【NLP】GloVe的Python实现
作者 | Peng Yan
编译 | VK
来源 | Towards Data Science

作为NLP数据科学家,我经常阅读词向量、RNN和Transformer的论文。
阅读论文很有趣,给我一种错觉,我已经掌握了各种各样的技巧。但是,在复现它们时,困难就出现了。
据我所知,许多NLP学习者都遇到了和我一样的情况。因此,我决定开始一系列的文章,重点是实现经典的NLP方法。我还为此创建了一个GitHub存储库:https://github.com/pengyan510/nlp-paper-implementation
本帖是本系列的第一篇,它以GloVe原稿论文为基础,再现GloVe模型。如前所述,重点纯粹是实现。有关基础理论的更多信息,请参阅原始论文。
根据论文的研究,GloVe模型是用一台机器训练的。发布的代码是用C编写的,这对NLP学习者来说可能有些陌生。
因此,我对模型进行了一个全面的Python实现,它与仅使用一台机器训练大量词汇表的目标一致。以下各节逐步了解实现细节。完整的代码在这里。
第0步:准备
训练数据集
对于这个项目,我使用Text8数据集作为训练数据。为了得到它,我们可以使用gensim下载程序:
import gensim.downloader as api
dataset = api.load("text8")
数据集是一个列表列表,其中每个子列表都是表示句子的单词列表。我们只需要所有单词的列表,所以用itertools将其扁平化:
import itertools
corpus = list(itertools.chain.from_iterable(dataset))
好吧,现在我们有训练语料库了。
存储参数
在机器学习模型上工作时,通常需要配置的参数范围很广,如数据文件路径、批处理大小、字嵌入大小等,如果管理不好,这些参数会产生大量开销。
根据我的经验,我发现最好的方法是将所有的文件存储在一个名称为yaml的文件中配置yaml。在代码中,还添加加载函数以从yaml文件加载配置,如下所示:
def load_config():
config_filepath = "config.yaml's file path"
with config_filepath.open() as f:
config_dict = yaml.load(f, Loader=yaml.FullLoader)
config = argparse.Namespace()
for key, value in config_dict.items():
setattr(config, key, value)
return config
我们可以在配置文件配置batch大小, 学习率,而不是硬编码的值,这也使得代码变得更好。
这就是所有的准备工作。让我们继续进行GloVe模型的实现!
第1步:计算共现对(Cooccurring Pairs)
创建词汇
为了计算共现的token,我们首先需要确定词汇。以下是词汇的一些要求:
它是一组出现在语料库中的token。
每个token都映射到一个整数。
如果token不属于主体,则应将其表示为未知token,或“unk”。
对于计算共现,只需要一个子集token,例如最频繁的前k个token。
为了以结构化的方式满足这些需求,创建了词汇类。该类有四个字段:
token2index:将token映射到索引的dict。索引从0开始,每次添加以前未看到的token时,索引都会增加1。
index2token:将索引映射到token的dict。
token_counts:一个列表,其中第i个值是索引i的token计数。
_unk_token:用作未知token索引的整数。默认值为-1。
它还定义了以下方法:
add(token):在词汇表中添加新的token。如果以前未看到,则会生成新索引。token的计数也会更新。
get_uindex(token):返回token的索引。
get_utoken(index):返回与索引相对应的token。
get_topk_subset(k):创建一个新词汇表,其中是出现最频繁的前k个token。
shuffle():随机所有token,以便token和索引之间的映射是随机的。当我们实际计算共现对时,需要这个方法的原因将在后面被揭示。
我们现在可以查看代码:
@dataclass
class Vocabulary:
token2index: dict = field(default_factory=dict)
index2token: dict = field(default_factory=dict)
token_counts: list = field(default_factory=list)
_unk_token: int = field(init=False, default=-1)
def add(self, token):
if token not in self.token2index:
index = len(self)
self.token2index[token] = index
self.index2token[index] = token
self.token_counts.append(0)
self.token_counts[self.token2index[token]] += 1
def get_topk_subset(self, k):
tokens = sorted(
list(self.token2index.keys()),
key=lambda token: self.token_counts[self[token]],
reverse=True
)
return type(self)(
token2index={token: index for index, token in enumerate(tokens[:k])},
index2token={index: token for index, token in enumerate(tokens[:k])},
token_counts=[
self.token_counts[self.token2index[token]] for token in tokens[:k]
]
)
def shuffle(self):
new_index = [_ for _ in range(len(self))]
random.shuffle(new_index)
new_token_counts = [None] * len(self)
for token, index in zip(list(self.token2index.keys()), new_index):
new_token_counts[index] = self.token_counts[self[token]]
self.token2index[token] = index
self.index2token[index] = token
self.token_counts = new_token_counts
def get_index(self, token):
return self[token]
def get_token(self, index):
if not index in self.index2token:
raise Exception("Invalid index.")
