Redis最全详解(一)——基础介绍
Redis介绍
redis是基于内存可持久化的日志型、Key-Value数据库。redis安装在磁盘,但是数据存储在内存。非关系型数据库NoSql。开源免费,遵守BSD协议,不用关注版权问题。
redis作者github:github.com/antirez
redis是一种基于键值对(key-value)数据库,其中value可以为string、hash、list、set、zset等多种数据结构,可以满足很多应用场景。还提供了键过期,发布订阅,事务,流水线等附加功能。
执行过程:发送指令-〉执行命令-〉返回结果
执行命令:单线程执行,所有命令进入队列,按顺序执行
单线程快原因:纯内存访问, 单线程避免线程切换和竞争产生资源消耗,RESP协议简单(后端封装,传输的是RESP协议的redis命令给redis服务器)
问题:如果某个命令执行慢,会造成其它命令的阻塞。
特性:
- 速度快(单线程)
- 键值对的数据结构服务器
- 丰富的功能
- 简单稳定
- 持久化
- 主从复制
- 高可用和分布式转移
- 客户端语言多
- 原子性:要么全执行要么全不执行
NoSQL数据库的四大分类
键值(Key-Value)存储数据库
这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型对于IT系统来说的优势在于简单、易部署。但是如果DBA只对部分值进行查询或更新的时候,Key/value就显得效率低下了。举例如:Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB.
列存储数据库
这部分数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。如:Cassandra, HBase, Riak.
文档型数据库
文档型数据库的灵感是来自于Lotus Notes办公软件的,而且它同第一种键值存储相类似。该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可 以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。如:CouchDB**,** MongoDb. 国内也有文档型数据库SequoiaDB,已经开源。
图形(Graph)数据库
图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API。[2] 如:Neo4J, InfoGrid, Infinite Graph.
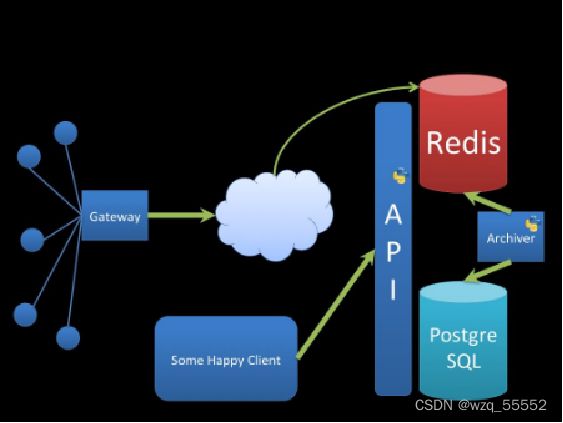
Redis使用场景
- 缓存数据库
- 排行榜
- 社交网络
- 消息队列
- 手机验证码
- 限制网站访问的访问频率(计数器应用,每秒访问次数,得到ip后检测恶意访问)
Redis配置包
官网下载tar中含有的配置文件,如果需要相应的配置就复制到自己redis的bin/目录下,修改,启动。
| 可执行文件 | 作用 |
|---|---|
| redis-server | 启动redis |
| redis-cli | redis命令行客户端 |
| redis-benchmark | 基准测试工具 |
| redis-check-aof | AOF持久化文件检测和修复工具 |
| redis-check-dump | RDB持久化文件检测和修复工具 |
| redis-sentinel | 启动哨兵 |
| redis-trib | cluster集群构建工具 |
kill -9 redis不能这样使用,数据持久化到硬盘也会丢失。
Redis单机安装
ubuntu系统直接安装server
#安装redis 使用命令
apt-get install redis-server
whereis redis #查看redis的安装位置
ps -aux | grep redis #查看redis服务的进程运行
netstat -nlt | grep 6379
#根据redis运行的端口号查看redis服务器状态,端口号前是redis服务监听的IP(默认只有本机IP 127.0.0.1)
#本地进入客户端
cd /etc/redis
redis-cli
#Redis以守护进程运行
#如果以守护进程运行,则不会在命令行阻塞,类似于服务
#如果以非守护进程运行,则当前终端被阻塞,无法使用
#0.0.0.0授权组所有
#推荐改为yes,以守护进程运行,redis.conf
#修改端口才可以远程连接,默认本地连接;连接密码,在第501行
vi redis.conf
bind 0.0.0.0
daemonize yes
requirepass 123456
#在redis.conf配置requirepass也可以
#redis 127.0.0.1:6379> config set requirepass 123456
#使得配置写入redis.conf
#redis 127.0.0.1:6379> config rewrite
#关闭redis服务端,数据会同步保存
redis-cli shutdown
#关闭,不建议用,数据无法持久化
ps -ef|grep redis
kill -9 号
#重启
/etc/init.d/redis-server restart
#这样启动也可以
redis-server ./redis.conf
centos系统安装tar包
只要能 ping 的通云主机或者虚拟机的 ip,然后在虚拟机或者云主机中放行对应的端口(或者关掉防火墙)即可访问 redis。下面来介绍一下 redis 的安装过程:
- 安装 gcc 编译
因为后面安装redis的时候需要编译,所以事先得先安装gcc编译。阿里云主机已经默认安装了 gcc,root用户,如果是自己安装的虚拟机,那么需要先安装一下 gcc:
yum install gcc-c++
- 下载 redis
有两种方式下载安装包,一种是去官网上下载(https://redis.io),然后将安装包考到 centos 中,一般usr/local/目录,另种方法是直接使用 wget 来下载:
wget http://download.redis.io/releases/redis-5.0.0.tar.gz
如果没有安装过 wget,可以通过如下命令安装:
yum install wget
- 解压安装
解压安装包:
tar zxvf /redis-5.0.0.tar.gz
然后将解压的文件夹 /redis-5.0.0 放到 /usr/local/ 下,一般安装软件都放在 /usr/local 下。然后进入 /usr/local/redis-5.0.0/ 文件夹下,执行 make 命令即可完成安装。
【注】如果 make 失败,可以尝试如下命令:
make MALLOC=libc
make install
接着安装redis到指定路径:
make PREFIX=/usr/local/redis install
-
修改配置文件
redis-5.0.0(包含很多源配置)中移动源文件到安装目录
cp redis.conf /usr/local/redis/bin cd /usr/local/redis
安装成功之后,需要把需要修改一下配置文件,包括允许接入的 ip,允许后台执行,设置密码等等。
打开 redis 配置文件:vi redis.conf
在命令模式下输入 /bind n(下一个)来查找 bind 配置,按 n 来查找下一个,找到配置后,将 bind 配置成 0.0.0.0,允许任意服务器来访问 redis,即:
bind 0.0.0.0
使用同样的方法,将 daemonize 改成 yes (默认为 no),允许 redis 在后台执行。
将 requirepass 注释打开,并设置密码为 123456(500多行,密码自己设置)。
