Mac上在vm虚拟机上搭建Hadoop集群并安装zookeeper hive hbase(下篇)
zookeeper
官网地址


上传一下包

解压
tar -zxvf zookeeper-3.4.9.tar.gz -C ../servers/
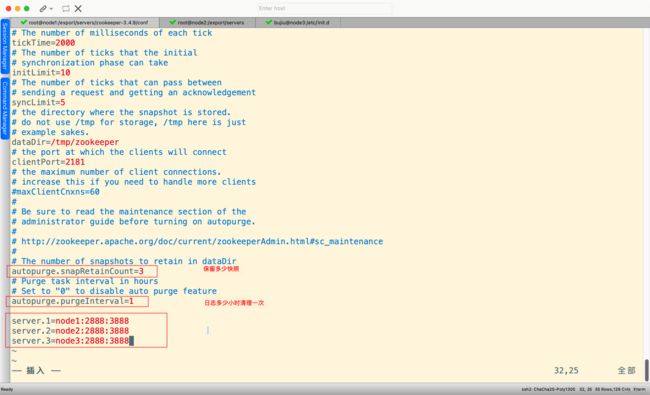
修改配置文件
cd zookeeper-3.4.9/conf/
cp zoo_sample.cfg zoo.cfg

vim zoo.cfg
添加myid配置
mkdir /export/servers/zookeeper-3.4.9/zkdatas

echo 1 > myid

安装包分发并修改myid的值
scp -r /export/servers/zookeeper-3.4.9/ node2:/export/servers/
scp -r /export/servers/zookeeper-3.4.9/ node3:/export/servers/
检查一下
把另外两台的myid改成2和3

启动服务
三台机子都要修改
cd /export/servers/zookeeper-3.4.9/conf
#这行粘贴过去,路径替换 /export/servers/zookeeper-3.4.9/zkdatas
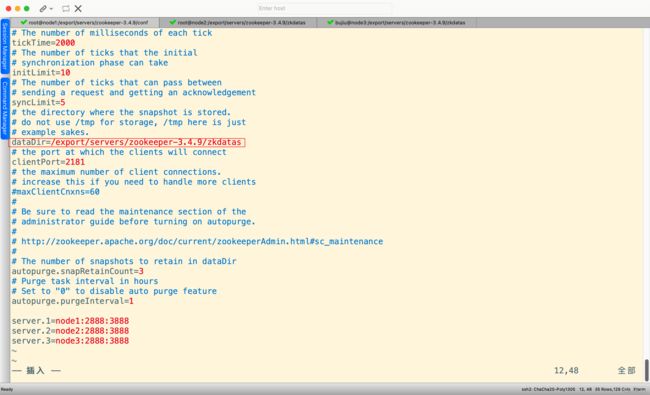
## 三台都要操作
cd /export/servers/zookeeper-3.4.9/
bin/zkServer.sh start
启动成功!
查看状态
bin/zkServer.sh status

