python学生成绩分析实验报告_用python对学生成绩进行预测
1、提出问题
影响学生考试成绩的因素有哪些?
2、理解数据
2、数据概况分析
2.1采集数据
该数据集来自kaggle,数据集包含了学生考试相关的17个变量。
https://www.kaggle.com/aljarah/xAPI-Edu-Datawww.kaggle.com2.2导入数据
import pandas as pd
sp=pd.read_csv("xAPI-Edu-Data.csv") #导入数据2.3查看数据集信息
#1.查看数据集大小
print("数据集大小",sp.shape)
#2.查看各字段数据类型,缺失值
print(sp.info())
数据集说明
- gender ——性别
- Nationality——国籍
- Placeofbirth——出生地
- StageID——教育阶段
- GradeID——年级
- SectionID——班级
- Topic—— 课程主题
- Semester- 学期
- Relation——谁对学生负责
- raisedhands——学生举手次数
- VisiTedResources- 学生访问课程次数
- AnnouncementsViewing——学生查看通知次数
- Discussion——学生参加讨论组的次数
- ParentAnsweringSurvey——家长回答是否由学校提供的调查
- ParentschoolSatisfaction —— 家长对学校的满意程度
- Student Absence Days——学生缺席的天数
- class——成绩
#观察数据统计描述
sp.describe() #仅对数值型数据进行统计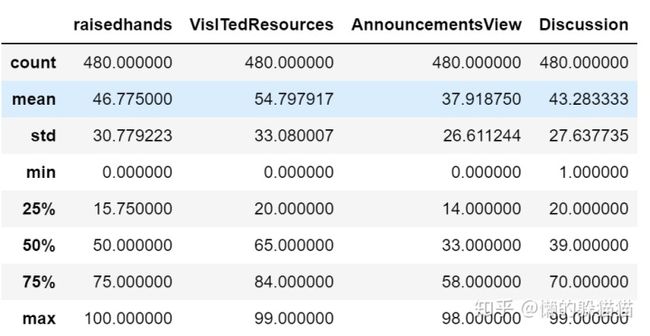
- 整体数据不存在缺失值。
- 类别型变量较多
- 数字型变量不存在较明显异常值。
3.单变量分析
3.1类别型变量
import matplotlib.pyplot as plt
%matplotlib inline
fig1 = plt.figure(facecolor='white',figsize=(16,10))
ax1=plt.subplot(2,3,1)