- 启动 redis
在 redis/bin 目录下,指定刚刚修改好的配置文件 redis.conf 来启动 redis:
redis-server ./redis.conf
再启动 redis 客户端:
./redis-cli
./redis-cli -h 127.0.0.1 -p 6379
由于我们设置了密码,在启动客户端之后,输入 auth 123456 即可登录进入客户端。或者redis-cli -a password
然后我们来测试一下,往 redis 中插入一个数据:
set name CSDN
然后来获取 name
get name
如果正常获取到 CSDN,则说明没有问题。
docker安装redis
//启动docker
systemctl start docker
docker pull redis
docker images
docker run -d --name redis -p 6379:6379 redis:5.0/id --requirepass "123456"
docker ps
#进入容器
docker exec it redis/id
#进入客户端
exec -it redis/id redis-cli -a 123456
ctrl+P+Q
redis.conf配置文件详解
redis.conf 配置项说明如下:
- Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程
daemonize no
- 当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定
pidfile /var/run/redis.pid
- **指定Redis监听端口,默认端口为6379,**为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字
port 6379
4. 绑定的主机地址
bind 127.0.0.1
5.当 客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
timeout 300
- 指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose
loglevel verbose
- 日志记录方式,默认为标准输出,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null
logfile stdout
- 设置数据库的数量,默认数据库为0,可以使用SELECT 命令在连接上指定数据库id
databases 16
- 指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合
save
Redis默认配置文件中提供了三个条件:
save 900 1
save 300 10
save 60 10000
分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。
- 指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
rdbcompression yes
- 指定本地数据库文件名,默认值为dump.rdb
dbfilename dump.rdb
- 指定本地数据库存放目录
dir ./
- 设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
slaveof
- 当master服务设置了密码保护时,slav服务连接master的密码
masterauth
- 设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH 命令提供密码,默认关闭
requirepass foobared
- 设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
maxclients 128
- 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
maxmemory
- 指定是否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no
appendonly no
- 指定更新日志文件名,默认为appendonly.aof
appendfilename appendonly.aof
- 指定更新日志条件,共有3个可选值:
no:表示等操作系统进行数据缓存同步到磁盘(快)
always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全)
everysec:表示每秒同步一次(折中,默认值)
appendfsync everysec
- 指定是否启用虚拟内存机制,默认值为no,简单的介绍一下,VM机制将数据分页存放,由Redis将访问量较少的页即冷数据swap到磁盘上,访问多的页面由磁盘自动换出到内存中(在后面的文章我会仔细分析Redis的VM机制)
vm-enabled no
- 虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享
vm-swap-file /tmp/redis.swap
- 将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据 就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0
vm-max-memory 0
- Redis swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page大小最好设置为32或者64bytes;如果存储很大大对象,则可以使用更大的page,如果不 确定,就使用默认值
vm-page-size 32
- 设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是在放在内存中的,,在磁盘上每8个pages将消耗1byte的内存。
vm-pages 134217728
- 设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4
vm-max-threads 4
- 设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启
glueoutputbuf yes
- 指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法
hash-max-zipmap-entries 64
hash-max-zipmap-value 512
- 指定是否激活重置哈希,默认为开启(后面在介绍Redis的哈希算法时具体介绍)
activerehashing yes
- 指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件
include /path/to/local.conf
Redis中的内存维护策略
redis作为优秀的中间缓存件,时常会存储大量的数据,即使采取了集群部署来动态扩容,也应该即时的整理内存,维持系统性能。
在redis中有两种解决方案,
一是为数据设置超时时间 expire命令
二是采用LRU算法(最近最久未被使用)动态将不用的数据删除。内存管理的一种页面置换算法,对于在内存中但又不用的数据块(内存块)叫做LRU,操作系统会根据哪些数据属于LRU而将其移出内存而腾出空间来加载另外的数据。
1.volatile-lru:设定超时时间的数据中,删除最不常使用的数据.
