代码随想录刷题笔记
代码随想录刷题笔记
- 一、数组
-
- 二分
- 双指针
- 滑动窗口
- 模拟
- 二、链表
- 三、哈希表
- 四、字符串
-
- 反转字符串
- 反转字符串II
- 替换空格
- 翻转字符串里的单词
- 左旋转字符串
- 实现strStr()
- 重复的子字符串
- 总结
- 五、双指针
- 六、栈和队列
-
- 基础理论
- 用栈实现队列
- 滑动窗口的最大值
- 前K个高频元素
- 总结
- 七、二叉树
-
- 基础理论
- 对称二叉树
- 从中序与后序遍历序列构造二叉树
- 二叉树的最近公共祖先
- 二叉树总结
- 八、回溯算法
-
- 理论基础
- 重新安排行程
- 九、贪心算法
-
- 摆动序列
- 跳跃游戏II
- 买卖股票的最佳时机含手续费
- 监控二叉树
- 十、动态规划
- 十一、单调栈
题目列表:代码随想录 (programmercarl.com)
一、数组
常用算法
- 二分
- 双指针
- 滑动窗口
- 模拟
二分
| 暴力 | O ( n ) O(n) O(n) |
|---|---|
| 二分 | O ( log n ) O(\text{log}n) O(logn) |
二分的前提是数组是有序的,二分法每次能排除一半的元素,时间复杂度为 O ( log n ) O(\text{log}n) O(logn)。
使用二分法是要注意解是否包含在左右边界中,在循环中,区间的定义不能改变(区间的开闭)。
双指针
| 暴力 | O ( n 2 ) O(n^2) O(n2) |
|---|---|
| 二分 | O ( n ) O(n) O(n) |
- 快慢指针(追击)
- 相向指针(相遇)
滑动窗口
| 暴力 | O ( n 2 ) O(n^2) O(n2) |
|---|---|
| 二分 | O ( n ) O(n) O(n) |
理解滑动窗口如何移动、窗口起始位置、如何更新窗口大小。
模拟
注意状态更新和数组越界。
二、链表
常用技巧:虚拟头结点
常见题型:
- 反转链表
- 迭代
- 递归
- 删除倒数第 n n n个节点、
- 快慢指针
- 链表相交
- 双指针
- 哈希表
- 环形链表
- 快慢指针
- 哈希表
注意nullptr。
三、哈希表
- 不同的数据通过哈希函数映射到统一索引的现象叫哈希碰撞,一般的解决方法有
- 拉链法
- 线性探测法
- 哈希法解决问题一般选择的数据结构:
- 数组
- set
- map
| 集合 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::set | 红黑树 | 有序 | 否 | 否 | O ( log n ) O(\text{log}n) O(logn) | O ( log n ) O(\text{log}n) O(logn) |
| std::multiset | 红黑树 | 有序 | 是 | 否 | O ( log n ) O(\text{log}n) O(logn) | O ( log n ) O(\text{log}n) O(logn) |
| std::unordered_set | 哈希表 | 无序 | 否 | 否 | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) |
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | key不可修改 | O ( log n ) O(\text{log}n) O(logn) | O ( log n ) O(\text{log}n) O(logn) |
| std::multimap | 红黑树 | key有序 | key可重复 | key不可修改 | O ( log n ) O(\text{log}n) O(logn) | O ( log n ) O(\text{log}n) O(logn) |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | key不可修改 | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) |
- 当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。但是哈希法也是牺牲了空间换取了时间,因为我们要使用额外的数组,set或者是map来存放数据,才能实现快速的查找。
四、字符串
反转字符串
双指针
反转字符串II
模拟
替换空格
空间复杂度 O ( 1 ) O(1) O(1)解法:
首先扩充数组到每个空格替换成"%20"之后的大小。然后从后向前替换空格,也就是双指针法。