总算成功了!!!
启动客户端
启动一个就行了
bin/zkCli.sh -server node1:2181
##或者
bin/zkCli.sh
hadoop
集群规划
| 服务器IP | 192.168.202.201 | 192.168.202.202 | 192.168.202.203 |
|---|---|---|---|
| 主机名 | node1 | node2 | node3 |
| NameNode | 是 | 否 | 否 |
| SecondaryNameNode | 是 | 否 | 否 |
| dataNode | 是 | 是 | 是 |
| ResourceManager | 是 | 否 | 否 |
| NodeManager | 是 | 是 | 是 |
官网链接
这里没用官网的,因为官方给的没有提供带C程序访问的接口,所以我们在使用本地库(本地库可以用来压缩,一级支持C程序等等)的时候会出现问题,需要重新编译。
编译后的包
第一步:上传apache hadoop包并解压
解压命令
cd /export/softwares
tar -zxvf hadoop-2.7.5.tar.gz -C ../servers/
bin/hadoop checknative
# 检查一下支持的本地库
官方给的是不支持这个snappy的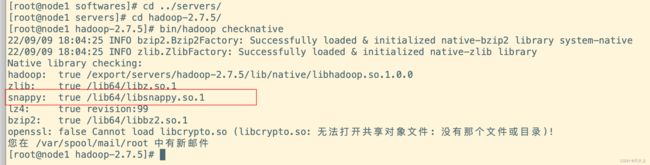
第二步:修改配置文件
这里直接用vim很不方便,win的话就用notepad++,Mac的话就用ultraEdit
修改core-site.xml
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim core-site.xml
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://node1:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/export/servers/hadoop-2.7.5/hadoopDatas/tempDatasvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>4096value>
property>
<property>
<name>fs.trash.intervalname>
<value>10080value>
property>
configuration>
修改hdfs-site.xml
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>node1:50090value>
property>
<property>
<name>dfs.namenode.http-addressname>
<value>node1:50070value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2value>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2value>
property>
<property>
<name>dfs.namenode.edits.dirname>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/nn/editsvalue>
property>
<property>
<name>dfs.namenode.checkpoint.dirname>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/snn/namevalue>
property>
<property>
<name>dfs.namenode.checkpoint.edits.dirname>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/editsvalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
<property>
<name>dfs.blocksizename>
<value>134217728value>
property>
configuration>
修改hadoop-env.sh
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
修改mapred-site.xml
发现没有这个文件,只有一个后缀加了.template的文件,复制一份重命名一下就可以了
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.job.ubertask.enablename>
<value>truevalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>node1:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>node1:19888value>
property>
configuration>
修改yarn-site.xml
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>node1value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>20480value>
property>
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>2048value>
property>
<property>
<name>yarn.nodemanager.vmem-pmem-rationame>
<value>2.1value>
property>
configuration>
修改mapred-env.sh
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim mapred-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
修改slaves
修改slaves文件,然后将安装包发送到其他机器,重新启动集群即可
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim slaves
node1
node2
node3
第一台机器执行以下命令
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/tempDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/nn/edits
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/snn/name
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/edits
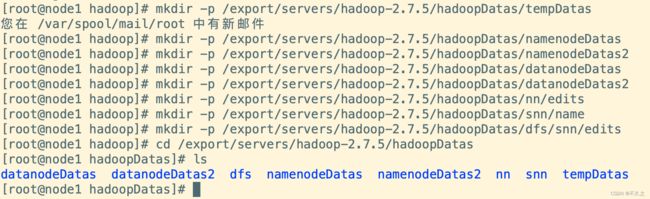
安装包的分发
第一台机器执行以下命令
cd /export/servers/
scp -r hadoop-2.7.5 node2:$PWD
scp -r hadoop-2.7.5 node3:$PWD
第三步:配置hadoop的环境变量
三台机器都要进行配置hadoop的环境变量
三台机器执行以下命令
vim /etc/profile
export HADOOP_HOME=/export/servers/hadoop-2.7.5
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
配置完成之后生效
source /etc/profile
第四步:启动集群
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个模块。
注意: 首次启动 HDFS 时,必须对其进行格式化操作。 本质上是一些清理和
准备工作,因为此时的 HDFS 在物理上还是不存在的。
hdfs namenode -format 或者 hadoop namenode –format
准备启动
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/
bin/hdfs namenode -format
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
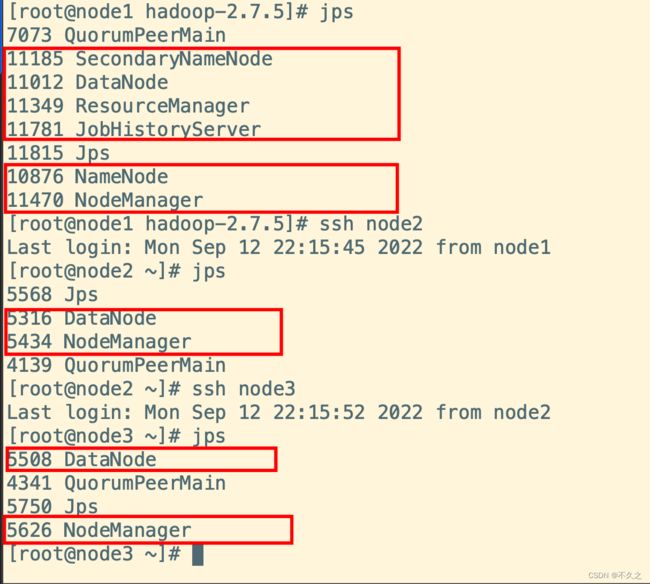
三个端口查看界面
查看hdfs:node:50070