2.allkeys-lru:查询所有的key中最近最不常使用的数据进行删除,这是应用最广泛的策略.
3.volatile-random:在已经设定了超时的数据中随机删除.
4.allkeys-random:查询所有的key,之后随机删除.
5.volatile-ttl:查询全部设定超时时间的数据,之后排序,将马上将要过期的数据进行删除操作.
6.noeviction:如果设置为该属性,则不会进行删除操作,如果内存溢出则报错返回.
· volatile-lfu:从所有配置了过期时间的键中驱逐使用频率最少的键
· allkeys-lfu:从所有键中驱逐使用频率最少的键
https://www.jianshu.com/p/c8aeb3eee6bc
Redis数据类型
5种基本类型,string、hash、list、set、zset。后期增加了HyperLogLog。
一般key可以加前缀来区分的,比如userId可以这样设计:user:Id值
这样可以跟关系型数据库命名_区分,而且桌面软件支持:命名。
1.key不要太长,尽量不要超过1024字节,这不仅消耗内存,而且会降低查找的效率;
2.key也不要太短,太短的话,key的可读性会降低;
3.在一个项目中,key最好使用统一的命名模式,例如user:123:password;
4.key名称区分大小写。
客户端命令
keys *
exists key
ttl key
del key
expire key second
persist key //取消过期时间
rename key key2
type key
字符串(string)
字符串类型:实际上可以是字符串(包括XML JSON),
还有数字(整形 浮点数),二进制(图片 音频 视频),最大不能超过512MB。string可以包含任何数据。
命令s开头
设值命令:
set age 23 ex 10 //10秒后过期 px 10000 毫秒过期
ttl age //查看age的剩余时间,-1表示永久有效
flushdb //清空数据
setnx name test //(not exist)不存在键name时,返回1设置成功;存在的话失败0(分布式锁方案之一)
set age 25 xx //存在键age时,返回1成功
mset name james age 19 //批量插入数据,key,value,key,value...
获值命令:
get age //存在则返回value, 不存在返回nil‘
getrange age 0 1 //显示1
strlen age //长度,2
批量设值:
mset country china city beijing
批量获取:
mget country city address //返回china beigjin, address为nil
字符串计数:
age是key
incr age //必须为整数自加1,非整数类型返回错误,无age键,默认为0,从0自增返回1
decr age //整数age减1
incrby age 2 //整数age+2
decrby age 2 //整数age -2
incrbyfloat score 1.1 //浮点型score+1.1
append追加指令:
set name hello; append name world //追加后成helloworld
字符串长度:
set hello “世界”;strlen hello//结果6,每个中文占3个字节
截取字符串:
set name helloworld ; getrange name 2 4//返回 llo
应用场景:
1、string通常用于保存单个字符串或JSON字符串数据
2、因string是二进制安全的,所以你完全可以把一个图片文件的内容作为字符串来存储
3、计数器(常规key-value缓存应用。常规计数: 微博数, 粉丝数)
INCR等指令本身就具有原子操作的特性,所以我们完全可以利用redis的INCR、INCRBY、DECR、DECRBY等指令来实现原子计数的效果。假如,在某种场景下有3个客户端同时读取了mynum的值(值为2),然后对其同时进行了加1的操作,那么,最后mynum的值一定是5。
不少网站都利用redis的这个特性来实现业务上的统计计数需求。
哈希(hash)
哈希hash是一个string类型的field和value的映射表,hash特适合用于存储对象(多个map)。主键当key,其它字段一起当value,用map存。
命令h开头
命令
hset key field value
设值:
hset user:1 name james //成功返回1,失败返回0
取值:
hget user:1 name //返回james
删值:
hdel user:1 age //返回删除的个数
计算个数:
hset user:1 name james; hset user:1 age 23;
hlen user:1 //返回2,user:1有两个属性值
批量设值:
hmset user:2 name james age 23 sex boy //返回OK
批量取值:
hmget user:2 name age sex //返回三行:james 23 boy
判断field是否存在:
hexists user:2 name //若存在返回1,不存在返回0
获取所有field:
hkeys user:2 // 返回name age sex三个field
获取user:2所有value:
hvals user:2 // 返回james 23 boy
获取user:2所有field与value:
hgetall user:2 //name age sex james 23 boy值
增加1:
hincrby user:2 age 1 //age+1
hincrbyfloat user:2 age 2 //浮点型加2
hsetnx user:2 age 1 //不存在键则插入,存在不插入
设置过期:
expire user:2 10 //10秒
应用场景:
1、 常用于存储一个对象
2、 为什么不用string存储一个对象?
