2022-5-9至2022-5-15周报
文章目录
- 摘要
- 基础知识
-
- 可视化GAN生成数据和真实数据的分布
- MINST数据集GAN手写数字生成
- 带毕设
摘要
Generally, two experiments were carried out in this week. The first experiment was to use the Tensorflow framework to build a GAN model, and to visualize the real data and generated data that verified the effect of the generated data. The experimental results are a little soddish, and I’m looking for the problem. The second experiment used the Pytorch framework to build a GAN model on the MINST handwritten digit dataset, and used GPU to accelerate the training, and finally obtained the ideal generation effect. Detailed analysis and understanding of the code are written in annotations.
本周主要进行了两个实验,第一个实验是利用Tensorflow框架实现GAN模型的搭建,并可视化真实数据和生成数据,来验证生成数据的效果。实验结果有些差强人意,并且正在寻找问题所在。第二个实验利用Pytorch框架,在MINST手写数字数据集上搭建GAN模型,利用GPU加速训练,最终得到了理想的生成效果。代码的详细分析与理解均写在注释中。
基础知识
可视化GAN生成数据和真实数据的分布
每一步的详细解析见注释
注意,若出现AttributeError,则看错误提示,如果提示GAN类中没有某某函数,则注意缩进,注意该函数应该属于哪一类,或者是全局函数,调整缩进即可解决。
TensorFlow实现的代码如下
import argparse
import numpy as np
from scipy.stats import norm
import tensorflow as tf
import matplotlib.pyplot as plt
from matplotlib import animation
import seaborn as sns
sns.set(color_codes=True)
#设置随机参数
seed = 42
np.random.seed(seed)
tf.set_random_seed(seed)
#设置真实数据的分布为高斯分布
class DataDistribution(object):
def __init__(self):
self.mu = 3 #均值为3
self.sigma = 0.5 #方差为0.5
def sample(self, N):
samples = np.random.normal(self.mu, self.sigma, N)
samples.sort()
return samples
#设置生成器的初始化分布为均匀分布
class GeneratorDistribution(object):
def __init__(self, range):
self.range = range
def sample(self, N):
return np.linspace(-self.range, self.range, N) + \
np.random.random(N) * 0.01
#设置线性运算用于生成器和判别器
def linear(input, output_dim, scope=None, stddev=1.0):
norm = tf.random_normal_initializer(stddev=stddev)
const = tf.constant_initializer(0.0)
with tf.variable_scope(scope or 'linear'):
w = tf.get_variable('w', [input.get_shape()[1], output_dim], initializer=norm)
b = tf.get_variable('b', [output_dim], initializer=const)
return tf.matmul(input, w) + b
def generator(input, h_dim):
h0 = tf.nn.softplus(linear(input, h_dim, 'g0'))
h1 = linear(h0, 1, 'g1')
return h1
def discriminator(input, h_dim):
h0 = tf.tanh(linear(input, h_dim * 2, 'd0'))
h1 = tf.tanh(linear(h0, h_dim * 2, 'd1'))
h2 = tf.tanh(linear(h1, h_dim * 2, 'd2'))
h3 = tf.sigmoid(linear(h2, 1, 'd3'))
return h3
#设置优化器,学习率衰减的梯度下降
def optimizer(loss, var_list, initial_learning_rate):
decay = 0.95
num_decay_steps = 150
batch = tf.Variable(0)
learning_rate = tf.train.exponential_decay(
initial_learning_rate,
batch,
num_decay_steps,
decay,
staircase=True
)
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(
loss,
global_step=batch,
var_list=var_list
)
return optimizer
tf创建GAN模型
class GAN(object):
def __init__(self, data, gen, num_steps, batch_size, log_every):
self.data = data
self.gen = gen
self.num_steps = num_steps
self.batch_size = batch_size
self.log_every = log_every
self.mlp_hidden_size = 4
self.learning_rate = 0.03
self._create_model()
def _create_model(self):
#创建预训练判别器D_pre
with tf.variable_scope('D_pre'):
self.pre_input = tf.placeholder(tf.float32, shape=(self.batch_size, 1))
self.pre_labels = tf.placeholder(tf.float32, shape=(self.batch_size, 1))
D_pre = discriminator(self.pre_input, self.mlp_hidden_size)
self.pre_loss = tf.reduce_mean(tf.square(D_pre - self.pre_labels))
self.pre_opt = optimizer(self.pre_loss, None, self.learning_rate)
with tf.variable_scope('Generator'):
self.z = tf.placeholder(tf.float32, shape=(self.batch_size, 1))
self.G = generator(self.z, self.mlp_hidden_size)
with tf.variable_scope('Discriminator') as scope:
self.x = tf.placeholder(tf.float32, shape=(self.batch_size, 1))
self.D1 = discriminator(self.x, self.mlp_hidden_size)
scope.reuse_variables()
self.D2 = discriminator(self.G, self.mlp_hidden_size)
#计算生成器和判别器的损失loss_g和loss_d,设置优化函数
self.loss_d = tf.reduce_mean(-tf.log(self.D1) - tf.log(1 - self.D2))
self.loss_g = tf.reduce_mean(-tf.log(self.D2))
self.d_pre_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='D_pre')
self.d_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Discriminator')
self.g_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Generator')
self.opt_d = optimizer(self.loss_d, self.d_params, self.learning_rate)
self.opt_g = optimizer(self.loss_g, self.g_params, self.learning_rate)
#采样以展示生成数据和真实数据的分布,_samples函数在可视化时要调用,提前声明
def _samples(self, session, num_points=10000, num_bins=100):
xs = np.linspace(-self.gen.range, self.gen.range, num_points)
bins = np.linspace(-self.gen.range, self.gen.range, num_points)
d = self.data.sample(num_points)
pd, _ = np.histogram(d, bins=bins, density=True)
zs = np.linspace(-self.gen.range, self.gen.range, num_points)
g = np.zeros((num_points, 1))
for i in range(num_points // self.batch_size):
g[self.batch_size * i:self.batch_size * (i + 1)] = session.run(self.G, {
self.z: np.reshape(
zs[self.batch_size * i:self.batch_size * (i + 1)],
(self.batch_size, 1)
)
})
pg, _ = np.histogram(g, bins=bins, density=True)
return pd, pg
#可视化,_plot_distributions函数在训练时要调用,提前声明
def _plot_distributions(self, session):
pd, pg = self._samples(session)
p_x = np.linspace(-self.gen.range, self.gen.range, len(pd))
f, ax = plt.subplots(1)
ax.set_ylim(0, 1)
plt.plot(p_x, pd, label='Real Data')
plt.plot(p_x, pg, label='Generated Data')
plt.title('GAN Visualization')
plt.xlabel('Value')
plt.ylabel('Probability Density')
plt.legend()
plt.show()
def train(self):
with tf.Session() as session:
tf.global_variables_initializer().run()
#预训练判别器D_pre为了将训练后的参数共享给判别器
num_pretrain_steps = 1000
for step in range(num_pretrain_steps):
d = (np.random.random(self.batch_size) - 0.5) * 10.0
labels = norm.pdf(d, loc=self.data.mu, scale=self.data.sigma)
pretrain_loss, _ = session.run([self.pre_loss, self.pre_opt], {
self.pre_input: np.reshape(d, (self.batch_size, 1)),
self.pre_labels: np.reshape(labels, (self.batch_size, 1))
})
self.weightsD = session.run(self.d_pre_params)
#将参数从预训练的D_pre拷贝给判别器
for i, v in enumerate(self.d_params):
session.run(v.assign(self.weightsD[i]))
for step in range(self.num_steps):
#更新判别器参数
x = self.data.sample(self.batch_size)
z = self.gen.sample(self.batch_size)
loss_d, _ = session.run([self.loss_d, self.opt_d], {
self.x: np.reshape(x, (self.batch_size, 1)),
self.z: np.reshape(z, (self.batch_size, 1))
})
#更新生成器参数
z = self.gen.sample(self.batch_size)
loss_g, _ = session.run([self.loss_g, self.opt_g], {
self.z: np.reshape(z, (self.batch_size, 1))
})
if step % self.log_every == 0:
print('{}: {}\t{}'.format(step, loss_d, loss_g))
if step % 100 == 0 or step==0 or step == self.num_steps -1 :
self._plot_distributions(session)
def main(args):
model = GAN(
DataDistribution(),
GeneratorDistribution(range=8),
args.num_steps,
args.batch_size,
args.log_every,
)
model.train()
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--num-steps', type=int, default=1200,
help='the number of training steps to take')
parser.add_argument('--batch-size', type=int, default=12,
help='the batch size')
parser.add_argument('--log-every', type=int, default=10,
help='print loss after this many steps')
parses = parser.parse_args(args=[])
return parses
执行如下代码运行程序
if __name__ == '__main__':
main(parse_args())
得到的结果

