代码随想录1刷—二叉树篇(三)
代码随想录1刷—二叉树篇(三)
-
-
- [236. 二叉树的最近公共祖先](https://leetcode.cn/problems/lowest-common-ancestor-of-a-binary-tree/)
-
-
- 注意
-
- 题外话:各种二叉树~
- [235. 二叉搜索树的最近公共祖先](https://leetcode.cn/problems/lowest-common-ancestor-of-a-binary-search-tree/)
- [701. 二叉搜索树中的插入操作](https://leetcode.cn/problems/insert-into-a-binary-search-tree/)
- [450. 删除二叉搜索树中的节点](https://leetcode.cn/problems/delete-node-in-a-bst/)(!)
-
- 递归:利用搜索树的特性
- 递归:普通二叉树的删除方式
- 迭代法(so复杂不想学)
- [669. 修剪二叉搜索树](https://leetcode.cn/problems/trim-a-binary-search-tree/)
-
- 递归法
- 迭代法
- [108. 将有序数组转换为二叉搜索树](https://leetcode.cn/problems/convert-sorted-array-to-binary-search-tree/)
- [538. 把二叉搜索树转换为累加树](https://leetcode.cn/problems/convert-bst-to-greater-tree/)
-
236. 二叉树的最近公共祖先
最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”

class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(root == q || root == p || root == nullptr)
return root;
TreeNode* left = lowestCommonAncestor(root->left,p,q);
TreeNode* right = lowestCommonAncestor(root->right,p,q);
if(left != nullptr && right != nullptr) return root;
if(left == nullptr && right != nullptr) return right;
return left;
}
};
注意
-
求最小公共祖先,需要从底向上遍历,而二叉树只能通过后序遍历(即:回溯)实现从底向上的遍历。
-
在回溯的过程中,因为要使用递归函数的返回值(也就是代码中的left和right)做逻辑判断,所以必须要遍历整棵二叉树,即使已经找到结果了,依然要把其他节点遍历完。
-
要理解如果返回值left为空,right不为空的情况下,为什么返回right。
-
如果递归函数有返回值,如何区分要搜索一条边,还是搜索整个树。
搜索一条边的写法:
if (递归函数(root->left)) return ; if (递归函数(root->right)) return ; //235. 二叉搜索树的最近公共祖先属于这个搜索整个树写法:
left = 递归函数(root->left); right = 递归函数(root->right); left与right的逻辑处理; //本题属于这个
题外话:各种二叉树~
二叉树,二叉平衡树,完全二叉树,二叉搜索树,还有平衡二叉搜索树,要注意各自特性,好好区分~
-
平衡二叉搜索数是不是二叉搜索树和平衡二叉树的结合?
- 是的,是二叉搜索树和平衡二叉树的结合。
-
平衡二叉树与完全二叉树的区别在于底层节点的位置?
-
首先明确:完全二叉树一定是平衡二叉树
-
是的,其区别在于:完全二叉树底层必须是从左到右连续的,且次底层是满的。
-
-
堆是完全二叉树和排序的结合,而不是平衡二叉搜索树?
- 堆是一棵完全二叉树,同时保证父子节点的顺序关系(有序), 堆又分为最大堆和最小堆。堆的性质非常简单,如果是最大堆,对于每个结点,都有结点的值大于两个孩子结点的值。如果是最小堆,那么对于每个结点,都有结点的值小于孩子结点的值。
- 而搜索树是父节点大于左孩子,小于右孩子,所以堆不是平衡二叉搜索树。
235. 二叉搜索树的最近公共祖先
和236. 二叉树的最近公共祖先不同,普通二叉树求最近公共祖先需要使用回溯,从底向上来查找,二叉搜索树就不用了,因为搜索树有序(相当于自带方向),那么只要从上向下遍历就可以了。从上到下遍历时,cur节点是数值在[p, q]区间中则说明该节点cur就是最近公共祖先了。
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (root->val > p->val && root->val > q->val) {
return lowestCommonAncestor(root->left, p, q);
} else if (root->val < p->val && root->val < q->val) {
return lowestCommonAncestor(root->right, p, q);
} else return root;
}
};
//迭代法,二叉搜索树的迭代法甚至比递归更容易理解,也是因为其有序性(自带方向性),按照目标区间找就行了。
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
while(root) {
if (root->val > p->val && root->val > q->val) {
root = root->left;
} else if (root->val < p->val && root->val < q->val) {
root = root->right;
} else return root;
}
return nullptr;
}
};
701. 二叉搜索树中的插入操作
只要遍历二叉搜索树,找到空节点 插入元素就可以了。
这里递归函数要不要有返回值呢?
