从大一统视角理解扩散模型(Diffusion Models)
每天给你送来NLP技术干货!
作者 | 中森
单位 | NLP算法工程师
方向 | 自然语言处理
来自 | PaperWeekly
资料来源
这篇文章是近期笔者阅读扩散模型的一些技术博客和概览的一篇梳理,主要参考的内容来自 Calvin Luo 的论文,针对的对象主要是对扩散模型已经有一些基础了解的读者。
Calvin Luo 的这篇论文为理解扩散模型提供了一个统一的视角,尤其是其中的数理公式推导非常详尽,本文将试图尽量简要地概括一遍大一统视角下的扩散模型的推导过程。在结尾处,笔者附上了一些推导过程中的强假设的思考和疑惑,并简要讨论了下扩散模型应用在自然语言处理时的一些思考。
本篇阅读笔记一共参考了以下技术博客。其中如果不了解扩散模型的读者可以考虑先阅读 lilian-weng 的科普博客。Calvin-Luo 的这篇介绍性论文在书写的时候经过了包括 Jonathan Ho(DDPM 作者), Song Yang 博士和一系列相关扩散模型论文的发表者的审核,非常值得一读。
1. What are Diffusion Models? by Lilian Weng:
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
2. Generative Modeling by Estimating Gradients of the Data Distribution by Song Yang:
https://yang-song.net/blog/2021/score/
3. Understanding Diffusion Models: A Unified Perspective by Calvin Luo:
https://arxiv.org/abs/2208.11970
生成模型希望可以生成符合真实分布(或给定数据集)的数据。我们常见的几种生成模型有 GANs,Flow-based Models,VAEs,Energy-Based Models 以及我们今天希望讨论的扩散模型 Diffusion Models。其中扩散模型和变分自编码器 VAEs,和基于能量的模型 EBMs 有一些联系和区别,笔者会在接下来的章节阐述。

▲ 常见的几种生成模型

ELBO & VAE
在介绍扩散模型前,我们先来回顾一下变分自编码器 VAE。我们知道 VAE 最大的特点是引入了一个潜在向量的分布来辅助建模真实的数据分布。
那么为什么我们要引入潜在向量?有两个直观的原因,一个是直接建模高维表征十分困难,常常需要引入很强的先验假设并且有维度诅咒的问题存在。另外一个是直接学习低维的潜在向量,一方面起到了维度压缩的作用,一方面也希望能够在低维空间上探索具有语义化的结构信息(例如图像领域里的 GAN 往往可以通过操控具体的某个维度影响输出图像的某个具体特征)。
引入了潜在向量后,我们可以将我们的目标分布的对数似然 logP(x),也称为“证据evidence”写成下列形式:

▲ ELBO的推理过程
其中,我们重点关注式 15。等式的左边是生成模型想要接近的真实数据分布(evidence),等式右边由两项组成,其中第二项的 KL 散度因为恒大于零,所以不等式恒成立。如果在等式右边减去该 KL 散度,则我们得到了真实数据分布的下界,即证据下界 ELBO。对 ELBO 进行进一步的展开,我们就可以得到 VAE 的优化目标。