其实很多数组填充类的问题,都可以先预先给数组扩容带填充后的大小,然后在从后向前进行操作。
翻转字符串里的单词
空间复杂度 O ( 1 ) O(1) O(1)解法:
- 移除多余空格(快慢指针)
- 将整个字符串反转
- 将每个单词反转
左旋转字符串
空间复杂度 O ( 1 ) O(1) O(1)解法:
- 反转区间为前n的子串
- 反转区间为n到末尾的子串
- 反转整个字符串
实现strStr()
重要Knuth-Morris-Pratt (KMP) 字符串查找算法
暴力算法: O ( m × n ) O(m\times n) O(m×n)
KMP算法: O ( m + n ) O(m+n) O(m+n)
- **主要思想:**当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。
- **前缀表:**记录下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪个位置开始重新匹配。 - **最长公共前后缀
**前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串。
后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
aabaa的最长 ~~公共 ~~相同 前后缀为aa,长度为2。 - 模式串与前缀表对应位置的数字表示的是:下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
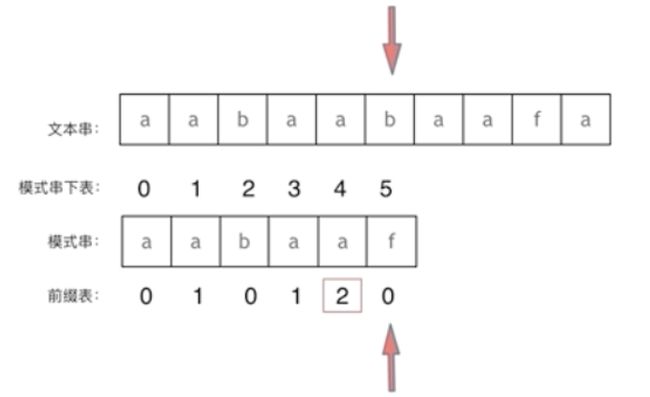
当s[i]不匹配时,应该回退到前缀表 next[i-1]中记录的下标位继续匹配。
- 构造next数组
构造next数组其实就是计算模式串s,前缀表的过程。 主要有如下三步:- 初始化
- 处理前后缀不相同的情况:回退
- 处理前后缀相同的情况:匹配长度+1
void getNext(int* next, const string& s){
// 初始化
int j = -1; // j 指向前缀末尾位置(前缀长度)
next[0] = j; // next[i] 表示 i(包括i)之前最长相等的前后缀长度(其实就是j)
for(int i = 1; i < s.size(); i++) { // i 指向后缀末尾位置,注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j; // 将j(前缀的长度)赋给next[i]
}
}
**如何回退?**举例子:
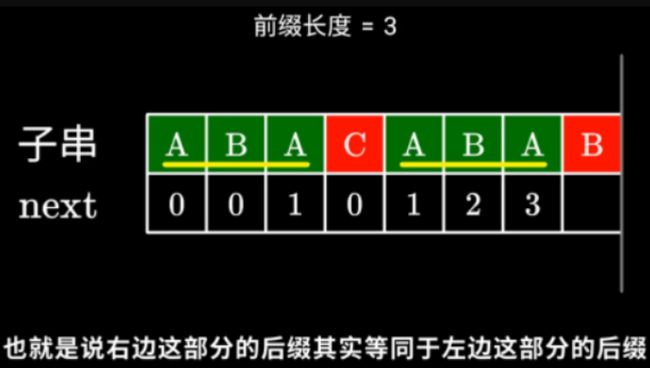
B和C不匹配,发生回退,要找到与后缀 ABA相同部分最长的前缀,其实等同于找到找到左边部分的最长相等前缀,即为n[j-1]。
- 使用前缀表进行匹配
int strStr(string haystack, string needle) {
if (needle.size() == 0) {
return 0;
}
int next[needle.size()];
getNext(next, needle);
int j = -1; // // 因为next数组里记录的起始位置为-1
for (int i = 0; i < haystack.size(); i++) { // 注意i就从0开始
while(j >= 0 && haystack[i] != needle[j + 1]) { // 不匹配
j = next[j]; // j 寻找之前匹配的位置
}
if (haystack[i] == needle[j + 1]) { // 匹配,j和i同时向后移动
j++; // i的增加在for循环里
}
if (j == (needle.size() - 1) ) { // 文本串s里出现了模式串t
return (i - needle.size() + 1);
}
}
return -1;
}
重复的子字符串
思路:构建next数组,数组长度减去最长相同前后缀的长度相当于是第一个周期的长度,也就是一个周期的长度,如果这个周期可以被整除,就说明整个数组就是这个周期的循环。
总结
- 双指针
- 反转字符串
- 替换空格,先给数组扩容再从后向前操作
- 移除元素,快慢指针
erase是 O ( n ) O(n) O(n)的操作,放在for循环里会导致 O ( n 2 ) O(n^2) O(n2)的复杂度。
- 反转
- KMP:字符串匹配问题
五、双指针
- 数组
移除元素,通过两个指针在一个for循环内完成两个for循环的工作 - 字符串
- 反转
- 扩充
- 移除
- 链表
- 快慢指针
- N数之和
- 排序 + 双指针 + 剪枝(注意剪枝条件)