-
可以有,也可以没有,递归函数有返回值的话,可以利用返回值完成新加入的节点与其父节点的赋值操作,如果没有返回值的话,需要记录上一个节点(parent),遇到空节点了,就让parent左孩子或者右孩子指向新插入的节点,然后结束递归。两个版本代码如下:
-
有返回值
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
if(root == nullptr){
TreeNode* node = new TreeNode(val);
return node;
}
if(root->val > val)
root->left = insertIntoBST(root->left,val);
if(root->val < val)
root->right = insertIntoBST(root->right,val);
return root;
}
};
- 无返回值
class Solution {
private:
TreeNode* parent;
void traversal(TreeNode* cur, int val){
if(cur == nullptr){
TreeNode* node = new TreeNode(val);
if(val > parent->val)
parent->right = node;
else parent->left = node;
return;
}
parent = cur;
if(cur->val > val)
return traversal(cur->left,val);
if(cur->val < val)
return traversal(cur->right,val);
}
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
parent = new TreeNode(0);
if(root == nullptr){
root = new TreeNode(val);
}
else{
traversal(root,val);
}
return root;
}
};
- 迭代版本
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
if (root == NULL) {
TreeNode* node = new TreeNode(val);
return node;
}
TreeNode* cur = root;
TreeNode* parent = root;
while(cur != nullptr){
parent = cur;
if(cur->val > val)
cur = cur->left;
else
cur = cur->right;
}
TreeNode* node = new TreeNode(val);
if(val < parent->val)
parent->left = node;
else
parent->right = node;
return root;
}
};
450. 删除二叉搜索树中的节点(!)
二叉搜索树添加节点只需要在叶子上添加就可以的,不涉及到结构的调整,而删除节点操作涉及到结构的调整。
这里依然使用递归函数的返回值来完成把节点从二叉树中移除的操作。此题最关键的逻辑就是第五种情况(删除一个左右孩子都不为空的节点),这种情况一定要想清楚。
递归中给出了两种写法,会第一种(利用搜索树的特性)就可以了,第二种递归写法(通用)比较绕。
递归:利用搜索树的特性
- 第一种情况:没找到删除的节点,遍历到空节点直接返回了
- 找到删除的节点
- 第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
- 第三种情况:删除节点的左孩子为空,右孩子不为空,删除节点,右孩子补位,返回右孩子为根节点
- 第四种情况:删除节点的右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
- 第五种情况:左右孩子节点都不为空,则将删除节点的左子树头结点(左孩子)放到删除节点的右子树的最左面节点的左孩子上,返回删除节点右孩子为新的根节点。
第五种情况有点难以理解,看下面动画:
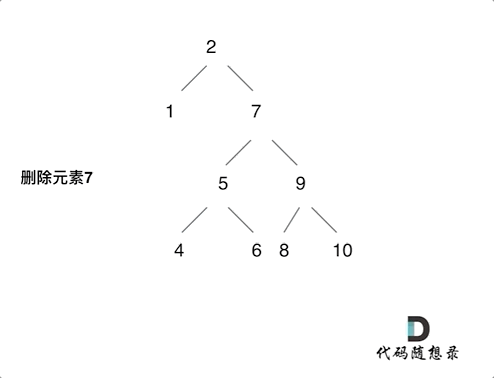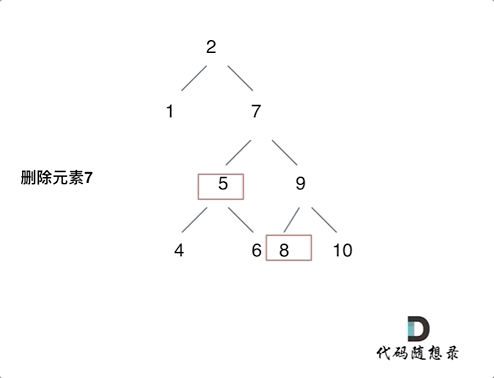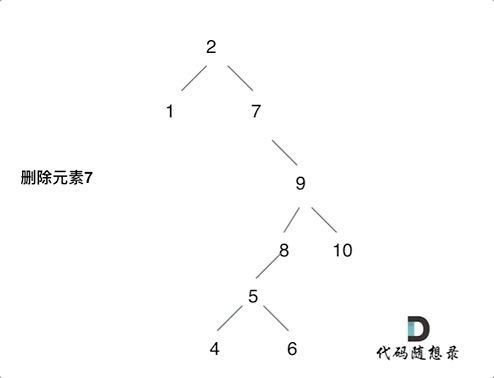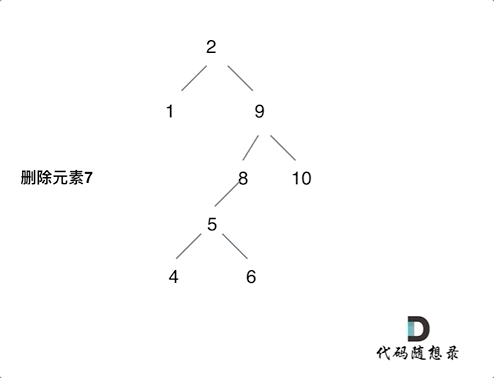
动画中,删除元素7, 那么删除节点(元素7)的左孩子就是5,删除节点(元素7)的右子树的最左面节点是元素8。把5为根节点的子树移到8的左孩子的位置,要删除的节点(元素7)的右孩子(元素9)为新的根节点。这样就完成删除元素7的逻辑。
class Solution {
public:
TreeNode* deleteNode(TreeNode* root, int key) {
//第一种情况:没找到删除的节点,遍历到空节点直接返回了
if(root == nullptr)
return root;
//找到删除的节点
if(root->val == key) {
//第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
if(root->left == nullptr && root->right == nullptr){
delete root;
root = nullptr;
return nullptr;
}
//第三种情况:删除节点的左孩子为空,右孩子不为空,删除节点,右孩子补位,返回右孩子为根节点
if(root->left == nullptr && root->right != nullptr){
auto retNode = root->right;
delete root;
return retNode;
}
//第四种情况:删除节点的右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
if(root->left != nullptr && root->right == nullptr){
auto retNode = root->left;
delete root;
return retNode;
}
//五种情况:左右孩子节点都不为空,则将删除节点的左子树头结点(左孩子)放到删除节点的右子树的最左面节点的左孩子上,返回删除节点右孩子为新的根节点。
else{
TreeNode* cur = root->right; //找右子树最左面的结点
while(cur->left != nullptr){
cur = cur->left;
}
cur->left = root->left; //把要删除的结点左子树头结点放在删除节点的右子树的最左面结点的左孩子上位置上。
TreeNode* tmp = root; //下面要删除,这里保存一下
root = root->right; //返回删除结点的右孩子作为新的根节点
delete tmp;
return root;
}
}
if(root->val > key)
root->left = deleteNode(root->left,key);
if(root->val < key)
root->right = deleteNode(root->right,key);
return root;
}
};
递归:普通二叉树的删除方式
普通二叉树的删除方式(没有使用搜索树的特性,遍历整棵树),直接用交换值的操作来删除目标节点。
目标节点(要删除的节点)需要操作两次:
- 第一次是和目标节点的右子树最左面节点交换。
- 第二次直接被NULL覆盖了。
class Solution {
public:
TreeNode* deleteNode(TreeNode* root, int key) {
if(root == nullptr) return root;
if(root->val == key){
if(root->right == nullptr){ //第二次操作
return root->left;
}
TreeNode* cur = root->right;
while(cur->left){
cur = cur->left;
}
swap(root->val,cur->val); //第一次操作
}
root->left = deleteNode(root->left,key);
root->right = deleteNode(root->right,key);
return root;
}
};
迭代法(so复杂不想学)
class Solution {
private:
TreeNode* deleteOneNote(TreeNode* target){ //删~
if(target == nullptr) return target;
if(target->right ==nullptr) return target->left;
TreeNode* cur = target->right;
while(cur->left){
cur = cur->left;
}
cur->left = target->left;
return target->right;
}
public:
TreeNode* deleteNode(TreeNode* root, int key) {
if(root == nullptr) return root;
TreeNode* cur = root;
TreeNode* pre = nullptr; //记录一下cur的父节点,用于删除cur噢
while(cur){
if(cur->val == key)
break;
pre = cur;
if(cur->val > key)
cur = cur->left;
else{
cur = cur->right;