▲ ELBO等式的展开
对该证据下界的变形的形式,我们可以直观地这么理解:证据下界等价于这么一个过程,我们用编码器将输入 x 编码为一个后验的潜在向量分布 q(z|x)。我们希望这个向量分布尽可能地和真实的潜在向量分布 p(z) 相似,所以用 KL 散度约束,这也可以避免学习到的后验分布 q(z|x) 坍塌成一个狄拉克 delta 函数(式 19 的右侧)。而得到的潜在向量我们用一个解码器重构出原数据,对应的是式 19 的左边 P(x|z)。
VAE 为什么叫变分自编码器。变分的部分来自于寻找最优的潜在向量分布 q(z|x) 的这个过程。自编码器的部分是上面提到的对输入数据的编码,再解码为原数据的行为。
那么提炼一下为什么 VAE 可以比较好地贴合原数据的分布?因为根据上述的公式推导我们发现:原数据分布的对数似然(称为证据 evidence)可以写成证据下界加上我们希望近似的后验潜在向量分布和真实的潜在向量分布间的 KL 散度(即式 15)。如果把该式写为 A=B+C 的形式。
因为 evidence(即 A)是个常数(与我们要学习的参数无关),所以最大化 B,也就是我们的证据下界,等价于最小化 C,也即是我们希望拟合的分布和真实分布间的差别。而因为证据下界,我们可以重新写成式 19 那样一个自编码器的形式,我们也就得到了自编码器的训练目标。优化该目标,等价于近似真实数据分布,也等价于用变分手法来优化后验潜在向量分布 q(z|x) 的过程。
但 VAE 自身依然有很多问题。一个最明显的就是我们如何选定后验分布 。绝大多数的 VAE 实现里,这个后验分布被选定为了一个多维高斯分布。但这个选择更多的是为了计算和优化的方便而选择。这样的简单形式极大地限制了模型逼近真实后验分布的能力。VAE 的原作者 kingma 曾经有篇非常经典的工作就是通过引入 normalization flow [1] 在改进后验分布的表达能力。而扩散模型同样可以看做是对后验分布 的改进。

Hierarchical VAE
下图展示了一个变分自编码器里,潜在向量和输入间的闭环关系。即从输入中提取低维的潜在向量后,我们可以通过这个潜在向量重构出输入。
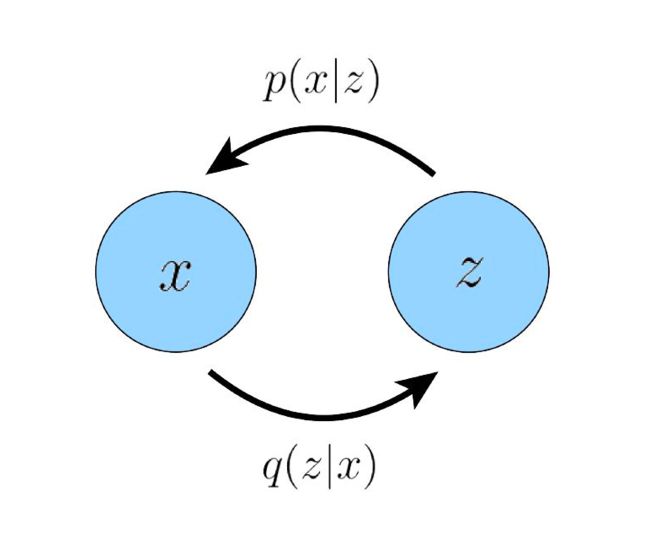
▲ VAE里潜在向量与输入的关系
很明显,我们认为这个低维的潜在向量里一定是高效地编码了原数据分布的一些重要特性,才使得我们的解码器可以成功重构出原数据分布里的各式数据。那么如果我们递归式地对这个潜在向量再次计算“潜在向量的潜在向量”,我们就得到了一个多层的 HVAE,其中每一层的潜在向量条件于所有前序的潜在向量。
但是在这篇文章里,我们主要关注具有马尔可夫性质的层级变分自编码器 MHVAE,即每一层的潜在向量仅条件于前一层的潜在向量。

▲ MHVAE里的潜在向量只条件于上一层
对于该 MHVAE,我们可以通过马尔可夫假设得到以下二式:
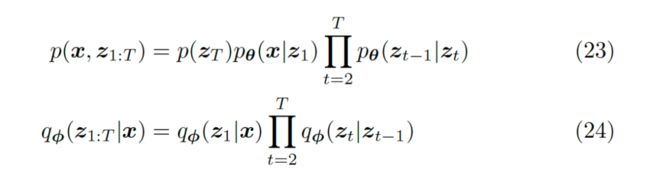
▲ 23和24式是用链式法则对依赖图里的关系的拆解
对于该 MHVAE,我们可以用以下步骤推导其证据下界:

▲ MHVAE的变分下界推导

Variation Diffusion Model
我们之所以在谈论扩散模型之前,要花如此大的篇幅介绍 VAE,并引出 MHVAE 的证据下界推导是因为我们可以非常自然地将扩散模型视为一种特殊的 MHVAE,该 MHVAE 满足以下三点限制(注意以下三点限制也是整个扩散模型推断的基础):
潜在向量 Z 的维度和输入 X 的维度保持一致。
每一个时间步的潜在向量都被编码为一个仅依赖于上一个时间步的潜在向量的高斯分布。
每一个时间步的潜在向量的高斯分布的参数,随时间步变化,且满足最终时间步的高斯分布满足标准高斯分布的限制。
因为第一点维度一致的原因,在不影响理解的基础上,我们将 MHVAE 里的 Zt 表示为 Xt(其中 x0 为原始输入),则我们可以将 MHVAE 的层级潜在向量依赖图,重新画为以下形式(即将扩散模型的中间扩散过程当做潜在向量的层级建模过程):

▲ 扩散过程的直观解释:在数据x0上不断加高斯噪声直至退化为纯噪声图像Xt
直至这里,我们终于见到了我们熟悉的扩散模型的形式。
而在将上面的公式 25-28 里的 Zt 与 Xt 替换后,我们可以得到 VDM 里证据下界的推导公式里的前四行,即公式 34-37。并且在此基础上,我们可以继续往下推导。
37 至 38 行的变换是链式法则的等价替换(或上述公式 23 和 24 的变换),38 至 39 行是连乘过程的重组,39 至 40 行是对齐连乘符号的区间,40 至 41 行应用了 Log 乘法的性质,41 至 42继续运用该性质进一步拆分,42 至 43 行是因为和的期望等于期望的和,43 至 44 是因为期望目标与部分时间步的概率无关可以直接省去,44 至 45 步是应用了KL 散度的定义进行了重组。

▲ VDM的证据下界推导
至此,我们又一次将原数据分布的对数似然,转化为了证据下界(公式 37),并将其转化为了几项非常直观的损失函数的加和形式(公式 45),他们分别为:
重构项,即从潜在向量 到原数据 的变化。在 VAE 里该重构项写为 ,而在这里我们写做 。
先验匹配项。回忆我们上述提到的 MHVAE 里最终时间步的高斯分布应建立为标准高斯分布。
一致项。该项损失是为了使得前向加噪过程和后向去噪的过程中,Xt 的分布保持一致。直观上讲,对一个更混乱图像的去噪应一致于对一个更清晰的图像的加噪。而因为一致项的损失是定义于所有时间步上的,这也是三项损失里最耗时计算的一项。
虽然以上的公式推导给了我们一个非常直观的证据下界,并且由于每一项都是以期望来计算,所以天然适用蒙特卡洛方法来近似,但如果优化该证据下界依然存在几个问题:
我们的一致项损失是一项建立在两个随机变量 上的期望。他们的蒙特卡洛估计的方差大概率比建立在单个独立变量上的蒙特卡洛估计的方差大。
我们的一致项是定义于所有时间步上的 KL 散度的期望和。对于 T 取值较高的情况(通常扩散模型 T 取 2000 左右),该期望的方差也会很大。
所以我们需要重新推导一个证据下界。而这个推导的关键将着眼于以下这个观察:我们可以将扩散过程的正向加噪过程 重写为 。之所以这样重写的原因是基于马尔可夫假设,这两个式子完全等价。于是对这个式子使用贝叶斯法则,我们可以得到式 46。
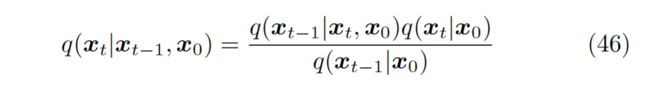
▲ 对前向加噪过程使用马尔可夫假设和贝叶斯法则后的公式
基于公式 46,我们可以重写上面的证据下界(式 37)为以下形式:其中式 47,48 和式 37,38 一致。式 49 开始,分母的连乘拆解由从 T 开始改为从 1 开始。式 50 基于上文提及的马尔可夫假设对分母添加了 的依赖。式 51 用 log 的性质拆分了对数的目标。
式 52 代入了式 46 做了替换。式 53 将划掉的分母部分连乘单独提取出来后发现各项可约剩下式 54 部分的 。式 54 用 log 的性质消去了 得到了式 55。式 56 用 log 的性质拆分重组了公式,式 57 如同前述式 43-44 的变换,省去了无关的时间步。式 58 则用了 KL 散度的性质。