六、栈和队列
基础理论
- C++标准库是有多个版本的,以下为三个最为普遍的STL版本:
- HP STL 其他版本的C++ STL,一般是以HP STL为蓝本实现出来的,HP STL是C++ STL的第一个实现版本,而且开放源代码。
- P.J.Plauger STL 由P.J.Plauger参照HP STL实现出来的,被Visual C++编译器所采用,不是开源的。
- SGI STL 由Silicon Graphics Computer Systems公司参照HP STL实现,被Linux的C++编译器GCC所采用,SGI STL是开源软件,源码可读性甚高。
- 栈是以底层容器完成其所有的工作,对外提供统一的接口,底层容器是可插拔的(也就是说我们可以控制使用哪种容器来实现栈的功能)。所以STL中栈往往不被归类为容器,而被归类为container adapter(容器适配器)。我们常用的SGI STL,如果没有指定底层实现的话,默认是以deque为缺省情况下栈的低层结构。也可以指定vector为栈的底层实现,初始化语句如下:
std::stack<int, std::vector<int> > third; // 使用vector为底层容器的栈
- 队列中先进先出的数据结构,同样不允许有遍历行为,不提供迭代器,SGI STL中队列一样是以deque为缺省情况下的底部结构。所以STL 队列也不被归类为容器,而被归类为container adapter( 容器适配器)。
用栈实现队列
力扣题目链接
stkIn:队尾元素
stkOut:队首元素
- push() :直接压入stkIn。
- pop() :先peek(),再stkOut.pop()。
- peek():若stkB不为空,直接返回stkOut.top();否则将stkIn的元素全部压入stkOut中,再返回stkOut.top()。
- empty() :若stkIn与stkOut均为空则为空。
滑动窗口的最大值
deque实现单调栈。
前K个高频元素
priority_queue 容器适配器定义了一个元素有序排列的队列。默认队列头部的元素优先级最高。因为它是一个队列,所以只能访问第一个元素,这也意味着优先级最高的元素总是第一个被处理。但是如何定义“优先级”完全取决于我们自己。
priority_queue 模板有 3 个参数,其中两个有默认的参数;第一个参数是存储对象的类型,第二个参数是存储元素的底层容器,第三个参数是函数对象,它定义了一个用来决定元素顺序的断言。因此模板类型是:
template <typename T, typename Container=std::vector<T>, typename Compare=std::less<T>> class priority_queue;
// less 大顶堆
// greater 小顶堆
priority_queue 实例默认有一个 vector 容器。函数对象类型 less 是一个默认的排序断言,定义在头文件 functional中,决定了容器中最大的元素会排在队列前面。functional中定义了 greater,用来作为模板的最后一个参数对元素排序,最小元素会排在队列前面。当然,如果指定模板的最后一个参数,就必须提供另外的两个模板类型参数。
class Solution {
public:
static bool cmp(pair<int, int>& m, pair<int, int>& n) {
return m.second > n.second; // 小顶堆
}
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int, int> occurrences;
for (auto& v : nums) {
occurrences[v]++;
}
// pair 的第一个元素代表数组的值,第二个元素代表了该值出现的次数
priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(&cmp)> q(cmp);
for (auto& [num, count] : occurrences) {
if (q.size() == k) {
if (q.top().second < count) {
q.pop();
q.emplace(num, count);
}
} else {
q.emplace(num, count);
}
}
vector<int> ret;
while (!q.empty()) {
ret.emplace_back(q.top().first);
q.pop();
}
return ret;
}
};
总结
提问:
- C++中stack,queue 是容器么?