plt.pie(sp['gender'].value_counts(),labels=['M',"F"],autopct='%1.1f%%',startangle=0)
plt.axis('equal')
plt.title('性别分布情况')
ax1=plt.subplot(2,3,2)
plt.pie(sp['NationalITy'].value_counts(),labels=list(set(sp['NationalITy'].values.T.tolist()[:])),autopct='%1.1f%%',startangle=0)
plt.axis('equal')
plt.title('国籍分布情况')
ax1=plt.subplot(2,3,3)
plt.pie(sp['PlaceofBirth'].value_counts(),labels=list(set(sp['PlaceofBirth'].values.T.tolist()[:])),autopct='%1.1f%%',startangle=0)
plt.axis('equal')
plt.title('出生地分布情况')
ax1=plt.subplot(2,3,4)
plt.pie(sp['StageID'].value_counts(),labels=list(set(sp['StageID'].values.T.tolist()[:])),autopct='%1.1f%%',startangle=0)
plt.axis('equal')
plt.title('教育阶段分布情况')
ax1=plt.subplot(2,3,5)
plt.pie(sp['GradeID'].value_counts(),labels=list(set(sp['GradeID'].values.T.tolist()[:])),autopct='%1.1f%%',startangle=0)
plt.axis('equal')
plt.title('年级分布情况')
ax1=plt.subplot(2,3,6)
plt.pie(sp['SectionID'].value_counts(),labels=list(set(sp['SectionID'].values.T.tolist()[:])),autopct='%1.1f%%',startangle=0)
