Remote Sensing Image Super-resolution and Object Detection: Benchmark and State of the Art
标题
遥感图像超分和目标检测的benchmark和SOTA。
摘要
在过去的二十年里,人们一直在研究遥感(RS)图像中的目标检测方法。在大多数情况下,用于遥感图像中小目标检测的数据集是不足的。许多研究人员使用场景分类数据集进行目标检测,这有其局限性;例如,在目标类别中,大尺寸目标的数量超过小目标。因此,它们缺乏多样性;这会进一步影响了RS图像中小目标检测器的检测性能。本文回顾了目前针对遥感图像的数据集和目标检测方法(基于深度学习)。我们也提出了一个大规模、公开可用的遥感超分辨率目标检测(RSSOD)数据集。RSSOD数据集由1,759张手工标注的图像组成,其中有22,091个空间分辨率约为0.05米的极高分辨率(VHR)图像实例。有五个类别,每个类别的标签频率不同;图像以YOLO和COCO格式标注。图像是从卫星图像中提取的,包括真实的图像失真,如切向比例失真和倾斜失真。提出的RSSOD数据集将帮助研究人员对各种类型最先进的目标检测方法进行基准测试,特别是对于使用图像超分辨率的小目标。我们还提出了一个新的多类(级)循环超分辨率生成对抗网络与残差特征聚合(MCGR)和辅助的YOLOv5检测器,以衡量基于图像超分辨率的目标检测,并与现有的基于图像超分辨率(SR)的最先进方法进行比较。所提出的MCGR在图像SR方面取得了最先进的性能,与目前最先进的NLSN方法相比,PSNR提高了1.2dB。MCGR对五类、四类、两类和单类的最佳目标检测mAPs分别为0.758、0.881、0.841和0.983,分别超过了最先进的目标检测器YOLOv5、EfficientDet、Faster RCNN、SSD和RetinaNet。
引言
目标检测和识别一直是计算机视觉的一个核心问题,它的目的是在图像中定位目标。过去十年在遥感领域,目标检测是一项重要的任务,它与各种应用密切相关,例如,地理资源的测绘、作物收获分析、灾害管理、交通规划和导航。由于其覆盖范围广,遥感图像有各种可以检测的目标,从小型到大型。因此,由于RS图像的多尺度性,其目标检测是一项具有挑战性的任务。但,深度学习的最新进展为目标检测和定位的突破提供帮助。
基于深度学习的方法对数据要求很高,其检测效率取决于输入数据的质量和数量。一个全面的、具有挑战性的数据集将有助于目标检测方法的进步,例如,ImageNet和MSCOCO数据集自推出以来一直是自然场景分类和目标检测的标准,大多数最先进的方法都使用这些数据集进行评估。同样,UC Merced和NWPU-RESISC45数据集促进了场景分类的进展,而ISPRS Vaihingen和38-Cloud数据集则为基于深度学习的遥感图像语义分割模型的发展指明了道路。最近的数据集如DOTA和DIOR处理了遥感中的常规目标。这些数据集(除了这些外还有很多),促进了研究人员在过去十年中开发新的数据驱动的目标检测和识别方法。
在光学RS图像的目标检测中,感兴趣的目标(在大多数情况下)所占的像素很少,例如,在地面采样距离(GSD)为0.5米的极高分辨率(VHR)图像中,一辆汽车(占地面积为4×1.5平方米)只占8×3(共24个像素)的像素格。对于小的目标,如车辆,几个像素就代表了整个目标;因此,识别和检测变得很有挑战性。一个GSD为0.25米的极高分辨率(VHR)卫星图像,对于一个尺寸为4×1.5平方米的车辆来说,将有一个96像素(16×6)的区域网格。因此,遥感目标检测的最新发展是在低分辨率(LR)图像中执行目标检测任务,就是利用图像超分辨率的概念,增加LR图像的空间分辨率,正如Courtrai等人和Bashir等人所做的那样。有必要对这种利用低分辨率图像进行目标检测的方法在具有挑战性的数据集进行基准测试。因此,遥感图像超分辨率目标检测(RSSOD)数据集将有助于这些研究人员对在高分辨率(HR)图像上执行的方法和检测任务进行基准测试。
文章的主要贡献如下:
-
一个大规模的公共数据集,RSSOD,用于城市环境中的小目标检测任务(样本图像见图1)。这个数据集有22,091个手工标注的实例和5个类别,由于其地理信息和标注的方向,该数据集将为研究人员提供一个具有挑战性的检测。