- 我们使用的stack,queue是属于那个版本的STL?
- 我们使用的STL中stack,queue是如何实现的?
- stack,queue 提供迭代器来遍历空间么?
栈里面的元素在内存中是连续分布的么?
- 陷阱1:栈是容器适配器,底层容器使用不同的容器,导致栈内数据在内存中是不是连续分布。
- 陷阱2:缺省情况下,默认底层容器是deque,那么deque的在内存中的数据分布是什么样的呢? 答案是:不连续的,
七、二叉树
基础理论
一、二叉树的种类
- 满二叉树
- 如果一棵二叉树只有度为0的结点和度为2的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。
- 每层的节点数为 2 k − 1 2^{k-1} 2k−1。
- 深度为 k k k的满二叉树节点个数为 2 0 + 2 1 + ⋯ + 2 k − 1 = 2 k − 1 2^0+2^1+ \cdots + 2^{k-1} = 2^k -1 20+21+⋯+2k−1=2k−1。
- 完全二叉树
- 在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。
- 若最底层为第 h 层,则该层包含 [ 1 , 2 h − 1 ] [1,2^{h-1}] [1,2h−1] 个节点。
- 二叉搜索树
二叉搜索树是一个有序树:- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉排序树
- 平衡搜索二叉树
- 又被称为AVL(Adelson-Velsky and Landis)树,且具有以下性质:
- 它是一棵空树或它的左右两个子树的高度差的绝对值不超过1。
- 左右两个子树都是一棵平衡二叉树。
- C++中map、set、multimap,multiset的底层实现都是平衡二叉搜索树(具体来说是红黑树),所以map、set的增删操作时间时间复杂度是 l o g n ( 0 ) logn(0) logn(0)。unordered_map、unordered_set,unordered_map、unordered_map底层实现是哈希表。
- 又被称为AVL(Adelson-Velsky and Landis)树,且具有以下性质:
二、二叉树的存储方式
- 链式存储(指针)
- 顺序存储(数组)
- 对于完全二叉树,如果父节点的数组下标是 i i i,那么它的左孩子就是 2 i + 1 2i+1 2i+1,右孩子就是 2 i + 2 2i+2 2i+2。
三、二叉树的遍历方式
- 深度优先(前中后指中间节点的遍历顺序)
- 前序遍历(迭代、递归)
- 中序遍历(迭代、递归)
- 后续遍历(迭代、递归)
- 广度优先
- 层次遍历(迭代)
DFS两种实现
- 递归三要素:
- 确定递归函数的参数和返回值
- 确定终止条件
- 确定单层递归的逻辑
- 迭代:
- 前序:处理顺序与访问顺序一致
- 先处理根结点
- right入栈、left入栈**(空节点不入栈,出栈顺序中左右)**
- 前序:处理顺序与访问顺序一致
vector<int> preorderTraversal(TreeNode* root) {
stack<TreeNode*> stk;
vector<int> res;
if(root != nullptr) stk.emplace(root);
while(!stk.empty()) {
TreeNode* cur = stk.top();
stk.pop();
res.emplace_back(cur->val);
if(cur->right != nullptr) stk.emplace(cur->right);
if(cur->left != nullptr) stk.emplace(cur->left);
}
return res;
}
- 中序:处理顺序与访问顺序不一致
- 根结点入栈、left(不为空)入栈
- 弹栈访问数据
- right(不为空)入栈
vector<int> inorderTraversal(TreeNode* root) {
stack<TreeNode*> stk;
vector<int> res;
TreeNode* cur = root;