}
}
if(pre == nullptr){ //搜索树只有头结点
return deleteOneNote(cur);
}
//pre是要删除结点的父节点,需要知道到底删左孩子还是右孩子
if(pre->left && pre->left->val == key)
pre->left = deleteOneNote(cur);
if(pre->right && pre->right->val == key)
pre->right = deleteOneNote(cur);
return root;
}
};
669. 修剪二叉搜索树
递归法


//暴力递归~
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if(root == nullptr)
return nullptr;
if(root->val < low)
return trimBST(root->right,low,high); //不符合,直接移除然后把子树挪上来~
if(root->val > high)
return trimBST(root->left,low,high);
root->left = trimBST(root->left,low,high);
root->right = trimBST(root->right,low,high);
return root;
}
};
迭代法
因为二叉搜索树的有序性,不需要使用栈模拟递归的过程。在剪枝的时候,可以分为三步:
- 将root移动到 [ L , R ] [L, R] [L,R] 范围内,注意是左闭右闭区间
- 剪枝左子树
- 剪枝右子树
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if (root == nullptr)
return nullptr;
//处理头结点,让root移动到[low,high] 范围内,注意是左闭右闭
while (root != nullptr && (root->val < low || root->val > high)) {
if (root->val < low)
root = root->right; // 小于L往右走
else
root = root->left; // 大于R往左走
}
TreeNode *curL = root;
// 此时root已经在[low,high] 范围内,处理左孩子元素小于low的情况
while (curL != nullptr) {
while (curL->left && curL->left->val < low) {
curL->left = curL->left->right;
}
curL = curL->left;
}
TreeNode *curH = root;
// 此时root已经在[low,high] 范围内,处理右孩子大于high的情况
while (curH != nullptr) {
while (curH->right && curH->right->val > high) {
curH->right = curH->right->left;
}
curH = curH->right;
}
return root;
}
};
108. 将有序数组转换为二叉搜索树
其实这里不用强调平衡二叉搜索树,数组构造二叉树,构成平衡树是自然而然的事情,因为大家默认都是从数组中间位置取值作为节点元素,一般不会随机取,所以想构成不平衡的二叉树是自找麻烦。
在106. 从中序与后序遍历序列构造二叉树和[654. 构造最大二叉树](https://programmercarl.com/0654.最大二叉树.html)中其实已经讲过了如何根据数组构造一棵二叉树。本质就是寻找分割点,分割点作为当前节点,然后递归左区间和右区间。本题其实要比前面的两道简单,因为有序数组构造二叉搜索树,寻找分割点非常容易,分割点就是数组中间位置的节点。那么为问题来了,如果数组长度为偶数,中间节点有两个,取哪一个?取哪一个都可以,只不过构成了不同的平衡二叉搜索树。
class Solution {
private: //(在构造二叉树的时候尽量不要重新定义左右区间数组,而是用下标来操作原数组。)
TreeNode* traversal(vector<int>& nums,int left,int right){
if(left > right)
return nullptr;
int mid = left + (right-left) / 2; //此处如果数组为偶数,有两个mid,取得是靠左边的
//本句实际上相当于int mid = (left + right) / 2;
//但直接写(left + right) / 2存在数值越界的问题,例如left和right都是最大int,这么操作就越界了
TreeNode* root = new TreeNode(nums[mid]);