图一 -
在我们提出的RSSOD数据集实验了当前最先进的模型性能基准。
-
我们还提出了一种新的多类(级)循环超分辨率生成对抗网络并将其与残差特征聚合结合起来(MCGR),用于在比例因子为2和4的低分辨率图像中的目标检测。
回顾遥感目标检测数据集和方法
在过去的十年中,研究人员已经开始探索用于遥感的目标检测数据集和方法。这主要是因为卫星传感器设计的进步,高质量的VHR图像现在可以用于深度学习。在本节中,我们简要回顾一下目前遥感中目标检测的数据集和方法。
遥感图像的目标检测数据集
由于遥感中的图像是俯视图,而且由于卫星有效载荷中传感器设计的变化,目标的大小是多样化的,所以目标实例在大小和方向上往往有很大的偏差。先前的数据集包括NWPU-RESISC45、NWPU VHR-10、DIOR、DOTA。在本节中,我们简要介绍了目前遥感目标检测和识别的数据集。
- TAS数据集。TAS数据集用来检测航空图像中的车辆,因为它包含了30幅图像,共有1319辆任意方向的汽车。其缺点是分辨率低,附近的建筑物和树木会投射出阴影影响检测。
- UC Merced Land-Use数据集。这是一个21类场景分类数据集,每类有100张256×256的图像。图像提取自美国地质调查局国家地图城市区域图像,空间分辨率为0.3048m。 UC Merced是遥感场景分类中使用最多的数据集之一,它有重叠的类别,如稀疏住宅区、高密度住宅区和中等密度住宅区,使这个数据集更加丰富,更具挑战性。一些遥感影像分类研究包括LGFBOVW分类器、LASC-CNN分类器、混合卫星影像分类系统、结构化度量学习、mcODM分类器、基于特征工程的分类器。
- NWPU数据集。NWPU的研究人员最初提出的遥感图像分类数据集被称为NWPU-RESISC45,它共有45个类别,每个类别有700张图像。该数据集的空间分辨率约为0.2至30米,而图像大小被固定为256×256。由于其规模(共有31,500张图像),该数据集被广泛用于场景分类;然而,大多数图像的空间分辨率较低,因此另一个带有VHR图像的数据集被称为NWPU VHR-10,其中包括715张空间分辨率为2m的图像和85张空间分辨率为8cm的图像。在提出的数据集中有10个类别,它还包括负面的例子。然而,缺点是它包括一些小尺寸的目标,由于它们的尺寸只有几个像素,所以没有被标记(例如,车辆类)。与NWPU-RESISC45不同的是,这个数据集是一个目标检测数据集,并且在这个数据集中使用了水平边界框(HBB)注释。研究人员经常将这些数据集用于遥感场景分类和目标识别任务。
- VEDAI。Razakarivony等人的这个数据集用于多类车辆检测,因为它总共包含了3640个车辆实例,其中包括9个类别,即船、汽车、野营车、飞机、皮卡、拖拉机、卡车、货车和其他类别。这个数据集包括总共1210幅图像,空间分辨率为12.5厘米,尺寸为1024×1024。研究人员经常使用这个数据集来衡量遥感中的目标检测。另一个车辆类数据集是DLR MVDA,它使用DLR 3K相机系统在1000米的高度上拍摄VHR图像,空间分辨率为13厘米。DLR MVDA使用定向边界框(OBB)进行注释,并使用多方向框来指示车辆的方向。
- RSC11数据集。这个数据集也是从谷歌地球上提取的,它包括11个场景类别,包括一些非常相似的类别场景,这使得这个数据集的分类变得困难。该数据集的空间分辨率为0.2米,共有1232幅图像,其中有一个图像的分辨率为0.1,图像大小为512×512。
- ISPRS Potsdam。该数据集是国际摄影测量和遥感学会的一个语义分割数据集。该数据集包含38张尺寸为6000×6000、空间分辨率为5厘米的VHR图像。该数据集已被广泛用于语义分割和目标检测任务,特别是在城市环境中,因为该数据集包括六个类别,即不透水表面、建筑物、低矮的 植被、树木、汽车和杂波。
- RSOD数据集。Xiao等人共收集了976张空间分辨率为0.5-2米的图像。这个数据集有四个类别,即油罐、飞机、天桥和操场。
- DOTA数据集。Xia等人的这个数据集是一个大型目标检测数据集,共有15个目标类别,包括大型目标(如桥梁、港口、篮球场)和小型目标(如小型车辆)。该数据集共包括2,806张不同分辨率的图像,有超过188k个目标实例。由于图像大小和空间分辨率的显著变化,目标的尺度、方向和形状也各不相同,使检测任务更具挑战性。
- DIOR数据集。Li等人的DIOR数据集包含23000张图片,有超过192000个实例和20个目标类别(每类约1200张图片)。在这个数据集中使用了基于HBB的注释,而后来发布的DIOR-R版本则使用了更新的OBB注释,用于OBB目标检测任务。