plt.axis('equal')
plt.title('班级分布情况')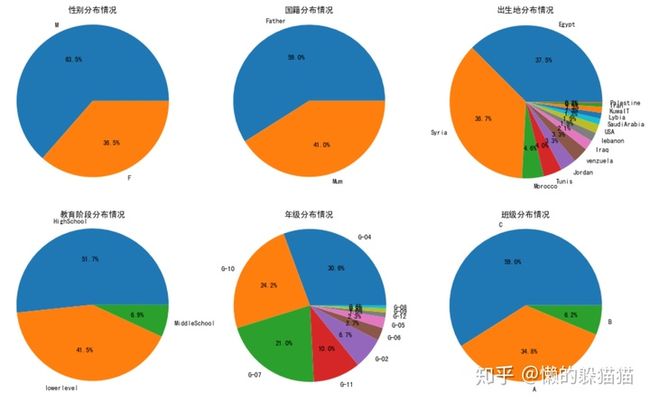
- 学生中女生数量多于男生,学生的国籍、出生70%是埃及或叙利亚。学生来自高中最多,小学次之,初中最少。学生年级大多是4,、7、10年级,班级中A班和C班较多。
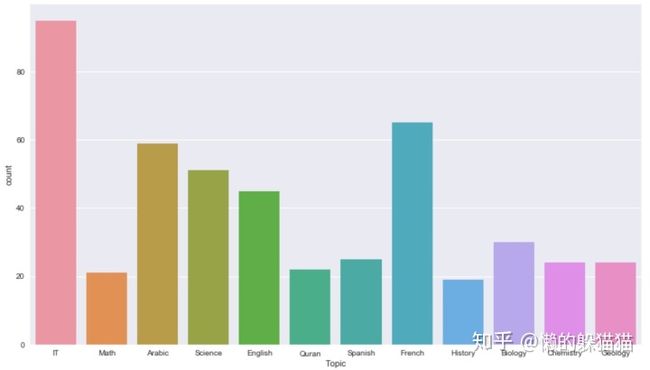
- 学科方面:学IT的学生人数最多,其次是法语,人数最少的是历史,学it的人数几乎是学历史的5倍左右。
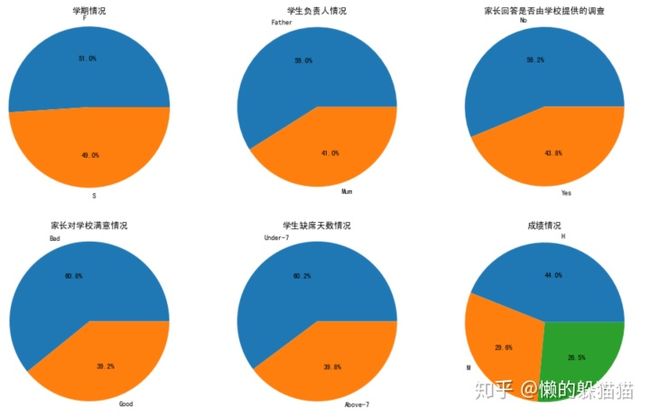
- 学生负责人是妈妈比较多,超过60%的家长对学校满意
- 有60%的学生缺席次数不超过七天,学生成绩等级达到优秀的最多,中等次之。
3.2数值型变量
#看一下它们的分布
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
fig,axes=plt.subplots(2,2)
fig.set_size_inches(12,10)
sns.distplot(sp['raisedhands'],ax=axes[0,0])
sns.distplot(sp['VisITedResources'],ax=axes[0,1])
sns.distplot(sp['AnnouncementsView'],ax=axes[1,0])
sns.distplot(sp['Discussion'],ax=axes[1,1])
axes[0,0].set(xlabel='raisedhands')
axes[0,1].set(xlabel='VisITedResources')
axes[1,0].set(xlabel='AnnouncementsView')
axes[1,1].set(xlabel='Discussion')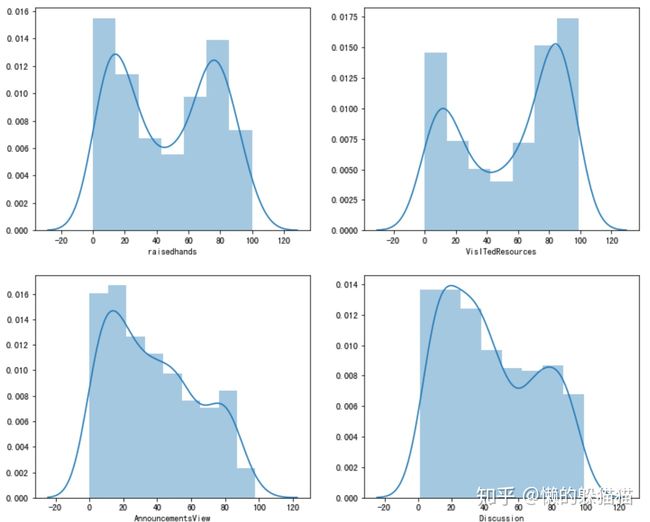
- 学生举手次数和访问课程次数比较平均,有学生举手次数或访问课程次数达到100%,也存在学生从不举手或访问课程