root->left = traversal(nums,left,mid-1); //用递归函数的返回值来构造中节点的左右孩子。
root->right = traversal(nums,mid+1,right);
return root;
}
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
TreeNode* root = traversal(nums,0,nums.size()-1);
return root;
}
};
//迭代法可以通过三个队列来模拟,一个队列放遍历的节点,一个队列放左区间下标,一个队列放右区间下标。
//模拟的就是取中间元素,然后不断分割去构造二叉树的过程
class Solution {
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
if (nums.size() == 0) return nullptr;
TreeNode* root = new TreeNode(0); // 初始根节点
queue<TreeNode*> nodeQue; // 放遍历的节点
queue<int> leftQue; // 保存左区间下标
queue<int> rightQue; // 保存右区间下标
nodeQue.push(root); // 根节点入队列
leftQue.push(0); // 0为左区间下标初始位置
rightQue.push(nums.size() - 1); // nums.size() - 1为右区间下标初始位置
while (!nodeQue.empty()) {
TreeNode* curNode = nodeQue.front();
nodeQue.pop();
int left = leftQue.front(); leftQue.pop();
int right = rightQue.front(); rightQue.pop();
int mid = left + ((right - left) / 2);
curNode->val = nums[mid]; // 将mid对应的元素给中间节点
if (left <= mid - 1) { // 处理左区间
curNode->left = new TreeNode(0);
nodeQue.push(curNode->left);
leftQue.push(left);
rightQue.push(mid - 1);
}
if (right >= mid + 1) { // 处理右区间
curNode->right = new TreeNode(0);
nodeQue.push(curNode->right);
leftQue.push(mid + 1);
rightQue.push(right);
}
}
return root;
}
};
538. 把二叉搜索树转换为累加树
二叉搜索树的中序遍历数组是有序的,实际上就是对有序数组计算累加,而中序遍历后直接进行累加的话,实际上第一次就要加全部,第二次少加一个,复杂化了,所以进行反中序遍历,如此得到倒序的数组进行累加,第一次累加仅加一个值,以此类推。
- 需要一个pre指针记录当前遍历节点cur的前一个节点,这样才方便做累加。
- 因为要遍历整棵树,所以不需要递归函数的返回值做什么操作了。
- 要右中左来遍历二叉树, 中节点的处理逻辑就是让cur的数值加上前一个节点的数值。
- 遇空就终止。
class Solution {
private:
int pre;
void traversal(TreeNode* cur){
if(cur == nullptr)
return;
traversal(cur->right);
cur->val += pre;
pre = cur->val;
traversal(cur->left);
}
public:
TreeNode* convertBST(TreeNode* root) {
pre = 0;
traversal(root);
return root;
}
};
//迭代 可以直接套模板~
class Solution {
private:
int pre; // 记录前一个节点的数值
void traversal(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
while (cur != nullptr || !st.empty()) {
if (cur != nullptr) {
st.push(cur);
cur = cur->right; // 右
} else {
cur = st.top(); // 中
st.pop();
cur->val += pre;
pre = cur->val;
cur = cur->left; // 左
}
}
}
public:
TreeNode* convertBST(TreeNode* root) {
pre = 0;
traversal(root);
return root;
}
};