1.1 Machine learning -监督学习- 线性回归 :预测蜂蜜产量
我的offer太恶心了,坚定了我好好学习早日转行的信心。
监督学习:数据被标记,程序从输入数据中预测输出
无监督学习:数据是无标记的,程序学习识别输入数据的固有结构
简介:这主要是一个用线性回归预测蜂蜜产量的例子
一、了解数据
1、我们已经为你从Kaggle下载了关于美国蜂蜜生产的数据。它被称为df,有以下列:
- state
- numcol
- yieldpercol
- totalprod
- stocks
- priceperlb
- prodvalue
- year
第一步我们用.head()查看数据结构:
导入数据 主要用pandas、numpy、linear_model
import codecademylib3_seaborn
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn import linear_model
df = pd.read_csv("https://s3.amazonaws.com/codecademy-content/programs/data-science-path/linear_regression/honeyproduction.csv")
print (df.head())
2、现在,我们关心的是每年蜂蜜的总产量。使用panda提供的.groupby()方法来获得每年totalprod的平均值。
将其存储在名为prod_per_year的变量中。
prod_per_year = df.groupby('year').totalprod.mean().reset_index()
3、创建一个名为X的变量,它是prod_per_year DataFrame中的年份列,在prod_per_year数据集中创建一个名为y的变量,它是totalprod列。
创建后,我们将需要重塑它们,使其成为正确的格式:
X = prod_per_year['year']
X = X.values.reshape(-1, 1)
#print (X)
y = prod_per_year['totalprod']
#print(y)
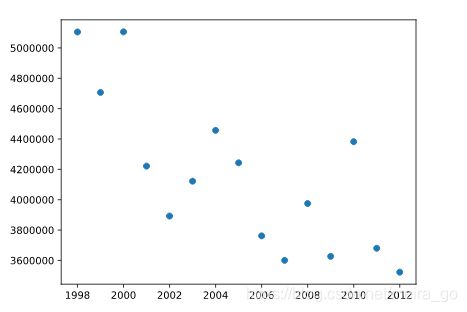
4、使用lt.scatter(),绘制y和X作为scatterplot。
使用plt.show()显示情节。
你能看出这些变量之间的线性关系吗?
plt.scatter(X,y)
#plt.show()
二、创建线性回归模型:
1、从scikit-learn中创建一个线性回归模型,并称之为regr。
使用来自linear_model模块的LinearRegression()构造函数来完成此任务。
使用. Fit()将模型与数据进行匹配。您可以将X作为.fit()的参数传入regr模型。
线性回归类来自于linear_model模块。
要创建一个新的LinearRegression对象,只需调用linear_model.LinearRegression()并将其赋给您的变量名:
my_regression_model = linear_model.LinearRegression()
regr = linear_model. LinearRegression()
regr.fit (X,y)
2、安装模型之后,打印出直线的斜率(存储在一个名为regr.coef_的列表中)和直线的截距(regr.intercept_)。
#print(regr.coef_[0])
#print(regr.intercept_)
3、创建一个名为y_predict的列表,这是您的regr模型对X数据的预测。
y_predict = regr.predict(X)
plt.plot(X,y_predict)
#plt.show()

三、预测部分
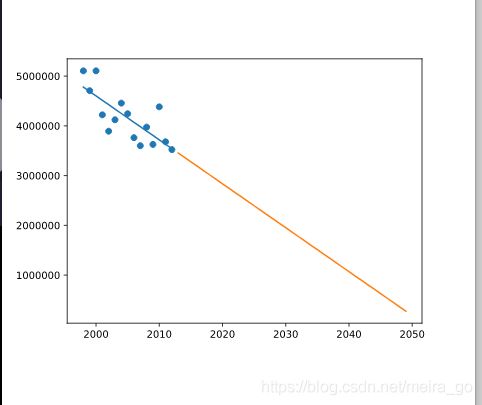
1、所以,根据这个线性模型,蜂蜜的产量似乎在下降。让我们预测一下2050年的蜂蜜产量。
我们已知的数据集止于2013年,因此让我们创建一个名为X_future的NumPy数组,它是2013年到2050年的范围。下面的代码创建了一个数字1到10的NumPy数组
nums = np.array(range(1, 11))
创建这个数组之后,我们需要为scikit-learn重新塑造它。
X_future = X_future.reshape(-1, 1)
您可以将reshape ()看作是旋转这个数组。X_future不再是一个大的数字行,而是一个大的数字列——每一行都有一个数字。
reshape()有点麻烦!在进行整形之前和之后打印出X_future可能会有帮助。
2、
创建一个名为future_predict的列表,它是您的regr模型为X_future的值所预测的y值。
3、Plot future_predict和X_future在不同的场景中。
根据这个,到2050年将生产多少蜂蜜?
X_future = np.array(range(2013, 2050))
X_future = X_future.reshape(-1, 1)
future_predict = regr.predict(X_future)
plt.plot(X_future,future_predict)
plt.show ()
完整代码:
import codecademylib3_seaborn
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn import linear_model
df = pd.read_csv("https://s3.amazonaws.com/codecademy-content/programs/data-science-path/linear_regression/honeyproduction.csv")
#print (df.head())
prod_per_year = df.groupby('year').totalprod.mean().reset_index()
# print(prod_per_year)
X = prod_per_year['year']
X = X.values.reshape(-1, 1)
#print (X)
y = prod_per_year['totalprod']
#print(y)
plt.scatter(X,y)
#plt.show()
regr = linear_model. LinearRegression()
regr.fit (X,y)
print(regr.coef_[0])
print(regr.intercept_)
y_predict = regr.predict(X)
plt.plot(X,y_predict)
#plt.show()
X_future = np.array(range(2013, 2050))
X_future = X_future.reshape(-1, 1)
future_predict = regr.predict(X_future)
plt.plot(X_future,future_predict)
plt.show ()