while(cur != nullptr || !stk.empty()) {
if(cur != nullptr) {
stk.emplace(cur);
cur = cur->left;
} else {
cur = stk.top();
stk.pop();
res.emplace_back(cur->val);
cur = cur->right;
}
}
return res;
}
- 后序:处理顺序与访问顺序一致
- right入栈、left入栈**(空节点不入栈,出栈顺序左右中)**
- 弹栈访问数据
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> stk;
vector<int> res;
if(root == nullptr) return res;
stk.emplace(root);
while(!stk.empty()) {
TreeNode* cur = stk.top();
stk.pop();
res.emplace_back(cur->val);
if(cur->left != nullptr) stk.emplace(cur->left);
if(cur->right != nullptr) stk.emplace(cur->right);
}
reverse(res.begin(), res.end());
return res;
}
BFS实现:
队列
对称二叉树
比较leftNode->left与rightNode->right、leftNode->right与rightNode->left。
从中序与后序遍历序列构造二叉树
类似题目:剑指 Offer 07. 重建二叉树
后序遍历的顺序为:左右中
后序遍历postorder的最后一个元素为当前根节点root,在中序遍历搜索root的索引,可将中序遍历inorder划分为[leftTree | root | rightTree],随即可求出leftTree和rightTree的长度,根据子树长度可将后序遍历划分为leftTree | rightTree | root。由于构建二叉树时确定的是postorder中的root位置和子树长度,所以右子树的根节点为root-1,左子树的根节点为root - 1 - rightLen。
递归构建二叉树。
class Solution {
public:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
// inorder 根结点左侧为左子树,右侧为右子树
for(int i = 0; i < inorder.size(); ++ i) {
dict[inorder[i]] = i;
}
return bulid(inorder, postorder, inorder.size() - 1, 0, inorder.size() - 1);
}
private:
unordered_map<int, int> dict;
TreeNode* bulid(vector<int>& inorder, vector<int>& postorder, int i, int l, int r) {
if(l > r) return nullptr;
TreeNode* root = new TreeNode(postorder[i]);
int rootIdx = dict[postorder[i]];
root->left = bulid(inorder, postorder, i - 1 - (r - rootIdx), l, rootIdx - 1); // (r - rootIdx) 为右子树长度
root->right = bulid(inorder, postorder, i - 1, rootIdx + 1, r);
return root;
}
};
同理,前序遍历是构建二叉树时确定的是preorder中的root位置和子树长度,所以左子树的根节点为root+1,左子树的根节点为root + 1 + leftLen。
二叉树的最近公共祖先
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (root == q || root == p || root == NULL) return root;