return self.index2token[index]
@property
def unk_token(self):
return self._unk_token
def __getitem__(self, token):
if token not in self.token2index:
return self._unk_token
return self.token2index[token]
def __len__(self):
return len(self.token2index)
对于类实现,我使用Python的dataclass特性。
有了这个特性,我只需要用类型注释定义字段,__init__()方法就会自动为我生成。我还可以在定义字段时为它们设置默认值。
例如,通过设置default_factory=dict, token2index默认为空dict。有关dataclass的更多信息,请参阅官方文档:https://docs.python.org/3/library/dataclasses.html
现在我们有了词汇类,剩下的问题是:我们如何使用它?基本上有两个用例:
从语料库中创建一个词汇表,它由前k个最常见的token组成。
在计算共现对时,使用创建的词汇表将语料库(token列表)转换为整数索引。
我创建了另一个类Vectorizer来协调这两个用例。它只有一个字段vocab,它指的是从语料库中创建的词汇。它有两种方法:
from_corpus(corpus, vocab_size):这是一个类方法。首先,通过添加语料库中的所有token来创建词汇表。然后选择词汇量最大最频繁的token来创建新的词汇表。这个词汇表被随机并用于实例化Vectorizer。随机的原因将在后面解释。
vectorize(corpus):将给定的语料库(一个token列表)转换为一个索引列表。
完整代码如下:
@dataclass
class Vectorizer:
vocab: Vocabulary
@classmethod
def from_corpus(cls, corpus, vocab_size):
vocab = Vocabulary()
for token in corpus:
vocab.add(token)
vocab_subset = vocab.get_topk_subset(vocab_size)
vocab_subset.shuffle()
return cls(vocab_subset)
def vectorize(self, corpus):
return [self.vocab[token] for token in corpus]
扫描上下文窗口
现在我们有了将所有单词转换成索引的vectorizer,剩下的任务是扫描所有上下文窗口并计算所有可能的共现对。
由于共现矩阵是稀疏的,所以使用Counter模块来计算。键是(单词i的索引,单词j的索引),其中单词j出现在单词i的上下文中。值是表示个数。但是,如果使用此策略,可能会出现两个问题。
问题1:如果我们在一次扫描中计算所有共现对,我们很可能会耗尽内存,因为distinct (word i’s index, word j's index)的值可能是巨大的。
解决方案:我们可以在多个扫描中计算共现对。在每次扫描中,我们将单词i的索引限制在一个很小的范围内,这样就大大减少了不同对的数量。
假设词汇表有100000个不同的token。如果我们在一次扫描中对所有对进行计数,则不同对的数量可能高达10¹⁰。
相反,我们可以在10次扫描中计算所有对。在第一次扫描中,我们将单词i的索引限制在0到9999之间;在第二次扫描中,我们将其限制在10000到19999之间;在第三次扫描中,我们将其限制在20000到29999之间,依此类推。
每次扫描完成后,我们把计数保存到磁盘上。现在在每一次扫描中,不同对的数目可以达到10⁹,这是原始数目的十分之一。
这种方法背后的思想是,我们不是在一次扫描中计算整个共现矩阵,而是将矩阵分成10个较小的矩形,然后依次计算它们。下面的图片将这个想法形象化。
左:一次扫描计数右:多次扫描计数

这种方法是可伸缩的,因为随着词汇表大小的增加,我们总是可以增加扫描次数以减少内存使用。
主要缺点是如果使用一台机器,运行时间也会增加。然而,由于扫描之间没有依赖关系,它们可以很容易地与Spark并行。但这超出了我们的范围。
同时,在这一点上,词汇混乱的原因可以被发现。当我们用最频繁的token创建词汇表时,这些token的索引是有序的。
索引0对应最频繁的token,索引1对应第二频繁的token,依此类推。如果我们继续以100000个token为例,在第一次扫描中,我们将计算10000个最频繁的token对,不同的token对的数量将是巨大的。
而在剩下的扫描中,不同对的数量会少得多。这会导致扫描之间的内存使用不平衡。通过对词汇表进行随机,不同的词汇对在扫描中均匀分布,内存使用平衡。
问题2:从解决方案继续到问题1,如何将每次扫描的计数保存到磁盘?最明显的方法是在扫描之间将(单词i的索引,单词j的索引,count)三元组写入共享文本文件。但是在以后的训练中使用这个文件会带来太多的开销。
解决方案:有一个python库h5py,它为HDF5二进制格式提供Pythonic接口。它使你能够存储大量的数字数据,并且可以像处理真正的NumPy数组一样轻松地对它们进行操作。
