1小时快速上手遥感语义分割
语义分割是在像素级别上的分类,属于同一类的像素都要被归为一类,因此语义分割是从像素级别来理解图像的。遥感影像的分类、信息提取也适合用语义分割方法。
本文以遥感影像的大棚提取为例,介绍遥感影像中使用语义分割的全流程,包括环境搭建、数据集制作、模型训练、模型预测等步骤。本文使用的框架是百度的PaddleSeg。

1 环境搭建
首先需要一台带GPU的电脑,安装好cuda和cudnn,才能方便开展后面的工作。包括安装conda、PaddleSeg、gdal等内容。
PaddleSeg是基于飞桨PaddlePaddle开发的端到端图像分割开发套件,涵盖了高精度和轻量级等不同方向的大量高质量分割模型。通过模块化的设计,提供了配置化驱动和API调用两种应用方式,帮助开发者更便捷地完成从训练到部署的全流程图像分割应用。
-
安装conda,可以是miniconda或者anaconda,安装完成后创建一个虚拟环境,并在这个虚拟环境下安装其他的包。我推荐使用miniconda,更加轻量。地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/
-
安装PaddleSeg,github地址:https://github.com/PaddlePaddle/PaddleSeg。安装教程可以参考https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.4/docs/install_cn.md
-
安装gdal:便于读写遥感影像,在Linux下可以使用下面的命令安装:conda install -c conda-forge gdal。Windows下可以在下面的网站上找到自己需要的库,使用pip命令进行安装:https://www.lfd.uci.edu/~gohlke/pythonlibs/
2 数据集制作
既然要使用深度学习,那就离不开训练数据了。我们需要制作一下数据集。网上有很多公开的已经制作好的数据集,但是在实际工作中,根据特定的业务需求,我们还是需要自己制作数据集。数据集的可以在Windows下制作。
2.1 影像获取和样本勾绘
我们首先使用QGIS下载潍坊市的几块高分辨率样影像,然后在ArcGIS中创建矢量,并勾绘矢量样本。我勾绘的矢量如下。
下面的图中,绿色的边界为大棚。
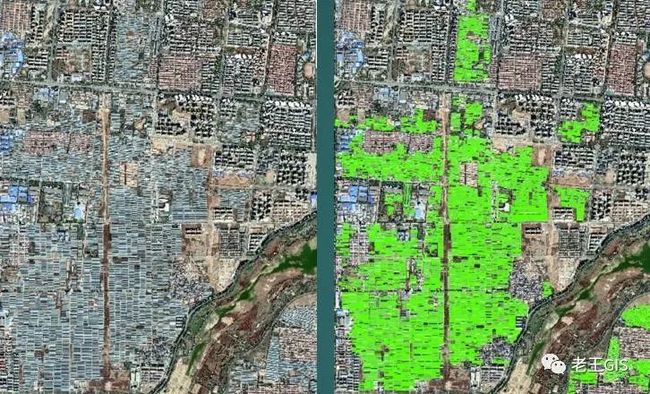
样本区1

放大图
需要注意的是,标注矢量的坐标系和投影需要与影像一致,并且添加一个类别字段,表明该要素的类别,例如背景是0,我们可以不勾绘,大棚是1。
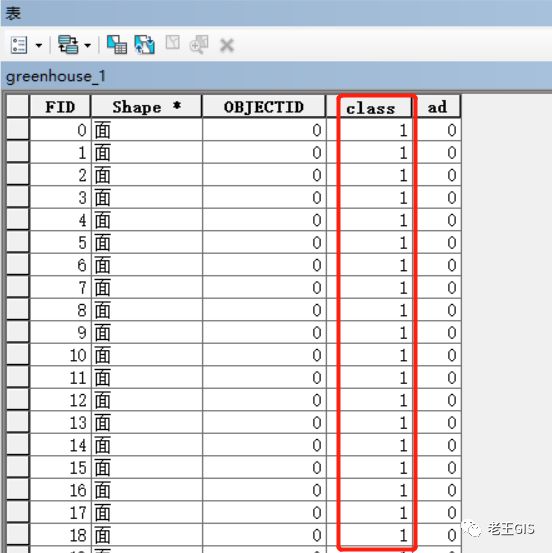
另外,标注矢量的边界不要超出影像的边界,这样才能方便后面制作数据集。
2.2 切片
现在我们有了影像和相应的标注矢量。
有了影像和矢量,但是深度学习框架不能直接使用这些。需要制作成特定大小的小图,例如512*512,1024*1024,当然标注也要制作成相同大小的小图。
因此需要写代码来实现切片和数据集的制作,步骤包括:
-
检查输入参数和矢量:检查输入文件是否存在、矢量是否合规。
-
矢量转栅格:根据模板影像(输入影像)将矢量栅格化, 栅格化后的分辨率、行列数、投影与模板影像相同。
-
切分影像:将影像按照指定的行列数、波段数、相邻切片的重叠像元数切分成相等宽、高的小影像。
-
切分标注栅格:将转换得到的标注栅格按照指定的行列数、波段数、相邻切片的重叠像元数切分成相等宽、高的小影像。
-
删除影像切片中nodata占比大于指定阈值的切片。
-
保留相同位置的切片
-
删除临时文件
将这些步骤整合成一个代码,可以更方便的运行,指明影像路径、矢量路径、输出路径、矢量的类别字段、输出图像行列数大小,重叠度,nodata占比的阈值。示例如下:
python .\seg_ds.py --img .\影像\wf1.tif --shp .\标注矢量\greenhouse_1.shp --output .\split --field class --size 1024 --lap 128 --th 0.1
切分后的影像如下:

2.3 生成训练集和验证集
因为PaddleSeg是通过读取这些文本文件来定位图像路径的, train.txt,val.txt和test.txt文本以空格为分割符分为两列,第一列为图像文件相对于dataset的相对路径,第二列为标注图像文件相对于dataset的相对路径。如下所示:
images/wf3_C02R11.tif labels/wf3_lab_C02R11.tif
images/wf3_C13R04.tif labels/wf3_lab_C13R04.tif
images/wf1_C08R05.tif labels/wf1_lab_C08R05.tif
images/wf3_C10R07.tif labels/wf3_lab_C10R07.tif
images/wf3_C00R02.tif labels/wf3_lab_C00R02.tif
images/wf3_C10R01.tif labels/wf3_lab_C10R01.tif
images/wf3_C12R08.tif labels/wf3_lab_C12R08.tif
images/wf1_C00R10.tif labels/wf1_lab_C00R10.tif
3 模型训练
准备好数据集后,接下来就可以使用PaddleSeg来训练了。模型训练可以参考官方的教程:https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.4/docs/whole_process_cn.md
3.1 配置文件
PaddleSeg在配置文件中详细列出了每一个可以优化的选项,用户只要修改这个配置文件就可以对模型进行定制(所有的配置文件在PaddleSeg/configs文件夹下面),如自定义模型使用的骨干网络、模型使用的损失函数以及关于网络结构等配置。除了定制模型之外,配置文件中还可以配置数据处理的策略,如改变尺寸、归一化和翻转等数据增强的策略。
3.2 预训练权重
一般我们训练时使用预训练的权重进行参数初始化,而不是随机初始化。下载地址为:https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.3/docs/model_zoo_overview.md
3.3 训练
准备好之后就可以训练了。
python train.py \
--config configs/greenhouse/bisenet_greenhouse.yml \
--do_eval \
--use_vdl \
--save_interval 1000 \
--save_dir output/greenhouse \
--num_workers 4
4 模型预测
原始的框架进行预测时是针对普通的图片预测的。为了实现对一整幅遥感影像的预测需要修改一下源代码。包括支持tif格式,使用gdal分块读取影像、进行预测、写出结果。需要修改的代码路径为:paddleseg/core/predict.py。
修改后,由于采用了分块读写的思路,可以对几十G、上百G的遥感影像进行预测了。修改完成后就执行命令进行预测。
python predict.py \
--config configs/greenhouse/bisenet_greenhouse.yml \
--model_path output/greenhouse/best_model/model.pdparams \
--image_path 影像所在文件夹/wf1.tif
--save_dir output
结果示意图如下:

5 数据、代码、视频教程
为了方便朋友们更快捷方便的上手遥感语义分割,我精心制作了更详细的教程,包括讲解、操作录屏、数据和代码,已经放在网易云课堂上。有需要的朋友可以学习了解一下。课程名称为:遥感深度学习实践—语义分割。课程总时长在一个小时左右,节省时间。
链接:http://m.study.163.com/provider/480000002275754/index.htm?share=2&shareId=480000002275754