查看yarn集群node1:8088
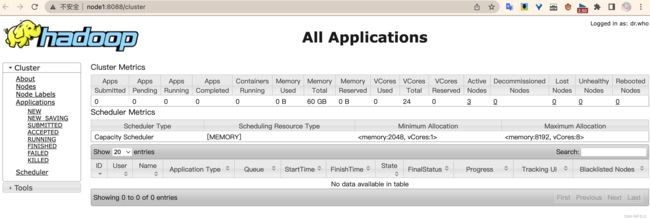
查看历史完成的任务node1:19888

Hive 的安装
这里我们选用hive的版本是2.1.1
下载地址为:
官网

下载之后,将我们的安装包上传到第三台机器的/export/softwares目录下面去
第一步:上传并解压安装包
将我们的hive的安装包上传到第三台服务器的/export/softwares路径下,然后进行解压
cd /export/softwares/
tar -zxvf apache-hive-2.1.1-bin.tar.gz -C ../servers/
第二步:安装mysql(之前已经装过)
第三步:修改hive的配置文件
修改hive-env.sh(把模版文件拷贝一份)
cd /export/servers/apache-hive-2.1.1-bin/conf
cp hive-env.sh.template hive-env.sh
HADOOP_HOME=/export/servers/hadoop-2.7.5
export HIVE_CONF_DIR=/export/servers/apache-hive-2.1.1-bin/conf
修改hive-site.xml(没有就新建)
cd /export/servers/apache-hive-2.1.1-bin/conf
vim hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>0102value>
property>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://node3:3306/hive?createDatabaseIfNotExist=true&useSSL=falsevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>hive.metastore.schema.verificationname>
<value>falsevalue>
property>
<property>
<name>datanucleus.schema.autoCreateAllname>
<value>truevalue>
property>
<property>
<name>hive.server2.thrift.bind.hostname>
<value>node3value>
property>
configuration>
第四步:添加mysql的连接驱动包到hive的lib目录下
hive使用mysql作为元数据存储,必然需要连接mysql数据库,所以我们添加一个mysql的连接驱动包到hive的安装目录下,然后就可以准备启动hive了
maven库
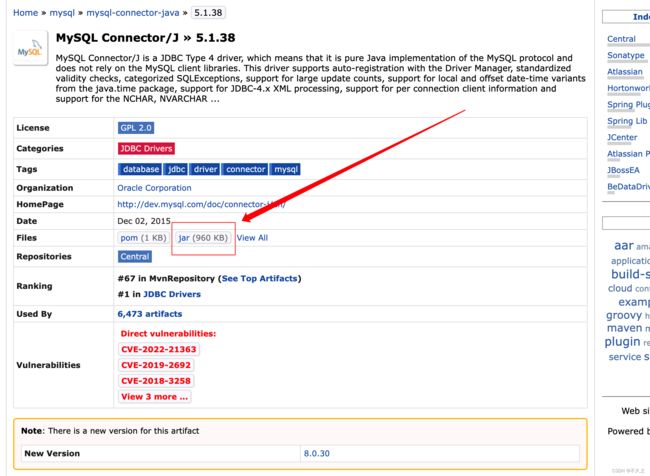
将我们准备好的mysql-connector-java-5.1.38.jar 这个jar包直接上传到
/export/servers/apache-hive-2.1.1-bin/lib 这个目录下即可
至此,hive的安装部署已经完成,接下来我们来看下hive的三种交互方式
第五步:配置hive的环境变量
node3服务器执行以下命令配置hive的环境变量
sudo vim /etc/profile
export HIVE_HOME=/export/servers/apache-hive-2.1.1-bin
export PATH=:$HIVE_HOME/bin:$PATH
source /etc/profile
测试一下
cd /export/servers/apache-hive-2.1.1-bin/
bin/hive