TreeNode* left = lowestCommonAncestor(root->left, p, q);
TreeNode* right = lowestCommonAncestor(root->right, p, q);
if (left != NULL && right != NULL) return root;
if (left == NULL) return right;
return left;
}
};
二叉树总结
- 二叉树的理论基础
- 二叉树的种类
- 存储方式:链式、顺序
- 遍历方式
- 定义方式
- 二叉树的遍历方式
- 深度(递归、迭代)
- 广度(队列)
- 求二叉树的属性
- 是否对称
- 深度
- 节点数
- 平衡(优先递归,迭代效率低)
- 路径(回溯)
- 左下角的值
- 二叉树的修改与构造
- 翻转
- 构造(优先递归)
- 合并
- 求二叉搜索树的属性
- 中序遍历,有序数组
- 二叉树公共祖先问题
- 优先递归
- 搜索树可以迭代
八、回溯算法
理论基础
- 回溯的效率
回溯法并不是什么高效的算法。因为回溯的本质是穷举,穷举所有可能,然后选出我们想要的答案,如果想让回溯法高效一些,可以加一些剪枝的操作,但也改不了回溯法就是穷举的本质。 - 回溯解决的问题
- 组合问题:N个数里面按一定规则找出k个数的集合
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 棋盘问题:N皇后,解数独等等
- 理解回溯
回溯法解决的问题都可以抽象为树形结构。因为回溯法解决的都是在集合中递归查找子集,集合的大小就构成了树的宽度,递归的深度构成的树的深度。 - 回溯模板
回溯三部曲:- 回溯函数模板返回值以及参数
- 回溯函数终止条件
- 回溯搜索的遍历过程
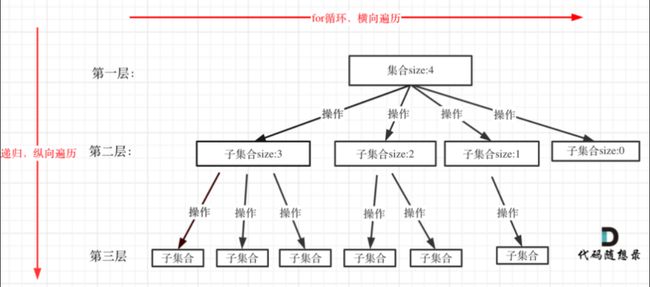
伪代码:
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
- 递归的返回值
- 如果需要搜索整棵二叉树且不用处理递归返回值,递归函数就不要返回值。
- 如果需要搜索整棵二叉树且需要处理递归返回值,递归函数就需要返回值。
- 如果要搜索其中一条符合条件的路径,那么递归一定需要返回值,因为遇到符合条件的路径了就要及时返回。
重新安排行程
方法一:回溯
- 记录映射关系(字典序排序)
- 回溯
- 终止条件
- 避免死循环
- 遇到符合条件的路径及时返回
class Solution {
public:
vector<string> findItinerary(vector<vector<string>>& tickets) {
int ticketNum = tickets.size();
if(ticketNum == 1) return tickets[0];
for(vector<string> t : tickets) {
targets[t[0]][t[1]] ++;
}
res.emplace_back("JFK");
recur("JFK", ticketNum);
return res;
}
private:
vector<string> res;
unordered_map<string, map<string,int>> targets;
bool recur(const string& from, int ticketNum) {
if(res.size() == ticketNum + 1) return true;
for(auto& to : targets[from]) { // 必须是引用
if(to.second > 0) {
-- to.second;
res.emplace_back(to.first);
if(recur(to.first, ticketNum)) return true;
res.pop_back();
++ to.second;
}
}
return false;
}
};
方法二:Hierholzer 算法