表一描述了提出的RSSOD数据集与现有数据集的比较。与其他目标检测数据集相比,RSSOD数据集具有最高的空间分辨率。数据集拥有高分辨率的图像,即约1000×1000像素,强调小目标。
遥感图像目标检测方法
目标检测方法主要有两种,即把检测作为端到端学习任务进行的通用目标检测器,或基于SR的方法,在目标检测前使用先验网络来提高图像质量。本节回顾了目前的通用对象检测器,包括一些最先进的小型对象检测器和基于图像SR的对象检测器。
-
通用目标检测器
近年来,基于深度学习的方法已经成功地实现了分类、检测和识别任务。在这些任务中,目标检测是最突出的领域之一,每年都会得到扩展,许多目标检测器正在被开发和发布。检测任务可以是单阶段的,也可以是双阶段的;在后者中,会产生region proposals,然后是bbox分类任务。
最早的2阶段检测器之一是基于基于区域的卷积神经网络(RCNN),它采用ss算法(Uijlings等人,2013)进行区域提议,这些提议被传递给CNN,用于生成每个提议区域的特征向量。在RCNN中,最终的分类任务由支持向量机(SVM)完成。RCNN过渡到Fast RCNN,它在最初的RCNN中引入了两个主要变化;第一个变化是在感兴趣的区域中引入共享特征图。第二个变化是用全连接(FC)神经网络取代SVM,用于目标分类和bbox回归;这允许端到端训练,实现实时目标检测。RCNN的另一个修改,Faster RCNN,作者引入了一个无成本的区域提议网络(RPN),这在 Pascal VOC数据集产生了5fps的最先进结果。
最初使用one stage检测器是为了以检测精度为代价实现高帧率;例如,You-Only-Look-Once(YOLO)模型在Pascal VOC 2007和2012上实现了45帧,平均平均精度(mAP)为63.4%,而Faster RCNN以0.5帧实现了mAP为70.0。因此,实时目标检测器的时代开始了,这开启了视频流上实时目标检测器的领域。另一个one-stage检测器是Single-Shot Detector(SSD)它通过消除区域提议阶段,在一个单一的过程中完成目标的定位和分类。具有固定尺寸的边界框被用于目标检测,最后的检测是使用非最大抑制进行的。通过在SSD中加入焦点损失,RetinaNet能够超越所有最先进的two-stage检测器的准确性,同时保持one-stage的速度。
Redmon等人提出了YOLO的最初三个版本;YOLO-v2和YOLO-v3。这些新的检测器纳入了更深的后端CNN、残差块和跳过连接,产生了最先进的性能,速度比RetinaNet高3.8倍。2020年,Bochkovskiy等人提出了YOLOv4,它利用了一个新的后端网络,称为CSPDarknet53,具有空间注意力和Mish-activation,与YOLOv3相比,mAP和fps(在MS COCO Dataset上)分别提高了10%和12%。在YOLOv4的一个月内,Jocher发布了YOLOv5版本,该版本取得了最先进的性能mAP和fps。YOLOv5x6模型在MS COCO Val 2017数据集上报告的最高mAP为55.4%,每幅图像的推理时间为19.4ms,目前在最先进的目标检测器中排名第一;各种模型的比较与 EfficientDet的比较见图2。