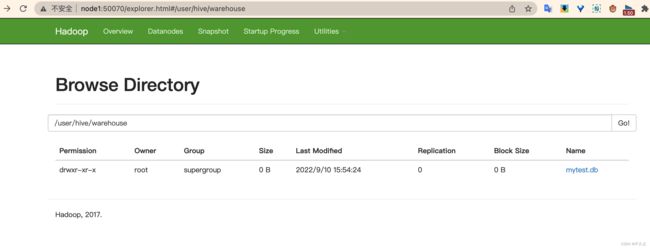
创建一个数据库
create database if not exists mytest;

hbase
官网地址

上传解压HBase安装包
tar -xvzf hbase-2.1.0-bin.tar.gz -C ../servers/
修改HBase配置文件
hbase-env.sh
cd /export/server/hbase-2.1.0/conf
vim hbase-env.sh
## 显示行 在vim里面敲
:set nu
# 第28行
export JAVA_HOME=/export/servers/jdk1.8.0_141
export HBASE_MANAGES_ZK=false
hbase-site.xml
vim hbase-site.xml
<configuration>
<!-- HBase数据在HDFS中的存放的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://node1:8020/hbase</value>
</property>
<!-- Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- ZooKeeper的地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
<!-- ZooKeeper快照的存储位置 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/export/servers/zookeeper-3.4.9/zkdatas</value>
</property>
<!-- V2.1版本,在分布式情况下, 设置为false -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
配置环境变量
# 配置Hbase环境变量
vim /etc/profile
export HBASE_HOME=/export/servers/hbase-2.1.0
export PATH=$PATH:${HBASE_HOME}/bin:${HBASE_HOME}/sbin
#加载环境变量
source /etc/profile
# 输入这个命令,输一半按tab健能联想出来就设置成功了
start-hbase.sh
复制jar包到lib
cp $HBASE_HOME/lib/client-facing-thirdparty/htrace-core-3.1.0-incubating.jar $HBASE_HOME/lib/
修改regionservers文件
vim regionservers
node1
node2
node3
分发安装包与配置文件
cd /export/servers
scp -r hbase-2.1.0/ node2:$PWD
scp -r hbase-2.1.0/ node3:$PWD
scp -r /etc/profile node2:/etc
scp -r /etc/profile node3:/etc
# 在node2和node3加载环境变量
source /etc/profile
#同理输入下面这个,能联想出来就是成功的
hbase
启动HBase
这里弄了一个一键启动zk的脚本,同理一键停止的脚本只需要把start改成stop就可以了。

ZK_HOME=/export/servers/zookeeper-3.4.9
cat /export/onekey/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;nohup ${ZK_HOME}/bin/zkServer.sh start >/dev/nul* 2>&1 &"
}&
wait
done
ZK_HOME=/export/servers/zookeeper-3.4.9
cat /export/onekey/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;nohup ${ZK_HOME}/bin/zkServer.sh stop >/dev/nul* 2>&1 &"
}&
wait
done
## 启动ZK
./start-zk.sh
## 启动hadoop
start-dfs.sh
## 启动hbase
start-hbase.sh