▲ 应用了马尔可夫假设的扩散模型证据下界推导1

▲ 应用了马尔可夫假设的扩散模型证据下界推导2
至此,我们应用了马尔可夫假设得到了一个更优的证据下界推导。该证据下界同样包含几项直观的损失函数:
重构项。该重构项与上面提及的重构项一致。
先验匹配项。与上面提及的形式略有差别,但同样是基于最终时间步应为标准高斯的先验假设。
去噪匹配项。与上面提及的一致项的最大区别在于不再是对两个随机变量的期望。并且直观上理解 代表的是后向的去噪过程,而 代表的是已知原始图像和目标噪声图像的前向加噪过程。该加噪过程作为目标信号,来监督后向的去噪过程。该项解决了期望建立于两个随机变量上的问题。
注意,以上的推导完全基于马尔可夫的性质所以适用于所有 MHVAE,所以当 T=1 的时候,以上的证据下界和 VAE 所推导出的证据下界完全一致!并且本文之所以称为大一统视角,是因为对于该证据下界里的去噪匹配项,不同的论文有不同的优化方式。但归根结底,他们的本质互相等价,且皆由该式展开推导得到。
下面我们会从扩散模型的角度做公式推导,来展开计算去噪匹配项。(注意第一版的推导里的一致项,也完全可以通过下一节的方式得到 q 和 p 的表达式,再通过 KL 来计算解析式)

Diffusion Model recap
在扩散模型里,有几个重要的假设。其中一个就是每一步扩散过程的变换,都
是对前一步结果的高斯变换(上一节 MHVAE 的限制条件 2):

▲ 与 MHVAE 不同,编码器侧的潜在向量分布并不经过学习得到,而是固定为线性高斯模型
这一点和 VAE 有很大不同。VAE 里编码器侧的潜在向量的分布是通过模型训练得到的。而扩散模型里,前向加噪过程里的每一步都是基于上一步结果的高斯变换。其中 一般当作超参设置得到。这点对于我们计算扩散模型的证据下界有很大帮助。因为我们可以基于输入 确切地知道前向过程里的某一步的具体状态,从而监督我们的预测。
基于式 31,我们可以递归式地对 不断加噪变换,得到最终 的表达式:

▲ 可以写为关于 的一个高斯分布的采样结果
所以对于式 58 里噪音匹配项里的监督信号,我们可以重写成以下形式,其中根据式 70,我们可以得到 和 的表达式,而 因为是前向扩散过程,可以应用马尔可夫性质看做 使用式 31 得到具体表达式。
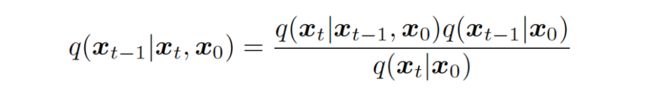
▲ 式58里的监督信号可以通过 计算具体的值
代入每一项 q 所代表的高斯函数表达式后,我们最后可以得到一个新的高斯分布表达式,其中每一项都是具体可求的:
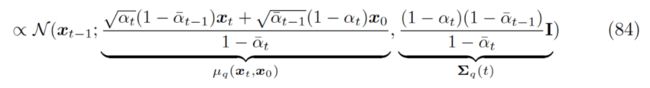
▲ 的解析形式
参考已经证明了前向加噪过程可以写为一个高斯分布了。在扩散模型的初始论文 [2] 里提到,对于一个连续的高斯扩散过程,其逆过程与前向过程的方程形式(functional form)一致。所以我们将对去噪匹配项里的 也采用高斯分布的形式(更加具体的一些推导放在了末尾的补充里)。注意式 58 里,对两个高斯分布求 KL 散度,其解析解的形式如下:
![]()
▲ 两个高斯分布的KL散度解析解
我们现在已知其中一个高斯分布(左侧)的参数,现在如果我们令右侧的高斯分布和左侧高斯分布的方差保持一致。那么优化该 KL 散度的解析式将简化为以下形式:
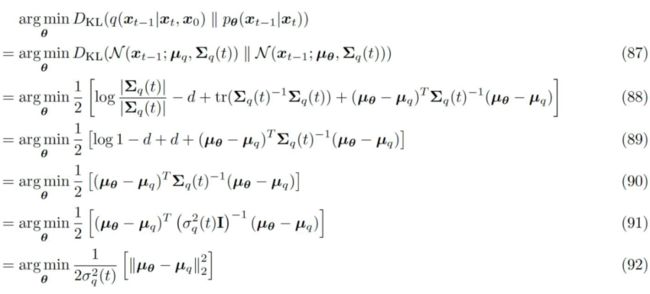
▲ 式58的噪音匹配项简化为最小化前后向均值的预测误差
如此一来式 58 的噪音匹配项就被简化为最小化前后向均值的预测误差(式 92)。读者请注意,以下的大一统的三个角度来看待 Diffusion model,实质上都是对式 92 里 的不同变形所推论出来的。其中 是关于 的函数,而 是关于 和t的函数。其中通过式 84,我们有 的准确计算结果,而因为 是关于 的函数。
我们可以将其写为类似式 84 的形式(注意,有关为什么可以忽略方差并且让均值选取这个形式放在了最末尾的补充讨论里。但关于这个形式的选择的深层原因实质上开辟了一个全新的领域来研究,并且关于该领域的研究直接导向了扩散模型之后的一系列加速采样技术的出现)。

▲ 将后向预测的均值写为类似前向加噪的形式
比较式 84 与 94 可知, 是我们通过噪音数据 来预测原始数据 的神经网络。那么我们可以将式 58 里证据下界的噪音匹配项,最终写为

▲ 噪声匹配项的最终形式
那么,我们最后得到扩散模型的优化,最终表现为训练一个神经网络,以任意时间步的噪音图像为输入,来预测最初的原始图像!此时优化目标转化为了最小化预测误差。同时式 58 上的对所有时间步的噪音匹配项求和的优化,可以近似为对每一时间步上的预测误差的期望的最小值,而该优化目标可以通过随机采样近似:

▲ 该优化目标可以通过随机采样实现

Three Equivalent Perspective
为什么 Calvin Luo 的这篇论文叫做大一统视角来看待扩散模型?以上我们花了不菲的篇幅论证了扩散模型的优化目标可以最终转化为训练一个神经网络在任意时间步从 预测原始输入 。以下我们将论述如何通过对 不同的推导得到类似的角度看待扩散模型。
首先,我们已经知道给定每个时间步的噪声系数 之后,我们可以由初始输入 递归得到 。同理,给定 我们也可以求得 。那么对式 69 重置后,我们可以得到式 115。

▲ 将式69里的 和 关系重置后可得式115
重新将式 115 代入式 84 里,我们所得的关于时间步 t 的真实均值表达式 后,我们可以得到以下推导:

▲ 在推导真实均值时替换
注意在上一次推导的过程中, 里的 在计算 kl 散度的解析式时被抵消掉了,而 我们采取的是用神经网络直接拟合的策略。而在这一次的推导过程中, 被替换成了关于 的表达式(关于 和 )后,我们可以得到 的新的表达式,依旧关于 ,只是不再与 相关,而是与 相关(式 124)。
其中,和式 94 一样,我们忽略方差(将其设为与前向一致)并将希望拟合的 写成与真实均值 一样的形式,只是将 替换为神经网络的拟合项后我们可以得到式 125。