hash是最接近关系数据库结构的数据类型,可以将数据库一条记录或程序中一个对象转换成hashmap存放在redis中。
用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储,主要有以下2种存储方式:
第一种方式将用户ID作为查找key,把其他信息封装成一个对象以序列化的方式存储,这种方式的缺点是,增加了序列化/反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护,引入CAS等复杂问题。
第二种方法是这个用户信息对象有多少成员就存成多少个key-value对儿,用用户ID+对应属性的名称作为唯一标识来取得对应属性的值,虽然省去了序列化开销和并发问题,但是用户ID为重复存储,如果存在大量这样的数据,内存浪费还是非常可观的。
总结:
Redis提供的Hash很好的解决了这个问题,Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口
1,原生:set user:1:name james;
set user:1:age 23;
set user:1:sex boy;
优点:简单直观,每个键对应一个值
缺点:键数过多,占用内存多,用户信息过于分散,不用于生产环境
2,将对象序列化存入redis
set user:1 serialize(userInfo);
优点:编程简单,若使用序列化合理内存使用率高
缺点:序列化与反序列化有一定开销,更新属性时需要把userInfo全取出来进行反序列化,更新后再序列化到redis
3,使用hash类型:
hmset user:1 name james age 23 sex boy
优点:简单直观,使用合理可减少内存空间消耗
缺点:要控制ziplist与hashtable两种编码转换,且hashtable会消耗更多内存erialize(userInfo);
序列化:把对象转换为字节序列的过程称为对象的序列化。
反序列化:把字节序列恢复为对象的过程称为对象的反序列化。
当你想把的内存中的对象状态保存到一个文件中或者数据库中时候;
当你想用套接字在网络上传送对象的时候;
当你想通过RMI传输对象的时候;
列表(list)
用来存储多个有序的字符串,一个列表最多可存2的32次方减1个元素
因为有序,可以通过索引下标获取元素或某个范围内元素列表,列表元素可以重复
List类型是一个链表结构的集合,其主要功能有push、pop、获取元素等。更详细的说,List类型是一个双端链表,我们可以通过相关的操作进行集合的头部或者尾部添加和删除元素,List的设计非常简单精巧,即可以作为栈,又可以作为队列,满足绝大多数的需求。
按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)一个列表最多可以包含 2^32 -1 个元素 (4294967295, 每个列表超过40亿个元素) 类似JAVA中的LinkedList 。
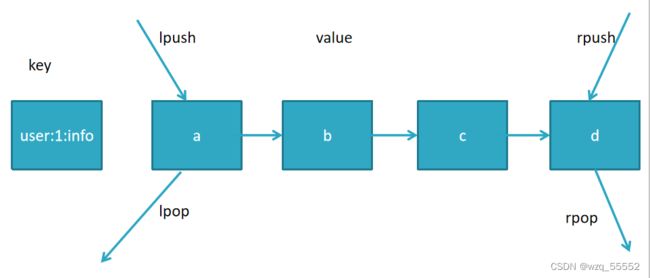
一个key,多个有序值
命令l开头
添加命令:
rpush james c b a //从右向左插入cba, 返回值3
lrange james 0 -1 //从左到右获取列表所有元素 返回 c b a
lpush key c b a //从左向右插入cba
linsert james before b teacher //在b之前插入teacher, after为之后
使用lrange james 0 -1 查看:
c teacher b a
lpushx key value //将一个值插入到已存在的列表头部。如果列表不在,操作无效
rpushx key value //一个值插入已存在的列表尾部(最右边)。如果列表不在,操作无效。
查找命令:
lrange key start end //索引下标特点:从左到右为0到N-1
lindex james -1 //返回最右末尾a,-2返回b
llen james //返回当前列表长度
lpop james //把最左边的第一个元素c删除
rpop james //把最右边的元素a删除
场景:
以订单为例子(不推荐使用redis做消息队列)
1,每个用户有多个订单key为 order:1 order:2 order:3, 结合hmset
hmset order:1 orderId 1 money 36.6 time 2018-01-01
hmset order:2 orderId 2 money 38.6 time 2018-01-01
hmset order:3 orderId 3 money 39.6 time 2018-01-01
2,把订单信息的key放到队列
lpush user:1:order order:1 order:2 order:3
3,新产生了一个订单order:4,
hmset order:4 orderId 4 money 40.6 time 2018-01-01
4,追加一个order:4放入队列第一个位置
lpush user:1:order order:4
5,当需要查询用户订单记录时:
List orderKeys = lrange user:1:order 0 -1 //查询user:1 的所有订单key值
for(Order order: orderKeys){
hmget order:1
}
集合(set)
用户标签,社交,查询有共同兴趣爱好的人,智能推荐。
类似于JAVA中的 Hashtable集合。
保存多元素,与列表不一样的是不允许有重复元素,且集合是无序,一个集合最多可存2的32次方减1个元素,除了支持增删改查,还支持集合交集、并集、差集;
命令s开头
exists user //检查user键值是否存在
sadd user a b c//向user插入3个元素,返回3
sadd user a b //若再加入相同的元素,则重复无效,返回0