验证Hbase是否启动成功
# 启动hbase shell客户端
hbase shell
# 输入status
status

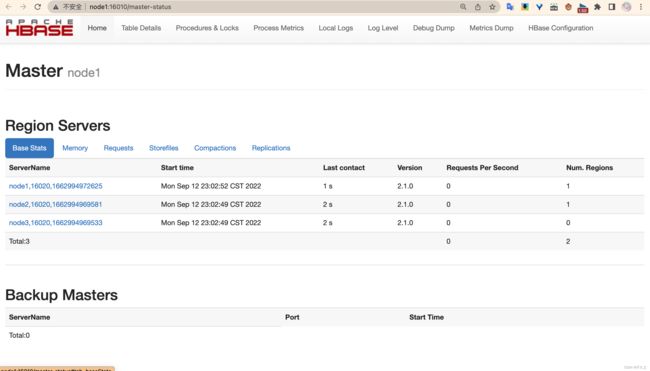
WebUI
可视化页面:node1:16010
安装Phoenix(补充)
下载
大家可以从官网上下载与HBase版本对应的Phoenix版本。对应到HBase 2.1,应该使用版本「5.0.0-HBase-2.0」。
官网地址
安装
1.上传安装包到Linux系统,并解压
cd /export/software
rz -E
tar -xvzf apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C ../servers/
2.将phoenix的所有jar包添加到所有HBase RegionServer和Master的复制到HBase的lib目录
# 拷贝jar包到hbase lib目录
cp /export/servers/apache-phoenix-5.0.0-HBase-2.0-bin/phoenix-*.jar /export/servers/hbase-2.1.0/lib/
# 进入到hbase lib 目录
cd /export/servers/hbase-2.1.0/lib/
# 分发jar包到每个HBase 节点
scp phoenix-*.jar node2:$PWD
scp phoenix-*.jar node3:$PWD
3.修改配置文件
cd /export/servers/hbase-2.1.0/conf/
vim hbase-site.xml
将以下配置添加到 hbase-site.xml 后边
<property>
<name>phoenix.schema.isNamespaceMappingEnabledname>
<value>truevalue>
property>
<property>
<name>hbase.regionserver.wal.codecname>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodecvalue>
property>
# 2. 将hbase-site.xml分发到每个节点
scp hbase-site.xml node2:$PWD
scp hbase-site.xml node3:$PWD
4.将配置后的hbase-site.xml拷贝到phoenix的bin目录
cp /export/servers/hbase-2.1.0/conf/hbase-site.xml /export/servers/apache-phoenix-5.0.0-HBase-2.0-bin/bin/
5.重新启动HBase
stop-hbase.sh
start-hbase.sh
6.启动Phoenix客户端,连接Phoenix Server
注意:第一次启动Phoenix连接HBase会稍微慢一点。
cd /export/servers/apache-phoenix-5.0.0-HBase-2.0-bin/
bin/sqlline.py node1:2181
# 输入!table查看Phoenix中的表
!table

7.查看HBase的Web UI,可以看到Phoenix在default命名空间下创建了一些表,而且该系统表加载了大量的协处理器。
8.测试
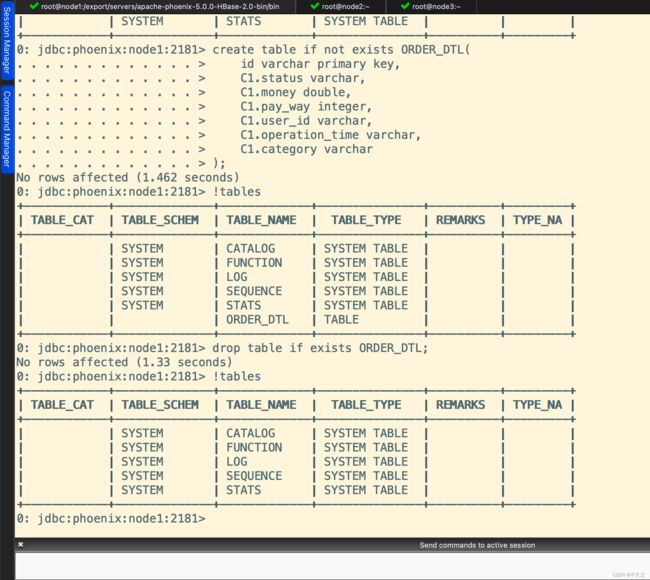
-- 1. 创建表
create table if not exists ORDER_DTL(
id varchar primary key,
C1.status varchar,
C1.money double,
C1.pay_way integer,
C1.user_id varchar,
C1.operation_time varchar,
C1.category varchar
);
-- 2. 删除表
drop table if exists ORDER_DTL;