10: 0.01629788987338543 5.449047088623047
20: 0.015439528040587902 5.5185065269470215
30: 0.015012879855930805 5.568796157836914
40: 0.012823699973523617 5.602939605712891
50: 0.011871363036334515 5.628302097320557
60: 0.011470320634543896 5.641646862030029
70: 0.010661423206329346 5.6463093757629395
80: 0.010381506755948067 5.6443190574646
90: 0.010480525903403759 5.643774509429932
100: 0.00982233602553606 5.6496429443359375

110: 0.009790807962417603 5.663323879241943
120: 0.009371417574584484 5.680130481719971
130: 0.009501847438514233 5.6975321769714355
140: 0.008907336741685867 5.715467929840088
150: 0.00861402414739132 5.732852935791016
160: 0.008382672443985939 5.749778747558594
170: 0.008301560766994953 5.766630172729492
180: 0.008098706603050232 5.7836785316467285
190: 0.007916152477264404 5.800600051879883
200: 0.0077050961554050446 5.81741189956665
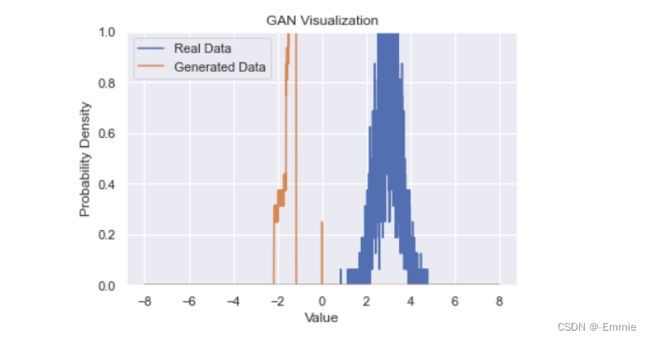
210: 0.007505951914936304 5.8341851234436035
220: 0.00744049996137619 5.850858211517334
230: 0.007380774710327387 5.867434024810791
240: 0.007155728992074728 5.883931636810303
250: 0.0071012056432664394 5.9001617431640625
260: 0.0068616303615272045 5.916114807128906
270: 0.006680747028440237 5.931644439697266
280: 0.0065270960330963135 5.947037220001221
290: 0.00657050684094429 5.962244033813477
300: 0.006405905354768038 5.9770026206970215

310: 0.006316028535366058 5.990970611572266
320: 0.006221506744623184 6.004660129547119
330: 0.0061231316067278385 6.0182366371154785
340: 0.006014955695718527 6.032130718231201
350: 0.00599629944190383 6.045213222503662
360: 0.005801557097584009 6.058042526245117
370: 0.0056908950209617615 6.070722579956055
380: 0.005618871655315161 6.083218097686768
390: 0.005715588107705116 6.09558629989624
400: 0.005546335130929947 6.10773229598999

410: 0.005434928461909294 6.1198201179504395
420: 0.005455771926790476 6.1316914558410645
430: 0.005327282473444939 6.1434149742126465
440: 0.005280074197798967 6.154966831207275
450: 0.005122395697981119 6.166290283203125
460: 0.0051498617976903915 6.176976680755615
470: 0.005127287935465574 6.1876702308654785
480: 0.005085904151201248 6.19823694229126
490: 0.004985454957932234 6.208592891693115
500: 0.004960369784384966 6.218894958496094
与预期结果相差很大,属于训练失败,应该无随机因素影响,不知道问题出在哪里。
预期结果:




MINST数据集GAN手写数字生成
动手实践CUDA11.0+cuDNN+PyTorch1.9.0的安装,并使用GPU加速进行GAN训练,代码如下
import torch
import torchvision
import torch.nn as nn
import numpy as np
image_size = [1, 28, 28]
latent_dim = 96
batch_size = 64
use_gpu = torch.cuda.is_available()
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 128),
# 提高收敛速度
torch.nn.BatchNorm1d(128),
torch.nn.ReLU(),
nn.Linear(128, 256),
torch.nn.BatchNorm1d(256),
torch.nn.ReLU(),
nn.Linear(256, 512),
torch.nn.BatchNorm1d(512),
torch.nn.ReLU(),
nn.Linear(512, 1024),
torch.nn.BatchNorm1d(1024),
torch.nn.ReLU(),
nn.Linear(1024, np.prod(image_size, dtype=np.int32)),
nn.Sigmoid(),
)
def forward(self, z):
# shape of z: [batchsize, latent_dim]
output = self.model(z)
image = output.reshape(z.shape[0], *image_size)
return image
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(np.prod(image_size, dtype=np.int32), 512),
torch.nn.ReLU(),
nn.Linear(512, 256),
torch.nn.GELU(),
nn.Linear(256, 128),
torch.nn.ReLU(),
nn.Linear(128, 64),
torch.nn.ReLU(),
nn.Linear(64, 32),
torch.nn.ReLU(),
nn.Linear(32, 1),
nn.Sigmoid(),
)
def forward(self, image):
# shape of image: [batchsize, 1, 28, 28]
prob = self.model(image.reshape(image.shape[0], -1))
return prob
# Training
dataset = torchvision.datasets.MNIST("mnist_data", train=True, download=True,
transform=torchvision.transforms.Compose(
[
torchvision.transforms.Resize(28),
torchvision.transforms.ToTensor(),
# 直接预测[0,1]之间的像素值,不需要归一化的操作
# torchvision.transforms.Normalize([0.5], [0.5]),
]
)
)
# 调用DataLoader加载图片数据集
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, drop_last=True)
# 分别实例化生成器与判别器
generator = Generator()
discriminator = Discriminator()
# 分别构建两个adam优化器,平滑系数betas适当调小以帮助学习
g_optimizer = torch.optim.Adam(generator.parameters(), lr=0.0003, betas=(0.4, 0.8), weight_decay=0.0001)
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=0.0003, betas=(0.4, 0.8), weight_decay=0.0001)
# BCELoss()损失函数,二项的交叉熵函数,定义部分
loss_fn = nn.BCELoss()
# target
labels_one = torch.ones(batch_size, 1)
labels_zero = torch.zeros(batch_size, 1)
if use_gpu:
print("use gpu for training")
generator = generator.cuda()
discriminator = discriminator.cuda()
loss_fn = loss_fn.cuda()
labels_one = labels_one.to("cuda")
labels_zero = labels_zero.to("cuda")
# 开始训练,两个for循环
num_epoch = 200
for epoch in range(num_epoch):
# 训练步骤开始,对dataloader进行遍历
for i, mini_batch in enumerate(dataloader):
gt_images, _ = mini_batch #只含x和y,不含标签
# z是一个符合正态分布的随机变量,latent_dim是Z的维度
z = torch.randn(batch_size, latent_dim)
if use_gpu:
gt_images = gt_images.to("cuda")
z = z.to("cuda")
# 把Z喂入生成器中,得出预测的images照片
pred_images = generator(z)
#对所有梯度置零
g_optimizer.zero_grad()
recons_loss = torch.abs(pred_images-gt_images).mean()
# 生成器优化函数
# discriminator(pred_images)是判别器对预测图片给出的概率大小,labels_one则是target,对生成器G进行优化,target取1;
g_loss = recons_loss*0.05 + loss_fn(discriminator(pred_images), labels_one)
g_loss.backward()
# 更新G的参数
g_optimizer.step()
# 对判别器梯度置零
d_optimizer.zero_grad()
#判别器的目标函数有两项
real_loss = loss_fn(discriminator(gt_images), labels_one) # 对真实图片预测成 1
fake_loss = loss_fn(discriminator(pred_images.detach()), labels_zero) # 希望判别器对预测生成的图片(假图)预测成0
# 不需要记录G的梯度,所以用pred_images.detach(),将G梯度从中隔离出来,不需要计算生成器的梯度
# 判别器优化函数
d_loss = (real_loss + fake_loss)
# 观察real_loss与fake_loss,同时下降同时达到最小值,并且差不多大,说明D已经稳定了
d_loss.backward()
d_optimizer.step()
if i % 50 == 0:
print(f"step:{len(dataloader)*epoch+i}, recons_loss:{recons_loss.item()}, g_loss:{g_loss.item()}, d_loss:{d_loss.item()}, real_loss:{real_loss.item()}, fake_loss:{fake_loss.item()}")
# 在torchvision中保存照片
if i % 400 == 0:
image = pred_images[:16].data
torchvision.utils.save_image(image, f"image_{len(dataloader)*epoch+i}.png", nrow=4)
程序在GPU加速下用一小时左右的时间执行完,生成600张图片。

可以看到训练初期,生成图像的变化。



展示三张效果很好的生成图,最终real_loss减小到0.45左右、fake_loss减小到0.3左右,并不稳定,忽大忽小。
接下来的计划:timeGAN公式与代码对照,思考它是如何修改生成器和判别器的
带毕设
讲系统设计和系统实现要分开两章写,系统实现要写一些类、包调用等开发细节;
修改了3版论文。