有关该库的更多详细信息,请查看其文档:https://docs.h5py.org/en/stable/
和前面一样,我创建了一个CooccurrenceEntries类,它进行计数并将结果保存到磁盘。该类有两个字段:
vectorizer:从语料库创建的向量器实例。
vectorized_corpus:一个单词索引列表。这是使用vectorizer对原始语料库(单词列表)进行向量化的结果。
主要有两种方法:
setup(corpus,vectorizer):这是一个用于创建CooccurrenceEntries实例的类方法。通过调用vectorizer的vectorize方法生成向量化的语料库。
build(window_size, num_partitions, chunk_size, output_directory=“.” ):此方法统计num_partitions扫描中的共现对,并将结果写入输出目录。chunk_size参数用于使用HDF5格式将数据保存为块。分块保存的原因将在模型训练部分讨论。简而言之,它用于更快地生成训练批。
具体实施如下:
@dataclass
class CooccurrenceEntries:
vectorized_corpus: list
vectorizer: Vectorizer
@classmethod
def setup(cls, corpus, vectorizer):
return cls(
vectorized_corpus=vectorizer.vectorize(corpus),
vectorizer=vectorizer
)
def validate_index(self, index, lower, upper):
is_unk = index == self.vectorizer.vocab.unk_token
if lower < 0:
return not is_unk
return not is_unk and index >= lower and index <= upper
def build(
self,
window_size,
num_partitions,
chunk_size,
output_directory="."
):
partition_step = len(self.vectorizer.vocab) // num_partitions
split_points = [0]
while split_points[-1] + partition_step <= len(self.vectorizer.vocab):
split_points.append(split_points[-1] + partition_step)
split_points[-1] = len(self.vectorizer.vocab)
for partition_id in tqdm(range(len(split_points) - 1)):
index_lower = split_points[partition_id]
index_upper = split_points[partition_id + 1] - 1
cooccurr_counts = Counter()
for i in tqdm(range(len(self.vectorized_corpus))):
if not self.validate_index(
self.vectorized_corpus[i],
index_lower,
index_upper
):
continue
context_lower = max(i - window_size, 0)
context_upper = min(i + window_size + 1, len(self.vectorized_corpus))
for j in range(context_lower, context_upper):
if i == j or not self.validate_index(
self.vectorized_corpus[j],
-1,
-1
):
continue
cooccurr_counts[(self.vectorized_corpus[i], self.vectorized_corpus[j])] += 1 / abs(i - j)
cooccurr_dataset = np.zeros((len(cooccurr_counts), 3))
for index, ((i, j), cooccurr_count) in enumerate(cooccurr_counts.items()):
cooccurr_dataset[index] = (i, j, cooccurr_count)
if partition_id == 0:
file = h5py.File(
os.path.join(
output_directory,
"cooccurrence.hdf5"
),
"w"
)
dataset = file.create_dataset(
"cooccurrence",
(len(cooccurr_counts), 3),
maxshape=(None, 3),
chunks=(chunk_size, 3)
)
prev_len = 0
else:
prev_len = dataset.len()
