命名实体识别 (13. Named entity recognition)
Named entity recognition (NER) is a sequence labelling task aiming at detecting, chunking or extracting named entities from a text, such as places, names, organizations, genes, etc.
命名实体识别(NER)是一个序列标记任务,旨在检测,分块或从文本中提取命名实体,例如位置,名称,组织,基因等。
A lot of resources are available online (here, here) to understand the ins and outs of the tasks. A currently popular real life use case is related to medical world and aims at extracting medical entities from patient records, for example.
在线(此处为此处)有大量资源可用于了解任务的来龙去脉。 例如,当前流行的现实生活用例与医学界有关,其目的是从患者记录中提取医学实体 。
NER implemented in Libra is pretty straightforward, and simply loads an NER pipeline from HuggingFace’s Transformers library. Make sure to understand how NER models work though.
在Libra中实现的NER非常简单,只需从HuggingFace的Transformers库中加载NER管道即可。 不过,请务必了解NER模型的工作原理。
You can simply load any .csv that contains a textual column, and call the named_entity_query() method with an instruction that determines which column will be studied.
您可以简单地加载任何包含文本列的.csv,然后使用一条确定要研究哪一列的指令来调用named_entity_query()方法。
For demonstration I will just create a tiny dataset with Pandas.
为了演示,我将使用Pandas创建一个很小的数据集。
As you can see from the results, the transformers pipeline uses BERT for TensorFlow along with a BERT tokenizer. You can also notice that for this (rather simple) text sample, entities were correctly attributed to tags (I-PER, I-LOC, etc).
从结果中可以看到,转换器管道将BERT用于TensorFlow以及BERT令牌生成器 。 您还可以注意到,对于此(相当简单)的文本示例,将实体正确地归属于标签(I-PER,I-LOC等)。

下一步是什么? (What’s next?)
Obviously there are many more ML tasks available out there, some of which are nowadays at the very center of the research, like Question Answering, for example.
显然,现在还有更多的ML任务可用,其中一些是当今研究的核心,例如Question Answering。
I believe that the Libra development team has great projects for their framework and that, with some time on their hands, all current issues will be fixed.
我相信天秤座的开发团队会为其框架制定出色的项目,并且将花费一些时间解决所有当前问题。
More generally, more modularity and robustness in the implementation would be great additions to Libra, along with an inference system that should be as easy as the training system.
更一般地,实施中的更多模块性和鲁棒性将是对Libra的极大补充,以及应该像训练系统一样容易的推理系统 。
For instance, simply dividing your data and testing the different models in a couple more lines of code wouldn’t hurt, and would allow beginners and intermediates to actually visualize concrete results.
例如,仅需分割数据并在多行代码中测试不同的模型,就不会有什么坏处,并且可使初学者和中级人员实际看到具体结果 。
More thorough tests would also be welcome to avoid a good load of bugs, not implemented methods and dependency conflicts, and I guess that will simply happen as the project grows, so no worries on this side.
我们也欢迎进行更彻底的测试,以避免大量的bug ,未实现的方法和依赖冲突,并且我想这会随着项目的发展而发生,因此,这方面无需担心。
On the positive side, Libra’s creator indicated in a LinkedIn post that more state-of-the-art research oriented stuff would be added to the library, which is really promising and I’m excited to see all of this happen!
从积极的方面来说,天秤座的创建者在LinkedIn文章中指出,将在图书馆中添加更多最先进的面向研究的资料 ,这确实很有希望,我很高兴看到所有这些事情发生!
结论 (Conclusion)
Libra offers a quite impressive collection of queries that make it relatively easy to get acquainted with different tasks, models and concepts (assuming that you don’t encounter any bug and that you have a well formatted CSV file for training and another one for inference).
Libra提供了非常令人印象深刻的查询集合,使您相对容易熟悉不同的任务,模型和概念 (假设您没有遇到任何错误,并且您有一个格式正确的CSV文件用于训练,而另一个则用于推理) 。
Of course, reaching a good balance between generalization and simplicity is ambitious.
当然,要在一般性和简单性之间取得良好的平衡是雄心勃勃的。
Do we actually want to be able to implement ANY machine learning task with ANY data in a few lines of code?
我们是否真的希望能够用几行代码中的任何数据来实现任何机器学习任务?
You might think that this leads to the “easy way” to do machine learning, and I definitely agree with you. Getting your hands dirty with frameworks like TF or PT will allow you to develop much better skills on the long run.
您可能会认为这导致进行机器学习的“简便方法”,我绝对同意您的观点。 从长远来看,使用 TF或PT之类的框架可以使您的手变得肮脏。
On the other hand, Libra grants access to state-of-the-art models and implementations to basically anyone and extremely fast, which I see as an excellent way get started and actually visualize what you’re doing.
另一方面,Libra允许任何人以极其快速的方式访问最先进的模型和实现,我认为这是入门并实际可视化您正在做的事情的绝佳方法 。
Thank you so much for reading through this article, I hope you took as much pleasure reading as I did writing it. Going through all these models and tasks taught me so much and I’m grateful to have wonderful people getting interested in reading about ML, AI, NLP and so on. Take care and see you soon!
非常感谢您阅读本文,希望您像阅读本文一样愉快。 通过所有这些模型和任务,我学到了很多东西,我很高兴有很棒的人对阅读ML,AI,NLP等感兴趣。 保重,很快再见!
翻译自: https://towardsdatascience.com/how-to-implement-any-machine-learning-project-with-3-lines-of-code-bf167e4c2a0b
2019机器学习代码实现