- 大部分学生查看通知和参加讨论的次数较少。
4、多变量分析
4.1性别和成绩的相关性分析
sns.countplot(x='gender',hue='Class',order=['M','F'],hue_order=['L','M','H'],data=sp)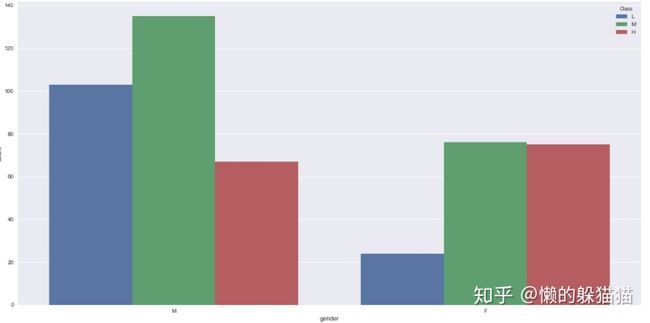
从图中看出男生中取得中等成绩的最多,其次是不及格的人数,成绩优秀的占比较小。而女生中大部分人取得中等及其以上,只有小部分人不及格,整体水平较好。
4.2了解学科和成绩的相关性
sns.set(rc={'figure.figsize':(20,10)})
sns.countplot(x='Topic',hue='Class',hue_order=['L','M','H'],data=sp)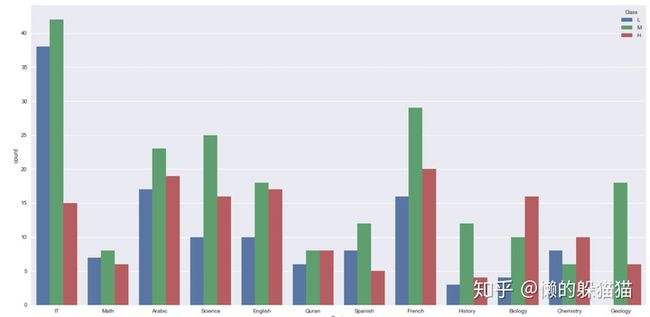
从图中我们可以看出,对于12个学科,有11个学科都存在着部分同学处于不及格的状态,只有地质学这门课程学生全部达到中等及以上。对于IT这门课程,虽然学习的人数最多,但是大部分同学获得的成绩在中等及中等以下,只有少部分学生的成绩达到优秀,说明学生对于这门课程的掌握程度还有待于提升;学习历史的人数最少,但是成绩中等的学生最多,成绩优秀和成绩较差的学生相对较少。
4.3了解班级和成绩的相关性(SectionID:班级)
sns.countplot(x='SectionID',hue='Class',hue_order=['L','M','H'],data=sp)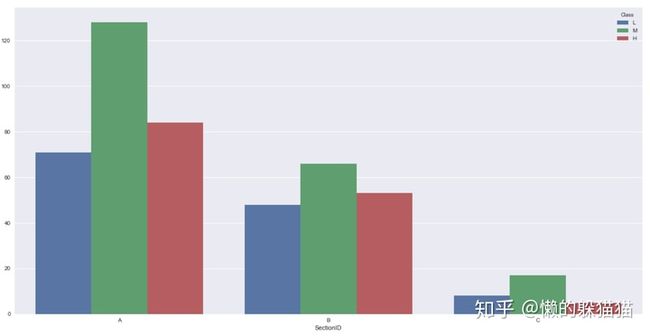
从图上看,班级和成绩分布符合客观规律,每个班级都是中等成绩的人数最多。
4.3了解学生负责人和学生成绩的相关性
sns.countplot(x='Relation',hue='Class',hue_order=['L','M','H'],data=sp)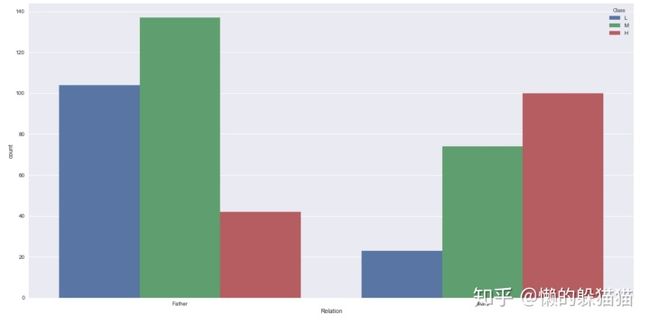
从图上看,学生负责人是母亲的学生学习成绩中优秀的多,中等次之,不及格少,而负责人是父亲的则相反。
5.学生成绩预测