smembers user //获取user的所有元素,返回结果无序
sismember user a //判断a元素是否是集合user的成员(开发中:验证是否存在判断)
srem user a //返回1,删除a元素
scard user //返回2,计算元素个数
差集语法:
SDIFF key1 [key2] :返回给定所有集合的差集(左侧)
SDIFFSTORE destination key1 [key2] :返回给定所有集合的差集并存储在 destination 中
交集语法:
SINTER key1 [key2] :返回给定所有集合的交集(共有数据)
SINTERSTORE destination key1 [key2] :返回给定所有集合的交集并存储在 destination 中
并集语法:
SUNION key1 [key2] :返回所有给定集合的并集
SUNIONSTORE destination key1 [key2] :所有给定集合的并集存储在 destination 集合中
场景:
标签,社交,查询有共同兴趣爱好的人,智能推荐
使用方式:
给用户添加标签:
sadd user:1:fav basball fball pq
sadd user:2:fav basball fball
…
或给标签添加用户
sadd basball:users user:1 user:2
sadd fball:users user:1 user:2
…
计算出共同感兴趣的人:
sinter user:1:fav user2:fav
有序集合(zset)
常用于排行榜,如视频网站需要对用户上传视频做排行榜,或点赞数
与集合有联系,不能有重复的成员。相比set,加了有序而已。不同的是每个元素都会关联一 个double类型的分数,用来排序。集合中最大的成员数为2次方32 - 1 (4294967295, 每个集合可存储40多亿个成员)。Redis的ZSet是有序、且不重复。
按score分值排序。zadd key score member。
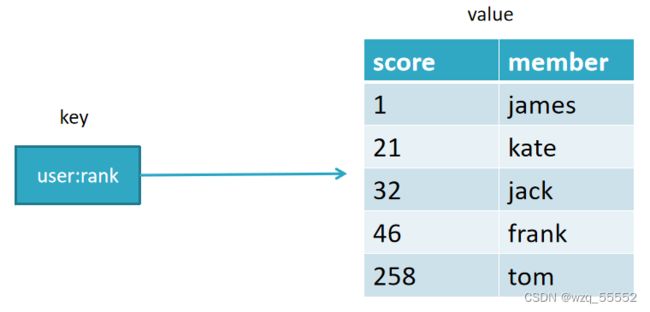
与LIST和SET对比
| 数据结构 | 是否允许元素重复 | 是否有序 | 有序实现方式 | 应用场景 |
|---|---|---|---|---|
| 列表 | 是 | 是 | 索引下标 | 时间轴,消息队列 |
| 集合 | 否 | 否 | 无 | 标签,社交 |
| 有序集合 | 否 | 是 | 分值 | 排行榜,点赞数 |
指令:
zadd key score member [score member......]
zadd user:zan 200 james //james的点赞数1, 返回操作成功的条数1
zadd user:zan 200 james 120 mike 100 lee// 返回3
zadd test:1 nx 100 james //键test:1必须不存在,主用于添加
zadd test:1 xx incr 200 james //键test:1必须存在,主用于修改,此时为300
zadd test:1 xx ch incr -299 james //返回操作结果1,300-299=1
zrange test:1 0 -1 withscores //查看点赞(分数)与成员名
zcard test:1 //计算成员个数, 返回1
ZRANGE key start stop [WITHSCORES] :通过索引区间返回有序集合成指定区间内的成员(低到高)
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] :通过分数返回有序集合指定区间内的成员
ZREVRANGE key start stop [WITHSCORES] :返回有序集中指定区间内的成员,通过索引,分数从高到底
ZREVRANGEBYSCORE key max min [WITHSCORES] :返回有序集中指定分数区间内的成员,分数从高到低排序
排名场景:
zadd user:3 200 james 120 mike 100 lee//先插入数据
zrange user:3 0 -1 withscores //查看分数与成员,0到-1指多所有
zrank user:3 james //返回名次(默认低到高):第3名返回2,从0开始到2,共3名
zrevrank user:3 james //返回0, 反排序,点赞数越高,排名越前
ZREM key member [member ...] :移除有序集合中的一个或多个成员
ZREMRANGEBYRANK key start stop :移除有序集合中给定的排名区间的所有成员(第一名是0)(低到高排序)
ZREMRANGEBYSCORE key min max :移除有序集合中给定的分数区间的所有成员
ZINCRBY key increment member :增加memeber元素的分数increment,返回值是更改后的分数
场景:
排行榜系统,如视频网站需要对用户上传的视频做排行榜
点赞数:
zadd user:1:20180106 3 mike //mike获得3个赞
再获一赞:
zincrby user:1:20180106 1 mike //在3的基础上加1
用户作弊,将用户从排行榜删掉:
zrem user:1:20180106 mike
展示赞数最多的5个用户:
zrevrangebyrank user:1:20180106 0 4
查看用户赞数与排名:
zscore user:1:20180106 mike zrank user:1:20180106 mike
HyperLogLog
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时, 计算基数所需的空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
为什么要使用HyperLogLog?