▲ 与上次推导时替换 为神经网络所拟合项一样,这次换为拟合初始噪声项
将我们新得到的两个均值表达式重新代入 KL 散度的表达式里, 再次被抵消掉(因为 和 选取的形式一致)最终只剩下 和 的差值。注意式 130 和式 99 的相似性!
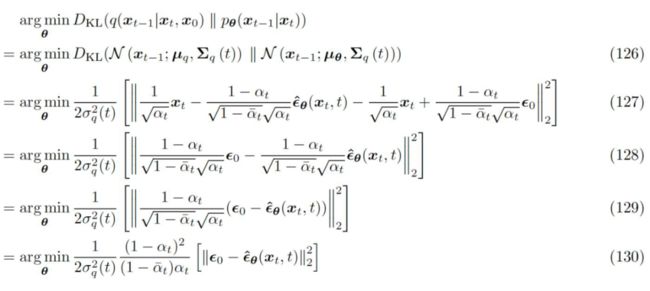
▲ 最终对证据下界里的去噪匹配项的优化可以写成关于初始噪声和其拟合项的差的最小化
至此,我们得到了对扩散模型的第二种直观理解。对于一个变分扩散模型 VDM,我们优化该模型的证据下界既等价于优化其在所有时间步上对初始图像的预测误差的期望,也等价于优化在所有时间步上对噪声的预测误差的期望!事实上 DDPM 采取的做法就是式 130 的做法(注意 DDPM 里的表达式实际上用的是 ,关于这点在文末也会讨论)。
下面笔者将概括第三种看待 VDM 的推导方式。这种方式主要来自于 SongYang 博士的系列论文,非常直观。并且该系列论文将扩散模型这种离散的多步去噪过程统一成了一个连续的随机微分方程(SDE)的特殊形式。SongYang 博士因此获得了 ICLR 2021 的最佳论文奖!
后续来自清华大学的基于将该 SDE 转化为常微分方程 ODE 后的采样提速论文,也获得了 ICLR 2022 的最佳论文奖!关于该论文的一些细节和直观理解,Song Yang 博士在他自己的博客里给出了非常精彩和直观的讲解。有兴趣的读者可以点开本文初始的第二个链接查看。以下只对大一统视角下的第三种视角做简短的概括。
第三种推导方式主要基于 Tweedie's formula。该公式主要阐述了对于一个指数家族的分布的真实均值,在给定了采样样本后,可以通过采样样本的最大似然概率(即经验均值)加上一个关于分数(score)预估的校正项来预估。注意 score 在这里的定义是真实数据分布的对数似然关于输入 的梯度。即

▲ score的定义
根据 Tweedie's formula,对于一个高斯变量 z~N(mu_z, sigma_z) 来说,该高斯变量的真实均值的预估是:
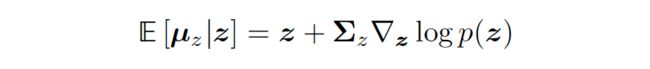
▲ Tweedie’s formula对高斯变量的应用
我们知道在训练时,模型的输入 关于 的表达式如下

▲ 上文里的式70
我们也知道根据 Tweedie's formula 的高斯变量的真实均值预估我们可以得到下式

▲ 将式70的方差代入Tweedie’s formula
那么联立两式的关于均值的表达式后,我们可以得到 关于 score 的表达式 133
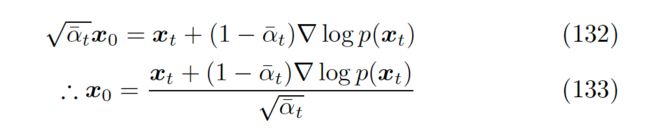
▲ 将 写为关于score的表达式
如上一种推导方式所做的一样,再一次重新将 的表达式代入式 84 对真实均值 的表达式里:(注意式 135 到 136 的变形主要在分子里最右边的 到 ,约去了根号下 )