化简题意:给定一个 n n n个点 m m m 条边的图,要求从指定的顶点出发,经过所有的边恰好一次(可以理解为给定起点的「一笔画」问题),使得路径的字典序最小。
这种「一笔画」问题与欧拉图或者半欧拉图有着紧密的联系,下面给出定义:
- 通过图中所有边恰好一次且行遍所有顶点的通路称为欧拉通路;
- 通过图中所有边恰好一次且行遍所有顶点的回路称为欧拉回路;
- 具有欧拉回路的无向图称为欧拉图;
- 具有欧拉通路但不具有欧拉回路的无向图称为半欧拉图。
如果没有保证至少存在一种合理的路径,我们需要判别这张图是否是欧拉图或者半欧拉图,具体地:
- 对于无向图 G G G, G G G 是欧拉图当且仅当 G G G是连通的且没有奇度顶点。
- 对于无向图 G G G, G G G是半欧拉图当且仅当 G G G是连通的且 G G G中恰有 0 0 0个或 2 2 2 个奇度顶点。
- 对于有向图 G G G, G G G 是欧拉图当且仅当 G G G 的所有顶点属于同一个强连通分量且每个顶点的入度和出度相同。
- 对于有向图 G G G, G G G 是半欧拉图当且仅当
- 如果将 G G G中的所有有向边退化为无向边时,那么 G G G 的所有顶点属于同一个强连通分量;
- 最多只有一个顶点的出度与入度差为 1 1 1;
- 最多只有一个顶点的入度与出度差为 1 1 1;
- 所有其他顶点的入度和出度相同。
Hierholzer 算法用于在连通图中寻找欧拉路径,其流程如下:
- 从起点出发,进行深度优先搜索。
- 每次沿着某条边从某个顶点移动到另外一个顶点的时候,都需要删除这条边。
- 如果没有可移动的路径,则将所在节点加入到栈中,并返回。
注意到只有那个入度与出度差为 1 1 1 的节点会导致死胡同。而该节点必然是最后一个遍历到的节点。我们可以改变入栈的规则,当我们遍历完一个节点所连的所有节点后,我们才将该节点入栈(即逆序入栈)。
对于当前节点而言,从它的每一个非「死胡同」分支出发进行深度优先搜索,都将会搜回到当前节点。而从它的「死胡同」分支出发进行深度优先搜索将不会搜回到当前节点。也就是说当前节点的死胡同分支将会优先于其他非「死胡同」分支入栈。
这样就能保证我们可以「一笔画」地走完所有边,最终的栈中逆序地保存了「一笔画」的结果。我们只要将栈中的内容反转,即可得到答案。
class Solution {
public:
unordered_map<string, priority_queue<string, vector<string>, std::greater<string>>> vec; // string->priority_queue 小顶堆
vector<string> stk;
void dfs(const string& curr) { // 深度优先搜索
while (vec.count(curr) && vec[curr].size() > 0) { // 映射表中存在当前出发点,且目的节点数不为0
string tmp = vec[curr].top(); //字典序大的先入栈,逆序后字典序最小
vec[curr].pop(); // 移除当前边
dfs(move(tmp));
}
stk.emplace_back(curr); // 遇到死胡同入栈
}
vector<string> findItinerary(vector<vector<string>>& tickets) {
for (auto& it : tickets) {
vec[it[0]].emplace(it[1]); // 构建映射表
}
dfs("JFK");
reverse(stk.begin(), stk.end());
return stk;
}
};
九、贪心算法
摆动序列
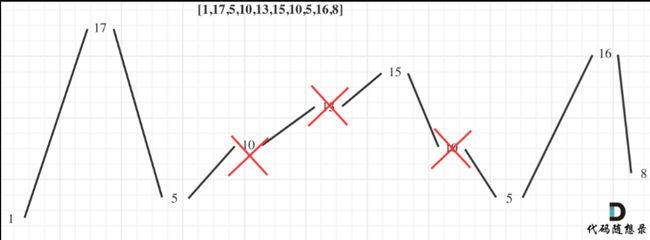
class Solution {
public:
int wiggleMaxLength(vector<int>& nums) {
if (nums.size() <= 1) return nums.size();
int curDiff = 0; // 当前一对差值
int preDiff = 0; // 前一对差值
int result = 1; // 记录峰值个数,序列默认序列最右边有一个峰值