dataset.resize(dataset.len() + len(cooccurr_counts), axis=0)
dataset[prev_len: dataset.len()] = cooccurr_dataset
file.close()
with open(os.path.join(output_directory, "vocab.pkl"), "wb") as file:
pickle.dump(self.vectorizer.vocab, file)
通过Vocabulary, Vectorizer, CooccurrenceEntri的抽象,计算共现对并保存到磁盘的代码很简单:
vectorizer = Vectorizer.from_corpus(
corpus=corpus,
vocab_size=config.vocab_size
)
cooccurrence = CooccurrenceEntries.setup(
corpus=corpus,
vectorizer=vectorizer
)
cooccurrence.build(
window_size=config.window_size,
num_partitions=config.num_partitions,
chunk_size=config.chunk_size,
output_directory=config.cooccurrence_dir
)
第2步:训练GloVe模型
从HDF5数据集加载批处理
我们首先需要从HDF5数据集中批量加载数据。由于可以像存储在NumPy矩阵中一样检索数据,因此最简单的方法是使用PyTorch数据加载器。
但是,加载每个batch需要以dataset[i]的形式调用许多次,其中dataset是h5py.Dataset实例。这涉及到许多IO调用,并且可能非常慢。
解决方法是加载h5py.Dataset一块一块地调入内存。每个加载的块在内存中都是一个纯粹的NumPy数组,因此我们可以使用PyTorch的Dataloader在其上迭代批处理。现在所需的IO调用数等于块的数量,块的数量要小得多。
这种方法的一个缺点是不可能完全随机,因为永远不会生成包含来自不同块的数据的批。为了获得更多的随机性,我们可以按随机顺序加载块,并将DataLoader的shuffle参数设置为True。
为加载批处理创建HDF5DataLoader类。它有五个字段:
filepath:HDF5文件的路径。
dataset_name:h5py.Dataset名称。
batch_size:训练批大小。
device:训练设备,可以是cpu或gpu。
dataset:h5py.Dataset文件中的实例。
它有两种方法:
open():此方法打开HDF5文件并定位数据集。不会发生读取。
iter_batches():此方法以随机顺序加载块,并创建PyTorch数据加载程序来迭代其中的批。
代码如下所示。需要注意的一点是,CooccurrenceDataset只是PyTorch数据集的一个子类,用于索引数据。
@dataclass
class HDF5DataLoader:
filepath: str
dataset_name: str
batch_size: int
device: str
dataset: h5py.Dataset = field(init=False)
def iter_batches(self):
chunks = list(self.dataset.iter_chunks())
random.shuffle(chunks)
for chunk in chunks:
chunked_dataset = self.dataset[chunk]
dataloader = torch.utils.data.DataLoader(
dataset=CooccurrenceDataset(
token_ids=torch.from_numpy(chunked_dataset[:,:2]).long(),
cooccurr_counts=torch.from_numpy(chunked_dataset[:,
2]).float()
),
batch_size=self.batch_size,
shuffle=True,
pin_memory=True
)
for batch in dataloader:
batch = [_.to(self.device) for _ in batch]
yield batch
@contextlib.contextmanager
def open(self):
with h5py.File(self.filepath, "r") as file:
self.dataset = file[self.dataset_name]
yield
编码GloVe模型
用PyTorch实现GloVe模型非常简单。我们定义了两个权矩阵和两个偏置向量。请注意,我们在创建嵌入时设置sparse=True,因为梯度更新本质上是稀疏的。在forward()中,返回平均batch损失。
class GloVe(nn.Module):
def __init__(self, vocab_size, embedding_size, x_max, alpha):
super().__init__()
self.weight = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=embedding_size,