如果要统计1亿个数据的基数值,大约需要内存100000000/8/1024/1024 ≈ 12M,内存减少占用的效果显著。
然而统计一个对象的基数值需要12M,如果统计10000个对象,就需要将近120G,同样不能广泛用于大数据场景。
常用命令:
PFADD key element [element ...] :添加指定元素到 HyperLogLog 中
PFCOUNT key [key ...] :返回给定 HyperLogLog 的基数估算值
PFMERGE destkey sourcekey [sourcekey ...] :将多个 HyperLogLog 合并为一个 HyperLogLog
应用场景
基数不大,数据量不大就用不上,会有点大材小用浪费空间 有局限性,就是只能统计基数数量,而没办法去知道具 体的内容是什么
统计注册 IP 数
统计每日访问 IP 数
统计页面实时 UV 数
统计在线用户数
统计用户每天搜索不同词条的个数
统计真实文章阅读数
HyperLogLog是一种算法,并非redis独有
目的是做基数统计,故不是集合,不会保存元数据,只记录数量而不是数值。 耗空间极小,支持输入非常体积的数据量
核心是基数估算算法,主要表现为计算时内存的使用和数据合并的处理。最终数值存在一定误差 redis中每个hyperloglog key占用了12K的内存用于标记基数(官方文档) pfadd命令并不会一次性分配12k内存,而是随着基数的增加而逐渐增加内存分配;而pfmerge操作则会将sourcekey合并
后存储在12k大小的key中,这由hyperloglog合并操作的原理(两个hyperloglog合并时需要单独比较每个桶的值)可以 很容易理解。
误差说明:基数估计的结果是一个带有 0.81% 标准错误(standard error)的近似值。是可接受的范围
Redis 对 HyperLogLog 的存储进行了优化,在计数比较小时,它的存储空间采用稀疏矩阵存储,空间占用很小,仅仅在 计数慢慢变大,稀疏矩阵占用空间渐渐超过了阈值时才会一次性转变成稠密矩阵,才会占用 12k 的空间
Redis全局命令
1,查看所有键:
keys * set school enjoy set hello world
2,键总数 :
dbsize //2个键,如果存在大量键,线上禁止使用此指令
3,检查键是否存在:
exists key //存在返回1,不存在返回0
4,删除键:
del key //del hello school, 返回删除键个数,删除不存在键返回0
5,键过期:
expire key seconds //set name test expire name 10,表示10秒过期
ttl key //查看剩余的过期时间
6,键的数据结构类型:
type key //type hello //返回string,键不存在返回none
| redis数据库管理方式 | 作用 |
|---|---|
| select 0 | 切换库,默认0库 |
| flushdb | 删除当前库的数据 |
| flushall | 删除所有库的数据 |
| dbsize | 返回当前的库的key数量 |
move key名称 库2 //移动当前库的key值到库2
数据库批量导数据到Redis
pipe管道批量输入
redis和数据库在同一个数据库才可以:
–skip-column-names列名跳过,执行order.sql语句,select语句,要导入的数据。
mysql -u用户名 -p密码 数据库名 --default-character-set=utf8 --skip-column-names --raw < order.sql | redis-cli -h 192.168.168.133 -p 6379 -a 123456 --pipe
redis-cli命令
./redis-cli -r 3 -a 12345678 ping //返回pong表示127.0.0.1:6379能通,正常
./redis-cli -r 100 -i 1 info |grep used_memory_human //每秒输出内存使用量,输100次
./redis-cli -p 6379 -a 123456
对于我们来说,这些常用指令以上可满足,但如果要了解更多
执行redis-cli --help, 可百度
redis-server命令
./redis-server ./redis.conf & //指定配置文件启动
./redis-server --test-memory 1024 //检测操作系统能否提供1G内存给redis, 常用于测试,想快速占满机器内存做极端条件的测试,可使用这个指令
redis-benchmark命令
测试性能,进入redis/bin目录
redis-benchmark -c 100 -n 10000
测试命令事例:
1、redis-benchmark -h 192.168.42.111 -p 6379 -c 100 -n 100000
100个并发连接,100000个请求,检测host为localhost 端口为6379的redis服务器性能
2、redis-benchmark -h 192.168.42.111 -p 6379 -q -d 100
测试存取大小为100字节的数据包的性能
3、redis-benchmark -t set,lpush -n 100000 -q
只测试 set,lpush操作的性能
4、redis-benchmark -n 100000 -q script load "redis.call('set','foo','bar')"
只测试某些数值存取的性能
Pipeline详解
pipeline出现的背景:
redis客户端执行一条命令分4个过程:
发送命令-〉命令排队-〉命令执行-〉返回结果
这个过程称为Round trip time(简称RTT, 往返时间),mget mset有效节约了RTT,但大部分命令(如hgetall,并没有mhgetall)不支持批量操作,需要消耗N次RTT ,这个时候需要pipeline来解决这个问题。
pipeline的作用就是批量操作,而不是java客户端遍历一次一次传输,往返时间远大于redis执行的时间。
原生批命令(mset, mget)与Pipeline对比:
one,原生批命令是原子性,pipeline是非原子性,
(原子性概念:一个事务是一个不可分割的最小工作单位,要么都成功要么都失败。
原子操作是指你的一个业务逻辑必须是不可拆分的. 处理一件事情要么都成功
要么都失败,其实也引用了生物里概念,分子-〉原子,原子不可拆分)
two,原生批命令一命令多个key, 但pipeline支持多命令(存在事务),非原子性
three: 原生批命令是服务端实现,而pipeline需要服务端与客户端共同完成
使用原则:
使用pipeline组装的命令个数不能太多,不然数据量过大,
增加客户端的等待时间,还可能造成网络阻塞,
可以将大量命令的拆分多个小的pipeline命令完成
Redis事务
pipeline是多条命令的组合,为了保证它的原子性,redis提供了简单的事务。
redis的简单事务,将一组需要一起执行的客户端命令放到multi和exec两个命令之间,其中multi代表事务开始,exec代表事务结束 。
watch命令:使用watch后, multi失效,事务失效
总结:redis提供了简单的事务,不支持事务回滚
Redis 事务可以一次执行多个命令(允许在一次单独的步骤中执行一组命令), 并且带有以下两个重要的保证:
批量操作在发送 EXEC 命令前被放入队列缓存。 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败, 其余的命令依然被执行。 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
- Redis会将一个事务中的所有命令序列化,然后按顺序执行
- 执行中不会被其它命令插入,不许出现加赛行为
**要么全部成功,要么都不成功。**一些秒杀场景可以实现。
命令:
DISCARD
:取消事务,放弃执行事务块内的所有命令。 EXEC
:执行所有事务块内的命令。
MULTI
:标记一个事务块的开始。
UNWATCH
:取消 WATCH 命令对所有 key 的监视。
WATCH key [key ...]
:监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。
一个事务从开始到执行会经历以下三个阶段:
开始事务。 命令入队。 执行事务。
转帐功能,A向B帐号转帐50元 一个事务的例子,它先以MULTI开始一个事务,然后将多个命令入队到事务中,最后由 EXEC 命令触发事务。触发后其他命令无法执行该key。
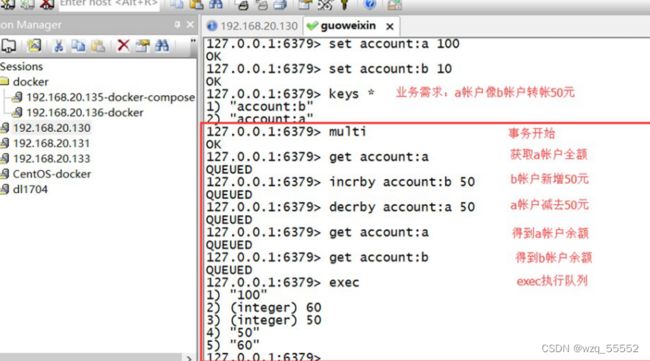
使用DISCARD放弃队列运行
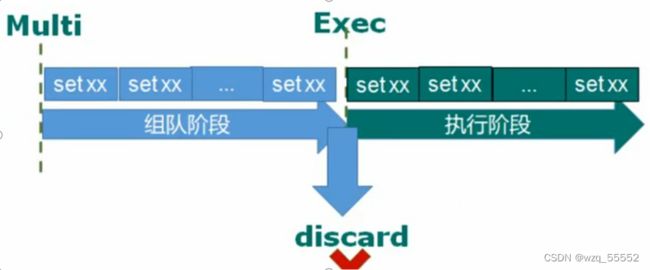
事务的错误处理
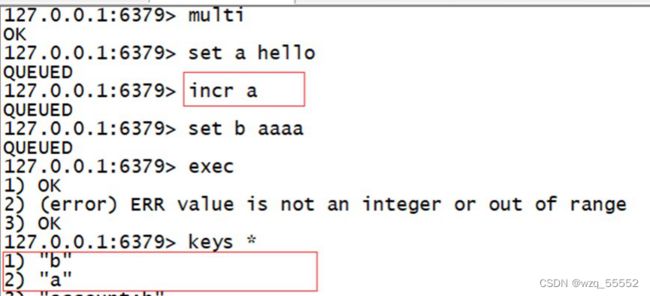
- 如果执行的某个命令报出了错误,则只有报错的命令不会被执行,而其它的命令都会执行,不会回滚。
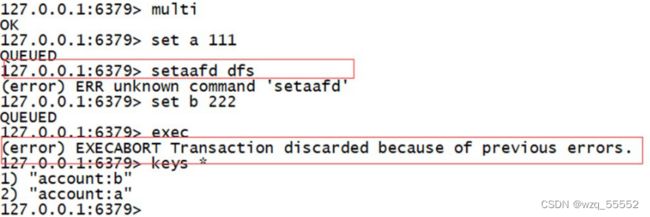
- 队列中的某个命令出现了报告错误,执行时整个的所有队列都会被取消。
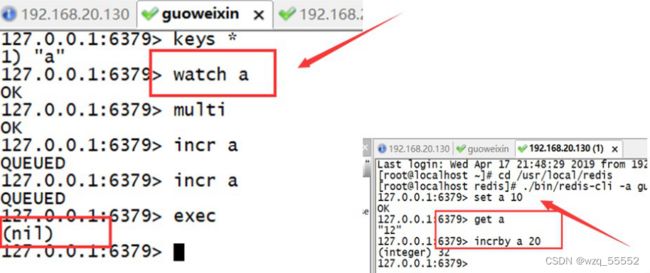
事务的WATCH
WATCH key [key ...]:监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。
需求:某一帐户在一事务内进行操作,在提交事务前,另一个进程对该帐户进行操作。
LUA语言与Redis
LUA脚本语言是C开发的,类似存储过程
使用脚本的好处如下:
1.减少网络开销;
2.原子操作;
3.复用性。
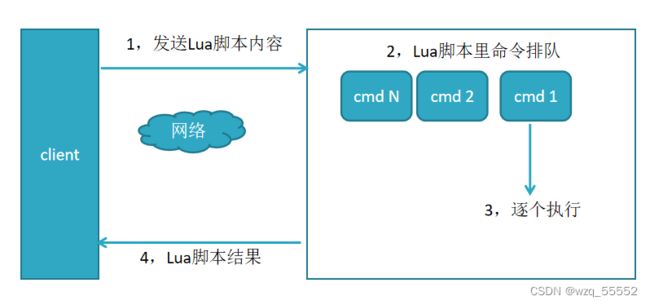
Redis慢查询分析
与mysql一样:当执行时间超过阀值,会将发生时间 耗时 命令记录
和很多关系型数据库(例如:MySQL)一样, Redis 也提供了慢查询日志记录,Redis 会把命令执行时间超过 slowlog-log-slower-than 的都记录在 Reids 内部的一个列表(list)中,该列表的长度最大为 slowlog-max-len 。需要注意的是,慢查询记录的只是命令的执行时间,不包括网络传输和排队时间。
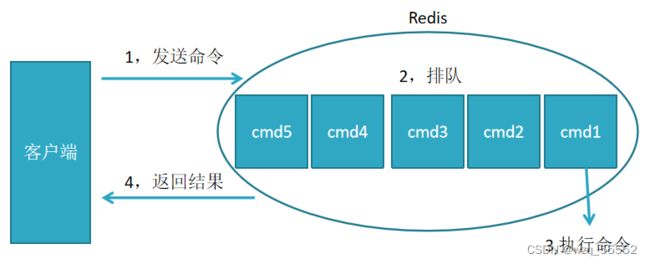
redis命令生命周期:发送 排队 执行 返回
慢查询只统计第3个执行步骤的时间
有两种方式设置慢查询阀值,默认为10毫秒
1.动态设置6379:> config set slowlog-log-slower-than 10000 //10000 微妙 10毫秒 使用config set完后,若想将配置持久化保存到redis.conf,要执行config rewrite
2.redis.conf修改:找到slowlog-log-slower-than 10000 ,修改保存即可
注意:slowlog-log-slower-than =0记录所有命令 -1命令都不记录
慢查询记录也是存在队列里的,slow-max-len 存放的记录最大条数,比如
设置的slow-max-len=10,当有第11条慢查询命令插入时,队列的第一条命令
就会出列,第11条入列到慢查询队列中, 可以config set动态设置,
也可以修改redis.conf完成配置。
获取队列里慢查询的命令:slowlog get
获取慢查询列表当前的长度:slowlog len //以上只有1条慢查询,返回1;
1,对慢查询列表清理(重置):slowlog reset //再查slowlog len 此时返回0 清空;
2,对于线上slow-max-len配置的建议:线上可加大slow-max-len的值,记录慢查询存长命令时redis会做截断,不会占用大量内存,线上可设置1000以上
3,对于线上slowlog-log-slower-than配置的建议:默认为10毫秒,根据redis并发量来调整,对于高并发比建议为1毫秒
4,慢查询是先进先出的队列,访问日志记录出列丢失,需定期执行slow get,将结果存储到其它设备中(如mysql)
Redis发布订阅
消息队列,不常有,一般都是kafka、rabbitmq。
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。 Redis 客户端可以订 阅任意数量的频道。
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
Redis 客户端可以订阅任意数量的频道。
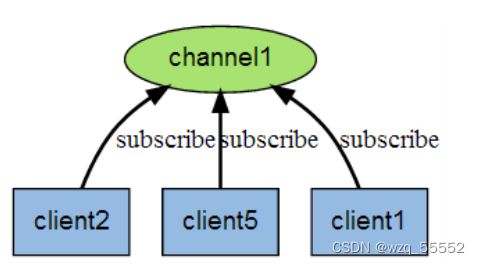
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、client5 和 client1 之间的关系
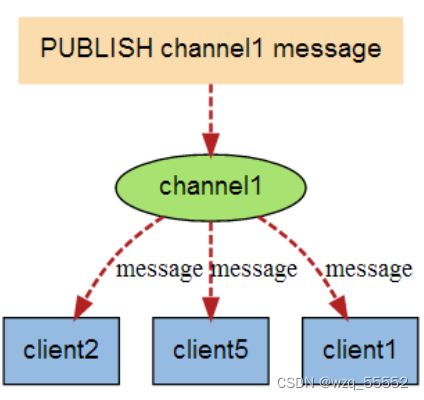
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
常用命令:
订阅频道:
SUBSCRIBE channel [channel ...] :订阅给定的一个或多个频道的信息 PSUBSCRIBE pattern [pattern ...] :订阅一个或多个符合给定模式的频道。
发布频道:
PUBLISH channel message :将信息发送到指定的频道。
退订频道:
UNSUBSCRIBE [channel [channel ...]] :指退订给定的频道。 PUNSUBSCRIBE [pattern [pattern ...]]:退订所有给定模式的频道。
应用场景:
这一功能最明显的用法就是构建实时消息系统,比如普通的即时聊天,群聊等功能 1在一个博客网站中,有 100个粉丝订阅了你,当你发布新文章,就可以推送消息给粉丝们。 2微信公众号模式
微博,每个用户的粉丝都是该用户的订阅者,当用户发完微博,所有粉丝都将收到他的动态;
新闻,资讯站点通常有多个频道,每个频道就是一个主题,用户可以通过主题来做订阅(如RSS),这样当新闻发 布时,订阅者可以获得更新
简单的应用场景的话, 以门户网站为例, 当编辑更新了某推荐板块的内容后:
- CMS发布清除缓存的消息到channel (推送者推送消息)
- 门户网站的缓存系统通过channel收到清除缓存的消息 (订阅者收到消息),更新了推荐板块的缓存
- 还可以做集中配置中心管理,当配置信息发生更改后,订阅配置信息的节点都可以收到通知消息