for (int i = 0; i < nums.size() - 1; i++) {
curDiff = nums[i + 1] - nums[i];
// 出现峰值
if ((curDiff > 0 && preDiff <= 0) || (preDiff >= 0 && curDiff < 0)) {
result++;
preDiff = curDiff;
}
}
return result;
}
};
跳跃游戏II

class Solution {
public:
int jump(vector<int>& nums) {
int n = nums.size();
if(n == 1) return 0;
int step = 1;
int rightmost = nums[0];
int nextStepMost = 0;
if(rightmost >= n - 1) return step;
for(int i = 1; i < n; i++) {
nextStepMost = max(nextStepMost, i + nums[i]);
if(nextStepMost >= n - 1) return ++ step;
if(rightmost <= i) {
++ step;
rightmost = nextStepMost;
}
}
return step;
}
};
买卖股票的最佳时机含手续费
class Solution {
public:
int maxProfit(vector<int>& prices, int fee) {
int result = 0;
int minPrice = prices[0]; // 记录最低价格
for (int i = 1; i < prices.size(); i++) {
// 情况二:相当于买入
if (prices[i] < minPrice) minPrice = prices[i];
// 情况三:保持原有状态(因为此时买则不便宜,卖则亏本)
if (prices[i] >= minPrice && prices[i] <= minPrice + fee) {
continue;
}
// 计算利润,可能有多次计算利润,最后一次计算利润才是真正意义的卖出
if (prices[i] > minPrice + fee) {
result += prices[i] - minPrice - fee;
minPrice = prices[i] - fee; // 情况一,这一步很关键
}
}
return result;
}
};
监控二叉树
class Solution {
private:
int result;
int traversal(TreeNode* cur) {
// 0 无覆盖; 1:存在摄像头; 2: 不需要摄像头(被覆盖或空子树)
if (cur == NULL) return 2; // 空子树
int left = traversal(cur->left); // 左
int right = traversal(cur->right); // 右
if (left == 2 && right == 2) return 0; // 左右子树为空 或者 左右子树被覆盖但是没有相机
else if (left == 0 || right == 0) { //
result++; //左右子树中有一个未被覆盖
return 1; //安装摄像头
} else return 2; // 左右子树均被覆盖,且至少存在一个摄像头
}
public:
int minCameraCover(TreeNode* root) {
result = 0;
if (traversal(root) == 0) { // root 无覆盖
result++;
}
return result;
}
};
十、动态规划
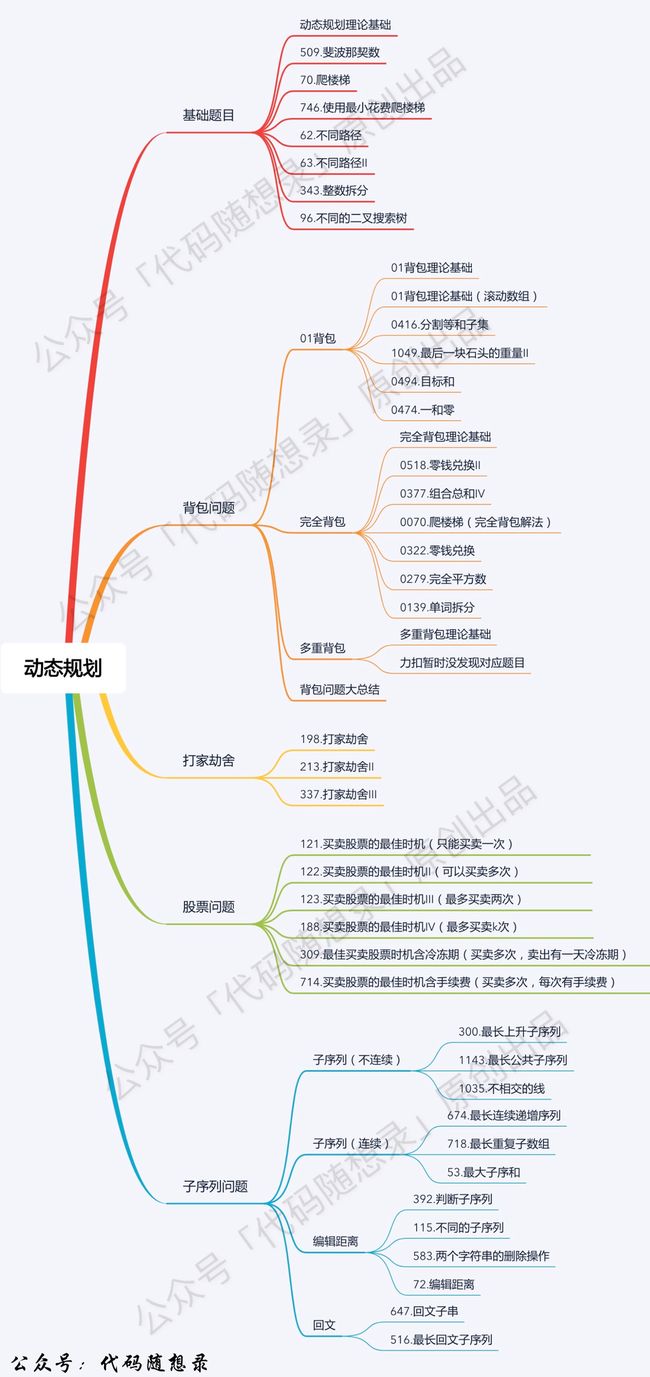
- 确定dp数组(dp table)以及下标的含义
- 确定递推公式
- dp数组如何初始化
- 确定遍历顺序
- 举例推导dp数组
十一、单调栈
通常是一维数组,要寻找任一个元素的右边或者左边第一个比自己大或者小的元素的位置,此时我们就要想到可以用单调栈了。