▲ 将 的关于score表达式代入式84
同样,将 采取和 一样的形式,并用神经网络 来近似 score 后,我们得到了新的 的表达式 143。
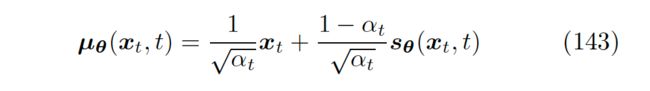
▲ 关于score的 的表达式
再再再同样,和上种推导里的做法一样,我们再将新的 代入证据下界里 KL 散度的损失项我们可以得到一个最终的优化目标
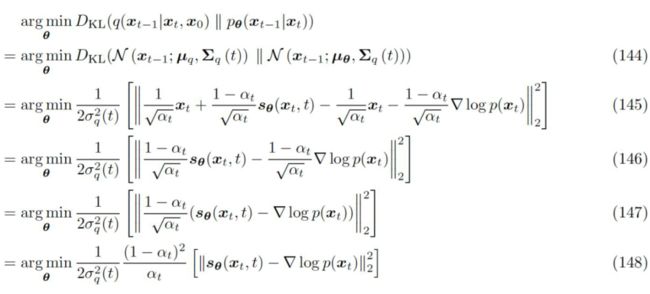
▲ 将新的 的表达式代入证据下界的优化目标里
事实上,比较式 148 和式 130 的形式,可以说是非常的接近了。那么我们的 score function delta_p(xt) 和初始噪声 是否有关联呢?联立关于 的两个表达式 133 和 115 我们可以得到。

▲ score function和初始噪声间的关系
读者如果将式 151 代入 148 会发现和式 130 等价!直观上来讲,score function 描述的是如何在数据空间里最大化似然概率的更新向量。而又因为初始噪声是在原输入的基础上加入的,那么往噪声的反方向(也是最佳方向)更新实质上等价于去噪的过程。而数学上讲,对 score function 的建模也等价于对初始噪声乘上负系数的建模!
至此我们终于将扩散模型的三个形式的所有推导整理完毕!即对变分扩散模型 VDM 的训练等价于训练一个神经网络来预测原输入 ,也等价于预测噪声 ,也等价于预测初始输入在特定时间步的 score delta_logp(xt)。
读到这里,相比读者也已经发现,不同的推导所得出的不同结果,都来自于对证据下界里去噪匹配项的不同推导过程。而不同的变形,基本上都是利用了 MHVAE 里最开始提到的三点基本假设所得。

Drawbacks to Consider
尽管扩散模型在最近两年成功出圈,引爆了业界,学术界甚至普通人对文本生成图像的 AI 模型的关注,但扩散模型这个体系本身依旧存在着一些缺陷:
扩散模型本身尽管理论框架已经比较完善,公式推导也十分优美。但仍然非常不直观。最起码从一个完全噪声的输入不断优化的这个过程和人类的思维过程相去甚远。
扩散模型和 GAN 或者 VAE 相比,所学的潜在向量不具备任何语义和结构的可解释性。上文提到了扩散模型可以看做是特殊的 MHVAE,但里面每一层的潜在向量间都是线性高斯的形式,变化有限。
而扩散模型的潜在向量要求维度与输入一致这一点,则更加死地限制住了潜在向量的表征能力。
扩散模型的多步迭代导致了扩散模型的生成往往耗时良久。
不过学术界对以上的一些难题其实也提出了不少解决方案。比如扩散模型的可解释性问题。笔者最近就发现了一些工作将 score-matching 直接应用在了普通 VAE 的潜在向量的采样上。这是一个非常自然的创新点,就和数年前的 flow-based-vae 一样。而耗时良久的问题,今年 ICLR 的最佳论文也将采样这个问题加速和压缩到了几十步内就可以生成非常高质量的结果。
但是对于扩散模型在文本生成领域的应用最近似乎还不多,除了 prefix-tuning 的作者 xiang-lisa-li 的一篇论文 [3]
之外笔者暂未关注到任何工作。而具体来讲,如果将扩散模型直接用在文本生成上,仍有诸多不便。比如输入的尺寸在整个扩散过程必须保持一致就决定了使用者必须事先决定好想生成的文本的长度。而且做有引导的条件生成还好,要用扩散模型训练出一个开放域的文本生成模型恐怕难度不低。
本篇笔记着重的是在探讨大一统角度下的扩散模型推断。但具体对 score matching 如何训练,如何引导扩散模型生成我们想要的条件分布还没有写出来。笔者打算在下一篇探讨最近一些将扩散模型应用在受控文本生成领域的方法调研里详细记录和比较一下

补充
关于为什么扩散核是高斯变换的扩散过程的逆过程也是高斯变换的问题,来自清华大神的一篇知乎回答里 [4] 给出了比较直观的解释。其中第二行是将 和 近似。第三行是对 使用一阶泰勒展开消去了 。第四行是直接代入了 的表达式。于是我们得到了一个高斯分布的表达式。

▲ 扩散的逆过程也是高斯分布
在式 94 和式 125,我们都将对真实高斯分布 q 的均值 的近似 建模成了与我们所推导出的 一致的形式,并且将方差设置为了与 q 的方差一致的形式。
直观上来讲,这样建模的好处很多,一方面是根据 KL 散度对两个高斯分布的解析式来说,这样我们可以约掉和抵消掉绝大部分的项,简化了建模。另一方面真实分布和近似分布都依赖于 。在训练时我们的输入就是 xt,采取和真实分布形式一样的表达式没有泄漏任何信息。并且在工程上 DDPM 也验证了类似的简化是事实上可行的。但实际上可以这样做的原因背后是从 2021 年以来的一系列论文里复杂的数理证明所在解释的目标。同样引用清华大佬 [4] 的回答:

▲ DDPM里简化去噪的高斯分布的做法其实蕴含着深刻的道理
在 DDPM 里,其最终的优化目标是 而不是 。即预测的误差到底是初始误差还是某个时间步上的初始误差。谁对谁错?实际上这个误解来源于我们对 关于 的表达式的求解中的误解。
从式 63 开始的连续几步推导,都应用到了一个高斯性质,即两个独立高斯分布的和的均值与方差等于原分布的均值和与方差和。而实质上我们在应用重参数化技巧求 的过程中,是递归式的不断引入了新的 来替换递归中的 里的 。那么到最后,我们所得到的 无非是一个囊括了所有扩散过程中的 。这个噪声即可以说是 t,也可以说是 0,甚至最准确来说应该不等于任何一个时间步,就叫做噪声就好!
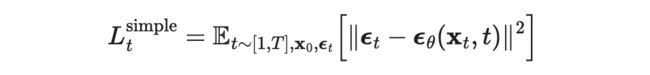
▲ DDPM的优化目标
关于对证据下界的不同简化形式。其中我们提到第二种对噪声的近似是 DDPM 所采用的建模方式。但是对初始输入的近似其实也有论文采用。也就是上文提及的将扩散模型应用在可控文本生成的论文里 [3] 所采用的形式。该论文每轮直接预测初始 Word-embedding。而第三种 score-matching 的角度可以参照 SongYang 博士的系列论文 [5] 来看。里面的优化函数的形式用的是第三种。
本篇笔记着重于讲述扩散模型的变分下界的公式推导,关于扩散模型与能量模型,朗之万动力学,随机微分方程等一系列名词的关系本篇笔记并无涉及。笔者将在另外一篇笔记里梳理相关的理解。

参考文献
[1] Improving Variational Inference with Inverse Autoregressive Flow https://arxiv.org/abs/1606.04934
[2] Deep Unsupervised Learning using Nonequilibrium Thermodynamics https://arxiv.org/abs/1503.03585
[3] abDiffusion-LM Improves Controllable Text Generation https://arxiv.org/abs/2205.14217
[4] abdiffusion model最近在图像生成领域大红大紫,如何看待它的风头开始超过GAN?- 我想唱high C的回答 - 知乎 https://www.zhihu.com/question/536012286/answer/2533146567
[5] SCORE-BASED GENERATIVE MODELING THROUGH STOCHASTIC DIFFERENTIAL EQUATIONS https://arxiv.org/abs/2011.13456
论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
武汉大学提出:用于基于统一Aspect的情感分析的关系感知协作学习
COLING'22 | SelfMix:针对带噪数据集的半监督学习方法
中山大学&阿里巴巴提出:用于基于Aspect的情感分析的关系图注意网络(GAT)
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注~