-
RS图像中小尺寸目标的检测器
这里我们讨论一些最先进的图像SR方法,用于LR到HR图像的SR,这些方法最近被不同的研究者进一步用于RS图像的小目标检测。
-
最先进的图像SR方法
这里我们讨论一些最先进的图像SR方法。2017年,Lim等人引入了增强型深度SR网络(EDSR)。最近(Rabbi等人,2020;Shermeyer & Van Etten,2019;Wei & Liu,2021),EDSR已经成为遥感图像中小目标检测的一个组成部分,但报告的这类检测器的检测mAP很低。
Wang等人对现有的SR生成对抗网络(GAN)架构提出改进,并提出了用于现实图像SR的ESRGAN。Wang等人引入了残差密集块(RRDB)以及对抗性和感知性损失。Wang等人报告了进一步的改进,他们用纯合成数据训练ESRGAN,使用接近真实世界的高阶退化建模。
Liang等人提出了SwinIR,通过在SwinIR变换器中加入三个部分:浅层特征提取、深层特征提取和使用Residual Swin Transformer Blocks(RSTB)的高质量图像重建,使用RSTB来解决图像SR。SwinIR在DIV2K和Flickr2K数据集上取得了最先进的性能。
在图像SR中,模型的整体性能取决于用于生成LR图像的退化模型;大多数模型考虑了额外的因素,如模糊;但现实世界的退化仍然是多样的;为了解决这个问题,Zhang等人在BSRGAN中提出了一个更实用的退化模型。BSRGAN退化模型生成的LR图像具有随机的blue shuffle、下采样和噪声退化,使得退化更加真实。
在DRN中,提出了一个双回归网络来学习LR到HR的映射和相应的退化映射函数,即HR到LR,它学习了下采样核。与EDSR、RCAN、RRDB等方法相比,该方法在PSNR和参数数量方面取得了最先进的性能。
Mei等人提出了一种用于图像SR的非局部稀疏注意(NLSA)方法;非局部注意是通过球形散列将输入分为相关特征的散列桶,从而在学习过程中不关注噪声和信息较少的位置。该网络被命名为NLSN,即非本地稀疏网络,它在Set14、B100、Urban100、Manga109数据集上取得了最先进的性能。
-
基于图像SR的小目标检测器
目标的大小是目标检测任务中的一个关键参数,尤其是整个推理图像。目前最先进的检测器在大中型目标上能有效地工作,但当涉及到小尺寸的目标(即尺寸在几个像素或占据整个图像尺寸的5%以下)时,通用目标检测器的性能会成倍下降。由于尺寸小,小目标的特征与其他类别的特征无法区分,这导致了检测的不准确性。提高检测性能的一种方法是通过简单地复制小目标,对感兴趣的小目标进行过采样,从而进行数据增强。增强技术增加了与预测和地面实况重叠的可能性,从而提高了预测精度。然而,由于增强过程中的重叠,这种技术会降低其他目标类别的检测精度;即使与其他目标的重叠为0,由于在背景上粘贴目标,负面样本也会减少,这可能会增加检测任务中的假阳性率。小目标检测的另一种方法是在多个分辨率上对小目标和大目标进行网络训练正如Park等人所做的那样。
对于小目标检测,辅助图像SR网络可以在实际检测任务之前提高数据集的空间分辨率,正如Courtrai等人和Bashir等人所做的。近年来,图像SR网络在2×和4×的比例系数上取得了重大成果。一些基于深度学习的方法从LR生成HR图像,包括单图像SR(SISR),它通过将单张图像作为输入来执行SR任务。关于所有图像超分辨率方法的详细回顾,包括传统的和基于深度学习的方法,我们鼓励读者阅读Yang等人和Bashir等人的文章。
Ferdous等人提出了two-stage检测器使用GAN的图像SR和使用SSD的目标检测,而Zhang等人使用弱监督学习,使用伪标签生成方法学习RS图像中的目标检测。另外,Rabbi等人结合ESRGAN和Edge-Enhanced GAN(EEGAN)开发了一个端到端的小目标检测网络,使用Faster RCNN和SSD进行目标检测。
-
RRSOD数据集
在这一节中,我们介绍了RSSOD数据集以及关于数据收集、类别选择、标注方法、数据分割、图像尺寸、空间分辨率和物体方向的信息。
图像收集
我们回顾了遥感场景分类和目标检测数据集(见表1),意识到缺乏高分辨率的城市物体检测数据集。我们从已经公开的其他任务(如场景分类)的数据集中收集数据。城市图像是从ISPRS Potsdam语义分割数据集中提取的,其中我们从38张VHR图像中提取1000×1000像素大小的块,重叠部分为100像素。为了重现性,我们使用了与原始数据集相同的名称,并使用一个额外的两位数来表示块编号;总共从单个图像中提取了36个块,即总共有1368张图像。RSSOD数据集的总体图像选择见表2。平均图像分辨率为856×853。

这些图像是由多个传感器拍摄的,物体的方向是随机的,物体的位置也是随机的,如图3a所示。大多数物体比较小,如图3b所示。

类别选择和数据分割
在遥感中,感兴趣的目标是最重要的;在大多数物体检测数据集中,常见的类别包括车辆(包括地面车辆、船舶和飞机)、树木、建筑物、不透水表面和低植被。考虑到物体的大小,我们省略了建筑类,因为大多数图像来自城市环境,建筑占据了大部分的图像空间;因此,最终考虑的类包括车辆、树木、飞机、船舶和低植被。类别的细节实例显示在表3中。

数据集按照传统的70:20:10的比例被分割为训练、验证和测试子集。图4描述了训练、验证和测试图像的总体实例分布。训练、验证和测试实例分别为1232、351和176。

标注方法
对于标注,我们选择了基于HBB的标注,并使用基于Python的开源标签工具OpenLabeling,对图像进行标注。所有的物体都使用YOLO格式手动标注,使用一个点和宽度,边界框(BB)的高度,即:<类标识符,x,y,w,h>;其中(x, y)表示BB的中心,而(w, h)分别表示宽度和高度。
标注是通过三轮的人工审查来完善的,在审查过程中解决了标签中的任何人为错误。此外,注释被分成四组,包括五个、四个、两个和一个类别。这样做是为了方便对不同类别的物体进行检测,并查看检测器对类别子集的性能。图5显示了一些来自RSSOD的标注图像。

使用多类(级)循环GAN与RFA进行小目标检测
在这一节中,我们提出了一个新的多类(级)循环GAN,它带有残差特征聚合(RFA),用于RSSOD数据集的物体检测。提出的网络基于两个任务。即图像SR和物体检测。我们首先介绍提出的图像SR网络。
基于图像SR的目标检测的MCGR
我们首先将SRResNet和EDSR中提出的图像SR中的传统残差块替换为基于RFA的块(见图6),该块使用Bashir等人提出的1×1卷积层聚合所有残差块的特征。这种特征串联增强了网络的性能并因此提高了SR图像的质量。

此外,我们使用SRGAN的修改形式,其中包括基于RFA的残差块和基于Wasserstein GANs的循环网络,使用L1和L2损失函数来训练网络;提出的循环GAN的网络如图7。

颜色代表含义与图6相似,浅蓝色代表还原层,棕色代表像素重排层。循环GAN(如图7所示)使用一个二级GAN,LRGEN。
从HRGEN生成的HR图像中生成LR图像。这个循环模型的整体损失函数如公式1所示:

其中,IHR和ILR是HR和LR图像;HRGEN和LRGEN是相应的HR和LR生成器,如图7所示。
通过比较LR-LRGEN,我们确保生成的LR图像与实际的LR相似,从而使网络生成的HR图像也将与实际的HR图像相似。这种循环的方法确保了两个GAN通过评估彼此产生的输出,使整体损失最小化。此外,在最后使用了一个检测网络,一个YOLOv5检测器,如图8所示。
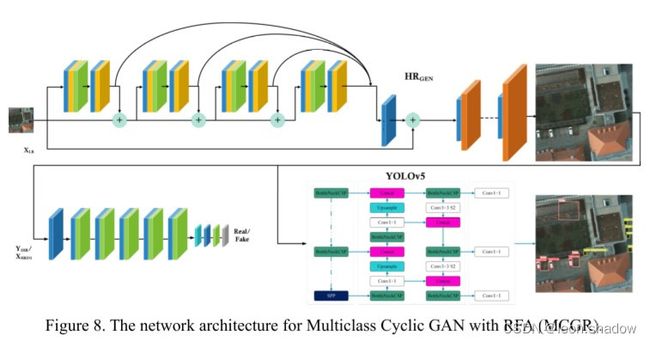
图8中所示的三个网络有不同的损失函数,总的损失函数是生成器、鉴别器和检测器的损失函数的加权和。生成器网络的损失函数在公式(2)中给出:

其中,L(HRGEN)是生成网络的损失,N是样本总数,HRGEN(Ii LR)是第i个生成的HR图像,而Ii HR是第i个真实HR图像。
使用改进的WGAN与YOLOv5,一个基于48块RFA的生成器,块大小为64×64,核为3×3;在鉴别器网络中使用高梯度惩罚系数,鉴别器损失L(Dis)在公式(3)中给出:

其中IHR、ISR和Iran,是HR、SR和从{IHR、ISR}中均匀采样的随机图像。HR、SR和随机图像的概率密度分布分别为PHR、PSR和Pran。梯度惩罚系数λ被赋予10的高值。最终的YOLOv5网络有一个bbox损失函数,如公式(4)所示:

其中Det和Anc代表检测网格和锚点的数量,而HR和SR预测的BB的坐标用(x,y,w,h)和(x′,y′,w′,h′)表示。(x, y)和(x′, y′)代表BB的中心点,而(w, h)和(w′, h′)分别代表真实和预测BB的宽度和高度。图8中的网络是使用总损失函数L(Tot)进行训练,如公式(5)所示:

权重系数μ1、μ2和μ3,分别为0.90、10和0.10。这一选择被用来规范三个网络产生的误差,从而给训练过程带来稳定性。因此,使用生成器生成的SR图像,目标类别识别和目标定位是由检测网络完成的。
评估方法
所提出的方法利用了图像SR的概念,在检测任务之前提高了图像质量。因此,我们使用图像质量指标,如PSNR、SSIM和任务评估(目标检测)来比较和对比提出的SR与现有的最先进的方法进行比较。
对于目标检测,我们测量了[email protected] IoU进行跨类的物体检测,并与现有的使用YOLOv5作为辅助检测器的目标检测方法进行比较。最近,这个指标被用来评估目标检测器。由于大多数物体的尺寸较小,因此在推理任务中选择了低值的IoU和Confidence threshold。
实施细节
所提出的网络使用PyTorch框架和Ubuntu 20.04计算机,并使用Nvidia的Titan XP图形处理器来实现。在训练阶段,总损失函数的系数μ1、μ2和μ3分别为0.90、10和0.10,并对网络进行了100个epochs的训练。
RSSOD的基准结果
在本节中,我们分享了使用最先进的图像SR和目标检测方法在RSSOD数据集上的基准测试结果。训练是在训练集上进行的,并对验证集进行了验证,而最终的评价是基于测试集的。我们还讨论了基准测试结果,以提供关于提出的MCGR网络在遥感图像中使用提出的RSSOD数据集进行目标检测的见解。
图像质量评估
我们使用三个主要的定量图像质量评估(IQA)指标来评估SR结果,即MSE、PSNR和SSIM。此外,我们还比较了提出的MCGR和最先进的NLSN方法在恢复复杂纹理方面的SR图像质量。LR版本的比例系数为4;我们比较了MCGR与HR图像、Real-ESRGAN、SwinIR-L、BSRGAN、DRN、EDSR、NLSN的结果,如图9和10所示。

如图9所示,Real-ESRGAN、SwinIR-L和BSRGAN做了过度的平滑处理;因此,汽车下面的地面纹理信息没有被恢复。另外,DRN混合了相邻像素的信息,导致图像质量不高。EDSR和NLSN恢复了图像中的高层次信息,但纹理信息,包括高频细节,则由提议的MCGR网络来恢复。图10描述了飞机类图像的SR结果,这证实了所提出的MCGR网络的优越性。

我们还在图11中展示了与表现第二好的方法NLSN相比的图像SR结果。在这里,放大的块描述了提出的MCGR使用基于RFA的循环GAN从LR图像中恢复真实世界的纹理。颜色表示物体的位置,而左半边四个方框是MCGR的结果,右边是NLSN的结果。图11中放大的图像显示了两种方法恢复的细节质量。

测试集的IQA指标摘要见表4。双三次插值的平均PSNR为30.23 dB,而提出的MCGR在MSE、PSNR和SSIM方面取得了最先进的性能。MCGR的最佳PSNR为34.68 dB。而NLSN、EDSR和DRN的PSNR分别为33.48 dB、33.13 dB和32.69 dB。MCGR的最佳MSE为27.98,而NLSN、EDSR和DRN的PSNR分别为33.48 dB、33.13 dB和32.69 dB。MCGR的PSNR为34.68 dB,而NLSN、EDSR和DRN的PSNR分别为31.17、37.64和44.89。MCGR取得了SSIM为0.93的最佳结果,而NLSN、EDSR和DRN分别为0.88、0.89和085。

如图9-11和表4所示,所提出的MCGR在从LR图像中恢复高频信息方面取得了最佳效果。在这里,我们还分享了使用精度/召回曲线对四个独立的网络进行训练的性能,其比例系数为4,用于五类、四类、两类和一类物体检测。训练进行了100个epochs,检测的mAP和精度/召回的曲线见图12。

从图12所示的训练性能可以看出,所提出的MCGR对于一个和两个类的收敛速度非常快(即在25个epoch以下),而对于四个类,网络在40个epoch后达到了稳定的mAP,树类的最低mAP为0.717,而车辆类的最高mAP为0983。对于五个类,学习变得有点困难,因为低植被类与树类相当相似,因此mAP0.5 IoU时达到了0.265。在五个、四个、两个和一个类上训练的四个模型的训练mAP分别为0.758、0.881、0.841和0.983。
目标检测器的基准评估
在本节中,我们讨论了RSSOD数据集上的物体检测结果与最先进的检测器如RetinaNet、SSD、Faster RCNN、EfficientDet-D5和提出的MCGR的比较。为了避免测试推理过程中的偏差,我们使用RSSOD-训练集的HR图像来训练有验证集的目标检测器。在RSSOD-测试集上,输入尺寸为640×640像素的五类物体检测结果见表5。对于HR测试图像,YOLOv5报告的最佳检测mAP为0.76,而第二好的mAP为0.746,由MCGR实现。同样明显的是,随着比例因子(SF)的增加,通用检测器的检测性能会随着物体尺寸的缩小而恶化。然而,MCGR在SF为2和4时分别达到了0.731和0.711的mAP。

所提出的网络在HR和LR图像上都取得了最先进的性能,每幅图像的推理时间相对合理(即16.61ms)。图13显示了测试集上一些图像的检测性能。

利用图像SR的MCGR检测小物体,明显提高了物体检测的效果,然而,推理时间比YOLOv5高四倍,但这明显优于其他的方法,这表明了MCGR的优越性能。
独立数据集上MCGR表现
我们还对独立的数据集DroneDeploy进行了MCGR网络基准测试,并在图14中分享了1000×1000像素块的物体检测结果。以验证提议的MCGR的性能。

我们还对Gąsienica-Józkowy等人的另一个空中数据集–浮动物体空中数据集(AFO)进行了MCGR测试,该数据集包含有六个类别的微小物体。Gąsienica-Józkowy提出的Ensembled方法在IoU为0.50的情况下实现了0.8216的物体检测mAP,而我们的MCGR实现了最先进的性能,mAP为0.845,见图15。关键的挑战是如何学习占据图像总面积不到1%的小物体的特征。

结论和未来发展方向
RS图像中的物体定位和检测任务是一个持续研究的课题;因此,为环境遥感开发最先进的物体检测器是最重要的。在本文中,我们为遥感物体检测器提出了一个新的基准RSSOD数据集,该数据集具有高度重叠的类别和复杂的设置,强调小尺寸物体。我们还提出了一个基于RFA的MCGR网络,实现了最先进的图像SR质量和物体检测任务。目前对车辆、飞机和船舶等类别的检测精度是令人满意的,而对于树和低植被类的复杂特征,还需要进一步探索学习。
广泛的实验表明,在物体检测任务之前使用图像SR网络有助于提高物体检测的mAP,所提出的MCGR在mAP方面比最先进的YOLOv5分别高出5%和13%,比例系数为2和4。此外,我们还分享了一个独立数据集上的物体检测结果,这显示了所提出的MCGR网络在其他数据集上进行物体检测的灵活性。
参考文章
Wang Y, Bashir S M A, Khan M, et al. Remote sensing image super-resolution and object detection: Benchmark and state of the art[J]. Expert Systems with Applications, 2022: 116793.