5.1特征选择和查看相关洗漱
s=pd.get_dummies(sp)#把所有的非数值型变量转化为数值型
corrDf = s.corr() #计算各个特征的相关系数
corrDf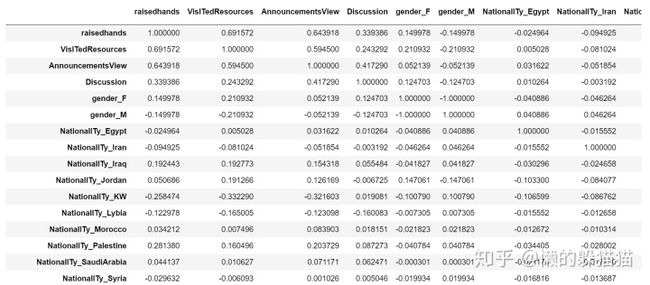
'''
查看各个特征与优秀成绩('Class_H')的相关系数,
ascending=False表示按降序排列
'''
corrDf['Class_H'].sort_values(ascending =False)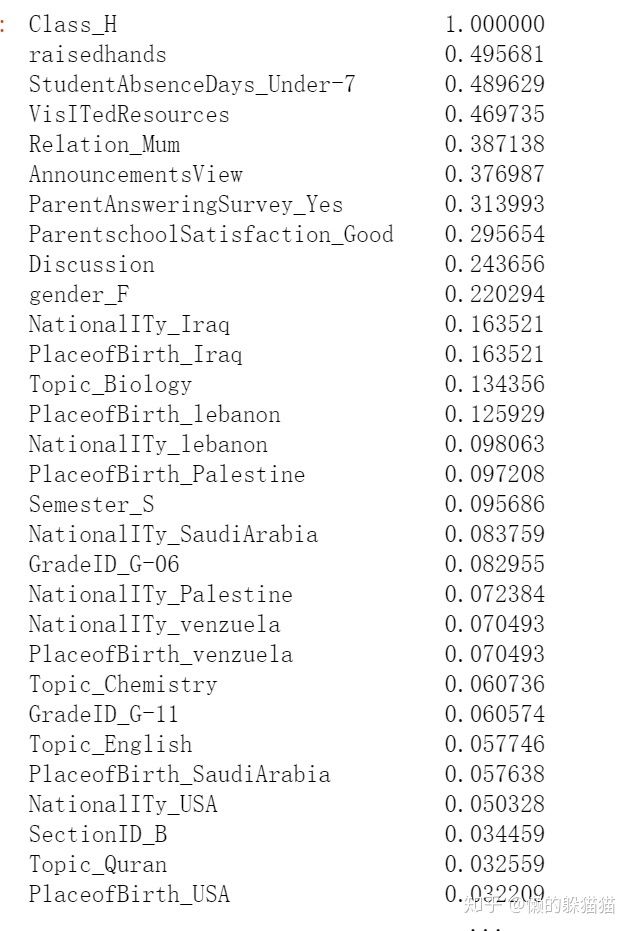
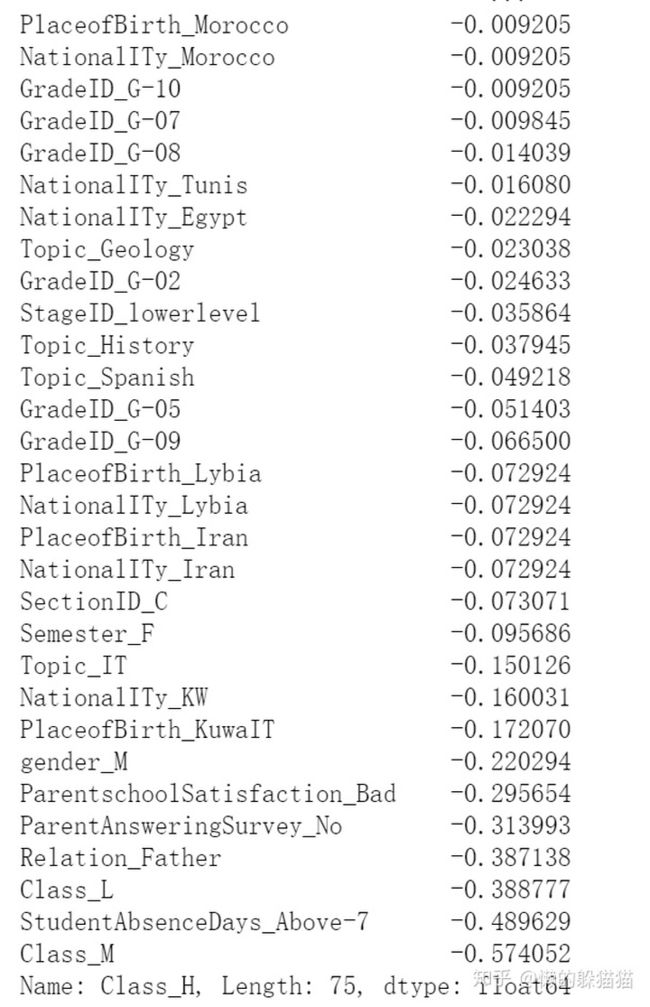
根据各个特征与优秀成绩(Class_H)的相关系数大小,我们可以看出除了变量GreadID,StageID,Semester,SectionID,PlaceofBirth等,大部分变量和优秀成绩之间有强烈的相关性,所以我们选择除去GreadID,StageID,Semester,SectionID,PlaceofBirth之外的变量,做为模型的特征输入。
x=sp.drop(['Class','StageID','GradeID','Semester','SectionID','PlaceofBirth'],axis=1)
y=sp['Class']
x=pd.get_dummies(x)#把所有的非数值型变量转化为数值型
x.head()
5.2选择测试数据集和训练数据集
from sklearn.cross_validation import train_test_split
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=10)5.3建立逻辑回归模型并检验准确性
#训练模型并检验准确率
lr=LogisticRegression()
lr.fit(x_train,y_train)
predict_y=lr.predict(x_test)
print('predict',predict_y)
score=accuracy_score(y_test,predict_y)
score
可以看出准确率为0.74左右