sparse=True
)
self.weight_tilde = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=embedding_size,
sparse=True
)
self.bias = nn.Parameter(
torch.randn(
vocab_size,
dtype=torch.float,
)
)
self.bias_tilde = nn.Parameter(
torch.randn(
vocab_size,
dtype=torch.float,
)
)
self.weighting_func = lambda x: (x / x_max).float_power(alpha).clamp(0, 1)
def forward(self, i, j, x):
loss = torch.mul(self.weight(i), self.weight_tilde(j)).sum(dim=1)
loss = (loss + self.bias[i] + self.bias_tilde[j] - x.log()).square()
loss = torch.mul(self.weighting_func(x), loss).mean()
return loss
训练GloVe模型
模型训练遵循标准的PyTorch训练程序。唯一的区别是,我们使用定制的HDF5Loader来生成批处理,而不是PyTorch的DataLoader。以下是训练代码:
dataloader = HDF5DataLoader(
filepath=os.path.join(config.cooccurrence_dir, "cooccurrence.hdf5"),
dataset_name="cooccurrence",
batch_size=config.batch_size,
device=config.device
)
model = GloVe(
vocab_size=config.vocab_size,
embedding_size=config.embedding_size,
x_max=config.x_max,
alpha=config.alpha
)
model.to(config.device)
optimizer = torch.optim.Adagrad(
model.parameters(),
lr=config.learning_rate
)
with dataloader.open():
model.train()
losses = []
for epoch in tqdm(range(config.num_epochs)):
epoch_loss = 0
for batch in tqdm(dataloader.iter_batches()):
loss = model(
batch[0][:, 0],
batch[0][:, 1],
batch[1]
)
epoch_loss += loss.detach().item()
loss.backward()
optimizer.step()
optimizer.zero_grad()
losses.append(epoch_loss)
print(f"Epoch {epoch}: loss = {epoch_loss}")
torch.save(model.state_dict(), config.output_filepath)
实施完毕!
接下来,让我们训练模型,看看结果!
第3步:结果
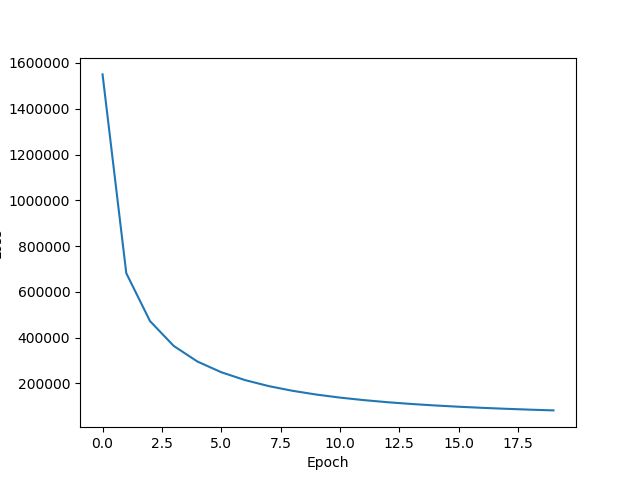
对于Text8数据集,训练一个epoch大约需要80分钟。我训练了20个epoch的模型,需要一天多的时间才能完成。学习曲线看起来很有希望,如果继续训练,损失似乎会进一步减少。
学习曲线图
我们也可以做一些单词相似性的任务来看看词向量的行为。
这里我使用了gensim中的KeyedVectors类,它允许你在不编写最近邻或余弦相似性代码的情况下执行此操作:https://github.com/pengyan510/nlp-paper-implementation/blob/master/glove/src/evaluate.py
相似性评估代码在这里。有关KeyedVectors的详细信息,请参阅文档:https://radimrehurek.com/gensim/models/keyedvectors.html#what-can-i-do-with-word-vectors
运行一些简单的相似性任务将显示以下结果:

正如我们所看到的,其中有些是有意义的,比如“computer”和“game”,“united”和“states”;有些则不是。在一个更大的数据集上进行更多epoch的训练应该会改善结果。
结尾
GloVe论文写得很好,容易看懂。然而,在实现过程中,有很多陷阱和困难,特别是当你考虑到内存问题时。
经过相当多的努力,我们最终得到了一个令人满意的解决方案,可以在一台机器上进行训练。
正如我在开始时所说,我将继续实现更多的NLP论文,并与大家分享
感谢阅读!
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑温州大学《机器学习课程》视频
本站qq群851320808,加入微信群请扫码: